分布式springcloud
Sentinel 流量组件
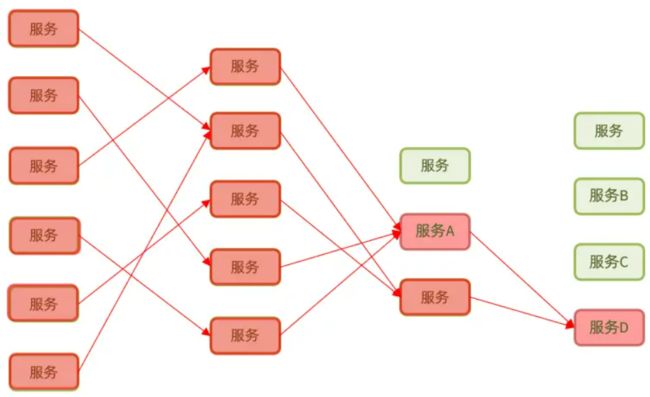
雪崩问题
微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。服务器支持的线程和并发数有限,到来的请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用。
综上,依赖于当前服务的其它服务随着时间的推移,最终也都会变的不可用,形成级联失败,导致整个微服务无法使用,这就是雪崩问题。
解决雪崩问题的常见方式有四种
-
超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。但是当请求速度大于超时时间时,随着时间推移,必然会导致服务器的资源耗尽,没有解决根本问题。
-
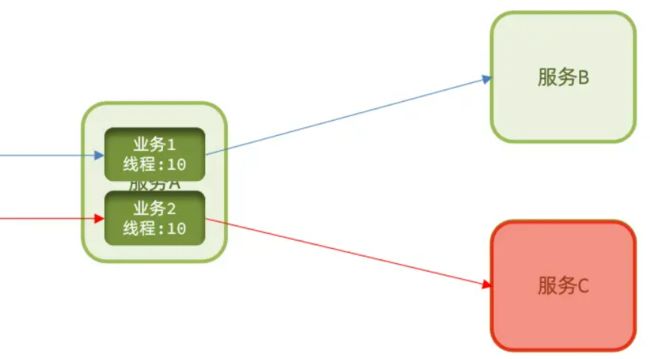
线程隔离:是一种舱壁模式,我们可以限定每个业务能使用的线程数,避免耗尽整个 tomcat 的资源,因此也叫线程隔离。这种模式的问题会空耗服务器资源,服务 C 已经宕机,但是还是有请求不断访问服务 C,空耗资源。
-
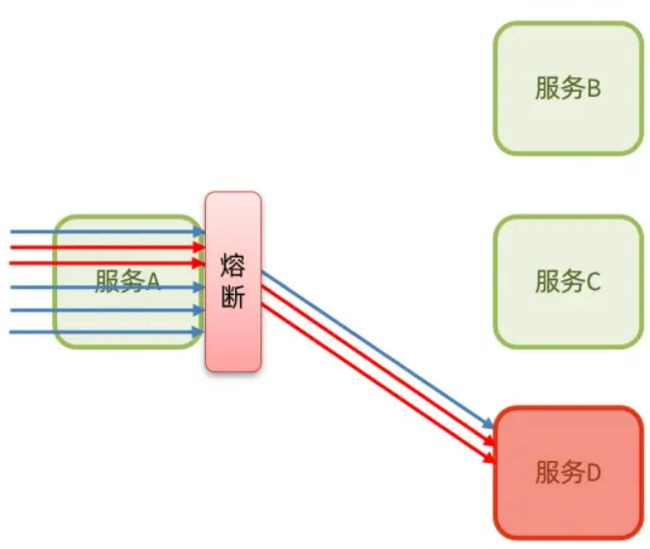
降级熔断:是一种断路器模式,由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
-
限流
流量控制:限制业务访问的 QPS,避免服务因流量的突增而故障。

限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于慢调用比例或异常比例 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
初识 Sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:home | Sentinel
Sentinel 具有以下特征
-
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
-
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
-
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
-
完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
整合 Sentinel
下载后 jar 包后,运行代码:java -jar sentinel-dashboard-1.8.1.jar
如果要修改 Sentinel 的默认端口、账户、密码,可以通过下列配置:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| server.port | 8080 | 服务端口 |
| sentinel.dashboard.auth.username | sentinel | 默认用户名 |
| sentinel.dashboard.auth.password | sentinel | 默认密码 |
例如,修改端口:
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar
我们在 order-service 中整合 Sentinel,并连接 Sentinel 的控制台,步骤如下
1)引入 Sentinel 依赖
com.alibaba.cloud spring-cloud-starter-alibaba-sentinel
2)配置控制台
修改 application.yml 文件,添加下面内容:
server: port: 8088 spring: cloud: sentinel: transport: dashboard: localhost:8080
3)访问 order-service 的任意端点
打开浏览器,访问 http://localhost:10010/order/101,多访问几次,多点几次刷新,这样才能触发 Sentinel 的监控。
然后再访问 Sentinel 的控制台,查看效果。
流量控制
雪崩问题虽有四种方案,但是限流是避免服务因突发的流量而发生故障,是对微服务雪崩问题的预防。
限流算法
1、滑动窗口
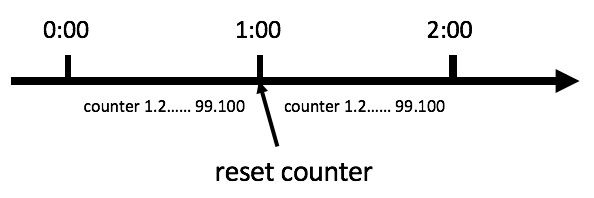
在介绍滑动窗口之前,先介绍一种计数器算法
计数器算法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:
这个算法虽然简单,但是有一个十分致命的问题,那就是临界问题:
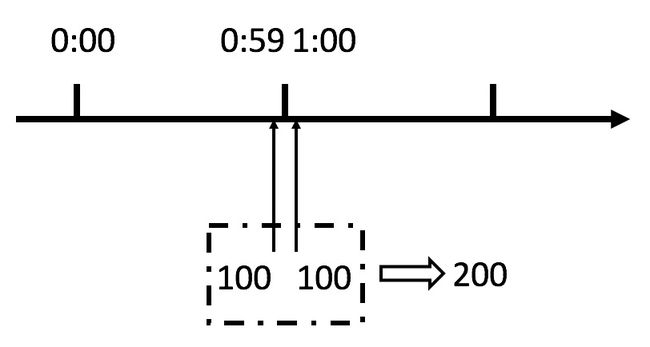
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
刚才的问题其实是因为我们统计的精度太低,为了解决这个问题,引出滑动窗口算法。
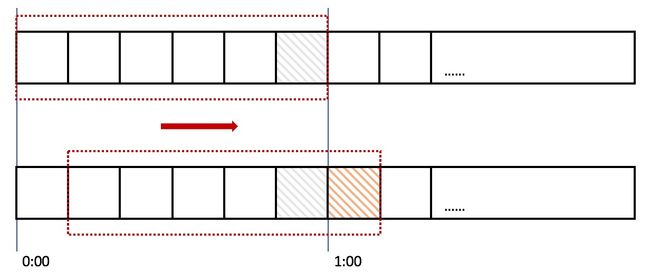
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟,一分钟内最大访问数为 100,即一个时间窗口的最大访问数为 100。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口 划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
同样是临界问题,若0:59到达的100个请求落在灰色的格子中,而1:00到达的请求落在橘黄色的格 子中。当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触 发了限流。
我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
2、令牌桶算法
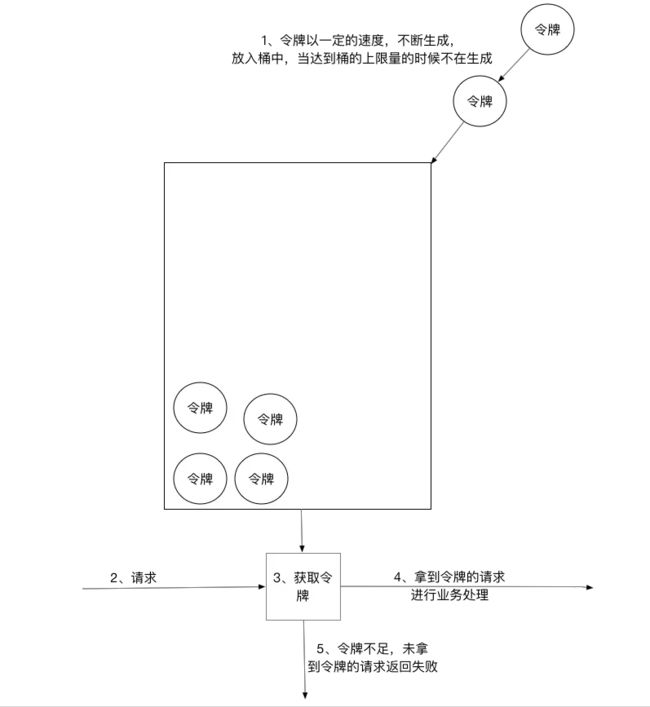
按一定额定的速率产生令牌,存入令牌桶,桶有最大容量(应该为微服务最大承载);服务过来时需要请求到一个令牌才可以进入服务执行;服务里就可以保持基本不会超过承载值。【保护服务】
1)、所有的请求在处理之前都需要拿到一个可用的令牌才会被处理; 2)、根据限流大小,设置按照一定的速率往桶里添加令牌; 3)、桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝; 4)、请求达到后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务逻辑,处理完业务逻辑之后,将令牌直接删除; 5)、令牌桶有最低限额,当桶中的令牌达到最低限额的时候,请求处理完之后将不会删除令牌,以此保证足够的限流;
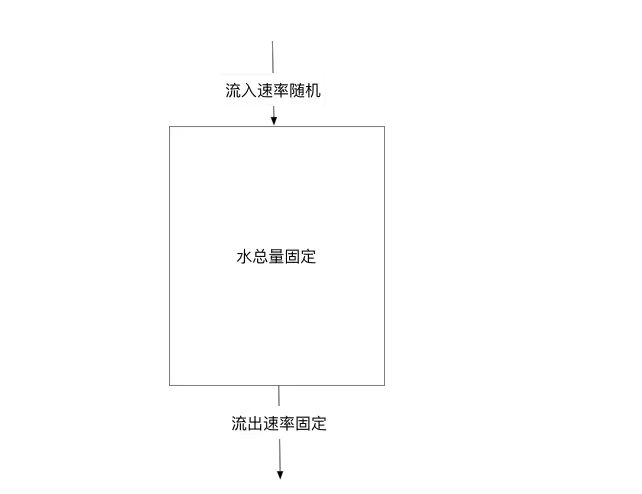
3、漏桶算法
维持一个队列,所有请求先进队列,然后从队列取出请求的速率是固定。【保护请求】
漏桶算法其实很简单,可以粗略的认为就是注水漏水过程,往桶中以一定速率流出水,以任意速率流入水,当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。漏桶算法存在一个缺陷,无法应对短时间的突发流量,比如双十一抢购、秒杀活动开始。
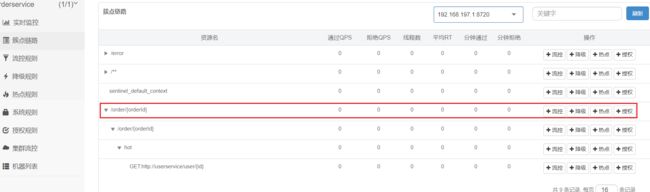
簇点链路
当请求进入微服务时,首先会访问 DispatcherServlet,然后进入 Controller、Service、Mapper,这样的一个调用链就叫做 簇点链路。
簇点链路中被监控的每一个接口就是一个资源。默认情况下 Sentinel 会监控 SpringMVC 的每一个端点(Endpoint,也就是 Controller 中的方法),因此 SpringMVC 的每一个端点(Endpoint)就是调用链路中的一个资源。
例如,我们刚才访问的 order-service 中的 OrderController 中的端点:/order/{orderId}
流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则:
-
流控:流量控制
-
降级:降级熔断
-
热点:热点参数限流,是限流的一种
-
授权:请求的权限控制
点击资源 /order/{orderId} 后面的流控按钮,就可以弹出表单。

其含义是限制 /order/{orderId} 这个资源的单机 QPS 为 1,即每秒只允许 1 次请求,超出的请求会被拦截并报错。
流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式
-
直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
-
直接对当前资源限流
-
-
关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
-
相当于高优先级资源触发阈值,对低优先级资源限流。
-
-
链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
直接模式
统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
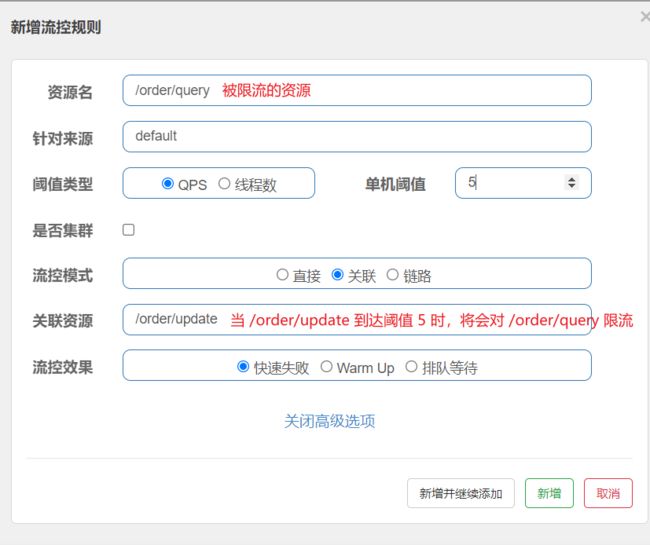
关联模式
统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流。
使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是优先支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
满足下面条件可使用关联模式:
-
两个有竞争关系的资源
-
一个优先级高,一个优先级低
链路模式
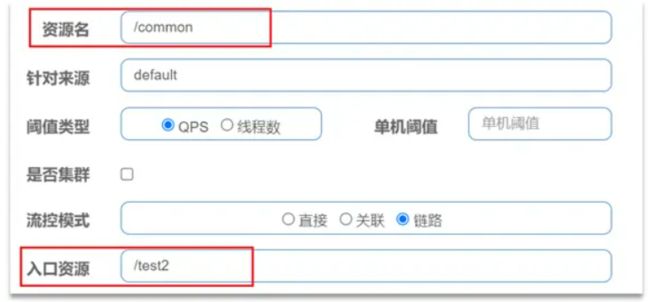
只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
例如有两条请求链路
-
/test1 --> /common
-
/test2 --> /common
如果只希望统计从 /test2 进入到 /common 的请求,则可以这样配置
默认情况下,OrderService 中的方法是不被 Sentinel 监控的,需要我们自己通过注解来标记要监控的方法。
给 OrderService 的 queryGoods 方法添加 @SentinelResource 注解。
@SentinelResource("goods")
public void queryGoods(){
System.err.println("查询商品");
}
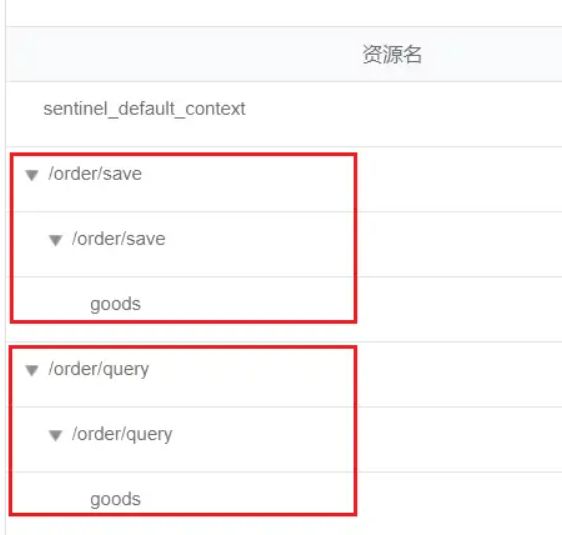
链路模式中,是对不同来源的两个链路做监控。但是 Sentinel 默认会给进入 SpringMVC 的所有请求设置同一个 root 资源,会导致链路模式失效。我们需要关闭这种对 SpringMVC 的资源聚合,修改 order-service 服务的 application.yml 文件
spring: cloud: sentinel: web-context-unify: false # 关闭context整合
重启服务,访问 /order/query 和 /order/save,可以查看到 Sentinel 的簇点链路规则中,出现了新的资源
添加新的流控规则如下
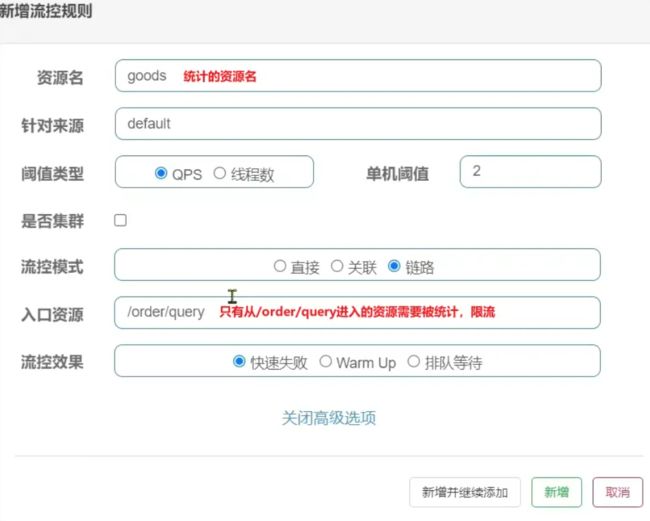
只统计从 /order/query 进入 /goods 的资源,QPS 阈值为 2,超出则被限流。
流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种
-
快速失败:达到阈值后,新的请求会被立即拒绝并抛出 FlowException 异常,是默认的处理方式。滑动时间窗口算法
-
Warm Up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。漏桶算法
-
排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长。令牌桶算法
快速失败
超过设置的 QPS 直接拒绝
Warm up
阈值一般是一个微服务能承担的最大 QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将 QPS 跑到最大值,可能导致服务瞬间宕机。
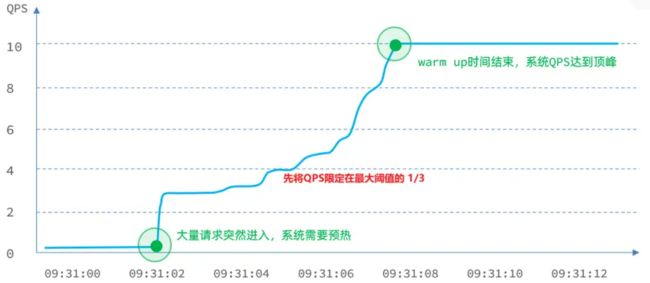
Warm Up 也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 maxThreshold / coldFactor,持续指定时长后,逐渐提高到 maxThreshold 值。而 coldFactor 的默认值是 3.
例如,我设置 QPS 的 maxThreshold 为 10,预热时间为 5 秒,那么初始阈值就是 10 / 3 = 3,然后在 5 秒后逐渐增长到 10
排队等待
当请求超过 QPS 阈值时,「快速失败」和 「Warm Up」会拒绝新的请求并抛出异常。
而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。这种方式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
例如:QPS = 5,意味着每 200ms 处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过 2000ms 的请求会被拒绝并抛出异常。
比如现在一下子来了 12 个请求,因为每 200ms 执行一个请求,那么预期等待时长就是:
-
第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
-
第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
又比如下图:
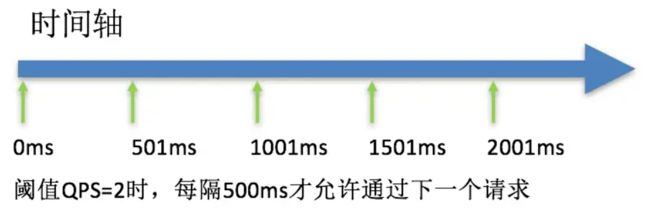
现在,第 1 秒同时接收到 10 个请求,但第 2 秒只有 1 个请求,此时 QPS 的曲线这样的
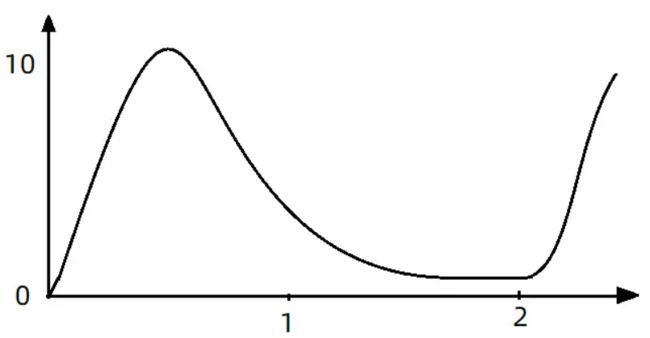
如果使用排队等待的流控效果,所有进入的请求都要排队,以固定的 200ms 的间隔执行,QPS 会变的很平滑
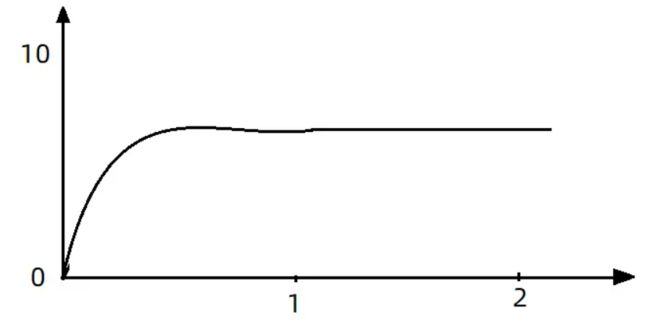
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。起到了流量整形效果。
热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过 QPS 阈值。而「热点参数限流」是分别统计参数值相同的请求,判断是否超过 QPS 阈值。
全局参数限流
例如,一个根据 id 查询商品的接口
访问/goods/{id} 的请求中,id 参数值会有变化,「热点参数限流」会根据参数值分别统计 QPS,统计结果:

当 id=1 的请求触发阈值被限流时,id值不为1的请求则不受影响。
配置示例:对 hot 这个资源的 0 号参数(也就是第一个参数)做统计,每 1s 相同参数值的请求数不能超过 5
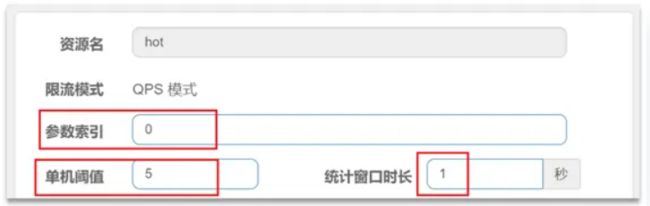
热点参数限流
在实际开发中,可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的 QPS 限制与其它商品不一样,高一些。那就需要配置「热点参数限流」的高级选项了。
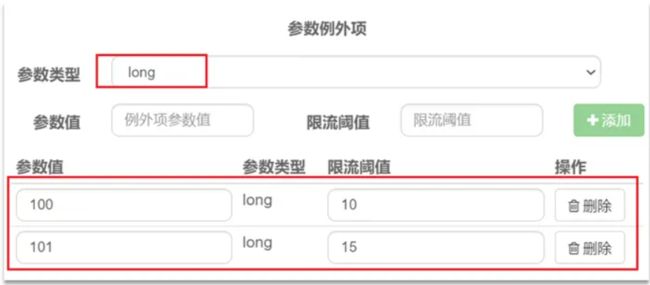
结合上一个配置,这里的含义是对 0 号的 long 类型参数限流,每 1 个相同参数的 QPS 不能超过 5,有如下两个例外
-
如果参数值是 100,则每 1s 允许的 QPS 为 10
-
如果参数值是 101,则每 1s 允许的 QPS 为 15
注意事项:热点参数限流对默认的 SpringMVC 资源无效,需要利用 @SentinelResource 注解在 controller 对应方法上标记资源。

隔离和降级
限流只是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。Sentinel 支持的雪崩解决方案为线程隔离和熔断降级。
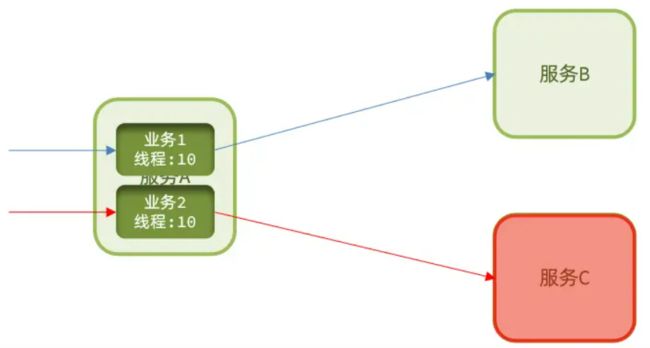
线程隔离:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
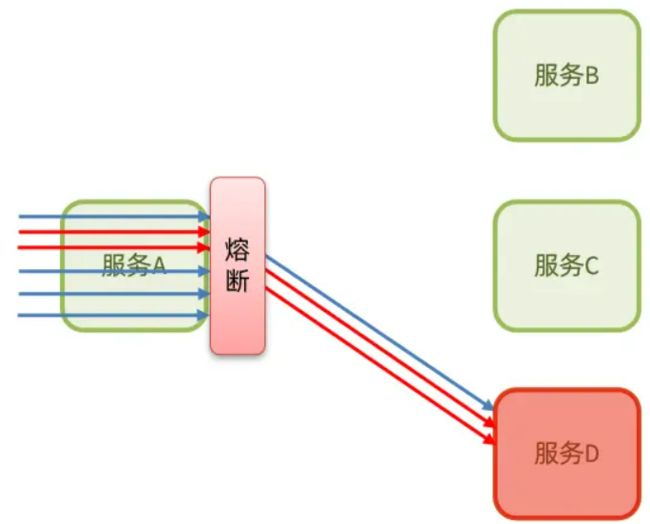
可以看到,不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。需要在调用方发起远程调用时做线程隔离、或者服务熔断。
而我们的微服务远程调用都是基于 Feign 来完成的,因此我们需要将 Feign 与 Sentinel 整合,在 Feign 里面实现线程隔离和服务熔断。
Feign 整合 Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合 Feign 和 Sentinel
修改配置,开启 Sentinel 功能,修改 OrderService 的 application.yml 文件,开启 Feign 的 Sentinel 功能
feign: sentinel: enabled: true # 开启feign对sentinel的支持
服务降级:访问失败后,服务编写失败降级逻辑代码,业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给 FeignClient 编写失败后的降级逻辑
①方式一:FallbackClass,但无法对远程调用的异常做处理。
②方式二:FallbackFactory,可以对远程调用的异常做处理,通常使用这种
步骤一:
编写 FallbackFactory 接口的实现类 UserClientFallbackFactory
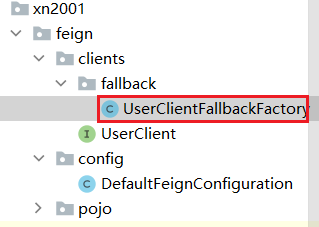
@Slf4j public class UserClientFallbackFactory implements FallbackFactory{ @Override public UserClient create(Throwable throwable) { return userClient -> { log.error("查询用户失败",throwable); return new User(); }; } }
步骤二:
将 UserClientFallbackFactory 注册为 bean
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}
步骤三:
在 client 接口上添加 fallbackFactory 选项
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
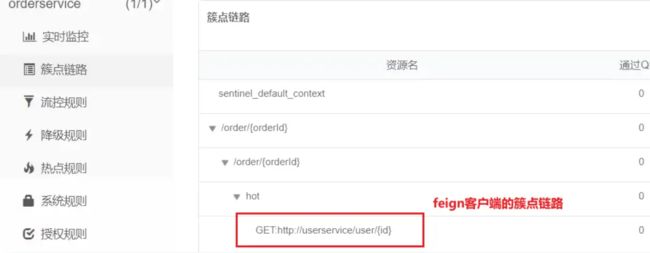
线程隔离
线程隔离(舱壁模式)有两种方式实现
-
线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果。
-
信号量隔离(Sentinel默认采用):不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
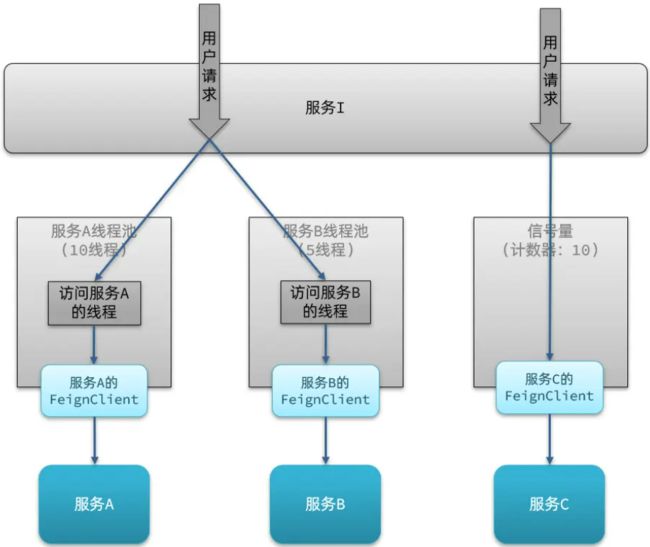
两者的优缺点
-
线程池隔离:基于线程池模式,有额外开销,但隔离控制更强
-
信号量隔离:基于计数器模式,简单,开销小
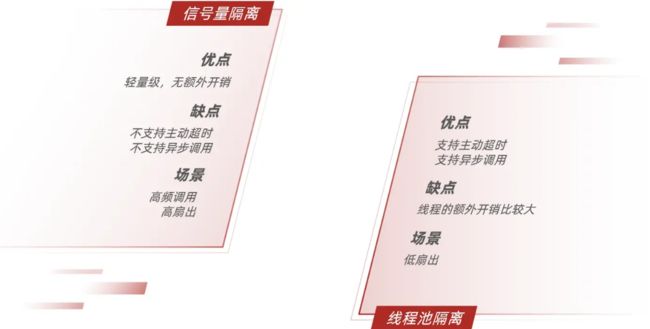
Sentinel 使用的是信号量隔离,而 Hystrix 则两种线程隔离都可以,18 年Hystrix已经停止更新。
如何使用呢,在添加限流规则时,可以选择两种阈值类型
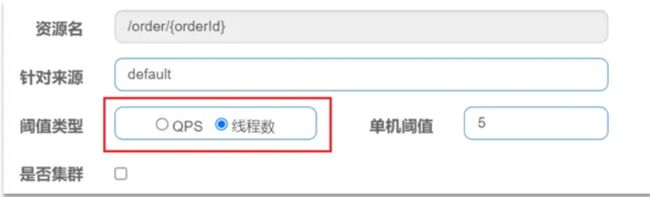
-
QPS:就是每秒的请求数,之前已经演示过。
-
线程数:是该资源能使用的 Tomcat 线程数的最大值。也就是通过限制线程数量,实现线程隔离(舱壁模式)。
熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
断路器控制熔断和放行是通过状态机来完成的,如下图就是一个断路器的状态机
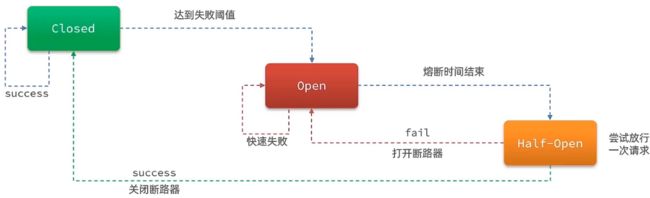
状态机包括三个状态
-
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。会去判断是否达到熔断条件,这一步我们叫做「熔断策略」,达到该条件则切换到 open 状态,打开断路器。
-
open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open 状态 5 秒后会进入 half-open 状态。
-
half-open:半开状态,会一段时间放行一次请求,根据执行结果来判断接下来的操作。请求成功:则切换到 closed 状态;请求失败:则切换到 open 状态。
断路器熔断策略有三种:慢调用、异常比例、异常数
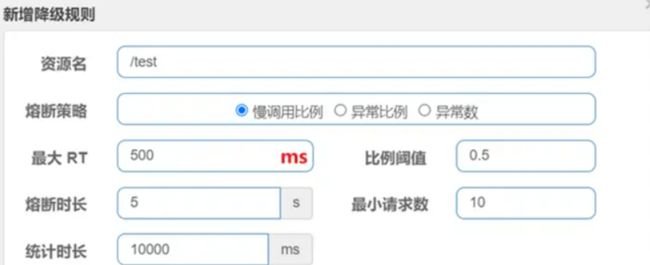
慢调用
业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
例如下图,设置 RT 超过 500ms 的调用是慢调用,统计最近 10000ms 内的请求,如果请求量超过 10 次,并且慢调用比例不低于 0.5,则触发熔断,熔断时长为 5s,然后进入 half-open 状态,放行一次请求做测试。
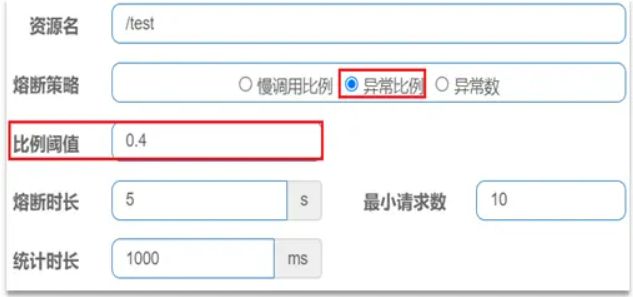
异常
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
例如,异常比例设置如下,统计最近 1000ms 内的请求,如果请求量超过 10 次,并且异常比例不低于 0.4,则触发熔断。
异常数设置如下,统计最近 1000ms 内的请求,如果请求量超过 10 次,并且异常数不低于 2 次,则触发熔断。

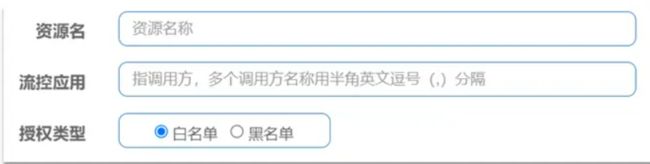
授权规则
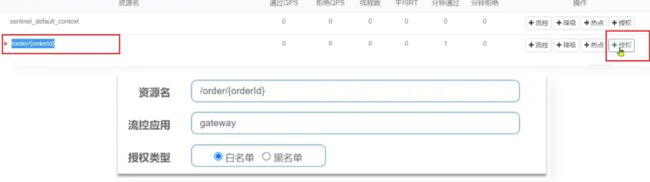
之前在 SpringCloud 网关中,可通过网关来判断访问是否可通行,但是若微服务的内部地址泄露,直接通过地址访问,便绕过了网关,这时网关无法判断。授权规则可以对请求方来源做判断和控制。授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
比如我们希望控制对资源 test 的访问设置白名单,只有来源为 appA 和 appB 的请求才可通过。
-
白名单:来源(origin)在白名单内的调用者允许访问
-
黑名单:来源(origin)在黑名单内的调用者不允许访问
点击左侧菜单的授权,可以看到授权规则
-
资源名:就是受保护的资源,例如 /order/{orderId}
-
流控应用:是来源者的名单
-
如果是勾选白名单,则名单中的来源被许可访问。
-
如果是勾选黑名单,则名单中的来源被禁止访问。
-
比如我们允许请求从 gateway 到 order-service,不允许浏览器访问 order-service,那么白名单中就要填写网关的来源名称(origin)。

Sentinel 是通过 RequestOriginParser 这个接口的 parseOrigin() 方法来获取请求的来源的。
这个方法的作用就是从 request 对象中,获取请求者的 origin 值并返回。默认情况下,Sentinel 不管请求者从哪里来,返回值永远是 default,也就是说一切请求的来源都被认为是一样的值 default
因此,我们需要自定义这个接口的实现,让不同的请求,返回不同的 origin
例如 order-service 服务中,我们定义一个 RequestOriginParser 的实现类
@Component
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
// 1.获取请求头
String origin = request.getHeader("origin");
// 2.非空判断
if (StringUtils.isEmpty(origin)) {
origin = "blank";
}
return origin;
}
}
我们必须让所有从 Gateway 路由到微服务的请求都带上 origin 头。这个需要利用之前学习的一个 GatewayFilter 来实现,使用 AddRequestHeaderGatewayFilter,修改 Gateway 服务中的 application.yml
spring:
cloud:
gateway:
default-filters:
- AddRequestHeader=origin,gateway #origin前面不能带空格,这表示 origin 的值为 gateway
这样,从 Gateway 路由的所有请求都会带上 origin 头,值为 gateway。而从其它地方到达微服务的请求一般没有这个头。
接下来,我们添加一个授权规则,放行 origin 值为 gateway 的请求。那么跳过网关直接访问将会被 Sentinel 拦截,通过网关访问的将会放行。
自定义异常结果
默认情况下,发生限流、降级、授权拦截时,都会抛出异常到调用方。异常结果都是 flow limmiting(限流)。这样不够友好,无法得知是限流还是降级还是授权拦截。
而如果要自定义异常时的返回结果,需要实现 BlockExceptionHandler 接口
public interface BlockExceptionHandler {
/**
* 处理请求被限流、降级、授权拦截时抛出的异常:BlockException
*/
void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception;
}
这个方法有三个参数:
-
HttpServletRequest request:request 对象
-
HttpServletResponse response:response 对象
-
BlockException e:被 Sentinel 拦截时抛出的异常
这里的 BlockException 包含多个不同的子类
| 异常 | 说明 |
|---|---|
| FlowException | 限流异常 |
| ParamFlowException | 热点参数限流的异常 |
| DegradeException | 降级异常 |
| AuthorityException | 授权规则异常 |
| SystemBlockException | 系统规则异常 |
自定义异常处理,下面我们就在 order-service 定义一个自定义异常处理类
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知异常";
int status = 429;
if (e instanceof FlowException) {
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
status = 401;
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");
}
}
规则持久化
现在,Sentinel 的所有规则都是内存存储,重启后所有规则都会丢失。在生产环境下,我们必须确保这些规则的持久化,避免丢失。
规则是否能持久化,取决于规则管理模式,Sentinel 支持三种规则管理模式
-
原始模式:Sentinel 的默认模式,将规则保存在内存,重启服务会丢失。
-
pull 模式
-
push 模式
pull模式
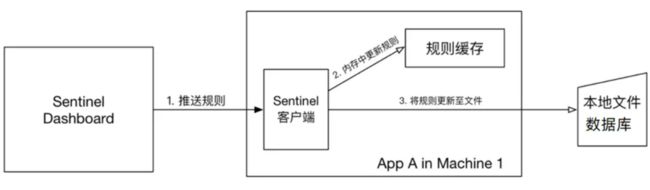
pull 模式:控制台将配置的规则推送到 Sentinel 客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
push模式
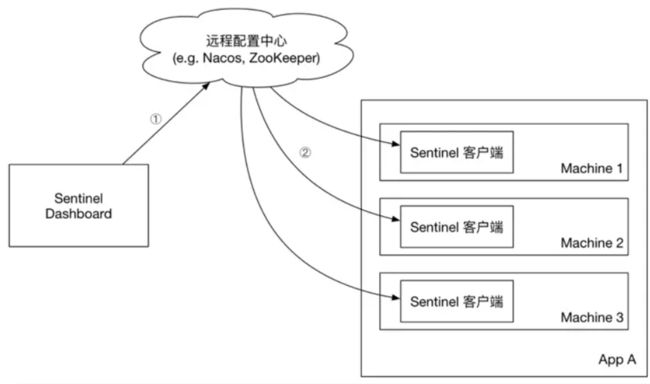
push 模式:控制台将配置规则推送到远程配置中心,例如 Nacos,Sentinel 客户端监听 Nacos,获取配置变更的推送消息,完成本地配置更新。这种模式是比较好的一种。
分布式事务
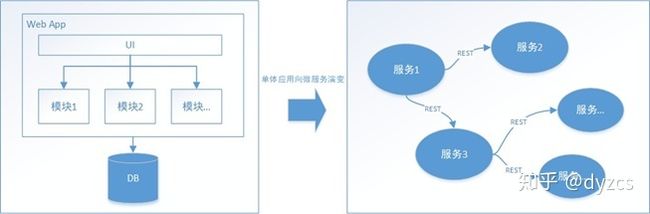
概述
随着互联网的快速发展,软件系统由原来的单体应用转变为分布式应用,下图描述了单体应用向微服务的演变:
分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间远程协作才能完成事务操作,这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务,例如用户注册送积分事务、创建订单减库存事务,银行转账事务等都是分布式事务。
在分布式环境下,如下场景:
begin transaction;
//1.本地数据库操作:张三减少金额
//2.远程调用:让李四增加金额
commit transation;
可以设想,当远程调用让李四增加金额成功了,由于网络问题远程调用并没有返回,此时本地事务提交失败就回滚了张三减少金额的操作,此时张三和李四的数据就不一致了。
分布式事务产生的场景
1、跨JVM进程产生分布式事务
典型的场景就是微服务架构:微服务之间通过远程调用完成事务操作。比如:订单微服务和库存微服务,下单的同时订单微服务请求库存微服务减少库存。
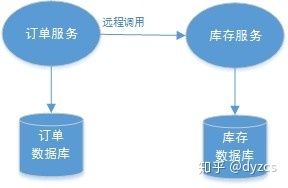
2、跨数据库实例产生分布式事务
单体系统访问多个数据库实例当单体系统需要访问多个数据库(实例)时就会产生分布式事务。比如:用户信息和订单信息分别在两个MySQL实例存储。
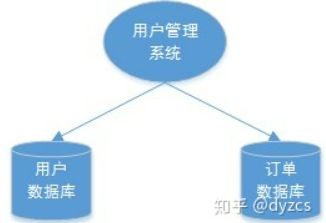
3、多服务访问同一个数据库实例
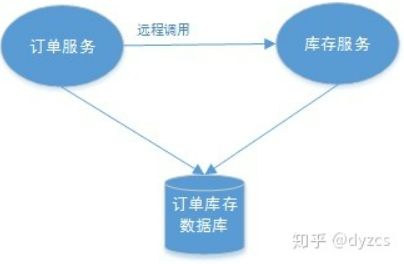
订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是跨JVM进程,两个微服务持有了不同的数据库链接进行数据库操作,此时产生分布式事务。
分布式事务基础理论
CAP理论
CAP 是 Consistency、Availability、Partition tolerance 三个单词的缩写,分别表示一致性、可用性、分区容忍性。
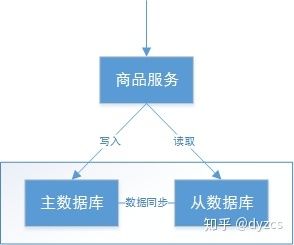
如下图,是商品信息管理的执行流程:
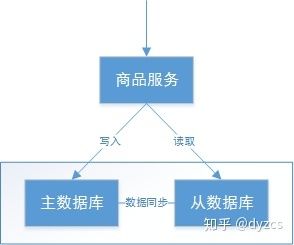
整体执行流程如下
-
商品服务请求主数据库写入商品信息(添加商品、修改商品、删除商品)
-
主数据库向商品服务响应写入成功
-
商品服务请求从数据库读取商品信息
C - Consistency
一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
上图中,商品信息的读写要满足一致性就是要实现如下目标:
-
商品服务写入主数据库成功,则向从数据库查询新数据也成功。
-
商品服务写入主数据库失败,则向从数据库查询新数据也失败。
如何实现一致性?
-
写入主数据库后要将数据同步到从数据库。
-
写入主数据库后,在向从数据库同步期间要将从数据库锁定,待同步完成后再释放锁,以免在新数据写入成功后,从数据库查询到旧的数据。
分布式系统一致性的特点:
-
由于存在数据同步的过程,写操作的响应会有一定的延迟。
-
为了保证数据一致性会对资源暂时锁定,待数据同步完成释放锁定资源。
-
对于请求数据同步失败的结点则会返回错误信息,一定不会返回旧数据。
A - Availability
可用性是指任何事务操作都可以得到响应结果,且不会出现响应超时或响应错误。
上图中,商品信息读取满足可用性就是要实现如下目标:
-
从数据库接收到数据查询的请求则立即能够响应数据查询结果。
-
从数据库不允许出现响应超时或响应错误。
如何实现可用性
-
写入主数据库后要将数据同步到从数据库。
-
由于要保证从数据库的可用性,不可将从数据库中的资源进行锁定。
-
即时数据还没有同步过来,从数据库也要返回要查询的数据,哪怕是旧数据,如果连旧数据也没有则可以按照约定返回一个默认信息,但不能返回错误或响应超时。
分布式系统可用性的特点:所有请求都有响应,且不会出现响应超时或响应错误
P - Partition tolerance
通常分布式系统的各个结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务,这叫分区容忍性。
上图中,商品信息读写满足分区容忍性就是要实现如下目标:
-
主数据库向从数据库同步数据失败不影响读写操作。
-
其一个结点挂掉不影响另一个结点对外提供服务。
如何实现分区容忍性?
-
尽量使用异步取代同步操作,例如使用异步方式将数据从主数据库同步到从数据,这样结点之间能有效的实现松耦合。
-
添加从数据库结点,其中一个从结点挂掉其它从结点提供服务。
分布式分区容忍性的特点:分区容忍性分是分布式系统具备的基本能力
CAP 组合方式
在所有分布式事务场景中不会同时具备 CAP 三个特性,因为在具备了P的前提下C和A是不能共存的
满足分区容忍性,含义是:
-
主数据库通过网络向从数据库同步数据,可以认为主从数据库部署在不同的分区,通过网络进行交互。
-
当主数据库和从数据库之间的网络出现问题不影响主数据库和从数据库对外提供服务。
-
其中一个节点挂掉不影响另一个节点对外提供服务。
如果要实现 C 则必须保证数据一致性,在数据同步的时候为防止向从数据库查询不一致的数据则需要将从数据库数据锁定,待同步完成后解锁,如果同步失败从数据库要返回错误信息或超时信息。
如果要实现 A 则必须保证数据可用性,在主数据库向从数据库进行同步信息时不能加同步锁,不管任何时候都可以向从数据查询数据,则不会响应超时或返回错误信息。通过分析发现在满足P的前提下 C 和 A 存在矛盾性。
-
AP 放弃一致性,追求分区容忍性和可用性。这是很多分布式系统设计时的选择。 例如:上边的商品管理,完全可以实现 AP,前提是只要用户可以接受所查询到的数据在一定时间内不是最新的即可。 通常实现 AP 都会保证最终一致性,后面将的 BASE 理论就是根据 AP 来扩展的,一些业务场景比如:订单退款,今日退款成功,明日账户到账,只要用户可以接受在一定的时间内到账即可。
-
CP 放弃可用性,追求一致性和分区容错性,zookeeper 其实就是追求的强一致,又比如跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成。
-
CA 放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,则可以实现一致性和可用性。那么系统将不是一个标准的分布式系统,最常用的关系型数据就满足了 CA。
CAP 是一个已经被证实的理论,一个分布式系统最多只能同时满足:一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项。对于多数大型互联网应用的场景,结点众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,要达到良好的响应性能来提高用户体验,因此一般都会做出如下选择:保证 P 和 A ,舍弃 C 强一致,保证最终一致性。
BASE 理论
强一致性和最终一致性
CAP 理论告诉我们一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项,其中AP在实际应用中较多,AP 即舍弃一致性,保证可用性和分区容忍性,但是在实际生产中很多场景都要实现一致性,比如前边我们举的例子主数据库向从数据库同步数据,即使不要一致性,但是最终也要将数据同步成功来保证数据一致,这种一致性和 CAP 中的一致性不同,CAP 中的一致性要求 在任何时间查询每个结点数据都必须一致,它强调的是强一致性,但是最终一致性是允许可以在一段时间内每个结点的数据不一致,但是经过一段时间每个结点的数据必须一致,它强调的是最终数据的一致性。
Base 理论介绍
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。BASE 理论是对 CAP 中 AP 的一个扩展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用但要保证核心功能可用,允许数据在一段时间内是不一致的,但最终达到一致状态。满足BASE理论的事务,我们称之为“柔性事务”。
-
基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如电商网站交易付款出现问题了,商品依然可以正常浏览。
-
软状态:由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性,如订单的"支付中"、“数据同步中”等状态,待数据最终一致后状态改为“成功”状态。
-
最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。如订单的"支付中"状态,最终会变 为“支付成功”或者"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
分布式事务解决方案 2PC
原理
针对不同的分布式场景业界常见的解决方案有 2PC、3PC、TCC、可靠消息最终一致性、最大努力通知这几种。
2PC 即两阶段提交协议,是将整个事务流程分为两个阶段,准备阶段(Prepare phase)、提交阶段(commit phase),2 是指两个阶段,P 是指准备阶段,C 是指提交阶段。
举例:张三和李四好久不见,老友约起聚餐,饭店老板要求先买单,才能出票。这时张三和李四分别抱怨近况不如意,囊中羞涩,都不愿意请客,这时只能AA。只有张三和李四都付款,老板才能出票安排就餐。但由于张三和李四都是铁公鸡,形成了尴尬的一幕:
准备阶段:老板要求张三付款,张三付款。老板要求李四付款,李四付款。
提交阶段:老板出票,两人拿票纷纷落座就餐。
例子中形成了一个事务,若张三或李四其中一人拒绝付款,或钱不够,店老板都不会给出票,并且会把已收款退回。
整个事务过程由事务管理器和参与者组成,店老板就是事务管理器,张三、李四就是事务参与者,事务管理器负责决策整个分布式事务的提交和回滚,事务参与者负责自己本地事务的提交和回滚。
在计算机中部分关系数据库如 Oracle、MySQL 支持两阶段提交协议,如下图:
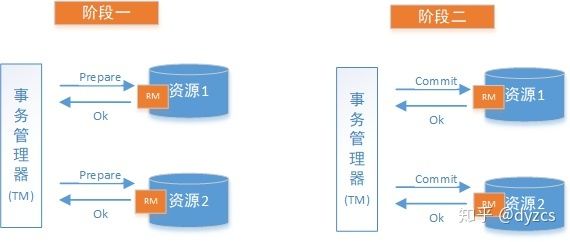
-
准备阶段(Prepare phase):事务管理器给每个参与者发送 Prepare 消息,每个数据库参与者在本地执行事务,并写本地的 Undo/Redo 日志,此时事务没有提交。(Undo 日志是记录修改前的数据,用于数据库回滚,Redo 日志是记录修改后的数据,用于提交事务后写入数据文件)
-
提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源。注意:必须在最后阶段释放锁资源。
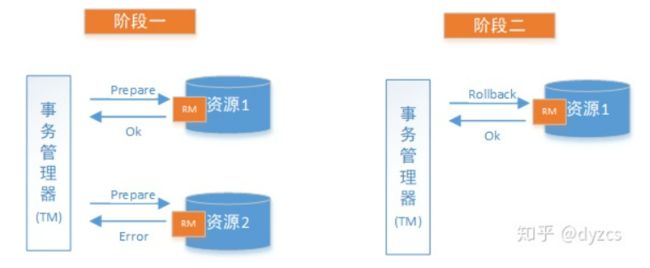
下图展示了2PC的两个阶段,分成功和失败两个情况说明:
成功情况
失败情况
解决方案
XA 方案
2PC 的传统方案是在数据库层面实现的,如 Oracle、MySQL 都支持 2PC 协议。国际开放标准组织 Open Group 定义了分布式事务处理模型 DTP。
以新用户注册送积分为例:
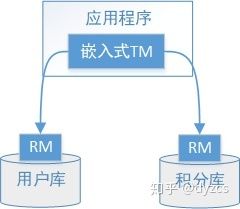
执行流程如下:
-
应用程序(AP)持有用户库和积分库两个数据源。
-
应用程序(AP)通过 TM 通知用户库 RM 新增用户,同时通知积分库RM为该用户新增积分,RM 此时并未提交事务,此时用户和积分资源锁定。
-
TM 收到执行回复,只要有一方失败则分别向其他 RM 发起回滚事务,回滚完毕,资源锁释放。
-
TM 收到执行回复,全部成功,此时向所有 RM 发起提交事务,提交完毕,资源锁释放。
DTP 模型定义如下角色:
-
AP(Application Program):即应用程序,可以理解为使用 DTP 分布式事务的程序。
-
RM(Resource Manager):即资源管理器,可以理解为事务的参与者,一般情况下是指一个数据库实例,通过资源管理器对该数据库进行控制,资源管理器控制着分支事务。
-
TM(Transaction Manager):事务管理器,负责协调和管理事务,事务管理器控制着全局事务,管理事务生命周期,并协调各个 RM。全局事务是指分布式事务处理环境中,需要操作多个数据库共同完成一个工作,这个工作即是一个全局事务。
DTP 模型定义TM和RM之间通讯的接口规范叫 XA,简单理解为数据库提供的 2PC 接口协议,基于数据库的 XA 协议来实现 2PC 又称为 XA 方案
以上三个角色之间的交互方式如下:
-
TM 向 AP 提供 应用程序编程接口,AP 通过 TM 提交及回滚事务。
-
TM 交易中间件通过 XA 接口来通知 RM 数据库事务的开始、结束以及提交、回滚等。
总结
整个 2PC 的事务流程涉及到三个角色 AP、RM、TM。AP 指的是使用 2PC 分布式事务的应用程序;RM 指的是资源管理器,它控制着分支事务;TM 指的是事务管理器,它控制着整个全局事务。
(1)准备阶段: RM 执行实际的业务操作,但不提交事务,资源锁定
(2)提交阶段: TM 会接受 RM 在准备阶段的执行回复,只要有任一个RM执行失败,TM 会通知所有 RM 执行回滚操作,否则,TM 将会通知所有 RM 提交该事务。提交阶段结束资源锁释放。
XA方案的问题
-
需要本地数据库支持XA协议。
-
资源锁需要等到两个阶段结束才释放,性能较差。
Seata 方案
Seata 是由阿里中间件团队发起的开源项目 Fescar,后更名为 Seata,它是一个开源的分布式事务框架。
传统 2PC 的问题在 Seata 中得到了解决,它通过对本地关系数据库的分支事务的协调来驱动完成全局事务,是工作在应用层的中间件。主要优点是性能较好,且不长时间占用连接资源,它以高效并且对业务 0 侵入的方式解决微服务场景下面临的分布式事务问题,它目前提供 AT 模式(即 2PC)及 TCC 模式的分布式事务解决方案。
Seata 的设计思想如下:
Seata 把一个分布式事务理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系数据库的本地事务,下图是全局事务与分支事务的关系图:
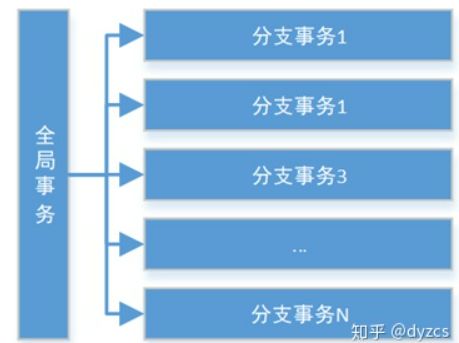
与传统 2PC 的模型类似,Seata 定义了 3 个组件来协议分布式事务的处理过程:
-
Transaction Coordinator(TC):事务协调器,它是独立的中间件,需要独立部署运行,它维护全局事务的运行状态,接收 TM 指令发起全局事务的提交与回滚,负责与 RM 通信协调各各分支事务的提交或回滚。
-
Transaction Manager(TM): 事务管理器,TM 需要嵌入应用程序中工作,它负责开启一个全局事务,并最终向 TC 发起全局提交或全局回滚的指令。
-
Resource Manager(RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器 TC 的指令,驱动分支(本地)事务的提交和回滚。
Seata实现2PC与传统2PC的差别:
架构层次方面:传统 2PC 方案的 RM 实际上是在数据库层,RM 本质上就是数据库自身,通过 XA 协议实现,而 Seata 的 RM 是以 jar 包的形式作为中间件层部署在应用程序这一侧的。
两阶段提交方面:传统 2PC无论第二阶段的决议是 commit 还是 rollback ,事务性资源的锁都要保持到 Phase2 完成才释放。而 Seata 的做法是在 Phase1 就将本地事务提交,这样就可以省去 Phase2 持锁的时间,整体提高效率。
小结
对于传统 2PC(基于数据库 XA 协议)和 Seata 实现 2PC 的两种方案,于 Seata 的 0 侵入性并且解决了传统 2PC 长期锁资源的问题,推荐采用 Seata 实现 2PC。
分布式事务解决方案 TCC
原理
TCC 是 Try、Confirm、Cancel 三个词语的缩写,TCC 要求每个分支事务实现三个操作:预处理 Try、确认 Confirm、撤销 Cancel。Try 操作做业务检查及资源预留,Confirm 做业务确认操作,Cancel 实现一个与 Try 相反的操作即回滚操作。
TM 首先发起所有的分支事务的 Try 操作,任何一个分支事务的Try操作执行失败,TM 将会发起所有分支事务的 Cancel 操作,若 Try 操作全部成功,TM 将会发起所有分支事务的 Confirm 操作,其中 Confirm/Cancel 操作若执行失败,TM 会进行重试。
TCC 分为三个阶段:
-
Try 阶段是做完业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的 Confirm 一起才能真正构成一个完整的业务逻辑。
-
Confirm 阶段是做确认提交,Try 阶段所有分支事务执行成功后开始执行 Confirm。通常情况下,采用 TCC 则认为 Confirm 阶段是不会出错的。即:只要 Try 成功,Confirm 一定成功。若 Confirm 阶段真的出错了,需引入重试机制或人工处理。
-
Cancel 阶段是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采用 TCC 则认为 Cancel 阶段也是一定成功的。若 Cancel 阶段真的出错了,需引入重试机制或人工处理。
TCC 异常处理
TCC需要注意三种异常处理分别是空回滚、幂等、悬挂
空回滚
在没有调用 TCC 资源 Try 方法的情况下,调用了二阶段的 Cancel 方法,Cancel 方法需要识别出这是一个空回滚,直接返回成功。
出现原因是当一个分支事务所在服务宕机或网络异常,分支事务调用记录为失败,这个时候其实是没有执行 Try 阶段,当故障恢复后,分布式事务进行回滚则会调用二阶段的 Cancel 方法,从而形成空回滚。
解决思路的关键就是要识别出这个空回滚。思路很简单就是需要知道一阶段是否执行,如果执行了,那就是正常回滚;如果没执行,那就是空回滚。
前面已经说过 TM 在发起全局事务时生成全局事务记录,全局事务 ID 贯穿整个分布式事务调用链条。再额外增加一张分支事务记录表,其中有全局事务 ID 和分支事务 ID,第一阶段 Try 方法里会插入一条记录,表示一阶段执行了。Cancel 接口里读取该记录,如果该记录存在,则正常回滚;如果该记录不存在,则是空回滚。
幂等
通过前面介绍已经了解到,为了保证 TCC 二阶段提交重试机制不会引发数据不一致,要求 TCC 的二阶段 Try、Confirm 和 Cancel 接口保证幂等,这样不会重复使用或者释放资源。如果幂等控制没有做好,很有可能导致数据不一致等严重问题。
对于同一个业务操作,无论执行多少次,最终的结果都是一样的。
解决思路在上述"分支事务记录"中增加执行状态,每次执行前都查询该状态。(类似redo日志?)
悬挂
悬挂就是对于一个分布式事务,其二阶段 Cancel 接口比 Try 接口先执行,导致 Try 执行后预留的业务资源无法被继续处理。
出现原因是在 RPC 调用分支事务 Try 时,先注册分支事务,再执行 RPC 调用,如果此时 RPC 调用的网络发生拥堵,通常 RPC 调用是有超时时间的,RPC 超时以后,TM 就会通知 RM 回滚该分布式事务,可能回滚完成后,RPC 请求才到达参与者真正执行,而一个 Try 方法预留的业务资源,只有该分布式事务才能使用,该分布式事务第一阶段预留的业务资源就再也没有人能够处理了,对于这种情况,我们就称为悬挂,即业务资源预留后没法继续处理。
解决思路是如果二阶段执行完成,那一阶段就不能再继续执行。在执行一阶段事务时判断在该全局事务下,"分支事务记录"表中是否已经有二阶段事务记录,如果有则不执行 Try。
RPC是远程过程调用(Remote Procedure Call)的缩写形式
小结
如果拿 TCC 事务的处理流程与 2PC 两阶段提交做比较,2PC 通常都是在跨库的 DB 层面,而 TCC 则在应用层面的处理,需要通过业务逻辑来实现。这种分布式事务的实现方式的优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现 Try、Confirm、Cancel 三个操作。此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。
分布式事务解决方案 可靠消息最终一致性
原理
可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能够接收消息并处理事务成功,此方案强调的是只要消息发给事务参与方最终事务要达到一致。

可靠消息最终一致性方案要解决以下几个问题:
1、本地事务与消息发送的原子性问题 本地事务与消息发送的原子性问题即:事务发起方在本地事务执行成功后消息必须发出去,否则就丢弃消息。即实现本地事务和消息发送的原子性,要么都成功,要么都失败。
2、事务参与方接收消息的可靠性
事务参与方必须能够从消息队列接收到消息,如果接收消息失败可以重复接收消息。
3、消息重复消费的问题
由于网络2的存在,若某一个消费节点超时但是消费成功,此时消息中间件会重复投递此消息,就导致了消息的重复消费。
解决方案
本地消息表
通过本地事务保证数据业务操作和消息的一致性,然后通过定时任务将消息发送至消息中间件,待确认消息发送给消费方成功再将消息删除。
本地消息表与业务数据表处于同一个数据库中,这样就能利用本地事务来保证在对这两个表的操作满足事务特性,并且使用了消息队列来保证最终一致性。核心思想是将分布式事务拆分成本地事务进行处理。
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候 将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
-
在分布式事务操作的一方完成写业务数据的操作之后向本地消息表发送一个消息,本地事务能保证这个消息一定会被写入本地消息表中。
-
之后将本地消息表中的消息转发到消息队列中,如果转发成功则将消息从本地消息表中删除,否则继续重新转发。
-
在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。在 .NET中 有现成的解决方案。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
小结
可靠消息最终一致性就是保证消息从生产方经过消息中间件传递到消费方的一致性:
-
本地事务与消息发送的原子性问题。
-
事务参与方接收消息的可靠性。
可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦。
分布式事务解决方案 最大努力通知
原理
以充值为例
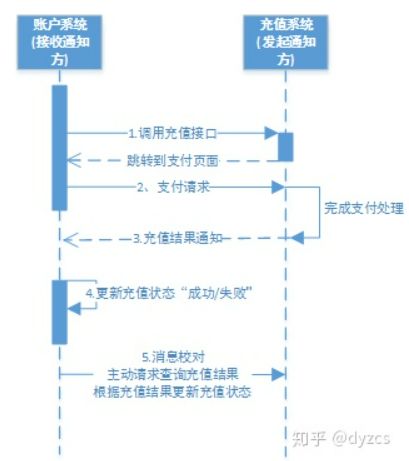
-
账户系统调用充值系统接口
-
充值系统完成支付处理向账户发起充值结果通知,若通知失败,则充值系统按策略进行重复通知
-
账户系统接收到充值结果通知修改充值状态
-
账户系统未接收到通知会主动调用充值系统的接口查询充值结果
最大努力通知方案的目标:发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。
具体包括:
-
有一定的消息重复通知机制。因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知
-
消息校对机制。如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息信息来满足需求。
最大努力通知与可靠消息一致性有什么不同?
-
解决方案思想不同 可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接 收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。
-
两者的业务应用场景不同 可靠消息一致性关注的是交易过程的事务一致,以异步的方式完成交易。最大努力通知关注的是交易后的通知事务,即将交易结果可靠的通知出去。
-
技术解决方向不同 可靠消息一致性要解决消息从发出到接收的一致性,即消息发出并且被接收到。最大努力通知无法保证消息从发出到接收的一致性,只提供消息接收的可靠性机制。可靠机制是,最大努力的将消息通知给接收方,当消息无法被接收方接收时,由接收方主动查询消息(业务处理结果)
解决方案
消息队列的 ack 机制
采用 MQ 的 ack 机制就可以实现最大努力通知。
方案1:
-
发起方将通知发给 MQ。使用普通消息机制将通知发给MQ。 注意:如果消息没有发出去可由接收方主动请求发起通知方查询业务执行结果。(后边会讲)
-
接收方监听 MQ。
-
接收方接收消息,业务处理完成回应 ack。
-
接收方若没有回应 ack 则 MQ 会重复通知。 MQ会按照间隔 1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔,直到达到通知要求的时间窗口上限。
-
接收方可通过消息校对接口来校对消息的一致性。
方案 2:
-
发起通知方将消息发给 MQ。
-
通知程序监听 MQ,接收 MQ 的消息。
方案 1 中接收通知方直接监听 MQ,方案 2 中由通知程序监听 MQ。通知程序若没有回应 ack 则 MQ 会重复通知。
-
通知程序通过互联网接口协议(如 http、webservice)调用接收通知方案接口,完成通知。
-
接收通知方可通过消息校对接口来校对消息的一致性。
方案1和方案2的不同点:
-
方案 1 中接收方监听 MQ,此方案主要应用与内部应用之间的通知。
-
方案 2 中由通知程序监听 MQ,收到 MQ 的消息后由通知程序通过互联网接口协议调用接收方。此方案主要应用于外部应用之间的通知,例如支付宝、微信的支付结果通知。
小结
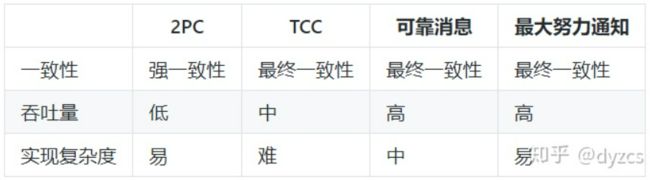
2PC:最大的诟病是一个阻塞协议。这种设计不能适应随着事务涉及的服务数量增加而扩展的需要,很难用于并发较高以及子事务生命周期较长 的分布式服务中。
TCC:典型的使用场景:满减,登录送优惠券等。
可靠消息最终一致性:典型的使用场景:注册送积分,登录送优惠券等。
最大努力通知:典型的使用场景:银行通知、支付结果通知等。
参考资料:
-
SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式,系统详解springcloud微服务技术栈课程|黑马程序员Java微服务_哔哩哔哩_bilibili
-
微服务技术栈 - 乐心湖's Blog | 技术小白的技术博客
-
分布式事务有这一篇就够了! - 知乎
Redis 分布式缓存
Redis 支持三种集群方案
-
主从复制模式
-
Sentinel(哨兵)模式
-
Cluster 模式
主从复制原理
基本原理
主从复制模式中包含一个主数据库实例(master)与一个或多个从数据库实例(slave)
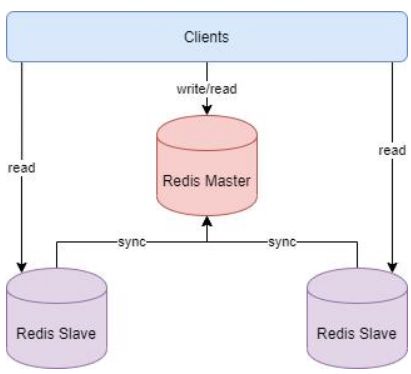
客户端可对主数据库进行读写操作,对从数据库进行读操作,主数据库写入的数据会实时自动同步给从数据库。
具体工作机制为:
-
slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写命令
-
master将保存的快照文件发送给slave,并继续记录执行的写命令
-
slave接收到快照文件后,加载快照文件,载入数据
-
master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化
-
此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性
优缺点
优点:
-
master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
-
master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
-
不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
-
master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
-
难以支持在线扩容,Redis的容量受限于单机配置
Sentinel(哨兵)模式
基本原理
哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障
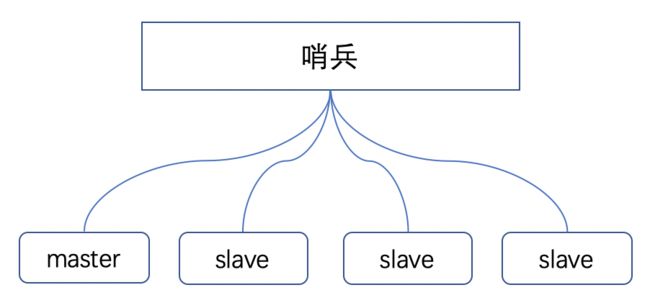
哨兵顾名思义,就是来为Redis集群站哨的,一旦发现问题能做出相应的应对处理。其功能包括
-
监控master、slave是否正常运行
-
当master出现故障时,能自动将一个slave转换为master
-
多个哨兵可以监控同一个Redis,哨兵之间也会自动监控
当 master 宕机时,有如下动作
-
将宕机的master下线
-
找一个slave作为master
-
通知所有的slave连接新的master
-
全量数据或者部分数据同步
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务,以及这些主服务器属下的所有从服务,并在被监视的主服务进入下线(不可服务)状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
哨兵作用
-
集群监控
-
消息通知
-
自动故障转移
注意:哨兵也是一台Redis服务器,只是不提供数据服务,通常哨兵配置的数量为单数。
集群监控
1、哨兵 1 连接到 Redis 集群
-
发送info命令到master,并建立cmd连接;
-
哨兵端保存哨兵状态(SentinelStatus),保存所有哨兵状态,主节点和从节点的信息;master端会记录 redis 实例的信息(SentinelRedisInstance);
-
哨兵根据master中获取的每个slave信息,去连接每个slave,发送同样也是info命令。
2、其他哨兵连接到 Redis 集群
-
发送info命令到master节点,并建立cmd连接;
-
发现master中存在其他哨兵节点的信息,新加入的哨兵将会保存其他哨兵信息
-
为了每个哨兵的信息都一致它们之间建立了一个发布订阅。为了哨兵之间的信息长期对称它们之间也会互发 ping 命令。
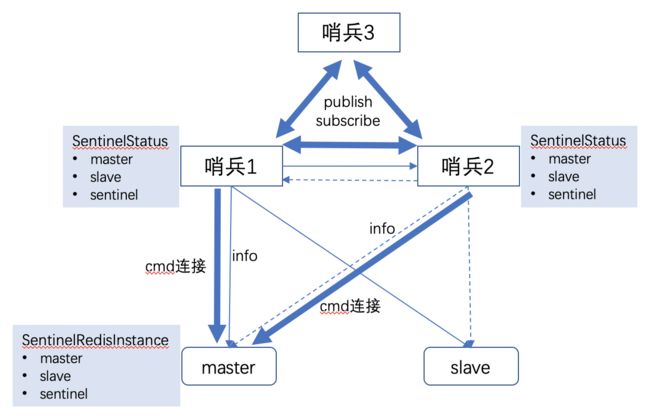
-
Sentinel会向master、slave以及其他Sentinel获取状态
-
Sentinel之间会组建“对应频道”,大家一起发布信息、订阅信息、收信息、同步信息等。
消息通知
1)Sentinel节点会通过master/slave 节点建立的cmd连接获取其工作状态
2)Sentinel收到反馈结果之后,会在哨兵内部进行信息的互通
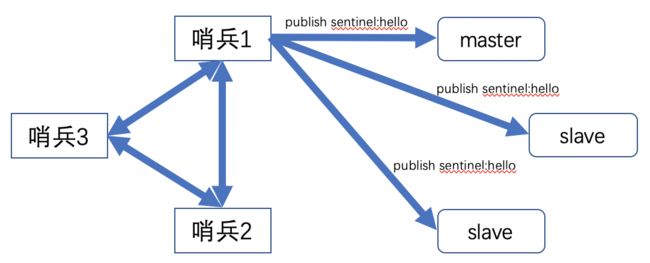
故障转移
关于故障转移,严格来讲可划分两个步骤:故障判定、故障转移。
Q1:如何判断一个节点出现故障?
-
哨兵会一直给主节点发送 publish sentinel:hello
直到主节点故障,哨兵报出 sdown,同时此哨兵还会向其他哨兵发布消息说这个主节点挂了。发送的指令是 sentinel is-master-down-by-address-port。
-
其余的哨兵接收到指令后,主节点挂了吗?让我去看看到底挂没挂。发送的信息也是 hello。
其余的哨兵也会发送他们收到的信息并且发送指令 sentinel is-master-down-by-address-port 到自己的内网,确认一下第一个发送 sentinel is-master-down-by-address-port 的哨兵说你说的对,这个家伙确实挂了。
-
当所有人都认为主节点挂了后就会修改其状态为 odown。
当一个哨兵认为主节点挂了标记的是 sdown,当半数哨兵都认为挂了其标记的状态是 odown。
一个哨兵认为master节点挂了称为主观下线(sdown),超半数哨兵认为master节点挂了则称为客观下线(odown)。
Q2:如何进行故障转移?
1)首先,哨兵选举出哨兵Leader去处理故障转移
2)其次,哨兵Leader从所有的slave节点找出一个作为master节点
主要的规则:
-
选择在线的节点,pass掉已下线的节点;
-
选择响应速度快的,pass掉响应慢的节点
-
选择与原master断开时间短的,pass掉断开时间较长的;
假如以上优先级均一致,会考虑其他优先原则:
-
偏移量较大
假如说 slave1 的 offset 为 50,slave2 偏移量为 55,则哨兵就会选择 slave2 为新的主节点。
-
runid偏大的
这点类似于职场中的论资排辈,也就说根据 runid 的创建时间来判断,时间早的先上位。
3)数据转移
-
新master上任:Sentinel向新的master发送slaveof no one
-
其他slave周知:向其他slave发送slaveof 新master IP端口
优缺点
优点:
-
哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
-
哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点:
-
同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
-
需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
Cluster模式
基本原理
Redis哨兵模式实现了高可用,读写分离,但是其主节点仍然只有一个,即写入操作都是在主节点中,这也成为了性能的瓶颈。存在难以扩容,Redis容量受限于单机配置的问题。Cluster模式实现了Redis的分布式存储,即每台节点存储不同的内容,来解决在线扩容的问题。
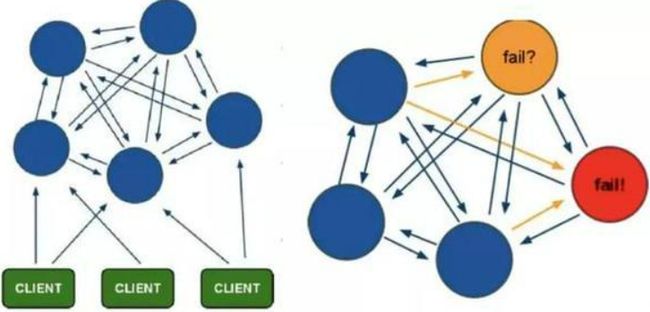
Cluster采用无中心结构,它的特点如下:
-
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
-
节点的fail是通过集群中超过半数的节点检测失效时才生效
-
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
-
相比较sentinel模式,多个master节点保证主要业务(比如master节点主要负责写)稳定性,不需要搭建多个sentinel实例监控一个master节点;
-
相比较一主多从的模式,不需要手动切换,具有自我故障检测,故障转移的特点;
-
相比较其他两个模式而言,对数据进行分片(sharding),不同节点存储的数据是不一样的;
-
从某种程度上来说,Sentinel模式主要针对高可用(HA),而Cluster模式是不仅针对大数据量,高并发,同时也支持HA。
Cluster模式的具体工作机制:
-
在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383(不是一致性哈希)
-
当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的主节点,然后进行存取操作
CRC16是CRC算法中常用的一种,使用16位的二进制多项式进行除法。
-
为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
-
当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Redis Cluser是如何保证高可用
Redis Cluster保证高可用主要还是依靠:故障检测与故障转移两种策略
故障转移
举例说明:包含7000、7001、7002、7003四个主节点的集群,我们此时加入7004、7005两个节点,并当做7000的主节点的两个从节点。
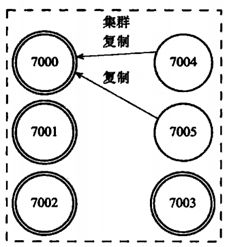
如果此时主节点7000下线(宕机),则 7000 的从节点将从他们中间选择一个作为主节点,用来处理客户端的读写请求。如下,7004 作为主节点,7005 作为了 7004 的从节点
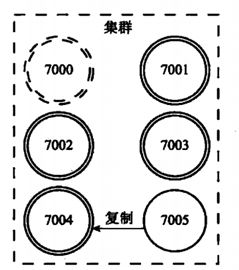
若 7000 再次上线,则他将作为 7004 的从节点
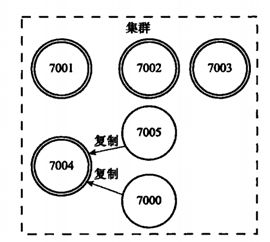
当一个从节点发现自己正在复制的主节点下线时,从节点将开始对下线主节点进行故障转移:
1) 在该下线主节点的所有从节点中,选择一个做主节点
2) 被选中的从节点会执行SLAVEOF no one命令,成为新的主节点;
3) 新的主节点会撤销对所有对已下线主节点的槽指派,并将这些槽全部派给自己。
4) 新的主节点向集群广播一条PONG消息,让其他节点知道“我已经变成主节点了,并且我会接管已下线节点负责的处理的槽”;
5) 新主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
选举新的主节点步骤:
1)集群里的每个负责处理槽的主节点都有一次投票的机会,而第一个向主节点要求投票的从节点将获得主节点的投票。
2)当从节点发现自己正在复制的主节点进入已下线状态时,从节点会向集群广播消息:要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票。如果一个主节点具有投票权,并且这个主节点尚未投票跟其它从节点,则返回给从节点 ACK 消息,表示投票给该从节点
3)每个主节点只有一次投票机会,所有有N个主节点的话,那么具有大于N/2+1张支持票的从节点只有一个,成为新的主节点
4)如果在一个配置纪元里没有从节点能收集到足够多的支持票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点为止。
故障检测
集群中每个节点都会定期地向集群中的其他节点发送PING消息,以此检测对方是否在线;如果接收PING消息的节点没有在规定的时间内,向发送PING消息的节点返回PONG消息,那么发送PING消息的节点就会将PING消息节点标记为疑似下线(possible fail,PFAIL)。
如果在集群中,超过半数以上负责处理槽的主节点都将某个节点X标记为PFAIL,则某个主节点就会将这个主节点X就会被标记为已下线(FAIL),并且广播到这条消息,这样其他所有的节点都会立即将主节点X标记为FAIL。
分布式锁
基本介绍
一个应用被部署到多个机器上做负载均衡。为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,我们该如何解决这个问题呢?
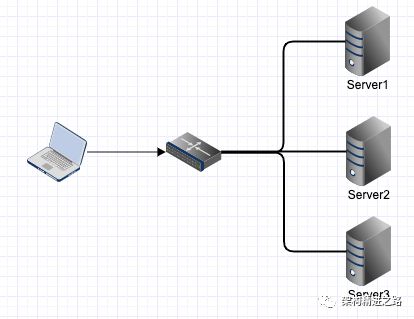
在传统单体应用单机部署的情况下,可以使用并发处理相关的功能(如Java并发处理相关的API:ReentrantLcok或synchronized)进行互斥控制来解决。但是,随着业务的发展,系统架构也会逐步优化升级,原本单体单机部署的系统被演化成分布式集群系统,由于分布式系统多线程、多进程并且分布在多个不同机器上,这将使原单机部署情况下的并发控制锁策略无法满足,并不能提供分布式锁的能力。为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,需要使用分布式锁。
1、处理效率提升:应用分布式锁,可以减少重复任务的执行,避免资源处理效率的浪费;
2、数据准确性保障:使用分布式锁可以放在数据资源的并发访问,避免数据不一致情况,甚至数据损失等。
实现方式
关于分布式锁的实现,可以分别控制在不同的环节。

1、开源组件锁控制:ZooKeeper
ZooKeeper 是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性的问题,例如怎样避免同时操作同一数据造成脏读的问题。ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。

1、客户端获取锁时,在 lock 节点(节点名可自定义)下创建临时顺序节点。
2、客户端获取到 lock 节点下的所有子节点,判断自己创建的临时顺序节点的序号是否最小,若是,则表示此客户端获取到了该锁。使用完后将其删除。
3、若发现自己创建的临时顺序节点序号不是最小,则说明未获取到锁,此时客户端监听比自己小的节点,对其注册事件监听器,监听删除事件。
4、若发现比自己小的节点被删除,则 Watcher 会受到相应通知,再次判断临时顺序节点的序号是否最小,根据上面的规则获取锁。
以上步骤中,应该注意的是,对于监听节点来说,当最小节点被删除后,之后监听该节点的 Watcher 会受到相应通知,其余不会收到通知。例如上图中,/lock/2 监听 /lock/1,当 /lock/1 删除后,/lock/3 不会收到通知。
ZooKeeper分布式锁方式,性能相对Redis方式较差,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
2、任务处理锁控制:Redis
优势:
-
性能极高 – Redis能读的速度是11w+次/s,写的速度是8w+次/s
-
丰富的数据类型 – Redis主要支持 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型
-
原子性 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行
-
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis实现简单分布式锁过程:
(1)获取锁:使用 setnx 加锁,并使用 expire 命令为锁添加一个超时时间,超过该时间则自动释放锁,通常 value 为一个随机生成的UUID,通过此在释放锁的时候进行判断。若未获取到锁,设置一个获取的超时时间,若超过这个时间则放弃获取锁。
SETNX key value // 并没有设置过期时间 set key val EX 过期时间(秒) nx
当且仅当 key 不存在时,将 key 的值设为 value。
返回整数,具体为
-
- 1,当 key 的值被设置
-
- 0,当 key 的值没被设置
多个进程执行以下Redis命令:
SETNX lock.foo
-
如果 SETNX 返回1,说明该进程获得锁,SETNX将键 lock.foo 的值设置为锁的超时时间(当前时间 + 锁的有效时间)。
-
如果 SETNX 返回0,说明其他进程已经获得了锁,进程不能进入临界区。进程可以在一个循环中不断地尝试 SETNX 操作,以获得锁。
(2)释放锁:通过UUID(通用唯一识别码(Universally Unique Identifier))判断是不是该锁,若是该锁,则执行delete进行锁释放。
利用Redis实现分布式锁,实现可能存在的缺点:
1、redis 过期时间问题:在执行delete进行释放锁的时候,假如操作删除锁动作失败,那此 Key-Value 过期时间则不好控制,可能会一直存在,可能对后续数据验证造成影响。
2、使用 set 设置 key - value 和过期时间应为原子操作,这个可以使用 set key value Ex 过期时间 nx 解决
3、当需要删除 key 时,由于 value 为 uuid,因此先对比是否为本线程加的锁,即对比 get 到的 uuid,是否相同,但是仍然存在问题,例如 redis 中的过期时间为 10s,业务代码执行了 9.5s,当从 redis 中 get 到本线程 uuid 后,花费 0.5s,那么此时 redis 将自动删除 key,之后若其他线程将 key - value 存入,此时第一个线程将会执行 delete 删除 key,那么删除了第二个线程 key - value,出现错误。这需要 get 和 delete 为原子操作,需要使用 lua 脚本进行原子解锁,参考官网文档,如下:
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 原子解锁
stringRedisTemplate.execute(new DefaultRedisScript(script, Long.class), Arrays.asList("lock"), uuid);
上面由自己实现貌似有点麻烦,因此可使用 Redission 在 Redis 的基础上实现 Java 内存数据网络,提供分布式服务,提供 Redis 的分布式锁。也就是说,使用 Redission 实现 Redis 分布式锁的控制。参考 https://github.com/redisson/redisson

Redission 如何实现 Redis 分布式锁
Redission 的 Lock 方法
Redission 的加锁方法 lock 继承了 juc 包下的 Lock,因此使用和可重入锁 ReentrantLock 相同,Redission 的 getLock("锁的名字") 进行分布式并发控制,这里锁的名字可以用来控制锁的粒度。
Redission 使用看门狗实现了锁的自动续期,因为 Redission 基于 Redis 的 setnx 实现,将此线程的 key - value 存入到 redis 中,若业务代码执行时间较长,则会默认更新 TTL 为 30s,即使在业务代码程序崩溃,没有手动解锁,也会由于超时时间(默认 30s)redis 自动删除 key,不会出现死锁问题。
当然我们也可使用 redission.lock(10, TimeUnit.SECONDS) 来自己指定时间,但是这种需要注意,这种方式 Redission 不会自动对 TTL 进行续期,也就是说,指定的时间必须大于业务方法的执行时间。
通常我们使用指定时间的方式加锁和手动解锁来显式控制。
Redission 的信号量
在 juc 包下,有信号量 Semaphore,因此 Redission 也有信号量的方法 getSemaphore("这个 Semaphore 的名称"),和 juc 包下的 Semaphore 相同,用来限流。
Redission 的 CountDownLatch
在 Redisssion 中,和 juc 相同的 CountDownLatch 为 getCountDownLatch("这个CountDownLatch 的名称")
注意,这些分布式并发锁都是基于 Redis 实现的,将特定的 key-val 存入到 Redis 中用来控制并发过程。
3、数据写入锁控制:MySQL
数据库层面是最终数据写入的时候,对数据做写入控制处理,算是分布式锁的最终末端环节。
实现方式一:唯一索引
UNIQUE KEY `uidx_name` (`name`) USING BTREE;
上述case中,我们对 name 字段做了索引的唯一性约束,当存在多个新增数据请求同时提交到数据库的话,数据库自身则会利用唯一索引,来保证数据的唯一性。
实现方式二:排他锁
执行以下SQL:
SELECT status FROM users WHERE id = 3 FOR UPDATE;
假如,在另一个事务中再次执行:
SELECT status FROM users WHERE id = 3 FOR UPDATE;
则第二个事务会一直等待上一个事务的提交,此时第二个查询处于阻塞的状态。
排它锁的应用:
在进行事务操作时,通过 “FOR UPDATE” 语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
实现方式三:乐观锁
实现逻辑:乐观锁每次在执行数据修改操作时,都会带上一个数据版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1 操作,否则就执行失败。因为每次操作的版本号都会随之增加,所以不会出现 ABA 问题。
除了 version 以外,还可以使用时间戳,因为时间戳天然具有顺序递增性。
比较麻烦的一点:就是在操作业务前,需要先查询出当前的 version 版本。
数据库分布式锁实现可能存在的缺点:
-
DB操作性能较差,并且有锁表的风险;
-
非阻塞操作失败后,需要轮询,占用cpu资源;
-
长时间不commit或者长时间轮询,可能会占用较多连接资源
比较
-
理解的难易程度 数据库 > Redis > Zookeeper
-
实现的复杂程度 Zookeeper >= Redis > 数据库
-
性能高低 Redis > Zookeeper > 数据库
-
可靠性 Zookeeper > Redis > 数据库
分布式 Session
参考 https://www.cnblogs.com/study-everyday/p/7853145.html
分布式 Session 存在的问题
单服务器web应用中,session信息只需存在该服务器中,因此单个服务下服务器可在一次会话中获得 session 存储的内容,但是在分布式场景中,可能存在通过负载均衡方式路由到不同的服务器中,那么就存在 session 存储在其中某一台服务器而其他服务器不知道该 session 的情况。存在 session 一致性的问题。
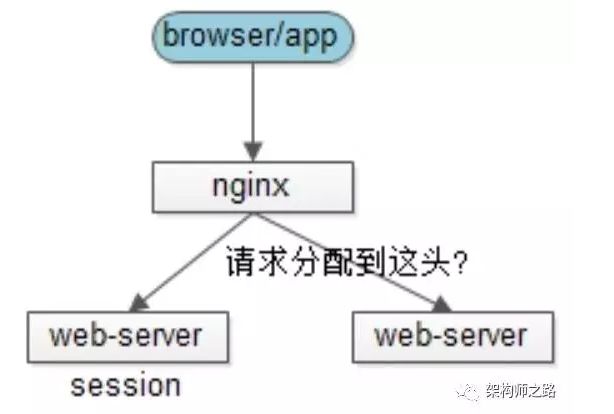
Session 一致性的解决方案
1、Session 复制(同步)
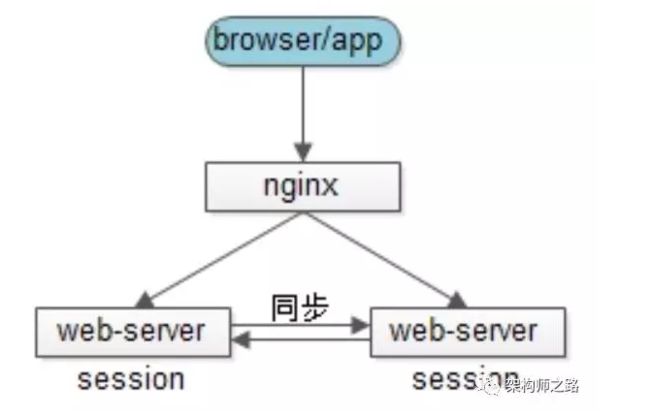
思路:多个web-server之间相互同步session,这样每个web-server之间都包含全部的session
优点:web-server支持的功能,应用程序不需要修改代码
不足:
-
session的同步需要数据传输,占内网带宽,有时延
-
所有web-server都包含所有session数据,数据量受内存限制,无法水平扩展
2、客户端存储
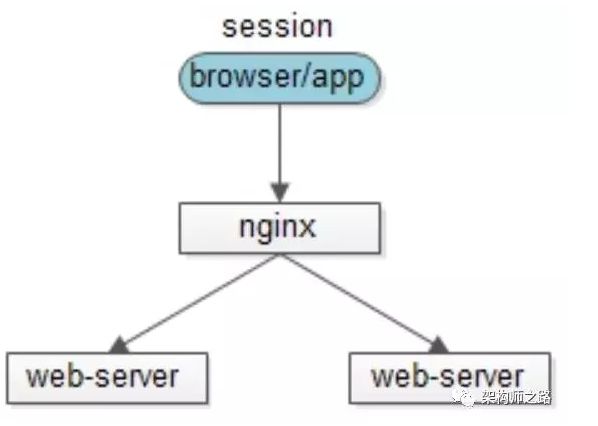
思路:服务端存储所有用户的 session,内存占用较大,可以将session存储到浏览器cookie中,每个端只要存储一个用户的数据了
优点:服务端不需要存储
缺点:
-
每次http请求都携带session,占外网带宽
-
数据存储在端上,并在网络传输,存在泄漏、篡改、窃取等安全隐患
-
session存储的数据大小受cookie限制
“端存储”的方案虽然不常用,但确实是一种思路。
3、反向代理 hash
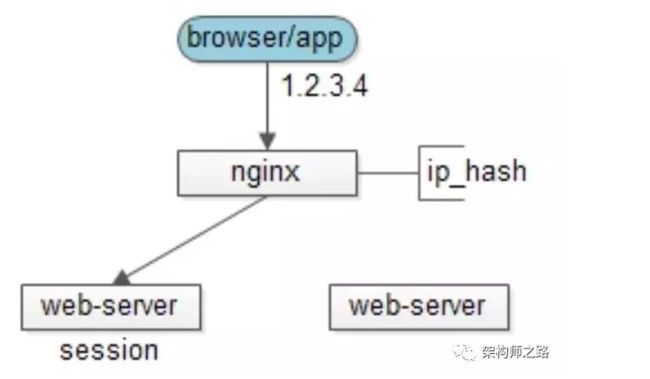
思路:web-server为了保证高可用,有多台冗余,反向代理服务器通过一些策略让 同一个用户的请求保证落在一台web-server
有如下方案:
方案一:四层代理 hash
反向代理层使用用户ip来做hash,以保证同一个ip的请求落在同一个web-server上
方案二:七层代理 hash
反向代理使用http协议中的某些业务属性来做hash,例如sid,city_id,user_id等,能够更加灵活的实施hash策略,以保证同一个浏览器用户的请求落在同一个web-server上
优点:
-
只需要改nginx配置,不需要修改应用代码
-
负载均衡,只要hash属性是均匀的,多台web-server的负载是均衡的
-
可以支持web-server水平扩展(session同步法是不行的,受内存限制)
不足:
-
如果web-server重启,一部分session会丢失,产生业务影响,例如部分用户重新登录
-
如果web-server水平扩展,rehash后session重新分布,也会有一部分用户路由不到正确的session
4、后端统一集中存储
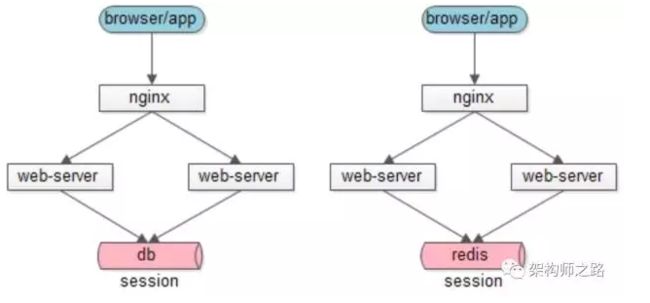
思路:将session存储在web-server后端的存储层,数据库或者缓存
优点:
-
没有安全隐患
-
可以水平扩展,数据库/缓存水平切分即可
-
web-server重启或者扩容都不会有session丢失
不足:增加了一次网络调用,并且需要修改应用代码
对于db存储还是cache,个人推荐后者:session读取的频率会很高,数据库压力会比较大。如果有session高可用需求,cache可以做高可用,但大部分情况下session可以丢失,一般也不需要考虑高可用。
Docker实用篇
1.初识Docker
1.1.什么是Docker
微服务虽然具备各种各样的优势,但服务的拆分通用给部署带来了很大的麻烦。
-
分布式系统中,依赖的组件非常多,不同组件之间部署时往往会产生一些冲突。
-
在数百上千台服务中重复部署,环境不一定一致,会遇到各种问题
1.1.1.应用部署的环境问题
大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题:
-
依赖关系复杂,容易出现兼容性问题
-
开发、测试、生产环境有差异

例如一个项目中,部署时需要依赖于node.js、Redis、RabbitMQ、MySQL等,这些服务部署时所需要的函数库、依赖项各不相同,甚至会有冲突。给部署带来了极大的困难。
1.1.2.Docker解决依赖兼容问题
而Docker确巧妙的解决了这些问题,Docker是如何实现的呢?
Docker为了解决依赖的兼容问题的,采用了两个手段:
-
将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包
-
将每个应用放到一个隔离容器去运行,避免互相干扰

这样打包好的应用包中,既包含应用本身,也保护应用所需要的Libs、Deps,无需再操作系统上安装这些,自然就不存在不同应用之间的兼容问题了。
虽然解决了不同应用的兼容问题,但是开发、测试等环境会存在差异,操作系统版本也会有差异,怎么解决这些问题呢?
1.1.3.Docker解决操作系统环境差异
要解决不同操作系统环境差异问题,必须先了解操作系统结构。以一个Ubuntu操作系统为例,结构如下:

结构包括:
-
计算机硬件:例如CPU、内存、磁盘等
-
系统内核:所有Linux发行版的内核都是Linux,例如CentOS、Ubuntu、Fedora等。内核可以与计算机硬件交互,对外提供内核指令,用于操作计算机硬件。
-
系统应用:操作系统本身提供的应用、函数库。这些函数库是对内核指令的封装,使用更加方便。
应用于计算机交互的流程如下:
1)应用调用操作系统应用(函数库),实现各种功能
2)系统函数库是对内核指令集的封装,会调用内核指令
3)内核指令操作计算机硬件
Ubuntu和CentOSpringBoot都是基于Linux内核,无非是系统应用不同,提供的函数库有差异:

此时,如果将一个Ubuntu版本的MySQL应用安装到CentOS系统,MySQL在调用Ubuntu函数库时,会发现找不到或者不匹配,就会报错了:

Docker如何解决不同系统环境的问题?
-
Docker将用户程序与所需要调用的系统(比如Ubuntu)函数库一起打包
-
Docker运行到不同操作系统时,直接基于打包的函数库,借助于操作系统的Linux内核来运行
如图:

1.1.4.小结
Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题?
-
Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
-
Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker如何解决开发、测试、生产环境有差异的问题?
-
Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术,具备下列优势:
-
可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
-
运行时利用沙箱机制形成隔离容器,各个应用互不干扰
-
启动、移除都可以通过一行命令完成,方便快捷
1.2.Docker和虚拟机的区别
Docker可以让一个应用在任何操作系统中非常方便的运行。而以前我们接触的虚拟机,也能在一个操作系统中,运行另外一个操作系统,保护系统中的任何应用。
两者有什么差异呢?
虚拟机(virtual machine)是在操作系统中模拟硬件设备,然后运行另一个操作系统,比如在 Windows 系统里面运行 Ubuntu 系统,这样就可以运行任意的Ubuntu应用了。
Docker仅仅是封装函数库,并没有模拟完整的操作系统,如图:

对比来看:

小结:
Docker和虚拟机的差异:
-
docker是一个系统进程;虚拟机是在操作系统中的操作系统
-
docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
1.3.Docker架构
1.3.1.镜像和容器
Docker中有几个重要的概念:
镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器进程做隔离,对外不可见。
一切应用最终都是代码组成,都是硬盘中的一个个的字节形成的文件。只有运行时,才会加载到内存,形成进程。
而镜像,就是把一个应用在硬盘上的文件、及其运行环境、部分系统函数库文件一起打包形成的文件包。这个文件包是只读的。
容器呢,就是将这些文件中编写的程序、函数加载到内存中允许,形成进程,只不过要隔离起来。因此一个镜像可以启动多次,形成多个容器进程。

例如你下载了一个QQ,如果我们将QQ在磁盘上的运行文件及其运行的操作系统依赖打包,形成QQ镜像。然后你可以启动多次,双开、甚至三开QQ,跟多个妹子聊天。
1.3.2.DockerHub
开源应用程序非常多,打包这些应用往往是重复的劳动。为了避免这些重复劳动,人们就会将自己打包的应用镜像,例如Redis、MySQL镜像放到网络上,共享使用,就像GitHub的代码共享一样。
-
DockerHub:DockerHub是一个官方的Docker镜像的托管平台。这样的平台称为Docker Registry。
-
国内也有类似于DockerHub 的公开服务,比如 网易云镜像服务、阿里云镜像库等。
我们一方面可以将自己的镜像共享到DockerHub,另一方面也可以从DockerHub拉取镜像:

1.3.3.Docker架构
我们要使用Docker来操作镜像、容器,就必须要安装Docker。
Docker是一个CS架构的程序,由两部分组成:
-
服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
-
客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。
如图:

1.3.4.小结
镜像:
-
将应用程序及其依赖、环境、配置打包在一起
容器:
-
镜像运行起来就是容器,一个镜像可以运行多个容器
Docker结构:
-
服务端:接收命令或远程请求,操作镜像或容器
-
客户端:发送命令或者请求到Docker服务端
DockerHub:
-
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
1.4.安装Docker
企业部署一般都是采用Linux操作系统,而其中又数CentOS发行版占比最多,因此我们在CentOS下安装Docker。参考课前资料中的文档:

2.Docker的基本操作
2.1.镜像操作
2.1.1.镜像名称
首先来看下镜像的名称组成:
-
镜名称一般分两部分组成:[repository]:[tag]。
-
在没有指定tag时,默认是latest,代表最新版本的镜像
如图:

这里的mysql就是repository,5.7就是tag,合一起就是镜像名称,代表5.7版本的MySQL镜像。
2.1.2.镜像命令
常见的镜像操作命令如图:

2.1.3.案例1-拉取、查看镜像
需求:从DockerHub中拉取一个nginx镜像并查看
1)首先去镜像仓库搜索nginx镜像,比如DockerHub:

2)根据查看到的镜像名称,拉取自己需要的镜像,通过命令:docker pull nginx

3)通过命令:docker images 查看拉取到的镜像

2.1.4.案例2-保存、导入镜像
需求:利用docker save将nginx镜像导出磁盘,然后再通过load加载回来
1)利用docker xx --help命令查看docker save和docker load的语法
例如,查看save命令用法,可以输入命令:
docker save --help
结果:

命令格式:
docker save -o [保存的目标文件名称] [镜像名称]
2)使用docker save导出镜像到磁盘
运行命令:
docker save -o nginx.tar nginx:latest
结果如图:

3)使用docker load加载镜像
先删除本地的nginx镜像:
docker rmi nginx:latest
然后运行命令,加载本地文件:
docker load -i nginx.tar
结果:

2.1.5.练习
需求:去DockerHub搜索并拉取一个Redis镜像
目标:
1)去DockerHub搜索Redis镜像
2)查看Redis镜像的名称和版本
3)利用docker pull命令拉取镜像
4)利用docker save命令将 redis:latest打包为一个redis.tar包
5)利用docker rmi 删除本地的redis:latest
6)利用docker load 重新加载 redis.tar文件
2.2.容器操作
2.2.1.容器相关命令
容器操作的命令如图:

容器保护三个状态:
-
运行:进程正常运行
-
暂停:进程暂停,CPU不再运行,并不释放内存
-
停止:进程终止,回收进程占用的内存、CPU等资源
其中:
-
docker run:创建并运行一个容器,处于运行状态
-
docker pause:让一个运行的容器暂停
-
docker unpause:让一个容器从暂停状态恢复运行
-
docker stop:停止一个运行的容器
-
docker start:让一个停止的容器再次运行
-
docker rm:删除一个容器
2.2.2.案例-创建并运行一个容器
创建并运行nginx容器的命令:
docker run --name containerName -p 80:80 -d nginx
命令解读:
-
docker run :创建并运行一个容器
-
--name : 给容器起一个名字,比如叫做mn
-
-p :将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
-
-d:后台运行容器
-
nginx:镜像名称,例如nginx
这里的-p参数,是将容器端口映射到宿主机端口。
默认情况下,容器是隔离环境,我们直接访问宿主机的80端口,肯定访问不到容器中的nginx。
现在,将容器的80与宿主机的80关联起来,当我们访问宿主机的80端口时,就会被映射到容器的80,这样就能访问到nginx了:

2.2.3.案例-进入容器,修改文件
需求:进入Nginx容器,修改HTML文件内容,添加“传智教育欢迎您”
提示:进入容器要用到docker exec命令。
步骤:
1)进入容器。进入我们刚刚创建的nginx容器的命令为:
docker exec -it mn bash
命令解读:
-
docker exec :进入容器内部,执行一个命令
-
-it : 给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
-
mn :要进入的容器的名称
-
bash:进入容器后执行的命令,bash是一个linux终端交互命令
2)进入nginx的HTML所在目录 /usr/share/nginx/html
容器内部会模拟一个独立的Linux文件系统,看起来如同一个linux服务器一样:

nginx的环境、配置、运行文件全部都在这个文件系统中,包括我们要修改的html文件。
查看DockerHub网站中的nginx页面,可以知道nginx的html目录位置在/usr/share/nginx/html
我们执行命令,进入该目录:
cd /usr/share/nginx/html
查看目录下文件:

3)修改index.html的内容
容器内没有vi命令,无法直接修改,我们用下面的命令来修改:
sed -i -e 's#Welcome to nginx#传智教育欢迎您#g' -e 's###g' index.html
在浏览器访问自己的虚拟机地址,例如我的是:http://192.168.150.101,即可看到结果:

2.2.4.小结
docker run命令的常见参数有哪些?
-
--name:指定容器名称
-
-p:指定端口映射
-
-d:让容器后台运行
查看容器日志的命令:
-
docker logs
-
添加 -f 参数可以持续查看日志
查看容器状态:
-
docker ps
-
docker ps -a 查看所有容器,包括已经停止的
2.3.数据卷(容器数据管理)
在之前的nginx案例中,修改nginx的html页面时,需要进入nginx内部。并且因为没有编辑器,修改文件也很麻烦。
这就是因为容器与数据(容器内文件)耦合带来的后果。

要解决这个问题,必须将数据与容器解耦,这就要用到数据卷了。
2.3.1.什么是数据卷
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。

一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录了。
这样,我们操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录了
2.3.2.数据集操作命令
数据卷操作的基本语法如下:
docker volume [COMMAND]
docker volume命令是数据卷操作,根据命令后跟随的command来确定下一步的操作:
-
create 创建一个volume
-
inspect 显示一个或多个volume的信息
-
ls 列出所有的volume
-
prune 删除未使用的volume
-
rm 删除一个或多个指定的volume
2.3.3.创建和查看数据卷
需求:创建一个数据卷,并查看数据卷在宿主机的目录位置
① 创建数据卷
docker volume create html
② 查看所有数据
docker volume ls
结果:

③ 查看数据卷详细信息卷
docker volume inspect html
结果:

可以看到,我们创建的html这个数据卷关联的宿主机目录为/var/lib/docker/volumes/html/_data目录。
小结:
数据卷的作用:
-
将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
数据卷操作:
-
docker volume create:创建数据卷
-
docker volume ls:查看所有数据卷
-
docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
-
docker volume rm:删除指定数据卷
-
docker volume prune:删除所有未使用的数据卷
2.3.4.挂载数据卷
我们在创建容器时,可以通过 -v 参数来挂载一个数据卷到某个容器内目录,命令格式如下:
docker run \ --name mn \ -v html:/root/html \ -p 8080:80 nginx \
这里的-v就是挂载数据卷的命令:
-
-v html:/root/html:把html数据卷挂载到容器内的/root/html这个目录中
2.3.5.案例-给nginx挂载数据卷
需求:创建一个nginx容器,修改容器内的html目录内的index.html内容
分析:上个案例中,我们进入nginx容器内部,已经知道nginx的html目录所在位置/usr/share/nginx/html ,我们需要把这个目录挂载到html这个数据卷上,方便操作其中的内容。
提示:运行容器时使用 -v 参数挂载数据卷
步骤:
① 创建容器并挂载数据卷到容器内的HTML目录
docker run --name mn -v html:/usr/share/nginx/html -p 80:80 -d nginx
② 进入html数据卷所在位置,并修改HTML内容
# 查看html数据卷的位置 docker volume inspect html # 进入该目录 cd /var/lib/docker/volumes/html/_data # 修改文件 vi index.html
2.3.6.案例-给MySQL挂载本地目录
容器不仅仅可以挂载数据卷,也可以直接挂载到宿主机目录上。关联关系如下:
-
带数据卷模式:宿主机目录 --> 数据卷 ---> 容器内目录
-
直接挂载模式:宿主机目录 ---> 容器内目录
如图:

语法:
目录挂载与数据卷挂载的语法是类似的:
-
-v [宿主机目录]:[容器内目录]
-
-v [宿主机文件]:[容器内文件]
需求:创建并运行一个MySQL容器,将宿主机目录直接挂载到容器
实现思路如下:
1)在将课前资料中的mysql.tar文件上传到虚拟机,通过load命令加载为镜像
2)创建目录/tmp/mysql/data
3)创建目录/tmp/mysql/conf,将课前资料提供的hmy.cnf文件上传到/tmp/mysql/conf
4)去DockerHub查阅资料,创建并运行MySQL容器,要求:
① 挂载/tmp/mysql/data到mysql容器内数据存储目录
② 挂载/tmp/mysql/conf/hmy.cnf到mysql容器的配置文件
③ 设置MySQL密码
2.3.7.小结
docker run的命令中通过 -v 参数挂载文件或目录到容器中:
-
-v volume名称:容器内目录
-
-v 宿主机文件:容器内文件
-
-v 宿主机目录:容器内目录
数据卷挂载与目录直接挂载的
-
数据卷挂载耦合度低,由docker来管理目录,但是目录较深,不好找
-
目录挂载耦合度高,需要我们自己管理目录,不过目录容易寻找查看
3.Dockerfile自定义镜像
常见的镜像在DockerHub就能找到,但是我们自己写的项目就必须自己构建镜像了。
而要自定义镜像,就必须先了解镜像的结构才行。
3.1.镜像结构
镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成。
我们以MySQL为例,来看看镜像的组成结构:

简单来说,镜像就是在系统函数库、运行环境基础上,添加应用程序文件、配置文件、依赖文件等组合,然后编写好启动脚本打包在一起形成的文件。
我们要构建镜像,其实就是实现上述打包的过程。
3.2.Dockerfile语法
构建自定义的镜像时,并不需要一个个文件去拷贝,打包。
我们只需要告诉Docker,我们的镜像的组成,需要哪些BaseImage、需要拷贝什么文件、需要安装什么依赖、启动脚本是什么,将来Docker会帮助我们构建镜像。
而描述上述信息的文件就是Dockerfile文件。
Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer。

更新详细语法说明,请参考官网文档: Dockerfile reference | Docker Docs
3.3.构建Java项目
3.3.1.基于Ubuntu构建Java项目
需求:基于Ubuntu镜像构建一个新镜像,运行一个java项目
-
步骤1:新建一个空文件夹docker-demo

-
步骤2:拷贝课前资料中的docker-demo.jar文件到docker-demo这个目录

-
步骤3:拷贝课前资料中的jdk8.tar.gz文件到docker-demo这个目录

-
步骤4:拷贝课前资料提供的Dockerfile到docker-demo这个目录

其中的内容如下:
# 指定基础镜像 FROM ubuntu:16.04 # 配置环境变量,JDK的安装目录 ENV JAVA_DIR=/usr/local # 拷贝jdk和java项目的包 COPY ./jdk8.tar.gz $JAVA_DIR/ COPY ./docker-demo.jar /tmp/app.jar # 安装JDK RUN cd $JAVA_DIR \ && tar -xf ./jdk8.tar.gz \ && mv ./jdk1.8.0_144 ./java8 # 配置环境变量 ENV JAVA_HOME=$JAVA_DIR/java8 ENV PATH=$PATH:$JAVA_HOME/bin # 暴露端口 EXPOSE 8090 # 入口,java项目的启动命令 ENTRYPOINT java -jar /tmp/app.jar
-
步骤5:进入docker-demo
将准备好的docker-demo上传到虚拟机任意目录,然后进入docker-demo目录下
-
步骤6:运行命令:
docker build -t javaweb:1.0 .
最后访问 http://192.168.150.101:8090/hello/count,其中的ip改成你的虚拟机ip
3.3.2.基于java8构建Java项目
虽然我们可以基于Ubuntu基础镜像,添加任意自己需要的安装包,构建镜像,但是却比较麻烦。所以大多数情况下,我们都可以在一些安装了部分软件的基础镜像上做改造。
例如,构建java项目的镜像,可以在已经准备了JDK的基础镜像基础上构建。
需求:基于java:8-alpine镜像,将一个Java项目构建为镜像
实现思路如下:
-
① 新建一个空的目录,然后在目录中新建一个文件,命名为Dockerfile
-
② 拷贝课前资料提供的docker-demo.jar到这个目录中
-
③ 编写Dockerfile文件:
-
a )基于java:8-alpine作为基础镜像
-
b )将app.jar拷贝到镜像中
-
c )暴露端口
-
d )编写入口ENTRYPOINT
内容如下:
FROM java:8-alpine COPY ./app.jar /tmp/app.jar EXPOSE 8090 ENTRYPOINT java -jar /tmp/app.jar
-
-
④ 使用docker build命令构建镜像
-
⑤ 使用docker run创建容器并运行
3.4.小结
小结:
-
Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
-
Dockerfile的第一行必须是FROM,从一个基础镜像来构建
-
基础镜像可以是基本操作系统,如Ubuntu。也可以是其他人制作好的镜像,例如:java:8-alpine
4.Docker-Compose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!

4.1.初识DockerCompose
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。格式如下:
version: "3.8"
services:
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: 123
volumes:
- "/tmp/mysql/data:/var/lib/mysql"
- "/tmp/mysql/conf/hmy.cnf:/etc/mysql/conf.d/hmy.cnf"
web:
build: .
ports:
- "8090:8090"
上面的Compose文件就描述一个项目,其中包含两个容器:
-
mysql:一个基于
mysql:5.7.25镜像构建的容器,并且挂载了两个目录 -
web:一个基于
docker build临时构建的镜像容器,映射端口时8090
DockerCompose的详细语法参考官网:Overview | Docker Docs
其实DockerCompose文件可以看做是将多个docker run命令写到一个文件,只是语法稍有差异。
4.2.安装DockerCompose
参考课前资料
4.3.部署微服务集群
需求:将之前学习的cloud-demo微服务集群利用DockerCompose部署
实现思路:
① 查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件
② 修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名
③ 使用maven打包工具,将项目中的每个微服务都打包为app.jar
④ 将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中
⑤ 将cloud-demo上传至虚拟机,利用 docker-compose up -d 来部署
4.3.1.compose文件
查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件,而且每个微服务都准备了一个独立的目录:

内容如下:
version: "3.2"
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: 123
volumes:
- "$PWD/mysql/data:/var/lib/mysql"
- "$PWD/mysql/conf:/etc/mysql/conf.d/"
userservice:
build: ./user-service
orderservice:
build: ./order-service
gateway:
build: ./gateway
ports:
- "10010:10010"
可以看到,其中包含5个service服务:
-
nacos:作为注册中心和配置中心-
image: nacos/nacos-server: 基于nacos/nacos-server镜像构建 -
environment:环境变量-
MODE: standalone:单点模式启动
-
-
ports:端口映射,这里暴露了8848端口
-
-
mysql:数据库-
image: mysql:5.7.25:镜像版本是mysql:5.7.25 -
environment:环境变量-
MYSQL_ROOT_PASSWORD: 123:设置数据库root账户的密码为123
-
-
volumes:数据卷挂载,这里挂载了mysql的data、conf目录,其中有我提前准备好的数据
-
-
userservice、orderservice、gateway:都是基于Dockerfile临时构建的
查看mysql目录,可以看到其中已经准备好了cloud_order、cloud_user表:

查看微服务目录,可以看到都包含Dockerfile文件:

内容如下:
FROM java:8-alpine COPY ./app.jar /tmp/app.jar ENTRYPOINT java -jar /tmp/app.jar
4.3.2.修改微服务配置
因为微服务将来要部署为docker容器,而容器之间互联不是通过IP地址,而是通过容器名。这里我们将order-service、user-service、gateway服务的mysql、nacos地址都修改为基于容器名的访问。
如下所示:
spring:
datasource:
url: jdbc:mysql://mysql:3306/cloud_order?useSSL=false
username: root
password: 123
driver-class-name: com.mysql.jdbc.Driver
application:
name: orderservice
cloud:
nacos:
server-addr: nacos:8848 # nacos服务地址
4.3.3.打包
接下来需要将我们的每个微服务都打包。因为之前查看到Dockerfile中的jar包名称都是app.jar,因此我们的每个微服务都需要用这个名称。
可以通过修改pom.xml中的打包名称来实现,每个微服务都需要修改:
app org.springframework.boot spring-boot-maven-plugin
打包后:

4.3.4.拷贝jar包到部署目录
编译打包好的app.jar文件,需要放到Dockerfile的同级目录中。注意:每个微服务的app.jar放到与服务名称对应的目录,别搞错了。
user-service:

order-service:

gateway:

4.3.5.部署
最后,我们需要将文件整个cloud-demo文件夹上传到虚拟机中,理由DockerCompose部署。
上传到任意目录:

部署:
进入cloud-demo目录,然后运行下面的命令:
docker-compose up -d
5.Docker镜像仓库
5.1.搭建私有镜像仓库
参考课前资料《CentOS7安装Docker.md》
5.2.推送、拉取镜像
推送镜像到私有镜像服务必须先tag,步骤如下:
① 重新tag本地镜像,名称前缀为私有仓库的地址:192.168.150.101:8080/
docker tag nginx:latest 192.168.150.101:8080/nginx:1.0
② 推送镜像
docker push 192.168.150.101:8080/nginx:1.0
③ 拉取镜像
docker pull 192.168.150.101:8080/nginx:1.0