ChatGPT 介绍
目录
什么是 AIGC?
图灵测试
chatgpt的发展历史
聊天机器人 Eliza
Eliza 后辈 Alice
机器学习 smaterChild
人工神经网络
Transformer
OpenAI
(Generative Pre-trained Transformer)
AI会导致我们失业吗
什么是 AIGC?
AIGC,即AI-generated Content,是一种利用人工智能进行内容创作的方式,被认为是继PGC(Professionally-generated Content)和UGC(User-generated Content)之后的一种新型内容创作方式。
AIGC在文字、图片、音视频、软件开发等多个领域发展迅速,近几年也有很多专注于AIGC的创作体验平台,用户输入一句话,让AI合成一张与之相关的图片描述,或者更常见的是,输入一篇文章的描述,或者只是一个故事的开头,然后让 AI 为您完成文章。它在任何需要写作或内容创建的地方都有广泛的应用,例如编写财务报告、开发代码或创建销售/营销材料。它可以帮助人们更快地理解和分析复杂的信息,从而帮助他们做出更好的决策并产生巨大的价值。由于技术的进步,这些提高生产力的愿景正在成为现实。
以前AI只是辅助内容创作的工具,而今天AI已经可以成为创作的主体,能够独立完成写作、设计、绘画等创意性工作。
AIGC能够生成文本、图像、视频、音频等多种形式的内容。随着技术的发展,AIGC已经开始被广泛应用于新闻、娱乐、教育、医疗、金融和广告等领域,其应用范围还在不断扩大。

图灵测试
什么是图灵测试?
图灵测试是由英国数学家艾伦·图灵(Alan Turing)在1950年提出的一种测试,用于评估计算机系统是否具有与人类智能相当的能力。
图灵测试的基本原理是,一个测试者与一个计算机程序进行对话,如果测试者无法区分程序的回答是由人类还是计算机生成的,那么该计算机程序被认为通过了图灵测试。测试者可以问任何问题,包括有关常识、逻辑和语言等方面的问题。
图灵测试的目的是评估计算机是否具有人类智能的能力,即是否能够表现出类似于人类的思维方式和行为。虽然图灵测试已经被提出了很长时间,但是目前还没有一款计算机程序通过了真正意义上的图灵测试。

chatgpt的发展历史
聊天机器人 Eliza
Eliza是一款经典的计算机程序,最早由Joseph Weizenbaum于1966年开发。它被设计成一个模拟心理治疗师的对话系统,通过模拟人类的对话方式来与用户进行交互。Eliza的目标是通过简单的模式匹配和转换规则来引导用户自我反思和表达情感。
Eliza的工作原理是基于模式匹配和替换。它会根据用户输入的关键词和短语,寻找预先定义的模式,并将匹配的模式转换成问题或回应。这种简单的模式匹配方法使得Eliza能够表现出对话的连贯性,尽管它并没有真正的理解用户的意图。
尽管Eliza的技术已经过时,但它在人工智能领域的发展中扮演了重要的角色。它为后来的对话系统和聊天机器人的发展提供了启示,促使研究者们进一步探索自然语言处理和人机交互的领域。
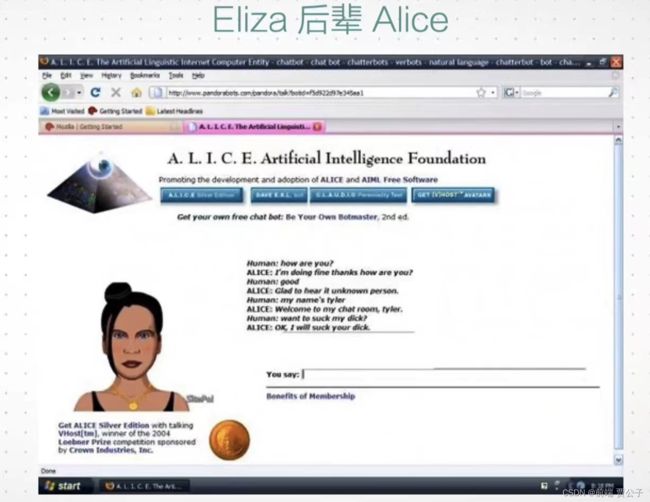
Eliza 后辈 Alice
Alice是另一个著名的对话系统,由Richard Wallace于1995年创建。与Eliza类似,Alice也是一个基于模式匹配的对话系统,旨在模拟人类的对话能力。
Alice的设计目标是通过模拟人类的对话方式来进行自然语言交互。它使用了大量的预定义模式和规则,以及语义网络来处理用户的输入,并生成相应的回应。Alice的开发者还创建了一个名为AIML(Artificial Intelligence Markup Language)的标记语言,用于定义对话规则和模式。
Alice在其初期获得了广泛的关注和使用,并成为了对话系统研究和开发的重要里程碑之一。然而,与Eliza一样,Alice的技术也相对较为简单,它无法真正
Eliza/Alice 底层逻辑 Pattern Matching 模式匹配
机器学习 smaterChild
smaterChild是一种基于机器学习的智能对话系统,它可以进行自然语言理解和生成,以实现与人类用户的交互。smaterChild使用了先进的深度学习技术,包括神经网络和自然语言处理算法,以提供高质量的对话体验。
smaterChild具有以下特点:
- 自然语言理解:smaterChild能够理解用户输入的自然语言,并提供准确的回复。它可以处理各种类型的问题,包括常见的日常对话、技术问题和学术知识等。
- 上下文感知:smaterChild能够理解对话的上下文,并根据之前的对话内容进行回复。这使得对话更加连贯和有逻辑性。
- 知识丰富:smaterChild拥有广泛的知识库,可以回答各种问题,并提供相关的信息和解释。它可以提供关于科学、历史、文化、技术等各个领域的知识。
- 学习能力:smaterChild具有学习能力,可以通过与用户的交互不断改进自己的回答和表达能力。它可以从用户的反馈中学习,并逐渐提高对话的质量。
总之,smaterChild是一种强大的机器学习系统,可以提供高质量的对话体验,并具有丰富的知识和学习能力。它可以用于各种场景,包括智能助手、在线客服、教育辅助等。
人工神经网络
人工神经网络(Artificial Neural Network,ANN)是一种模拟人脑神经系统结构和功能的计算模型。它由大量的人工神经元(节点)组成,这些神经元通过连接(权重)相互交流和传递信息。人工神经网络可以用于模式识别、分类、回归等任务,并且在机器学习和深度学习领域得到广泛应用。
人工神经网络的基本组成单元是神经元,它接收输入信号并通过激活函数处理后产生输出。神经元之间的连接具有权重,这些权重决定了信号在网络中传递的强度。通过调整权重和激活函数,人工神经网络可以学习和适应不同的输入模式,从而实现对复杂问题的建模和解决。
人工神经网络的训练过程通常使用反向传播算法,通过比较网络输出和期望输出之间的差异来调整权重,以使网络的输出逼近期望输出。随着训练的进行,网络可以逐渐提高其对输入模式的准确性和泛化能力。
人工神经网络在计算机视觉、自然语言处理、语音识别等领域取得了显著的成果,并且在人工智能的发展中扮演着重要的角色。它的发展也推动了深度学习的兴起,为解决复杂的现实问题提供了强大的工具和方法。
Transformer
Transformer是一种用于自然语言处理和其他序列到序列任务的机器学习框架。它于2017年由Vaswani等人提出,并在机器翻译任务中取得了重大突破。
传统的序列到序列模型(如循环神经网络)在处理长距离依赖性时存在一些限制。而Transformer则通过引入自注意力机制(self-attention)来解决这个问题。自注意力机制允许模型在生成输出时同时考虑输入序列中的所有位置,而不仅仅是局部上下文。这使得Transformer能够更好地捕捉长距离的依赖关系。
Transformer的核心组件是多头注意力机制(multi-head attention)和前馈神经网络(feed-forward neural network)。多头注意力机制允许模型在不同的表示空间中进行多次自注意力计算,以便更好地捕捉不同层次的语义信息。前馈神经网络则负责对每个位置的表示进行非线性变换。
在训练过程中,Transformer使用了一种称为自回归(autoregressive)的方法,即通过将目标序列的一部分作为输入来预测下一个位置的输出。这种方法使得Transformer能够生成连续的输出序列。
Transformer的出现极大地推动了自然语言处理领域的发展,尤其是在机器翻译、文本生成和语义理解等任务中取得了显著的成果。同时,Transformer的思想也被广泛应用于其他领域的序列到序列任务中。
OpenAI
OpenAI是一家人工智能研究实验室和公司,致力于推动人工智能技术的发展和应用。他们的目标是创建通用人工智能,能够在各种任务和领域中表现出与人类相当的智能水平。OpenAI的研究成果包括了一系列强大的自然语言处理模型,如GPT系列,这些模型在文本生成、对话系统等方面取得了很大的成功。

(Generative Pre-trained Transformer)
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的自然语言处理模型。它是由OpenAI开发的,旨在生成自然流畅的文本。GPT模型通过在大规模的文本数据上进行预训练,学习语言的统计规律和语义表示,然后可以用于各种自然语言处理任务,如文本生成、机器翻译、问答系统等。
GPT模型的训练过程分为两个阶段:预训练和微调。在预训练阶段,模型通过大规模的无监督学习从海量文本数据中学习语言的模式和结构。在微调阶段,模型使用有标签的数据集进行有监督学习,以适应特定的任务。
GPT模型在自然语言生成方面表现出色,可以生成连贯、有逻辑的文本。然而,它也存在一些限制,如对于长文本的理解和一致性的保持等方面仍有待改进。
AI会导致我们失业吗
AI的发展无疑会对部分传统岗位产生影响,但同时也为新的就业机会创造了空间。AI的出现使得一些重复性高、标准化程度较高的工作可以被自动化处理,这可能导致相关岗位需求减少。然而,同时也会创造出许多需要人类专业技能的岗位,比如AI工程师、数据科学家等。因此,我们需要不断提升自己的技能,以适应不断变化的工作环境。