【node.js】 node学习笔记
目录
一.node的特点
二.node在实际项目中的应用
三.node的架构
node中如何实现异步IO?
node事件驱动架构?
四.node全局对象及全局变量
1.全局变量process
2.setImmediate
3.process.nextTick
四.模块管理机制
3.1 模块化原理解析
3.2 require方法加载规则
四.fs内置模块
五.path内置模块
六.url内置模块
七.http内置模块
八.node事件循环
node中的宏任务和微任务
node事件循环完整过程
不同node版本宏任务和微任务的执行差异
setTimeout和setImmediate的执行顺序
九.Express基本使用
1.基本服务器搭建
2.中间件的使用
3.路由
一.node的特点
1.基于V8引擎(webkit内核)渲染和解析JS(类似的还有webview和谷歌浏览器等),它不是后台语言,它是一个工具或环境,用来解析js的工具或者环境。我们一般会把node安装在服务器上,在服务器上写一些js代码,实现服务端的一些功能。基于命令node xxx.js把js代码运行在node环境下
2. 单线程异步非阻塞的I/O操作
JS在客户端浏览器中运行,是否可以对客户端本地的文件进行读写操作?
不能,要保证客户端的信息安全。input:type="file" 文件上传表单除外,但这种也需要用户手动进行选择才可以。
JS在服务器运行能否对服务端的文件进行操作?
可以,node赋予js进行I/O读写的能力(内置模块FS)
3.window 和 global
1)在客户端浏览器中运行的js,js的全局对象是window,它提供了很多内置的属性和方法
2)在node中运行js,js全局对象是global, 也包括许多内置的属性
1.proceess:node中做进程管理的属性,常用有
- process.nextTick()
- process.env
2.Buffer:数据格式管理的;
3.setImmediate 立刻执行(类似于setTimeout(fun,0))
注意:在REPL命令中输出this是global,但在xxx.js中输出的this是当前模块本身。
4.不适合处理CPU密集型的任务
nodejs是单线程的,如果遇到涉及到较大计算量的cpu密集型的任务,其后面的代码是不会执行的。但配合异步IO和事件循环是可以处理一些高并发的请求的。
let http = require('http');
function sleepTime (time) {
const sleep = Date.now() + time * 1000;
while(Date.now() < sleep) {}
return;
}
sleepTime(4); // 这就是一个cpu密集型的任务,占用主线程
const server = http.createServer((req,res) => {
res.end('server starting');
});
server.listen(8080,() => {
console.log('start on 8080......');
})二.node在实际项目中的应用
1)webpack是基于node环境运行的
2)npm是安装了node后自带的模块管理工具,基于它可以安装和卸载对应的模块
3)基于node.js实现服务器的功能操作
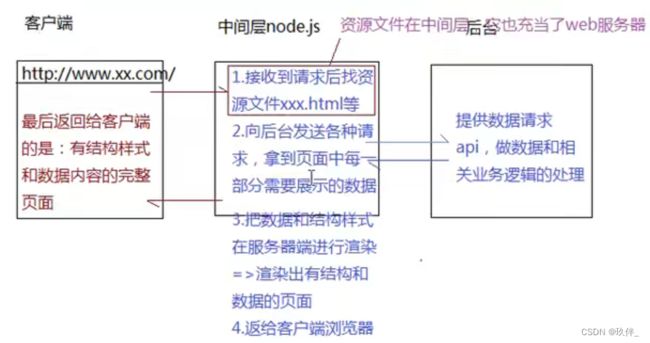
项目架构1:基于node.js架构全栈项目(一般用于中小型项目)

项目架构2:基于node.js构建中间层
特点:单线程异步,无阻塞I/O,事件驱动。node.js作为服务层,抗压和抗并发的能力不错

这种方式,可以基于node.js实现跨域访问,客户端和中间层在一个域下(同源),基于中间层从第三方服务器上获取数据(node.js可以跨域获取数据)
另外,当客户端和服务器同时进行开发的时候,需要两端协商接口规范(API文档),然后由服务端先开发出一个伪接口,有时这个伪接口就是基于node.js开发的一套数据mock的后台,在项目联调的时候,再把接口切换到真实的后台上。
项目架构3:基于node.js实现服务器渲染
客户端数据绑定后在源代码中看不到绑定的内容,不利于SEO优化。所以有些产品需要放弃客户端渲染,改为服务器渲染,这个渲染操作就由node处理。
三.node的架构
nodejs的核心是由三层组成。最上层Native modules是内置核心模块,里面暴露了js的内置功能模块接口;中间层Bindings是在使用对应模块时调用对应模块的c++函数的,且需要V8引擎配合完成;最下层包括许多模块,其中V8引擎用于构建js代码的运行环境,负责js代码的执行,js和底层c++代码的转换;libuv库用于处理node的事件循环,事件队列,异步IO;除此之外还有其他若干模块对应不同的功能。

node中如何实现异步IO?
对于IO分为阻塞和非阻塞两种类型,对于非阻塞的IO,CPU的时间片可以处理其他的事务,从而提升性能,但立即返回的不是最终需要的数据,而是调用的状态,操作系统为了得到最终的数据,会使用轮询让应用程序重复调用IO操作,从而确认IO操作是否已经完成,一旦完成就将最终的数据返回,但此时程序依旧等待IO的结果,依旧是阻塞的。在node中使用libuv库,在IO操作调用发起后直接进行下一个操作的处理,等待IO的结果处理完后,通知js主线程通过回调的方式将结果传递给当前代码。 nodejs单线程配合事件驱动架构及libuv实现异步IO。
node事件驱动架构?
类似消息订阅发布模式,发布者广播消息,订阅者接受消息。

当libuv库接收到了异步IO操作时,事件多路分解器找到当前平台环境下可用的IO处理接口,等待IO操作结束后通过对应的事件添加到事件队列中,随后按照顺序从事件队列中取出事件交给主线程执行。在接收到IO操作时,会发布某个事件,事件的订阅者在IO操作结果返回后执行在订阅时的处理程序,获取结果。
node事件驱动简单代码实现:
let eventEmitter = require('events');
const myEvent = new eventEmitter();
// 绑定事件event1,订阅者
myEvent.on('event1',() => {
console.log('event1执行了');
});
// 触发事件event1,发布者
myEvent.emit('event');四.node全局对象及全局变量
node中提供关键字global表示全局对象,其上挂载了许多属性和方法。
node中this和global的关系
在node中默认this是空对象,直接判断this和global的关系两者不相等,但在自调用函数中判断两者是相等的。因为在node中每一个文件都是一个独立的模块,每一个模块在执行的时候最外层都被包裹了一个自调用的函数,node会为该函数传递一些固定的参数,例如:__filename,require,__dirname,exports等,包括this;
console.log(this); // {}
console.log(this === global); // false
(function () {
console.log(this === global); // true
})()1.全局变量process
作用:获取当前正在执行脚本的信息,对当前进程进行一些操作等
1)process.memoryUsage():查看当前脚本内存使用信息
console.log(process.memoryUsage());输出对象如下:

2)process.cpuUsage():获取当前cpu的信息
console.log(process.cpuUsage());获取的是用户和操作系统占用的当前CPU的时间片段
![]()
3)process.cwd():获取当前项目的运行目录
![]()
4)process.version:获取当前node版本
![]()
5)process.versions:获取当前node版本的详细信息,比如V8的版本,libuv版本等

6)process.arch:获取当前系统cpu架构,32位或64位
![]()
7)process.env:获取当前用户环境的信息,有几个常用属性如下
process.env.NODE_ENV:常用于如vue脚手架中,用于区分当前是生产环境还是开发环境,默认是undefined,通常在配置脚手架时设置,设置dev/production;
process.env.PATH:获取当前本机的系统环境变量,例如:C:\Program Files (x86)\Common Files\Intel\Shared Libraries\redist\intel64\compiler;C:\windows\system32;...
process.env.USERPROFILE:获取用户管理员目录,windows系统下,MAC系统下为HOME,输出例如:
8)process.platform:获取当前系统平台
![]()
9)process.argv:返回数组,内容分别是当前node启动的脚本程序路径和当前文件路径

从数组第三项开始是输入命令时传入的参数,可以通过process.argv0直接获取当前数组的第一个元素
![]()
10)process.pid:获取当前脚本执行时在操作系统内的pid
![]()
11)process.uptime():获取前脚本的运行时间
![]()
12)关于事件监听
使用process.on()绑定事件 ,在脚本执行完触发exit事件,其内部不能执行异步代码,但在事件beforeExit回调中可以执行异步代码
process.on('exit',(code) => {
console.log('exit的状态码是:',code);
});
process.on('beforeExit',(code) => {
console.log('beforeExit的状态码是:',code);
});
console.log('代码执行完了');控制输出如下:

13)process.exit():让程序主动退出,不会触发beforeExit事件,其后的代码不会执行;
14)process.stdout.write():标准输出,可以在终端面板中输出内容,可写流
console.log = function (data) {
process.stdout.write('---' + data + '\n');
}
console.log('hello');此时再执行console.log方法控制台就会按照指定格式输出
![]()
除此之外还可以读取文件
let fs = require('fs');
fs.createReadStream('test.txt').pipe(process.stdout);15)process.stdin:标准的输入,可以获取在终端面板中的输入内容。
process.stdin.pipe(process.stdout);上述代码可以实现在终端面板中打印输入的内容;
2.setImmediate
表示立即执行,是宏任务,回调函数会放置在事件循环的check阶段。
如果应用中存在大量的计算任务,它是不适合在主线程中执行的,计算任务会阻塞主线程,所以这种任务最好交给由c++维护的线程执行。可以通过setImmediate方法将任务放入事件循环的check阶段,因为代码在这个阶段不会阻塞主线程,也不会阻塞事件循环。
示例:
function sleep (delay) {
let start = new Date().getTime();
while(new Date().getTime() - start < delay) {
continue;
}
console.log('sleep');
}
console.log('start');
setImmediate(sleep,2000);
console.log('end')输出结果如下:

3.process.nextTick
该方法属于微任务,但其优先级高于普通的微任务,在事件循环之前被调用。如果希望某代码执行不阻塞主线程,且希望该方法尽早的执行,可以对该方法使用process.nextTick;
示例:对于下列方法readFile可能通过同步的方式返回方法,也可能通过异步方式返回结果,这会导致不可预测的事情发生,所以期望该方法始终以异步的方式返回结果。
let fs = require('fs');
function readFile (filename,callback) {
if(typeof filename!== 'string') {
return callback(new TypeError('文件名必须是字符串'));
}
fs.readFile(filename,function (err,result) {
if(err) return callback(err)
return callback(null,data);
})
}可以使用process.nextTick方法使同步返回代码 return callback(new TypeError('文件名必须是字符串')); 成为异步代码,如下所示:
let fs = require('fs');
function readFile (filename,callback) {
if(typeof filename!== 'string') {
return process.nextTick(callback,new TypeError('文件名必须是字符串'));
}
fs.readFile(filename,function (err,result) {
if(err) return callback(err)
return callback(null,data);
})
}这样在进入事件循环之前,使用process.nextTick包裹的同步代码就会执行
四.模块管理机制
js中常用的模块管理机制有AMD(代表有require.js),CMD(代表有sea.js),CommonJS(代表有node.js)ES6Module;
以上这些模块化思想,规定了在js中我们的模块该如何创建,如何导入以及如何导出,node是基于CommonJS模块化管理思想
node中的模块
1)内置模块:node中自带的模块
http/https:创建和管理服务的模块
fs:给js进行I/O操作的模块
url:解析URL地址的模块
path:管理路径的模块
2)第三方模块:基于npm安装,别人写好供我们时候的
mime qs(将对象与x-www-form-urlencode进行转换的) express(服务器框架) express-seession body-parser(进行post请求传送处理的)
3)自定义模块:自己写的模块
在node中,我们每创建一个js,都相当于创建了一个新的模块,模块中的方法也都是模块中的私有方法,不同模块之间的同名方法不会有冲突。
node中提供了一个对象module,里面的exports方法就是用来导出模块中方法,例如:
在同一个目录下有A.js和B.js两个模块在A中暴露一个方法func供B使用
// A.js
function func() {
console.log('A');
}
module.exports = {
// 里面的属性和方法就是需要暴露给外面调取使用的
func;
}require是node中提供用来导入模块中的方法,语法:let 模块名 = require([模块的地址])
// B.js
let A = require('./A');
A.func(); // A
require导入模块是同步的,没导入完成后面的代码无法执行,每一次导入模块都是把导入的模块的js代码从上到下执行一遍。
3.1 模块化原理解析
每次导出接口成员的时候通过module.exports.xxx = xxx的方式比较麻烦,所以node为了简化操作,专门提供了一个变量exports,使 var exports = module.exports , 即exports是module.exports的一个引用。
在每个模块最后都会隐式存在 return module.exports , 所以在其他模块中调用require方法就会获得返回的module.exports这个对象。
console.log(exports === module.exports); // true
// 下面两者等价
exports.foo = 'aaa';
module.exports.foo = 'aaa';需要注意的是,当一个模块需要导出单个成员的时候,直接给exports赋值是不管用的。
exports.a = 111;
exports = {}; // 这样直接赋值改变了exports的指向,使其指向了一个新的对象,后续的代码就不会生效了
exports.foo = 'aaa'; // 相当于给上述新对象添加了一个属性foo,而不是module.exports3.2 require方法加载规则
优先从缓存中加载,先查看需要加载的模块是否已经加载过,加载过的模块直接中缓存中获取,随后加载自己创建的模块(路径前会有/或./或../),随后找第三方模块(安装在自己本地的),如果没有安装,则找node中的内置模块,如果没有,则报错;
1)自己调用的模块:则需要加上/(根目录)./(当前目录)../(上级目录)这三个中的某一个,可以省略.js后缀名,其中/(根目录)的方式几乎不同,首位的/表示的是当前文件模块所属磁盘的根目,例如:require('./index.js');
2)node内置模块:其本质也是文件,核心模块文件已经被编译到了二进制文件中,我们只需要按照名字加载就可以了,例如:require('fs');
3)第三方模块:凡是第三方模块都需要通过npm来下载,通过require('包名')的方式进行加载才能使用,例如加载require('art-temmplate'),需要经历的加载过程如下:
先找到当前文件所处目录中的node_modules目录;
再去查找node_modules目录中的art-temmplate目录;
再去查找node_modules/art-temmplate/package.json文件;
再去查找package.json文件中的main属性,main属性中记录了当前art-temmplate入口模块;
然后加载使用这个第三方包(入口模块一般是index.js),实际最终加载的还是文件;
如果package.json文件不存在或者mian指定的入口文件不存在,则node会自动找该目录下的index.js,也就是说index.js会作为一个默认备选项;
如果以上所有任何一个条件都不成立,则会进入上一级目录中的node_modules目录中查找,如果上一级还没有,则继续向上上级查找,直到当前磁盘根目录还找不到,则会报错(can't find module xxx);
一般项目中有且只有一个node_modules,放在项目的根目录中,这样的话该项目中的所有子目录中的代码都可以加载到第三方包。
四.fs内置模块
提供了大量的属性和方法,让js在node环境中执行的时候,可以操作服务器上的资源文件,也就是赋予了I/O操作的能力
常用方法:
1)readdir/readdirSync:异步或同步读取指定目录(相对/绝对目录都可以)下的文件
readdirSync:同步读取文件
let fs = require('fs');
// 读取当前目录下的文件
let result = fs.readdirSync('./');
console.log(result);目录结构如下:

输出结果如下: 结果是一个数组,元素是指定的文件名

readdir:异步读取文件,读取成功后出发回调函数执行
回调函数参数err存储读取失败后的错误信息;result存储的是读取成功后的结果(此时err=null)
fs.readdir('./',(err,result) => {
if(err === null) {
console.log(err,result);
}
})2)readFile/readFileSnyc:异步或者同步读取某一个文件中的内容。不设置编码格式,默认得到的是buffer文件流(编码格式)的数据,设置UTF8,得到的是字符串;但对于富媒体资源,例如:图片,音频,读取和传输的过程就是基于buffer文件流格式操作的,所以不要设置UTF8。
fs.readFileSnyc([path],[encoding])
// 同步读取文件操作
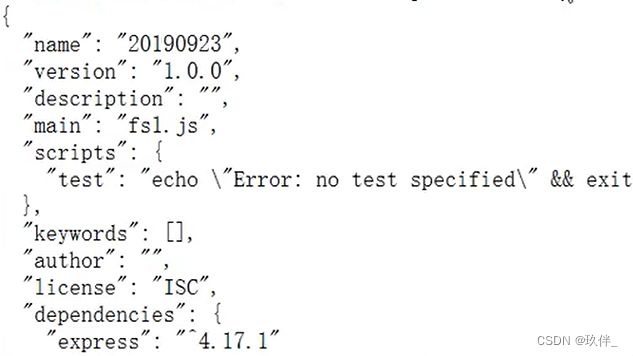
let result = fs.readFileSnyc('./package.json','utf8');
console.log(result);读取到的内容如下
fs.readFile([path],[encoding],[callback])
// 异步读取文件操作
fs.readFile('./package.json','uft8',(err,result) => {
if(err !== null ) return;
consol.log(result);
})3)writeFile/writeFileSync:向某个文件中同步/异步写入内容。如果文件不存在,默认创建一个文件再写入,而且写入的方式是覆盖写入。
fs.writeFileSync([path],[string/buffer content],[encoding]):覆盖写入,该方法没有返回值
let result = fs.writeFileSync('./AA.txt','hello','utf8');fs.appendFile([path],[string/buffer content],[encoding]):追加式写入
let result = fs.appendFile('./AA.txt','hello123','utf8',err => {
console.log(err);
});fs.appendFile([path],[string/buffer content],[encoding],[callback]):异步操作可以监听文件写入操作的成功或失败
let result = fs.writeFile('./AA.txt','hello','utf8',err => {
console.log(err);
})注意:写入的文件可以不存在,但是必须要保证路径的正确性,否则异步的方式会报错,同步代码需要使用try...catch捕获错误信息;
let err = null;
try {
fs.writeFileSync('./未知的路径/a.txt','nihao','utf8');
} catch(error) {
err = error;
}
if(err !== null) {
console.log('报错');
}4)copyFile([’需要拷贝的文件‘],['拷贝到的目标文件'],[callback]):把某个文件及里面的内容拷贝到新的目录中
// 将文件A.txt拷贝到B.txt中
fs.copyFile('./A.txt','./B.txt',err => {
console.log(err);
})5)mkdir([path],[callback]):创建目录
fs.mkdir('./js',err => {
console.log(err);
})6)rmdir([path],[callback]):删除目录,一定要保证目录中不存在文件,否则不让删除。
fs.rmdir('./js',err => {
console.log(err);
})7)unlink(['文件的地址'],[callback])
fs.unlink('./js/A.txt',err => { console.log(err) })真实项目开发中更多的使用的是异步的方式操作文件;
示例1:基于Promise封装readFile
let fs = require('fs');
let path = require('path');
let exportObj = {};
// 根据后缀名返回编码格式utf8/null
function suffixHandle(pathname) {
let suffixREG = /\.([a-zA-Z0-9]+)$/,
suffix = suffixREG.test(pathname) ? suffixREG.exec(pathname)[1] : '', // 在捕获之前判断是否能够匹配\
encoding = 'utf8';
/^(PNG | GIF | JPG | JPEG | WEBP | BMP | ICO | SVG | MP3 | MP4 | WAV | OGG | M3U8)$/i.test(suffix)
? encoding = null : null;
return encoding;
}
['readFile','readdir','mkdir','rmdir','unlink'].forEach(item => {
exportObj[item] = function anonmous (pathname) {
pathname = path.resolve(pathname);
return new Promise((resolve,reject) => {
let encoding = suffixHandle(pathname);
let callback = (err,result) => {
if(err !== null) {
reject(err);
return;
}
resolve(result);
}
if(item !== 'readFile') {
encoding = callback;
callback = null;
}
// 调用fs内置方法
fs[item](pathname,encoding,callback);
})
}
});
['writeFile','appendFile'].forEach(item => {
exportObj[item] = function anonmous (pathname,content) {
pathname = path.resolve(pathname);
return new Promise((resolve,reject) => {
let encoding = suffixHandle(pathname);
content !== null && typeof content === 'Object' ?
content = JSON.stringify(content) : null;
typeof content !== 'string' ? content += '' : null;
let callback = (err,result) => {
if(err !== null) {
reject(err);
return;
}
resolve(result);
}
// 调用fs内置方法
fs[item](pathname,content,encoding,callback);
})
}
});
exportObj.copyFile = function anonmous (pathname1,pathname2) {
pathname1 = path.resolve(pathname1);
pathname2 = path.resolve(pathname2);
return new Promise((resolve,reject) => {
// 调用fs内置方法
fs['copyFile'](pathname1,pathname2,err => {
if(err !== null) {
reject(err);
return;
}
resolve();
});
});
};
module.exports = exportObj;
在index.js中调用readFile
let { readFile } = require('./utils/fsPromise');
readFile('./package.json')
.then(res => {
console.log(res);
})
.catch(err => {
console.log(err);
})注意1:关于 __dirname和__filename
在使用fs模块操作文件时,如果操作的路径是以./或../开头的相对路径,很容易出现路径动态拼接错误的问题。因为代码运行的时候,会以执行node命令时所处的目录,动态凭借出被操作文件的完整路径。
例如:需要读取一个文件其位于 D:\font_projects\node_learn\package.json,如果当前代码在D:\font_projects目录下执行的,需要读取的路径为 './package.json',路径拼接:D:\font_projects + ./package.json ==> 'D:\font_projects\package.json' , 从而导致路径出现问题。
解决这个问题,需要提供一个完整的文件存放路径,__dirname获取当前模块所在的绝对路径,即:D:\font_projects\node_learn,且用户调用的时候传递的pathname都以项目根目录为参照,因为执行代码都在根目录执行。
__filename用来获取当前模块的绝对路径,即:D:\font_projects\node_learn\package.json
五.path内置模块
path模块是用来处理路径的模块
1)path.join([...paths]):用来将多个路径片段拼接成一个完整的路径字符串,可以传递多个路径片段。../会抵消前面的路径。
let path = require('path');
let pathStr = path.join('/a','/b/c','../','./d','e');
console.log(pathStr); // \a\b\d\e一般使用join方法对__dirname进行路径的拼接,尽量不要使用“+”进行拼接,join方法可以对路径中多余的'.'进行屏蔽
let path = require('path');
let fs = require('fs');
fs.readFile(path.join(__dirname,'1.txt'),'utf8',(err,result) => {
if(err) {
console.log(err);
return;
}
console.log(result);
});2)path.basename([path][,ext]):可以获取路径中的文件名,如果只需要拿到文件的名称不需要获取文件的扩展名,可以传递第二个参数,指定要去除的文件扩展名。
let path = require('path');
const fpath = '/a/c/v/index.js';
const fullname = path.basename(fpath);
console.log(fullname); // index.js
const name = path.basename(fpath,'js');
console.log(name); // index3)path.extname:获取路径中的文件扩展名
const path = require('path');
const ext = path.extname('/a/b/c/index.js');
console.log(ext); // .js4)path.resolve([path]):获取当前node执行时所在的绝对目录,如果传递了一个相对目录,也是以获取的绝对目录为依托,再去查找对应的目录
例如:当前node在D:\font_projects\node_learn目录下执行,调用console.log(path.resolve())获取的就是D:\font_projects\node_learn,如果传递的参数console.log(path.resolve('../package.json')),那么输出的路径就是D:\font_projects\package.json
六.url内置模块
1)url.parse([url],):用来解析URL中每一个部分的信息.第二个参数传true,自动会把问号参数解析成键值对的方式,存储在query属性中。
let url = require('url');
let address = 'https://www.msn.cn/zh-cn/weather/forecast/in-%E4%B8%?loc=eyJsb=hourly&day=1';
console.log(url.parse(address));
// console.log(url.parse(address,true));url解析的输出结果如下,其中有两个比较常用的属性:
query:问号传递参数的键值对;pathname:请求路径的名称

第二个参数传递true时的输出结果:

七.http内置模块
服务器要做的常规任务
1.需要一个服务,创建服务:IIS/NGINX/APPACHE/NODE[HTTP/
HTTPS内置模块],需要提供监听的端口号(0-65535)
2.接收客户端的请求信息(包括资源文件的和请求数据的)
3.查找到对应的资源文件内容或者对应的数据信息、
4.把找到的内容返回客户端
1)http.createServer([callback(req,res)]):用于创建服务,当客户端向服务器发送请求的时候会触发回调函数callback,每一次都会后去本次请求的相关信息。其中req对象中存储了客户端请求的相关信息,res对象中提供了对应的属性和方法,可以让服务器返回客户端的信息。
req对象中的参数:
req.url:存储的是请求信息中的资源文件的路径名称和问号传参信息,例如:路径为localhost:8000/index.html?name=qwe,则获取到的是/index.html?name=qwe;
req.method:客户端请求的方式;
req.headers:客户端请求头信息;
res.write([content]):服务器返回信息,可以执行多次,返回的数据格式一般都是字符串或buffer。
res.end([content]):告诉客户端返回的内容已经结束了,必须要写,参数content是向客户端返回内容(可选),它相当于基于响应主体返回信息;
res.writeHead([状态码,[options]):基于响应头返回信息,在options对象中传递响应头,其作用是告诉客户端返回的数据格式和编码格式,返回的格式类型是MIME类型(每一种文件都有一个自己所属的类型,而这个类型就是MIME类型),常见的MIME类型有:'text/plan','text/html','text/javascript
2)server.listen([post],[callback]):用于监听端口号。当服务创建成功并且端口号已经监听完成,触发回调callback。
示例1:使用原生node创建一个简单的服务器用于响应客户端的页面请求
需要获取客户端请求的路径,找到服务器中对应的html文件,使用之前封装的fs的方法读取html文件信息返回;
请求的路径中有后缀名的是web静态资源文件的请求,没有后缀名的一般都是数据接口;
还需要告诉客户端返回的数据格式和编码格式,需要根据客户端请求的文件后缀名在响应头中告诉客户端返回文件的MIME类型,可以使用插件MIME实现
let url = require('url');
let http = require('http');
let path = require('path');
let mime = require('mime');
let { readFile } = require('./utils/fsPromise')
// 创建http服务
let server = http.createServer((req, res) => {
let requestURL = req.url;
// 获取请求资源的路径名称和问号传参的信息
let { pathname, query } = url.parse(requestURL, true);
// 根据请求的路径名称在static文件中查找对应的资源文件和内容
pathname = path.resolve('./static') + pathname;
let suffixREG = /\.([A-Za-z0-9]+)$/;
let encodingREG = /^(PNG | GIF | JPG | JPEG | WEBP | BMP | ICO | SVG | MP3 | MP4 | WAV | OGG | M3U8)$/i;
let encoding = null;
// 请求的路径中有后缀名的是web静态资源文件的请求,没有后缀名的一般都是数据接口
let suffix = suffixREG.test(pathname) ? suffixREG.exec(pathname)[1] : null;
if (suffix !== null) {
!encodingREG.test(suffix) ? encoding = 'charset=utf8' : null;
// 请求的是静态资源文件,获取对应的MINE类型
suffix = mime.getType(suffix);
// 根据路径读取对应的文件返回客户端
readFile(pathname).then(result => {
res.writeHead(200, {
// 告诉客户端返回的数据格式和编码格式
'content-type': `${suffix};${encoding};`
})
res.end(result);
}).catch(err => {
res.writeHead(404, {
// 告诉客户端返回的数据格式和编码格式
'content-type': `application/json;charset=utf8;`
})
res.end(JSON.stringify(err));
});
return;
}
});
// 监听端口号(0 - 65535)
server.listen(8000, () => {
console.log('success,port 8000');
});使用node指令运行上述代码 ,随后在浏览器中输入指定路径效果如下:
![]()

八.node事件循环
在浏览器平台的事件循环存在两个队列,分别是宏任务和微任务队列,在node环境下依旧可以大致分为宏任务和微任务,但宏任务可以进一步细分为六个队列,同样每个队列内部会存放不同的回调函数。
node中的宏任务和微任务
node中异步队列也存在两种,宏任务和微任务队列
宏任务:setTimeout,setInterval,setImmediate,文件读写I/O操作
微任务:Promise,process.nexttick()
注意:微任务 process.nexttick() 执行优先级高于Promise.then()
node事件循环完整过程
1.执行同步代码,遇到异步任务则将不同的异步任务调到对应的队列中;
2.所有同步代码执行完后,会执行满足条件的微任务;
3.微任务执行完后,执行宏任务,其存在六个不同循环队列,会按照按照顺序timer -> poll -> close 执行宏任务,如下图所示:
当node.js启动时会初始化event loop,每一个event loop都会包含如下六个循环阶段

1)timers(定时器):此阶段执行那些由setTimeout()和setInterval()调度的回调函数,即执行定时器的回调函数;
2)I/O callbacks 或称 pending callbacks (I/O回调):此阶段会执行操作系统的回调函数,比如tcp udp,除了close callback和timers(定时器回调)与setImmediate()调度的回调;
3)idle(空转):此阶段只在系统内部调用
4)poll(轮询):执行的I/O回调函数,例如文件的读写,在恰当的时候node会阻塞在这个阶段;
5)check(检查):setImmediate()设置的回调会在此阶段执行。
6)close callbacks(关闭事件的回调):诸如 socket.on('close',...)此类回调会在此阶段调用
poll阶段遵循的规则:
如果event loop进入了poll阶段,且代码未设定了定时器,将会发生如下变化:
- 如果poll queue不为空,event loop将同步执行queue里的callback,直到queue为空,或执行的callback到达系统上限;
- 如果 poll queue为空,将会发生如下情况:
- 如果代码已经被setImmediate()设定了callback,event loop将结束poll阶段进入check阶段,并执行check阶段的queue(check阶段的queue是由setImmediate设定的)
- 如果代码没有设定setImmediate(callback),event loop将阻塞在该阶段等待callback加入poll queue,一旦到达立即执行。
如果event loop进入了poll阶段,且代码设定了定时器:
- 如果 poll queue 进入空状态时(即poll阶段为空闲状态),event loop将检查timers,如果有一个或多个timers时间已经到达,event loop将按循环进入timers阶段,并执行timer queue;
由上面的分析可知,首先执行timer队列中满足的宏任务;
4.timer中所有宏任务执行完后会依次切换队列(切换执行I/O callbacks中的回调),但在完成队列切换之前会清空微任务的代码;
5.按照如上顺序依次切换队列执行回调......
示例1:判断下列代码的输出顺序
setTimeout(() => { console.log('s1')})
Promise.resolve().then(() => { console.log('p1')});
console.log('start');
process.nextTick(() => { console.log('tick')});
setImmediate(() => { console.log('setImmediate')});
console.log('end');结果分析:
1)首先执行同步代码,并将异步回调放入对应的队列中,其中setTimeout回调s1放入宏任务队列的timer中,Promise的回调p1放入微任务队列中,执行同步代码输出‘start’,将nextTick的回调tick放入微任务队列中,将setImmediate回调setImmediate放入check队列中,最后执行同步代码输出'end';
2)同步代码执行完后查看微任务队列中的微任务,nextTick的执行优先级高于Promise,所以依次输出'tick','p1'
3)随后执行宏任务,切换队列到timer中,执行输出's1',切换事件队列到poll,由于队列poll为空,再次切换队列到check,执行输出'setImmediate';
终端输出结果:

不同node版本宏任务和微任务的执行差异
有如下代码
setTimeout(() => {
console.log('s1');
Promise.resolve().then(() => { console.log('p1')})
});
console.log('start');
setTimeout(() => {
console.log('s2');
Promise.resolve().then(() => { console.log('p2')});
process.nextTick(() => { console.log('t1') });
})
console.log('end');对于node10及以前版本:
先执行同步代码输出'start'和'end',同时将定时器回调s1和s2放入timer队列中;
执行timer队列中的s1回调,将微任务p1放入微任务队列中,但node10及以前队列的切换必须等当前队列中的回调全部执行完后再进行,所以会执行回调s2,将微任务t2和p3放入微任务队列中;
待到timer队列回调全部执行完后再切换到微任务队列中执行t1,p1,p2;
所以最终的执行顺序是:start -> end -> s1 -> s2 -> t1 -> p1 -> p2
对于node11及以后的版本:
先执行同步代码输出'start'和'end',同时将定时器回调s1和s2放入timer队列中;
执行timer队列中的s1回调,将微任务p1放入微任务队列中,发现此时存在微任务,则优先执行p1回调;(和浏览器执行时机一致)
随后再切换队列至timer,执行定时器s2的回调,将回调中的微任务p3和t2放入微任务队列中,随后切换队列执行微任务p3,t2;
最终的执行顺序是:start -> end -> s1 -> p1 -> s2 -> t1 -> p2
setTimeout和setImmediate的执行顺序
现有如下代码:
setTimeout(() => {
console.log('setTimeout')
},0);
setImmediate(() => {
console.log('setImmediate')
});观察终端输出结果:setTimeout和setImmediate的执行顺序是不确定的
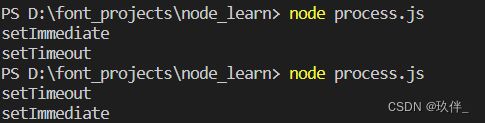
setTimeout在不传递第二个参数的情况下参数默认为0,但执行过程中可能会产生延时,此时setImmediate的回调会先进入异步队列check中,当node执行完同步代码后就会执行check队列中的该回调,待到延时结束再添加并执行timer队列中的setTimeout回调,从而输出结果为:setImmediate -> setTimeout
如果没有延时则setTimeout的回调直接添加到timer队列中,同步代码执行完执行异步回调时候按照队列 timer -> check的顺序执行,从而输出的结果为:setTimeout -> setImmediate
再看如下代码:此时两个定时器被readFile回调包裹
let fs = require('fs');
fs.readFile('./1.txt', () => {
setImmediate(() => {
console.log('setImmediate')
});
setTimeout(() => {
console.log('setTimeout')
});
})观察终端输出结果:setImmediate始终优先于setTimeout执行

分析:当同步代码执行完后,node会将满足条件的setTimeout和setImmediate回调依次放入timer和check队列中,但readFile的回调是放在poll队列中执行的,当readFile回调执行完后会切换队列,队列按照顺序向下切换到check队列,优先执行check队列中的setImmediate回调,随后再按照事件环的顺序执行timer中的setTimeout回调,因此setImmediate回调始终优先于setTimeout执行。
总结:
默认情况两者执行的先后顺序是不确定的;
但在I/O回调中setImmediate先执行而setTimeout后执行;
九.Express基本使用
1.基本服务器搭建
1)创建服务和监听端口
使用require引入express模块,执行express创建一个服务,返回的结果app用来操作这个服务;app.listen([port],[callback])用于创建服务监听端口;
let express = require('express');
let app = express();
app.listen(8080,() => {
console.log('service successfully at port 8080');
});2)搭建静态资源服务器
express.static([PATH]):到指定的目录中查找客户端需要的资源文件,并将其返回
app.use(express.static('./static'));上述案例中就将项目根目录下的static目录作为资源文件的路径,所有的静态资源请求都去这个文件夹中查找;
3)实现数据请求的api接口
REQUEST对象
req.path:存储请求地址的路径名称,底层通过url.parse()处理;
req.query:存储问号传参的相关消息,返回的是对象;
req.body:在配合body-parse中间件情况下,req.body存储的是请求主体传递过来的信息;
req.method:请求方式;
req.get:获取响应头信息;
......
RESPONSE对象:
res.end():类似于原生的操作,结束响应并返回内容;
res.json():返回给客户端内容,传递的数据是json对象,内部会转换;
res.send():最常用的给服务端返回信息,可以传递path、buffer、txt等,基于原生的send方法通过响应主体返回给客户端信息;
res.status([code]):返回状态码;
res.set():设置响应头信息res.set([KEY],[VALUE]) res.set({KEY:VALUE,......});
res.redirect([STATUS],[PATH]):请求重定向
res.type([content]):返回content-type的类型值;
......
示例1:创建一个静态资源服务器,设置静态资源目录static,并处理资源找不到时的处理方式(设置404状态码或请求重定向);
let express = require('express');
let app = express();
app.listen(8080,() => {
console.log('service successfully at port 8080');
});
app.use(express.static('./static'));
app.use((req,res) => {
// 执行static并没有找到对应的资源文件,做404处理
res.status(404);
res.send('NOT FOUND!');
// 或者使用重定向处理
res.redirect(301,'http://www.baidu.com')
});4)数据api请求处理
数据api请求的方法:app.get()/post()/delete()/put()/head()...
示例1:客户端请求地址http://localhost:8080/list?lx=pro,我们就把package.json中的dependencies返回,如果lx=dev,就把devDependencies返回
let fsPromise = require('./utils/fsPromise.js')
......
app.get('/list',(req,res) => {
let {lx = 'pro'} = req.query;
fsPromise.readFile('./package.json').then(result => {
result = JSON.parse(result);
result = lx === 'dev' ? result.devDependencies : result.dependencies;
res.status(200);
res.type('application/json');
res.send(result);
}).catch(err => {
res.status(500);
res.type('application/json');
res.send(err);
})
})2.中间件的使用
中间件用于在创建完服务和处理数据文件请求之前,我们提前做一些公共的事情。例如需要在所有的请求之前把客户端基于请求主体传递的信息获取到,存放到req.body属性上,此时可以使用中间件。
express中用app.use((req,res,next) => {})方法使用中间件,next执行是让其继续执行下面该做的事
1)中间件body-parser
获取post请求体的内容,通过执行不同的方法,把客户端传递的内容转化为对象存放在req.body上,例如bodyParser.urlencoded/json/raw
let bodyParser = require('body-parser');
app.use(bodyParser.urlencoded({extended:true}));
app.post('/add',(req,res) => {
console.log(req.body);
});如果不使用中间件,需要用字符串拼接的方式获取请求体
app.use((req,res,next) => {
let chunk = '';
req.on('data',chart => chunk += chart);
req.on('end',() => {
let qs = require('qs');
req.body = qs.parse(chunk);
next();
});
});2)中间件express-session
设置中间件,req.session可以设置session信息
let session = require('express-session');
app.use(session({
secret:'asdf', // 密钥
saveUninitialized:false,
resave:false,
cookie:{
maxAge:1000 * 60 * 60 * 24 * 30 // 设置session的过期时间
}
}))3.路由
在node的server.js中会反复使用app.get/post方法处理不同路径的请求,是该文件的代码过于冗长, 可以使用express路由将不同路径的请求操作独立到不同的文件中处理;
使用步骤:
1.首先创建routes文件夹,在该文件夹下创建项目中需要的路由文件;

2.在每个路由文件中,导入express,基于Router方法创建路由,将创建好的路由导出,创建好的路由对象使用方式同app;
let express = require('express');
let route = express.Router();
route.get('/user',() => {});
module.exports = route;3.在server.js中创建请求路径和对应路由文件的映射关系;
app.use('/user',require('./routes/user'));