Golang实现逻辑编排解释引擎
作者:井卓
文章简介:
逻辑编排提供一站式集成平台,简化了在集成接口、应用和服务时,所涉及的业务逻辑和流程。本文会介绍如何通过ChatGPT学习Golang、以及表达式解释器的实现和Golang解析引擎的基本设计架构。
Golang实现逻辑编排解释引擎
- 背景:
逻辑编排提供一站式集成平台,简化了在集成接口、应用和服务时,所涉及的业务逻辑和流程。但逻辑编排自研流程中缺少后端的解析引擎,于是我通过ChatGPT高效的学习了Golang,并完成了开发。本文会介绍如何通过ChatGPT对Golang学习教程的提炼和依赖资料的获取路径、表达式解释器的实现和Golang解析引擎的基本设计架构等。
2.如何使用ChatGPT学习Golang
2.1 跑起来 "Hello World!"
问ChatGPT如何用go跑起来一个"Hello World!" ,尽量精简提问,这样就能更精确的拿到自己想要的内容
通过这个提问可以提炼出两个要点
- 一个最简单的go文件是什么样子
- package main
- import "fmt"
- func main() {
- fmt.Println("Hello, World!")
- }
- 如何运行这个go文件,chat可以精确的告诉go的安装地址,以及安装流程,可以很快搞定
2.2 用例子来学习
比起官网上冗长的学习教程,我更想看到 go和我们前端常用的ts有什么区别,这样的内容可以直接问ChatGPT,并且让他给出具体的例子,会得到例子。
2.2.1 变量定义
变量定义在两种语言的中的区别是不同的,除了语法上的不同。在参数的类型上对于数字类型Golang有 int, float32, float64等多种类型。这是因为Golang作为编译型静态类型语言,在变量定义的时候根据不同的类型所占据的字节数是有差别的,所以对语言的变量类型定义更加严格。但这些数字类型这在TypeScript中都统一称做number。
- // Golang
- var a int = 1
- // TypeScript
- var a: number = 1;
2.2.2 面向对象的区别
面向对象编程是可以代码 高内聚,低耦合的方案。可以通过ChatGPT方便的知道语言的特性,在Golang中没有传统的类(class)的概念,也就是常说的oo,它采用了一种不同的面向对象编程模式,称为"结构体(struct)"和"方法(method)",与高级语言中类定义的方式有所区别。
- // Golang
- type FlowNode struct {
- id string
- nodeName string
- }
- func NewFlowNode(params map[string]interface{}) (*FlowNode, error) {
- nodeType, err := node.ToNodeEnum(params["type"].(string))
- if err != nil {
- fmt.Println(err)
- return nil, nil
- }
- flowNode := &FlowNode{
- id: params["id"].(string),
- nodeName: params["displayName"].(string),
- }
- return flowNode, nil
- }
- func (f *FlowNode) GetId() string {
- return f.id
- }
- // TypeScript
- class FlowNode {
- private id: string;
- private nodeName: string;
- constructor(params: any) {
- this.id = params.id
- this.nodeName = params.nodeName
- }
- public GetId(): string {
- return this.id
- }
- }
2.3 进阶学习更为复杂的用例
学习go还是为了写后端接口,在了解了基础的语法后,进阶的问如何用go起后端服务,跑起来一个基础的接口用例
- package main
- import (
- "fmt"
- "net/http"
- )
- func main() {
- // 定义一个HTTP请求处理函数
- http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
- fmt.Fprintf(w, "Hello, World!") // 向客户端发送 "Hello, World!" 响应
- })
- // 启动HTTP服务器,监听在端口8080
- err := http.ListenAndServe(":8080", nil)
- if err != nil {
- fmt.Println("Server error:", err)
- }
- }
在这这个的基础上询问如何实现get请求,post请求,以及如果连接数据库,拿到具体的学习用例,来满足自己的目的。
3.表达式解释器的实现
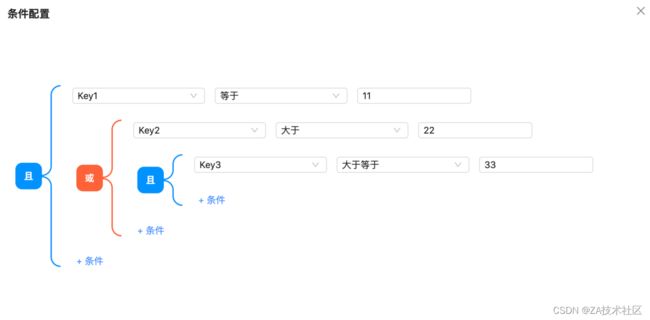
在逻辑编排中需要配置不同的分支进入的逻辑,需要用Go实现一套规则的解释引擎,也就是表达式解释器。规则引擎的配置交互如图所示 。
3.1 什么是表达式解释器
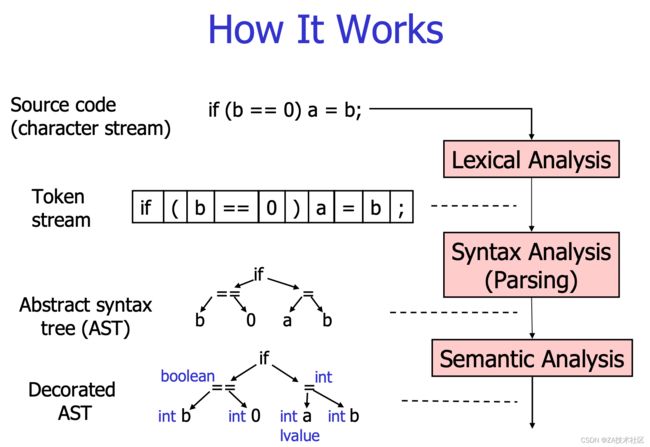
需要先了解如何实现一个解释器。解释器(Interpreter)是一个基于用户输入执行源码的工具并拿到结果的工具,解释器会解析源码,生成 AST(Abstract Syntax Tree)抽象语法树,逐个迭代并执行 AST 节点。解释器有三个阶段:词法分析(Lexer),语法分析(Syntax ),执行(Eval)
其中 Lexer 负责将原始文本转换为标记流。解析器将标记流转换为抽象语法树(AST)。 AST 基本上是表示为树数据结构的源代码。访问者通过递归“访问”AST 中的每个节点来进行实际的评估/执行。稍后我们将仔细研究它们中的每一个。
3.2 词法分析
词法分析的过程是解析字符串生成有具体含义的每个单词,这个过程我们需要借助有穷自动机来完成,在此之前我们需要重新了解一下正则表达式,这是所有的步骤的基石。
3.2.1 正则表达式
日常编程大家应该都接触过正达式,用它来匹配字符串等,也可能已经很熟悉其语法了。但我这次想从正则表达式的最基本概念来重新介绍一次,主要想让大家更深地理解它。首先我们要重新定义一下“语言”这个概念。“语言”就是指字符串的集合,其中的字符来自于一个有限的字符集合。也就是说,语言总要定义在一个有限的字符集上,但是语言本身可以既可以是有穷集合,也可以是无穷集合。比如“JavaScripe语言”就是指满足JavaScripe语法的全体字符串的集合,它显然是个无穷集合。当然也可以定义一些简单的语言,比如这个语言{ a }就只有一个成员,那就是一个字母a。后面我们都用大括号{}来表示字符串的集合。所谓正则表达式呢,就是描述一类语言的一种特殊表达式,正则表达式共有2种基本要素:
- 表达式ε表示一个语言,仅包含一个长度为零的字符串,可以理解为{ String.Empty },我们通常把String.Empty记作ε,读作epsilon。
- 对字符集中任意字符a,表达式a表示仅有一个字符a的语言,即{ a }。
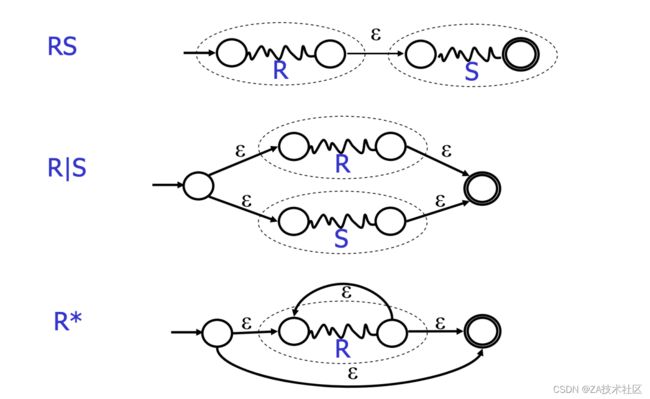
同时正则表达式定义了3种基本运算规则:
- 两个正则表达式的并,记作X|Y,表示的语言是正则表达式X所表示的语言与正则表达式Y所表示语言的并集。比如a|b所得的语言就是{a, b}。类似于加法
- 两个正则表达式的连接,记作XY,表示的语言是将X的语言中每个字符串后面连接上Y语言中的每一种字符串,再把所有这种连接的结果组成一种新的语言。比如令X = a|b,Y = c|d,那么XY所表示的语言就是{ac, bc, ad, bd}。因为X表示是{a, b},而Y表示的是{ c, d},连接运算取X语言的每一个字符串接上Y语言的每一个字符串,最后得到了4种连接结果。这类似于乘法
- 一个正则表达式的克林闭包,记作X,表示分别将零个,一个,两个……无穷个X与自己连接,然后再把所有这些求并。也就是说X* = ε | X | XX | XXX | XXX | ……。比如a这个正则表达式,就表示的是个无穷语言{ ε, a, aa, aaa, aaaa, …. }。这相当于任意次重复一个语言。
比如我们常见的变量定义改写成正则就是 ^[a-zA-Z_][a-zA-Z0-9_]*$,数字对应的正则是^-?\d+(\.\d+)?$, 我们大家平时熟悉的正则表达式是写成上文这样的字符串形式。但这次我们要自己处理正则表达式,写成字符串显然增加了处理的难度(要解析正则表达式字符串)。所以词法分析库中,需要通过面相对象思想来抽象正则表达式,每一种正则表达式要素或运算编写了一个子类, 具体要如何转换需要借助NFA和DFA来进行。
3.2.2 有穷自动机NFA
有穷自动机首先包含一个有限状态的集合,还包含了从一个状态到另外一个状态的转换。有穷自动机看上去就像是一个有向图,其中状态是图的节点,而状态转换则是图的边。此外这些状态中还必须有一个初始状态和至少一个接受状态。下面的图展示了一个有穷自动机,有根从外边来的箭头指向的状态表示初始状态,有个黑圈的状态是接受状态:
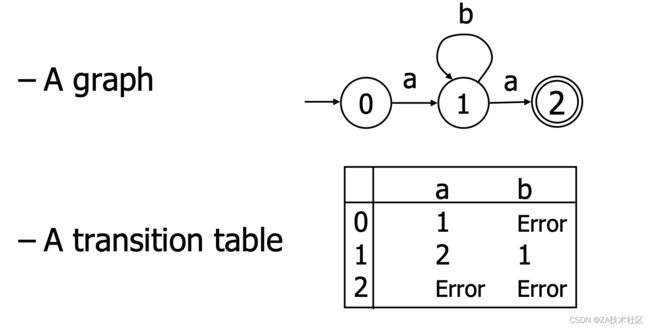
有穷自动机怎么处理输入的字符串"ab*a"的流程如下:
- 一开始,自动机处于初始状态
- 输入字符串的第一个字符,这时自动机会查询当前状态上与输入字符相匹配的边,并沿这条边转换到下一个状态。
- 继续输入下一个字符,重复第二步,查询当前状态上的边并进行状态转换
- 当字符串全部输入后,如果自动机正好处于接受状态上,就说该自动机接受了这一字符串
3.2.3 非确定性有穷自动机DFA
非确定性有穷自动机(NFA),它允许从一个状态发出多条具有相同符号的边,甚至允许发出标有ε(表示空)符号的边,也就是说,NFA可以不输入任何字符就自动沿ε边转换到下一个状态,他会比NFA接受的状态更多,也是我常用的词法分析方案,也就是说在NFA中从开始状态到结束的状态的路径并不是固定的,甚至有可能是空字符串!

下图展示了一个非确定性有穷自动机:

不同的自动机对应不同的正则表达式,例如正则表达式-?[0-9]+就是对应上述的非确定性有穷自动机,借助这样的有穷自动机我们可以实现把正则拆分到不同的自动机上,来实现词法分析中对字符串的解析, 我们上边的更多正则的规则可以用下图进行描述。
通过NFA我们可以把所有的正则进行解析和完善,并列出相应的对应表关系。把不同的正则抽象成不同的类,用来语法分析,也就是表达式中诸如变量、数字、算数运算符号、逻辑运算符号这样有特定意义的单词,来进入下一步的解析。
3.3 语法分析
词法分析把字符串解析成一个个具有具体意义的单词,一种完整的编程语言,必须在此基础上定义出各种声明、语句和表达式的语法规则。观察我们所熟悉的编程语言,其语法大都有某种递归的性质。例如四则运算与括号的表达式,其每个运算符的两边,都可以是任意的表达式。比如1+a是表达式,(1+a)*(2 – c)也是表达式,((a+b) + c) * (d – e)也是表达式。再比如if语句,其if的块和else的块中还可以再嵌套if语句。我们在词法分析中引入的正则表达式和正则语言无法描述这种结构,如果用DFA来解释,DFA只有有限个状态,它没有办法追溯这种无限递归。所以,编程语言的表达式,并不是正则语言。要引入一种表现能力更强的语言——上下文无关语言。
要介绍上下文无关语言,我们先来了解一下定义上下文无关文法的工具——产生式的写法。我们还是使用编程语言的表达式作为例子,但这次我们假设表达式只有三种——单个表示变量名标识符、括号括起来的表达式和两个表达式相加。比如a是一个变量表达式,a+b是两个变量表达式相加的表达式,(a+b)是一个括号表达式。我们用符号E来表示一个表达式,那么这三种表达式分别可以定义为:
E → E + S | E
E → number | ( S )
这种形式的定义就叫做产生式。出现在→左侧符号E称作非终结符(nonterminal symbol),代表可以继续产生新符号的“文法变量”。 符号→表示非终结符可以“产生”的东西。而上述产生式中的蓝色id、+、(等符号,是具有固定意义的单词,它们不再会产生新的东西,称作终结符(terminal symbol)。注意,非终结符可以出现在产生式的右侧,这就是具有递归性质文法的来源。产生式经过一系列的推导,就能够生成各种完全由终结符组成的句子。比如,我们演示一下表达式(1+2+(3+4))+5的推导过程:
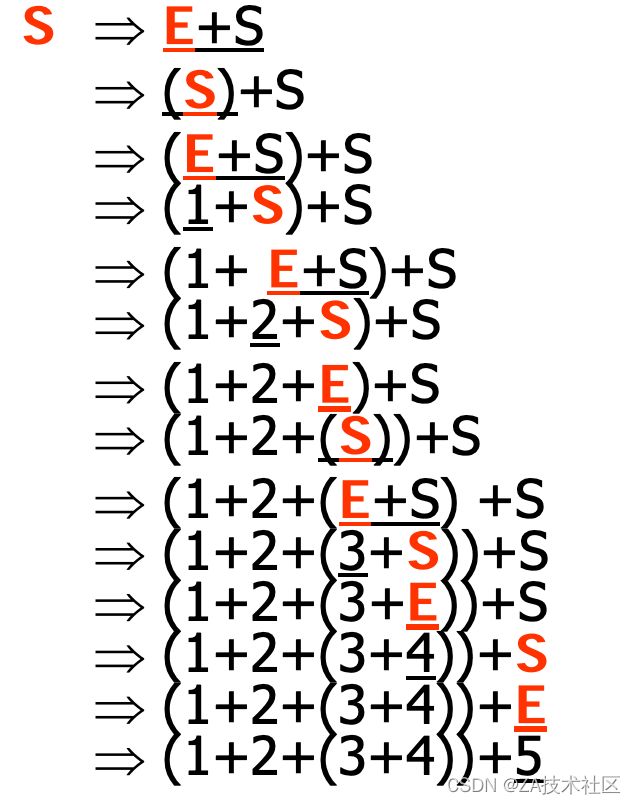
推导树与Ast:

上边我们说到语法分析使用的上下文无关语言,以及描述上下文无关文法的产生式、产生式推导和语法分析树等概念。今天我们就来讨论实际编写语法分析器的方法。今天介绍的这种方法叫做递归下降(recursive descent)法,这是一种适合手写语法编译器的方法,且非常简单。递归下降法对语言所用的文法有一些限制,但递归下降是现阶段主流的语法分析方法,因为它可以由开发人员高度控制,在提供错误信息方面也很有优势,使用递归下降法编写语法分析器无需任何类库,编写简单的分析器时甚至连前面学习的词法分析库都无需使用。我们来看一个例子:现在有一种表示二叉树的字符串表达式,它的文法是:
- N → a ( N, N )
- N → ε
其中终结符a表示任意一个英文字母,ε表示空。这个文法的含义是,二叉树的节点要么是空,要么是一个字母开头,并带有一对括号,括号中逗号左边是这个节点的左儿子,逗号右边是这个节点的右儿子。例如字符串 A(B(,C(,)),D(,))就表示这样一棵二叉树:

把这样的推导过程用代码表达出来,我们就能构成真正的Ast数,进行下一步的的解释执行。
下边介绍我们用LL文法对一个二元表达式(1 + 2 + (3 + 4)) + 5的解析。

4.解释执行
通过语法分析拿到真正的Ast之后,可以做的事情有两种,解释器(compiler) 和 编译器(Interpreter)和,如果有个翻译器把源程序翻译成机器语言,那它就是 编译器。如果一个翻译器可以处理并执行源程序,却不用把它翻译器机器语言,那它就是 解释器。比如我们用的Taro其实本质上就是编译器的一种,解析我们用React成Ast,并翻译成原生的小程序语法。而我们这里的表达式解释器主要是写的是解释器,通过对表达式Ast的解释执行拿到表达式的结果。
4.1 模式匹配
下面就是这个计算器的代码。它接受一个表达式,输出一个数字作为结果,正如上一节所示。
- (define calc
- (lambda (exp)
- ; 匹配表达式的两种情况
- (match exp
- ; 是数字,直接返回
- [(? number? x) x]
- ; 匹配并且提取出操作符 op 和两个操作数 e1, e2
- [`(,op ,e1 ,e2)
- ; 递归调用 calc 自己,得到 e1 的值
- (let ([v1 (calc e1)]
- ; 递归调用 calc 自己,得到 e2 的值
- [v2 (calc e2)])
- ; 分支:处理操作符 op 的 4 种情况
- (match op
- ; 如果是加号,输出结果为 (+ v1 v2)
- ['+ (+ v1 v2)]
- ; 如果是减号,乘号,除号,相似的处理
- ['- (- v1 v2)]
- ['* (* v1 v2)]
- ['/ (/ v1 v2)]))])))
- ; 是变量 在全局的作用域中查找
- [(? variable? x) x]
这里的 match 语句是一个模式匹配。它的形式是这样:
- (match exp
- [模式 结果]
- [模式 结果]
- ... ...
- )
它根据表达式 exp 的“结构”来进行“分支”操作。每一个分支由两部分组成,左边的是一个“模式”,右边的是一个结果。左边的模式在匹配之后可能会绑定一些变量,它们可以在右边的表达式里面使用。
一般说来,数据的“定义”有多少种情况,用来处理它的“模式”就有多少情况。比如算术表达式有两种情况,数字或者 (op e1 e2)。所以用来处理它的 match 语句就有两种模式。“你所有的情况,我都能处理”,这就是“穷举法”。穷举的思想非常重要,你漏掉的任何一种情况,都非常有可能带来麻烦。所谓的“数学归纳法”,就是这种穷举法在自然数的递归定义上面的表现。因为你穷举了所有的自然数可能被构造的两种形式,所以你能确保定理对“任意自然数”成立。
6.总结
我们在了解表达式解释器的理论基础上,需要应用于实战,下边是我们一个表达式节点配置的schema,分别包含解释器的上下文以及需要解析的逻辑语句信息。其中 schema 会被翻译成 ( Key1 == 1) && ( Key2 == 2) && ( (Key1 > 1) ||(Key3 >= 2)) 然后放入我们的表达式解释器中拿到真正的执行结果,可以疑问这里的Key是什么,其实这是我们的上下文中存储的变量,我们在最终解释器的模式匹配中,会设置如果遇到变量就去相应的作用域中查找, 由于我们这里实现的表达式解释的上下文的没有嵌套的情况,所以这里的的表达式只有一层。通过以上步骤,我们就实现了表达式解释器,可以当作逻辑编排中的规则引擎进行使用,利用动态表达式来实时修改配置,我们保险产品的显示规则等,下文将继续介绍表达式解释器如何应用到逻辑编排中。
4. 用Golang实现逻辑编排引擎设计
4.1. 什么是逻辑编排
逻辑编排提供一站式集成平台,简化了在集成接口、应用和服务时,所涉及的业务逻辑和流程。提供简便易用的设计方式,快速生成服务接口以及定时任务, 流程设计如下。

在具体交互流程如下,用户可以可视化的配置自己的条件分支,以及不同的分支需要执行的流程结果。

4.2. 逻辑编排的架构设计
4.2.1 节点架构设计
规则解析引擎的的代码实现比较灵活,没有固定的模板。应用设计模式主要是应对代码的复杂性,实际上,解释器模式也不例外。它的代码实现的核心思想,就是将语法解析的工作拆分到为不同的节点类型,以此来避免大而全的解析类。一般的做法是,将语法规则拆分成一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
在架构设计上的逻辑编排引擎的节点类型有开始节点,结束节点, 条件节点, 代码节点, 合并节点,分支节点。所有的节点信息都会被记录在一维的数组中,每个节点的都会有两个字段preId和nextId 记录自己上下节点的ID信息,这是一个类似于双向链表的数据结构。之前我看过内容生产平台的出码部分的源码,数据结构也是类似的。拿到节点数组后,会按照不同的节点type进行分发,从而实例化不同的节点。每个实例节点都继承自相同的父类,需要统一实现 Run从而来处理不同的节点特定的逻辑内容
开始节点
标注逻辑解析引擎开始的节点。
结束节点
作为整个解析引擎的结束,nextId 是空标注程序的结束,需要接口的返回参数, 作为整个接口的输出。
条件节点
条件配置节点就是我们上边实现的表达式解释器,它通过执⾏规则并进⾏推理,能够实现规则匹配、前向推理、后向推理等功能。拿到当前逻辑判断节点的结果 true 或者 false 。决定当前分⽀是否可以继续向下执⾏,这里的表达式解析引擎实现的具体步骤会在下文介绍。
接口调用节点
接口节点可以支持配置请求头,请求链接,请求参数,通过go发送接口,并拿到接口的执行结果,并将结果请求传递到后边的节点。
代码块节点
代码节点的解释执行是通过goja进行的,goja是Golang的一个包用来可以执行js的代码,同时支持定制上下文拦截器 context,来对整个逻辑编排数据的读取进行读取, 通过 getArg 可以读取到上文中传入当前节点的参数,setReturn 可以设置代码中需要返回的数据。
- const phone_number = context.getArg('phone_number');
- const p1 = phone_number.substring(0,3)
- const p2 = phone_number.substring(7,11)
- const result = `${p1}****${p2}`;
- context.setReturn({'result_phone': result}) ;
分支节点
记录逻辑编排中会进行分支的地方,记录叉的节点信息,并发的判断不同分叉节点的逻辑是否通过,从而判断具体是哪个分支才能向后执行。
合并节点
记录逻辑编排中合并节点信息的地方,用于向下传递参数信息。
4.2.2 作用域Scope架构设计
任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问。所以每个节点支持配置自己的输出和输入的参数,用来暴露出给全局的参数信息,前边节点的输出,可以当作后边节点的输入。
每节点都会有 inputArgs 参数,用来存储输入的参数信息。输入的参数类型分为以下几种globalData 全局参数 , flowData 节点参数, immediate 立即数,具体结构如下。其中 immediate可以直接的读取数据,globalData 和 flowData会被从作用域从进行存取。
每节点都会有 outputArgs 参数,用来在作用域中记录,当前节点暴露出的字段信息有哪些,用于向下边节点传递信息。
5.总结
通过本文的阅读,会了解如何通过ChatGPT对教程的提炼和依赖资料的获取,以及Golang解析引擎的基本设计架构:
- 如何通过ChatGPT对学习一门新语言的流程进行高效的拆解。
- 表达式解释器的基本构成,词法分析,语法分析,解释器分别作用的流程与原理。
- 逻辑编排的架构设计,需要对流程的过程进行抽象,用面向对象的思想编程,抽出逻辑流程的节点之间的共性与区别。