Python复习笔记——基础篇
目录
●认识Python:
●开发环境:
●编程:
●知识点:
●输出函数print()
●转义字符:\
●二进制与编码
●标识符和保留字
●变量的定义和使用
●简单数据类型
●整数
编辑●浮点数
●bool 编辑
●str
●一般字符串、整数的驻留机制:
●数据类型转换
●注释编辑
●注释
●input()编辑
●Python 运算符
●Python 运算符编辑编辑
●语法结构
●条件表达式编辑编辑
●range()
●进阶数据类型
●list
●list的增删改查
●Dict编辑
●set
●进阶数据小结编辑
●function(函数)
●Python异常处理
●类
●copy
●认识Python:
Python中的变量也是对象,函数也是对象,类class本身也是对象,Python中一切皆对象。
Python内存动态分配,既我们一般不用管内容的分配问题。
Python对象是否可变:是指在id不变的情况下,能否把Python对象中的对象修改为另一个对象,如果可以,为可变对象,必定有增删改方法;如果不可以,为不可变对象,很少增删改,甚至没有增删改方法,不可变对象一般hashable。
类中def叫方法,模块——.py文件中直接def的叫函数。
| str | 绝对不可变 | “你好” | hashable | 可做字典key |
| numb数字 | 绝对不可变 | 1、1.2 | hashable | 可做字典key |
| 元组tuple | 绝对不可变 | (1,2) | hashable | 可做字典key |
| 元组tuple | 相对不可变 | ([1,2],3,4) | unhashable | 不能做字典key |
| 字典dict | 可变 | 有增删改方法 | unhashable | 不能做字典key |
| 集合set | 可变 | 有增删方法 | unhashable | 不能做字典key |
| == | 只比较value |
| is | 只比较ID |
Python变量当用对象类名命名时,有个弊端,就是删了还存在,不报错。如:
set={1,2,3} del set print(set)→



●开发环境:

IDLE:自带的简单的开发环境
Python 3.8:交互式命令行程序
?Python 3.8 Manuals:说明手册
Models Docs:记录已安装的依赖包/模块
pycharm:集成开发环境。专业版:收费 ; 社区版:免费
在settings里可以修改默认类型文件的模版,比如加上时间,【# coding=GBK】等内容(python3以后不用写了,默认【# coding=utf-8】):



●编程:
Python解释器:将python语言翻译成电脑所能识别的语言,叫python interpreter。一般是一个python.exe的文件。
●知识点:
●输出函数print()
●输出到控制台:print(),可以输出number、string,默认换行。
print(1,2)/print(1,end="")来打印到一行
●输出外部文件:

| print('\033[a;b;cm字符串\033[m' | |
| 开头 | \033[a;b;cm |
| a | 显示方式:0(高亮)/ 5(闪烁) |
| b | 文字颜色 |
| c | 背景颜色 |
| 结尾 | \033[m |

●转义字符:\
| 转义 | 英文 | 释义 |
| \n | newline | 换行 |
| \t | tab | 最多4个空位,最少1个空位 |
| \r | return | \r之前的内容失效 |
| \b | backspace | 退格,删一个位 |
| \\ | \ | |
| \' | ' | |
| r(R) | 原字符 | 保持原意 |


一个【\】不行,两个【\\】可以
●二进制与编码
搜索【calc】小计算器【程序员】模式,对【进制】切换十分友好:
| 8bit | 1byte | 1 |
| 1024byte | 1kb | 千 |
| 1024kb | 1mb | 兆 |
| 1024mb | 1gb | 吉 |
| 1024gb | 1tb | 太 |
所有字符都被可以被编码:

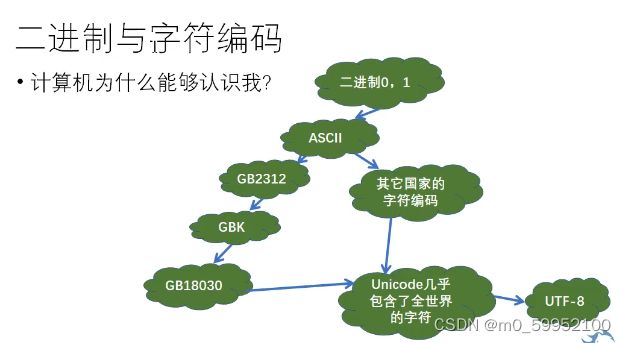
str.ord()返回str的ascii码
ascii码.char() return str

标记字母不区分大小写:
●标识符和保留字


●变量的定义和使用
或者说变量是对对象id的重命名,这里有点像Excel定义名称和indirect()函数的用法。
ps:万物皆对象,对象均有id,type,value。变量就是存储对象id的容器,所以变量可容纳任何对象,即,a=任一对象,而这个赋值过程就是将对象id存储在系统给a分配的存储空间中。


变量【name】只存储id

●简单数据类型
字符串可以是【单引号】【双引号】【三引号】

●整数
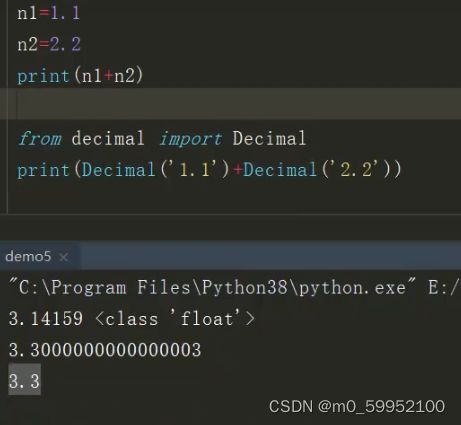
●浮点数

浮点数计算有时候会错(个别情况),纠正方法:

●bool 
●str
str1.endswith(str2):bool,#判断字符串1是否以字符串2结尾
eval(str):如eval(‘{1:2}’’),返回:{1:2},一个字典
str可以和数字相乘,例:"我“ * 3 = “我我我”
不可变,因为它就是一个元素的元组tuple。

| str.lower() | "12ssLL" | '12ssll' | 以下都有,非字母不会变。 |
| str.upper() | "12ssLL" | "12SSLL" | |
| str.swapcase() | "12ssLL" | "12SSll" | |
| str.captitalize() | "12ssLL" | "12ssLL" | 它是upper(str[0]),lower(str[1:]) |
| str.title() | "12ssLL" | "12Ssll" | 把每个非字母字符后(包括str[0])的字母串, 第一个字母大写,其余小写。 |
| str.center() | "hello".center(7,"*") | '*hello*' |
| str.ljust() | "hello".ljust(7,"*") | 'hello**' |
| str.rjust() | "hello".rjust(7,"*") | '**hello' |
| str.zfill(): 对数字str的填充很友好 |
'-123.07'.zfill(9) 'hello'.zfill(7) |
'-00123.07' '00hello' |

| str.split() str.rsplit() |
'h p w'.split()=='h p w'.rsplit() 'h|p|w'.split()=='h|p|w'.rsplit() |
['h','p','w'] ['h|p|w'] |
| str.split('|') str.rsplit('|') |
'h|p|w'.split('|') 'h|p|w'.rsplit('|') |
['h','p','w'] ['h','p','w'] |
| str.split('|') | 'h|p|w'.split('|',maxsplit=1) | ['h','p|w'] |
| str.rsplit('|') | 'h|p|w'.rplit('|',maxsplit=1) | ['h|p','w'] |



合法标识符:字母、数字、_
isnumeric():不能判断浮点数、负数的str。
●字符串的查找


格式化字符串:




str的编码、解码:

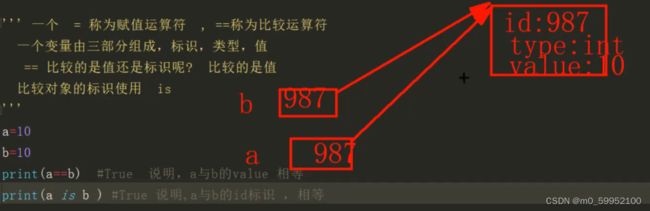
●一般字符串、整数的驻留机制:
a="Python" b='Python' c='''Python''' id(a)==id(b)==id(c)
| 条件 | 举例 | 驻留? |
|---|---|---|
| 字符串长度为0或1 | ''或“1” | 驻留 |
| 字符串仅由字母、数字、下划线组成 | '1abe_' | 驻留 |
| 字符串包含字母、数字、下划线以外的字符 | ‘1-’或者‘ab&’ | 不驻留 |
| 驻留发生在程序编译时,而非运行时 【+】在编译时会被运行 推荐使用join()方法,效率更高,大大节约时间 |
a='abc' b='ab'+"c" c=''.join(['a','b','c']) |
a、b驻留 c不驻留 |
| [-5,256]的整数,浮点数不行 | a=-5 b=-5 | 驻留 |
| import sys ,其中a、b只能是str |
a=sys.intern(b) | 强制驻留 |
| pycharm对str、all-numb进行了驻留优化 | a=1.1 b=1.1 | pycharm中驻留 |
●数据类型转换
“1.77”这样的小数字符串不能用int(),“78”可以用int()。
。

●注释
●注释

●input()
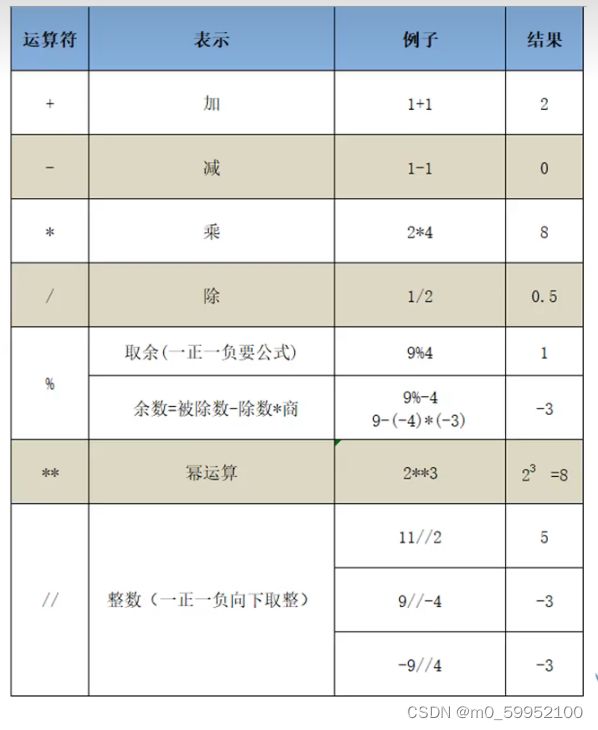
●Python 运算符

取整【//】,不能整除时,把结果往小了去取。如【2.2】→【2】,【-2.2】→【-3】;
牵扯负数取余时,一定要先求【//】,然后用余数公式计算,才能笔算出正确结果。


a,b=b,a 调换a、b的值,十分实用。



位运算符:
~:按位取反
^:按位异或。没有同或,可以异或后取反得到同或。





●Python 运算符

●语法结构


●条件表达式

●表达式 if a>b else (表达式 if a
●分类打印输出,可以用字典,key为条件,value为值
●range()
返回一个literable对象,不用不生成,遍历时再生成,节省空间。



continue可以理解为继续的标记,程序不会执行它。通过bug调试可以发现会跳过这句。
●进阶数据类型
●list
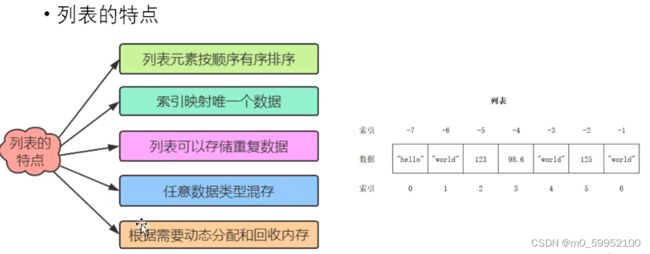
方括号括起来的对象,一定是列表,就算没有元素,也是空列表。元素可以是任意对象。
ps:列表是由一个个对象的id组成的数据组。
list特性:重新声明list时(a=list()),系统会生成新的对象,新的对象id会被存在变量a的存储中,而不是在现有的对象中寻找。正所谓列表是可变的。
而tuple的特性正好相反,系统会先寻找是否已有tuple对象,有,就不再新建,而是直接将旧的tuple对象的id存储到变量所代表的存储中。它是不可变的。
上面讲到的numb、str、bool也有类似元组的特性,所以说它们是不可变的。
以上特性决定了赋值变量时是否产生新的存储。
list1, list2 = [], [] id(list1) != id(list2) ;除非list1 = list2 = [],这时候id(list1) == id(list2)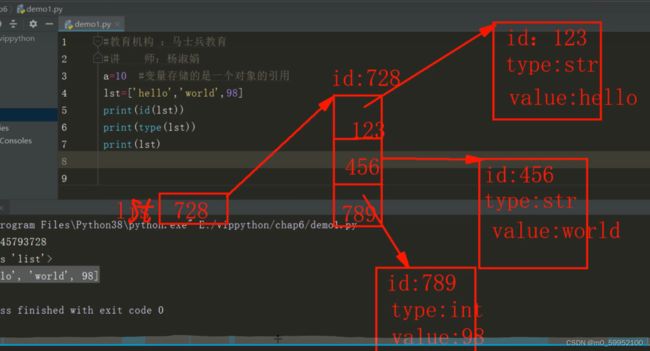

永远不用担心列表的内存、大小不够。是动态分配的,保证够用。

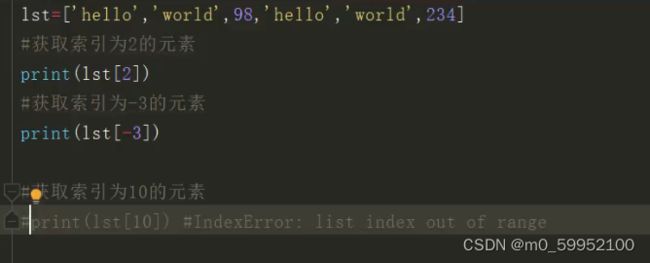
【:】是切片的标志。


●list的增删改查
【list.append()】等内置方法使用时避免列表的赋值,就不用担心是否有新列表产生,这就是使用内置方法的意义。
【技巧】切片:【list[1:2:3]】=[1,2,3]的形式不算是变量的赋值,不用担心有新列表产生,推荐使用,功能强大、灵活。增删改查都可以,yyds!
如果我们还是用了【变量=列表】的表达式,要使用【del list】的形式删除不用的列表变量,避免缓存过多,影响效率。
增
拼接
虽然没有变量的赋值,但是会产生新的列表,没有list.extend()好。
【list1】+【list2】=【list3】:会生成新的列表。


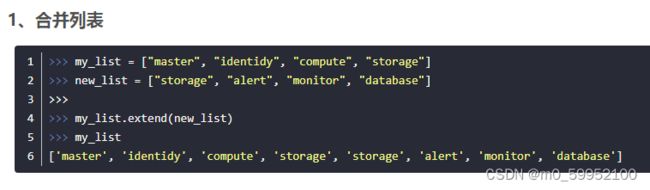
list.append():在列表末尾追加,参数可以是任意对象,包括函数名,如【function()】的【function】。
list.extend():在末尾添加可迭代对象,不可迭代的对象会报错:






list.insert(2,[123]): 在索引2后面添加列表[123],[123]的索引为3,后面元素往后推。
删
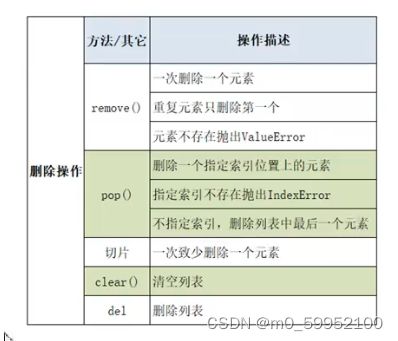
列表的排序
list.sort(): 不产生新列表,对原列表进行排序。
list.sorted(): 对新列表进行排序,原列表不变。
- sort是在原位重新排列列表,无返回值,而sorted()是产生一个新的列表,有返回值
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作


列表生成式
[i*i for i in range(1,10)]
●Dict
ps:dict的key值如果重复了,不会报错,会发生覆盖,谁被覆盖不好说。
d return "李四"
字典(Dict)是可变序列。dict_values、dict_keys、dict_items都是可变的iterator。但是单个key是不可变的。
字典会先对键(key)进行hash变换,再排序。键(key)必须是“不可变的”,如numb,str,tuple。不能是list、set、dict。
字典(Dict)的查询速度不会因为数据的变大而明显变慢,因为就像按部首查字典一样,按hash查value的时间就是固定的步骤,速度是有保证的。
创建字典:
dic=dict()/dic={}: 空字典。
dic=dict("张三"=20,"李四"=40) / {"张三":20,"李四":40}
字典的增删改查
查
age=dic["张三"] #20
age=dic.get("张三") #20 age=dic.get('芳姐',“不存在”) #不写【“不存在”】就返回【none】
增删改
dict.pop(key) 等价于 del dict[key]
字典没有直接修改key的方法。


方法





同理:
items=dict.items() return dict_items([("张三",100),("李四",98),("王五",45)])
type(items) return dict_items
list[items] return [("张三",100),("李四",98),("王五",45)]
字典生成式:
zip() :return zip对象 ,iterable。
zip对象生存周期短,使用list(zip()),或者dict()后就被清空了,仿佛有一个类似zip.clear()的函数被执行。实际该对象没有这个方法。
| list() | 被清空 |
| dict() | 被清空 |
| 报错 | |
| 字典生成式 | 被清空 |
| 打印print | 还在 |
list(zip(iterable1,iterable2)) return [("张三",100),("李四",98),("王五",45)]
dict={key:value for key,value in zip(iterable1,iterable2)}
注意错误的表达{i for i in range(5):j for j in range(j)}
dict=dict(zip(iterable1,iterable2)),zip省略不可以,报错。
执行list(zip(iterable1,iterable2)),zip省略也可以

●tuple

| t=tuple() | 空元组 |
| t=() | 空元组 |
| t=1, | (1,) |
| t=(1,) | (1,) |
| 报错 | |
| 报错 | |
| a=[1,2,3] t=(a,2,4) a.append(5) |
([1,2,3],2,4) ([1,2,3,5],2,4) id并没有变化 |
1、 tuple没有生成式,最多用 t=tuple(i for i in iterator)
●set
set是离了婚的字典dict,既dict.keys,如{1,2,3}
同样有hash变换,同样key不可重复。不可变对象、hashable。
创建集合:
set=set() #set={}是空字典
set=set(iterator) #iterator中不能包含unhashable对象。
| 添加 | ||
| add | 加exactly一个hashable对象 | 否则报错 |
| update | 对集合进行扩展,参数为key的iteaator 类似列表的extend |
否则报错 |
| 删除 | ||
| remove | 删除指定的集合key | 不存在报错 |
| discard | 删除指定的集合key | 不报错 |
| pop | 按print顺序,从左到右依次删除: 如print出来{1,2,3,4},则pop从1~4 |
pop空时报错 |
| clear | 清空集合 | |
| del | 删除集合 | |
| 比较 | ||
| set1.issubset(set2) | set1是set2的子集吗? | bool |
| set1.issuperset(set2) | set1包含set2吗? set1是set2的超集吗? |
bool |
| set1.isdisjoint(set2) | set1和set2没有交集吗? | bool |
| 数学操作 (有相应函数,但难记,跟符号等价) |
||
| A&B |
交集 | 粉色部分 |
| A|B | 并集 | 绿色部分 |
| A-B | 差集 | 蓝色部分 |
| A^B | 对称差集 | 青色部分 |
| 生成式 | ||
| {i for i in iterator} | iterable里必须都是hashable的key |


●进阶数据小结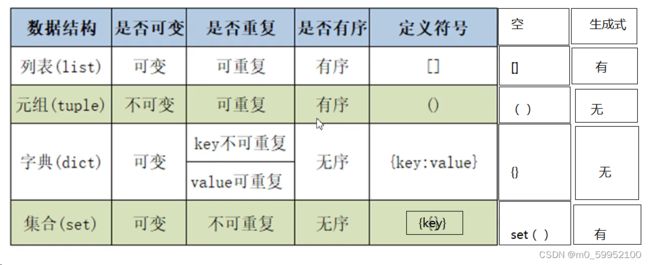
●function(函数)



| 形参 | 实参 | |
| 位置参数 | def func(a,b): pass |
func(10,20)中的10,20 |
| 默认参数 | def func(a,b=20): pass |
func(10),其中,20是默认实参 |
| 关键字实参 | def func(a,b): pass def func(a,b=20): pass def func(*args,**args): pass def func(a,b,*,c,d) |
func(a=10,b=30)中的10/30 *号后面的参数只能采用关键字实参 func(a=1,2,c=3,d=4) |
| args={'a':1,'b':2} | func(**args) | func(a=1,b=2) |
| args=[1,2,3] | func(*args) | func(1,2,3) |
递归函数:
| 1*2*3*4*n | def fac(n): if n==1: return 1 elif n==2: return 2*1【等价2*fac(1)】 elif n==3: return 3*2*1【等价3*fac(2)】 elif n==4: return 4*3*2*1 【等价4*fac(3)】 ........ |
def fac(n): if n==1: return 1 elif n>1: return n*fac(n-1) else: return 'error' |
| 1,1,2,3,5,8 | n<3时,return 1 n>2时,return fac(n-1)+fac(n-2) |
def fac(n): if n<3: return 1 elif n>2: return fac(n-1)+fac(n-2) else: return 'error' |

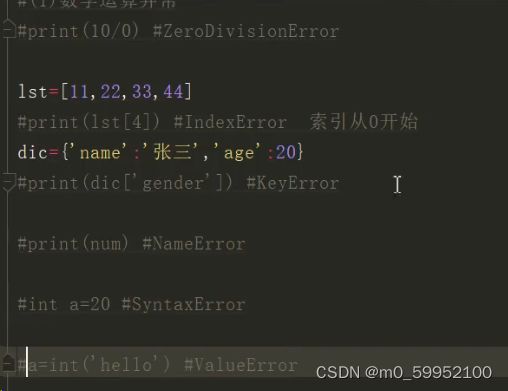
●Python异常处理





●类
类这个对象:


| 类 | ||
| 创建 | class Student: pass |
没() |
| 类名 | 程序员约定:类名Student【各单词】首字母大写 | 标识符(字母、数字、_) |
| 类属性 | class Student: region=‘北京’ |
|
| 实例属性 |
class Student: def __init__(self,name,age): self.name=name self.age=age |
通过__init__ 构造方法 |
| 实例方法 | class Student: def eat(self,b): pass |
2.用类调用实例方法时,self要传参——具体实例 3.用实例对象调用实例方法时,self不用传参。 |
| 类方法 | class Student: @classmethod def eat(cls,b): pass |
1.用类调用类方法时,cls不用传参 2.用实例对象调用类方法时,cls不用传参。 |
| 静态方法 | class Student: @staticmethod def eat(): pass |
无参数 |
| 调用 | ||
| 实例化 | st=Student("张三",20) | |
| 调用实例方法 | st.eat(b) Student.eat(st,b) |
二者等价 类调用时,self要传参 |
| 调用类方法 | st.eat(b) Student.eat(b) |
不用管cls |
| 调用静态方法 | st.eat() Student.eat() |
静态方法个人理解为它既不依赖实例对象也不依赖于类,它只是需要一个载体即可,所以无论是通过类对象直接调用还是实例对象进行调用都是可以的,需要注意的是在静态方法中无法使用实例属性和方法。单纯的工具。 |
| 动态绑定 | class Student: __slots__=(1,2) |
1、类的变化,会引起所有对象的变化 2、一般只对实例对象进行动态绑定 |
| 属性 | st.gender='女' | |
| 方法 | def show(b): pass Student.display=show |
对类动态绑定很少见 |
| 封装 | ||
| 调用不必关心细节 | 一个类就是一个封装 | |
| __; 自觉不要访问 |
self.__name=name def __eat(): pass 私有属性、方法 |
st.__name,报错 st._Student__name,可以 st.__eat(),报错 st._Student__eat(),可以 |
| 继承 | ||
| 多级继承 | 所有对象都继承了object派生类老祖宗,一般省略 | |
| 重写构造方法 | super().__init__(name,age), 意思是 import父类的构造方法 我认为叫补充构造方法更合理,就是在父类构造方法的基础上,补充子类独有的方法、属性 |
 |
| 多继承 | 可以一次继承多个父类 |  |
| 重写实例方法 | 一般是在父类实例方法的基础上,加上自己的一些方法动作。 同样,用super(). 进行调用父类方法,再加上自己的动作。 多个父类,super()改为对应父类名。 |
 |
| object类 | ||
| 类的老祖宗,不写时,默认继承 | 派生类 | |
| dir(类名) | 内置函数,直接可以用 | 可以查看类、实例对象的所有属性,包括私有属性、方法 |
| 重写实例对象描述 | 自定义类,实例化后print,会输出一串 |
重写__str__方法后print,就可以自定义print输出 |
| 多态 | ||
| 鸭子模型 | 使用的时候不关心数据类型,实际上都是对象。python是弱类型。 | 不同对象的属性、方法可以相关(继承),也可以无关 |
| 特殊属性 | ||
| 属性 | 对象.__dict__ | 返回对象的所有属性:name、age。。。 |
| 属性 | 对象.__class__【结果等于】type() | 返回对象的类型 |
| 属性 | 类对象.__bases__ | 返回类对象的所有父类对象 |
| 属性 | 类对象.__base__ | 返回类对象的第一个父类(基类),跟super()很像 |
| 属性 | 类对象.__mro__ | 返回类对象的继承结构,向父类方向 |
| 方法 | 类对象.__subclasses__() | 返回类对象的被继承结构,向子类方向 |
| 方法 | 实例对象a.__add__(实例对象b): a+b,没有该方法的自定义对象,不能相加。 |
 |
| 方法 | 实例对象.__len__(): 没有该方法的自定义对象,不能求len(实例对象)。 |
 |
| 方法 | 实例对象的产生、创建 |
class myclass; def __new__(cls): pass |
| 方法 | 实例对象的初始化 | __init__() |

python是动态语言。 java是静态语言。
●copy
变量赋值:
变量对象cpu1=变量对象cpu2,而变量所指向的所有对象都没有被copy。
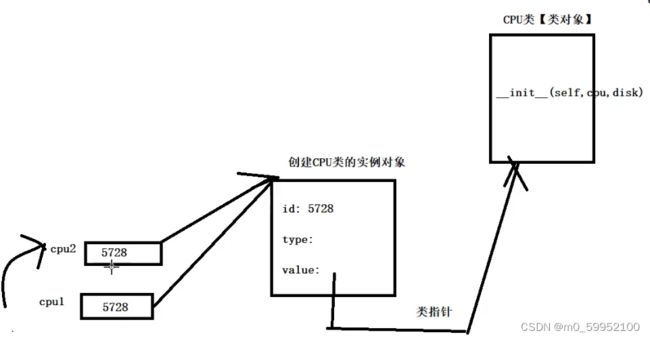
浅拷贝:
import copy
computer2=copy.copy(computer)
只拷贝了主要对象,对象包含的子对象不拷贝,子对象是一样的。

浅拷贝:
import copy
computer2=copy.deepcopy(computer)
把computer包含的所有对象拷贝了一份。

