python爬虫思路——动态网站
前面讲了怎么爬静态网站:python爬虫思路——静态网站
在了解静态网站爬虫的基础上来学动态网站的爬取(虽然我个人感觉没什么太大的关系),今天以爬取微博评论为例。
一、步骤
1. 既然要爬取动态网站,那么应该先判断该网站是不是动态网站。首先我们打开浏览器的设置——>然后搜索找到JavaScript——>将允许关掉,禁用JavaScript。
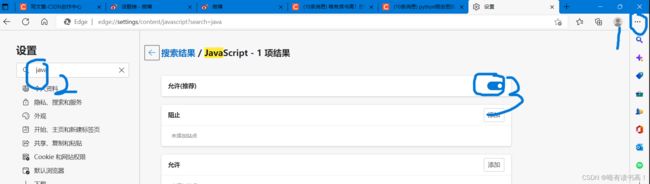
如果禁用JavaScript后,出现网页不能忘完全加载内容了,或者不能进行翻页滑轮下滑等情况,那么该网页绝大部分是动态网页(还有一种是伪动态网页,这个改天我再写另一篇爬取方法)
2. 把JavaScript打开,不然无法加载数据就没法爬取。首先找到你要爬取的网页——>跟之前爬静态网站一样打开开发者工具,然后找到网络那一栏,也就是之前找cookie的步骤——>一般存储动态网页的内容数据为XHP、JS或doc格式的文件,一个个找,先找XHP文件——>将微博评论下滑,加载更多评论,看右边的XHP文件,发现多了两个文件——>那么我们需要的评论数据就在这量个文件里,如果没有就是另外两种格式的文件。
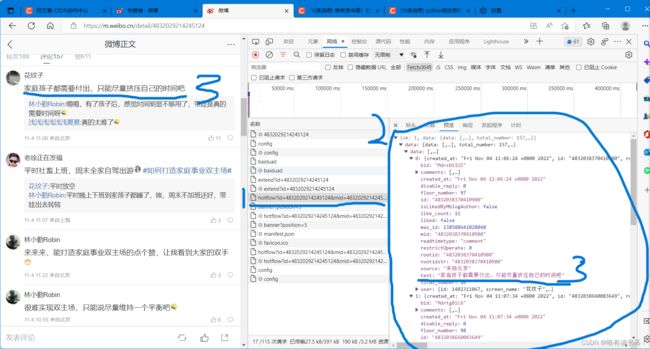
3. 我们选择第一个文件名与更新文件一样的文件,看看里面有没有我们要的数据。点击该文件,在右侧点击预览——>我们发现该文件是和json类型的数据,那么我们需要将该类型的数据像洋葱一样一层层拨开——>如图,当我们发现文字后和原评论对比,发现就是该评论——>这只是一级评论,当你再拨开一层,你会发现二级评论在comments里。
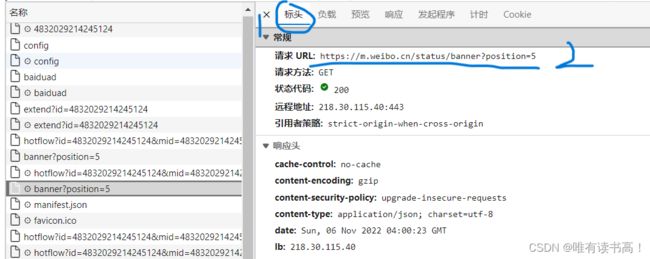
4. 到了这里我们已经找到我们要的数据在哪里了,那么接下来需要对这个文件进行爬取,然后在进一步解析出里面的评论。首先我们点击标头——>在标头里找到请求URL,那就是我们要爬取的链接——>将其复制到代码里,别忘了把cookie和浏览器的user-agent(如果这个文件没有就换下面几个文件,都一样的)。
5. 同样用request的方法将文件爬取下来在进行解析,爬下来的数据是字符串形式,需要转成json格式方便解析。首先爬取文件——>导入json库,将爬取结果转为json数据——>使用字典的键值对一层层查找评论数据——>加入保护机制,因为不能确定每个链接同一层都有同样的键,如果查找不到该键就返回空字典,避免程序直接报错终止运行——>找存放数据的列表,通过循环的方式将里面的每条评论爬取——>导入re库,用正则表达式过滤数据,因为爬下来的数据有的可能含有表情或者转义成的标签乱码等。
import json
import re
import requests
headers = {
'user_agent': '浏览器的.....',
'cookie': '自己的cookie'
}
url = 'https://m.weibo.cn/comments/hotflow?id=4832029214245124&mid=4832029214245124&max_id_type=0'
txt = requests.get(url, headers=headers)
jsn = json.loads(txt.text)
# 获取数据
data = jsn['data'] if 'data' in jsn else {} #保护程序,如果找不到就返回一个空字典
# 得到存数据的列表
items = data['data'] if 'data' in data else {}
# 得到max_id
max_id = data['max_id'] if 'max_id' in data else None
with open('pl.txt', 'a', encoding='utf-8') as file: # 在文件里续写
for item in items: # 遍历列表每个评论
texts = item['text'] if 'text' in item else None # 找到评论文本
texts = re.sub('\<.*\>', ' ', texts) # 去除一些标签转译成的符号
file.write(texts + '\n')运行结果如下

6. 如今完了一部分的评论爬取,要继续爬取下滑加载的评论,就需要找到两个文件链接之间的规律。对于网页来说,如果出现了(?),那么说明网页的路径已经完了,(?)后的一长窜都是参数,&是参数之间的分隔符,意为and。——>为了方便观察,我们把某些参数删除后在去浏览器查找这个网页,如果还能显示是原文件,那么这个参数不重要,删掉(建议用二分法删比较快)
下面我们把问号前面的网页删掉,反正是一样的,为了方便比对参数的不同:
#?id=4832029214245124&mid=4832029214245124&max_id_type=0
#?id=4832029214245124&mid=4832029214245124&max_id=138313761601884&max_id_type=0我们发现,两个链接参数唯一不同的参数是max_id,那么我们应该在刚刚解析文件找评论的同时,还应该找这个max_id的值——>然后在代码的链接变量url的外面建立循环,将url改为字符串拼接的方式:变化参数位置前的内容+变化的参数+变化参数位置后面的内容 (一般来说,像上面那个链接没显示max_id的值时,一般为0或者1)
加入try是为了保护程序,因为可能出现该链接不存在的情况,这样就会报错程序终止。
while max_id != None:
try:
time.sleep(5) # 爬虫延时
url = 'https://m.weibo.cn/comments/hotflow?mid=4832029214245124&max_id=+ str(max_id)
txt = requests.get(url, headers=headers)
jsn = json.loads(txt.text)
data = jsn['data'] if 'data' in jsn else {} # 获取数据
items = data['data'] if 'data' in data else {} # 得到存数据的列表
max_id = data['max_id'] if 'max_id' in data else None # 得到max_id
# 判断是否爬取完,因为最后一次爬的评论的max_id=0,判断循环结束的条件是max_id=None,所以改一下
if max_id == 0:
max_id = None
with open('pl.txt', 'a', encoding='utf-8') as file: # 在文件里续写
for item in items: # 遍历列表每个评论
texts = item['text'] if 'text' in item else None # 找到评论文本
texts = re.sub('\<.*\>', ' ', texts) # 去除一些标签转译成的符号
file.write(texts + '\n')
num += 1
if num % 10 == 0:
print('爬了{}条评论'.format(num))
except: max_id = None如果需要进一步的爬取二级评论可以用同样的方法做对应的的数据解析,
如果通过热搜榜爬取评论,那么就需要寻找从热搜榜到该微博之间各个网页的链接之间的关系,是个比较费眼睛的工作。
如果还不明白的小伙伴可以去B站搜索左素爬虫,这个博主的非常详细,课堂氛围也很不错,我就是在这学的。