退运险业务及系统架构演进史
作者:曾利⺠、杨代铭
⽂章简介:本⽂回顾退运险上线⼗年以来相关系统架构的演进。
背景
退运险对于我司来说是⼀个举⾜轻重⼀款产品,初创时期贡献了99.9%的 保费收⼊,随着公司的发展各类产品的不断创新,退运险的⽐重在缩⼩,但 它的规模在不断扩⼤,当前年保单量已超百亿。为了满⾜业务的发展,相应 的系统经历不断的演进。
初代架构
核⼼系统于2013年11⽉开始设计,当时不知道业务到底能有多⼤,所以 起个名字叫⽆界⼭,由于对未来的不可知,初版微架都⽐较保守(初代⼤神 ⼤⻦⾔)。退运险作为其⽀持的最重要也是量最⼤的业务,很多设计都基于 它,当时⽇需处理的保单达380万,可能现在看这个数据不算什么,但是要知 道当时通常中⼩型保险公司核⼼系统的⽇均⽀持保单量在10万以内,较普遍 是1⾄3万左右;⼤中型公司则约在⼏⼗万量级,不超过百万。处理⽅式也特 别简单:ODPS预处理报⽂,再解析报⽂,扔出notify消息,核⼼收到后处 理,通过分库分表⽅式解决⼤数据存储问题。各个系统在hsf等中间件的帮助 下具备⽔平扩展能⼒。
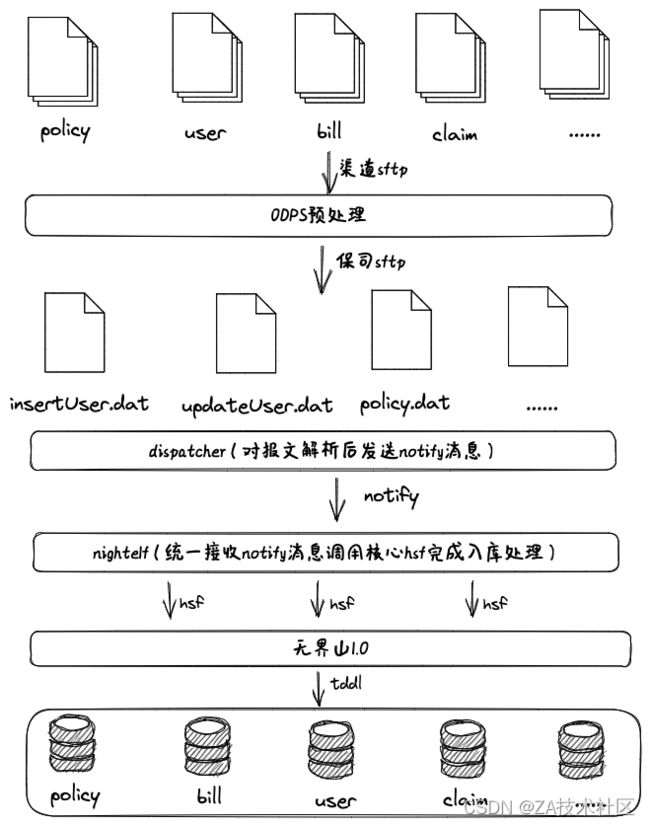
初代架构存在的问题是性能实在是蜗⽜,资源调度极度上不去,消息压⼒ ⼤,⼀旦有异常,堆积导致notify奔溃,业务规模也不断在扩⼤,特别是双⼗ ⼀⼤促时尤为突出,⽇保单量已达亿级别,系统也渐渐显得⼒不从⼼,2015 年进⾏升级引⼊美洲豹(JStorm),将之前dispatcher和nightelf两个项⽬合 ⼆为⼀,架构上通过中间件解决⽔平扩容和单点问题,于当年年11⽉份正式 ⽣产运⾏。
⼆代架构
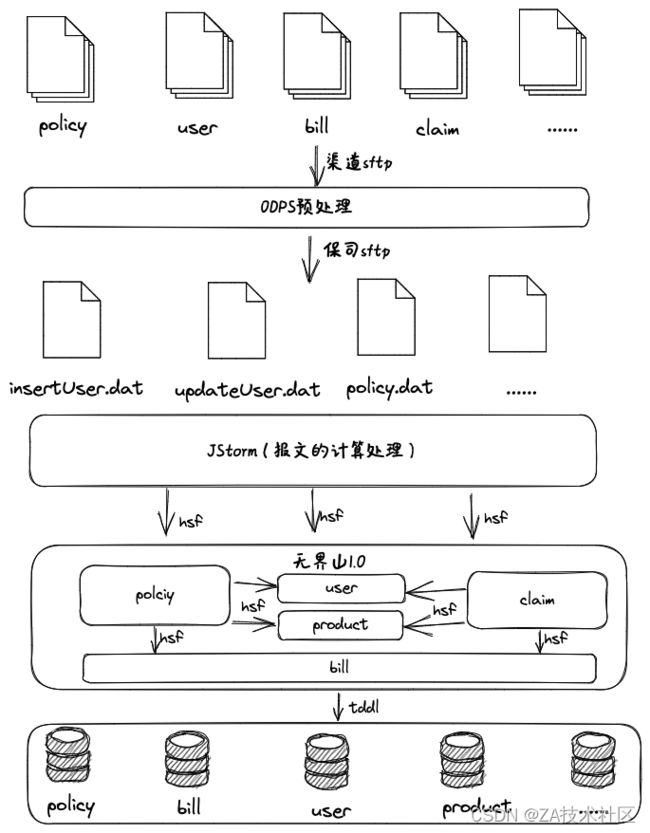
初代架构迭代优化后基本能很好的⽀持退运险业务,但是公司在不断发 展,后续健康险、意外险、财产险等业务不断的开展,核⼼系统也需要⽀持 越来越多的实时业务,对系统的稳定性要求越来越⾼,然⽽退运险⼊库时间 ⽐较集中,系统负载持续在⾼位,导致系统稳定性下降。要同时⽀持退运险 业务和实时业务,虽然可以通过⽔平扩容的⽅式提⾼系统的吞吐量,但是⼀ 天就跑四五个⼩时跑报⽂,扩容会⼀定程度上造成资源浪费,⽽且在跑报⽂ 时间段内也不能避免不影响实时业务。在电商平台进⾏⼤促活动时尤为突 出,在双11期间为了追求更⾼的QPS,前期需要投⼊⼤量的⼈⼒和资源进⾏ 系统调优和压测,⽣产也需要准备⼤量的云资源进⾏⽀持。JStorm是分布式 实时计算引擎,⽽在退运险场景⾥只⽤其任务分发的功能,有点杀鸡⽤⽜ ⼑。⽽且JStorm⽇常维护成本太⾼,使⽤极其不便。
在2018年进⾏⼀次完全的重构,针对退运险的业务基于⽆界⼭核⼼系统 衍⽣出⽆界⼭-电商⼦系统,底层使⽤⽆界⼭1.0的DB,⽀持电商场景包括退 运险、保证保质保险等创新业务。得益于公司Devops的建设,让这套系统测 试、发布和扩容更⾼效。服务间的调⽤使⽤dubbo,消息中间件使⽤kafaka, bill服务也通过消息进⾏异步处理。上线后当年双11单⽇⽀持8千万保单⼊库, 峰值TPS达到2.2万,期间未造成其它实时业务的超时等异常情况。
完成基础架构调整后,于2019年进⾏业务层的深度优化。因为退运险作 为公司第⼀批险种,在核⼼已经运⾏了五六年。在这段时间⾥,核⼼已经新 上了数千个产品,对接了四五个事业部,为了兼容,原有的单独针对淘系报 ⽂的⼊库逻辑已经被改的⾯⽬全⾮。另外⼈员以及部⻔的变动,短时间内经 历多次交接,⼀些特殊逻辑在过程中没交待清晰。以上这些问题,都给维 护、测试和排错等⼯作带来诸多的不便。⽽随着众安与淘系的合作程度加 深,淘系退运险保单量正在进⼀步增加,预计2019年双⼗⼀会达到顶峰。完 成本次优化后,删减了冗余的代码逻辑,减少了DB查询次数,提升了系统的 整体性能。上线后2019年双11单⽇处理保单1.6亿,处理⽤时⽤了160分钟, 峰值TPS达2.7万,报⽂报⽂同⽐去年增加⼀倍处理时⻓缩短40%。
主要改进内容:
开发⽆界⼭-电商⼦系统,与其它险种系统进⾏隔离,减少相互影响,bill 通过kafaka异步⼊库,进⼀步削峰;
使⽤dubbo中间件替代⽼旧的HSF进⾏服务间调⽤,提⾼系统性能;
使⽤新的报⽂处理平台和kafaka消息中间件替代JStorm进⾏异步处理;
优化ODPS预处理逻辑,调整报⽂结构,降低ODPS处理资源消耗;
产品配置、⽤户信息进⾏本地化缓存,减少重复DB查询,提升系统性 能。
三代架构
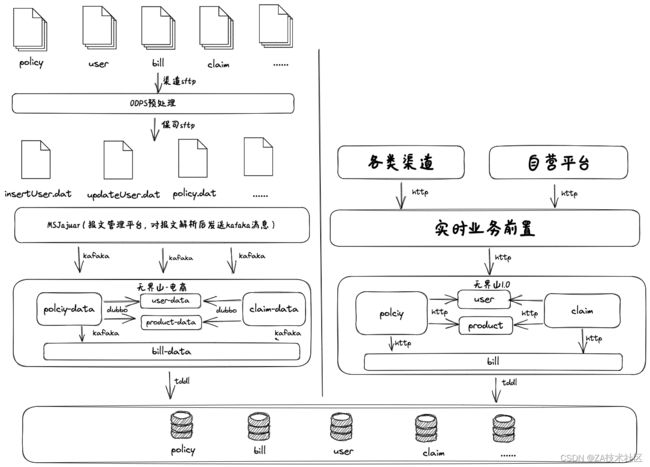
数字⽣活事业部⼀直在⾮阿退运险⽅向进⾏了不断地努⼒,期间接⼊过 蘑菇街、趣店等电商平台,但都量不⼤⽇保单在万单级别,近年来随着抖 ⾳、快⼿等新兴平台电商业务蓬勃发展,使得退运险在⾮阿渠道得以突破, 2020年6⽉份快⼿接⼊,2021年7⽉份抖⾳接⼊后,⾮阿退运险⽇保单量逐渐 超千万单。退运险不仅仅只有阿⾥单⼀渠道和场景,逐步向多元化的⽅向发 展。三代架构在这过程中也逐渐形成,公司⽆界⼭核⼼也升级为2.0不在和退 运险共⽤DB,其它险种和退运险相互再⽆影响。根据当前需求新开发报⽂管 理平台,使⽤OCeanBase分区表替代原来分库分表,使⽤Redis的Message queue进⾏报⽂⽂件的分发处理。以及开发gateway-data、anacientone系统 处理退运险实时业务。
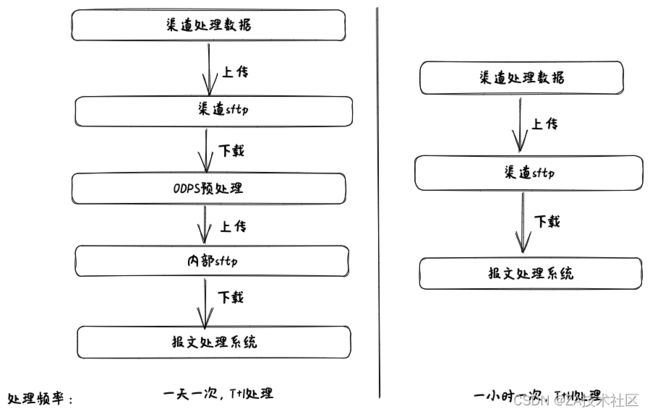
在降本增效的环境下,不再不计代价的追求⾼QPS,⽽是要求以更经济 的⽅式⽀持业务。为了达到这个⽬标,在优化系统的同时,也优化业务模 式,⽐如淘系报⽂之前T+1给前⼀天所有的报⽂,导致会出现⼀个报⽂有上亿 条数据,处理数据时间过于集中,处理过程只能串⾏进⾏,导致系统资源没 有充分利⽤。最终我们和渠道⼀起进⾏优化整改,以T+H的⽅式给报⽂增加 给报⽂频次,给了更⻓的时间窗⼝处理数据,也⼤⼤减少单个报⽂数据量, 从⽽进⼀步进⾏了削峰,⽇常只需400QPS就能保障业务正常运转,以往需要 达到4000QPS。⼤促期间以往需要⼏⼗台ECS⽀持,QPS需要达到2万,现 在只需原来的⼗分⼀就能满⾜要求,以更少的系统资源⽀持业务,达到降本 增效的⽬的。同时也提⾼保单的⼊库时效,提升了⽤户体验。
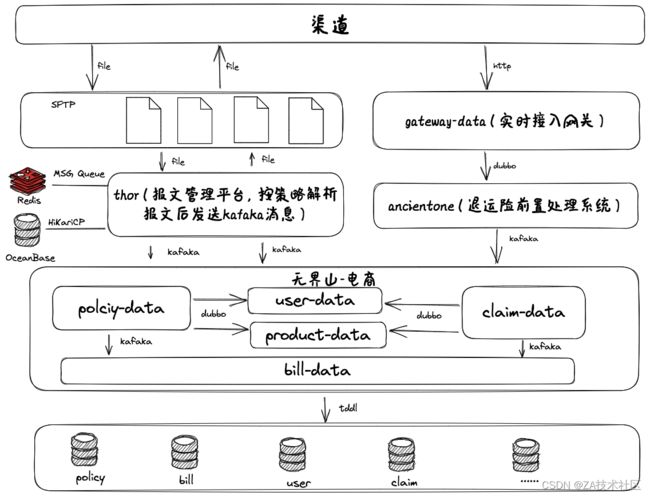
主要改进内容:
⽀持实时接⼊,其中快⼿以及⼀些⼩渠道通过实时⽅式接⼊;
⽀持配置个性化策略解析报⽂,可以配置不同频次解析报⽂;
⽀持异常检测、预警,以及⾃动修复;
剔除ODPS预处理报⽂,⼀来减少报⽂处理环节,⼤⼤降低⼤⽂件传输消 耗,⼆来直接减少了ODPS计算费⽤;
⽀持回传结果⽂件,解决对账问题;
其它险种DB隔离,不再相互影响。
总结
对⽐三代架构,其中的中间件可能⼤不相同,但是核⼼的思想基本是⼀ 致的,就是通过异步的⽅式进⾏削峰。⼤道⾄简⽀持年保单量百亿的系统也 不过如此。其实退运险虽然数据量庞⼤,但是它在电商的交易场景⾥⽤户感 知不强,所以它对实时性的要求⽐较低,结合它的这⼀特性才有这样的系统 设计。另外是因为站在巨⼈的肩膀上,依托公司的各项基础设施,才能这么 简单构建这类处理海量数据的分布式系统。
我司成⽴⼗周年,退运险业务上线也正好⼗年,这⼗年业务规模不断地 扩⼤,形态也有变化,系统经历了⼏次变⾰。也经历公司各个时期,从⼈⾁ 运维,到Duang、boom、ship、最后到现在的DevCube。基于公司⾃研的 DevOps研发运维⼀体化解决⽅案,使我们的系统能敏捷迭代,全链路监控预 警,以及快速修复⽣产故障等。
退运险是互联⽹的产物,所以得益于互联⽹相应的技术和思想,才构建 这套系统。正如布鲁克斯在《⼈⽉神话》中所说的没有银弹,没有⼀个系统 ⼀开始就能做到尽善尽美,会随着业务发展、技术进步不断的调整和优化。 回头看之前的技术选型会有问题,但在当时就是最合适的⽅案。
本⽂未对业务场景以及⼀些技术细节进⾏展开,对相关⽅⾯有兴趣的同 学可以单独找我探讨。后续相关的负责⼈也会输出相关⽂章介绍