Streaming Telemetry翻译学习
您需要了解的有关管道的所有信息
- 典型的基本分析平台架构
- 管道:简要概述
- 管道:如何开始
- 管道:metrics.json
- 管道:内部监控
- 管道:TCP拨出
- 管道:UDP拨出
- gRPC:有关的知识
- 管道:gRPC拨出(无TLS)
- 管道:gRPC拨出(TLS)
- 管道:gRPC拨入(无TLS)
- 管道:gRPC拨入(TLS)
- 管道:转到“ dump.txt”
- 管道:到InfluxDB
- 管道:到Prometheus
- 管道:到Kafka
- 这么多方法……最好的方法是什么?
- 结论
去年,我们提供了一些有关管道及其运营模式的出色教程和博客。 希望能为您提供有关该收集器的良好第一印象的足够信息! IOS XR Telemetry最近获得了新的协议和功能。 另外,对于使用管道和使用遥测的端到端过程,我们仍然会遇到不同的问题。 因此,对整个过程进行更详细的说明可能会有所帮助。 本教程的目的是提醒您该体系结构使用路由器的遥测流,并详细说明如何在不同模式下使用管道。 这份文件很长,有意为之。 目的是将所有内容都放在一个地方。 您将可以快速跳转到感兴趣的部分。如果您认为需要记住如何在IOS XR路由器上配置模型驱动遥测的基础知识,请查看我们的上一篇文章。
典型的基本分析平台架构
我们仍然收到的第一个普遍问题是,是否可以重新使用现有的SNMP收集器来使用和处理流遥测。 最简洁的答案是不”。 长远的答案是,遥测不仅比SNMP快得多,而且具有不同的格式,因此,该数据的处理也不同。 在遥测方面,人们可能会想到这种高级架构:
- 收集层:数据从路由器流出来的第一站。 主要目标是收集所有流,并将它们从GPB / JSON转换为上一层将支持的格式。 过滤也可能在这里配置。
- 存储层:通常是TSDB(时间序列数据库)。 目标是从“集合层”中获取数据并将其与时间戳一起存储。 您还可以在此处拥有其他类型的数据库(将遥测视为大数据解决方案)。
- 应用程序层:在这里,您可以对存储在存储层中的数据应用业务逻辑工具。
到目前为止,您应该已经基本了解了三层体系结构。 有关将此体系结构映射到实际解决方案的问题可能会出现。
这是针对IOS-XR模型驱动的遥测消耗的基于开源的端到端解决方案:
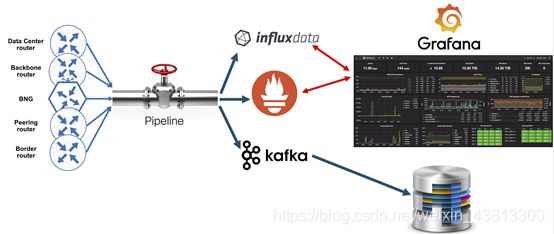
解决方案中的所有元素都可以从Github下载(当然,路由器除外!)。 管道代表“集合层”。 InfluxDB和Prometheus代表“存储层”,即存储数据的地方。 Grafana是“应用程序层”的一个示例。 到目前为止,Grafana是一种非常流行的可视化工具,可用于监视和警报。 管道还可以将数据流传输到Kafka总线。 您可以连接自己的数据库以使用Kafka总线上的数据。 管道是本教程的主题。 在以下教程中将详细解释存储和应用程序层。
管道:简要概述
管道是编写良好的基于Golang的代码,它直接从路由器或从发布/订阅总线(Kafka)间接使用IOS XR遥测流。 收集后,管道将执行数据转换并将结果转发给已配置的使用者。
管道支持来自路由器的不同输入传输格式(请注意,任何类型的多个输入模块都可以并行运行):
• TCP
• gRPC
• UDP
• Apache Kafka
管道也可以支持不同的编码:
• (compact) GPB
• KV-GPB
• JSON
管道可以将数据流传输到几个不同的使用者。 支持的下游消费者包括:
• InfluxDB (TSDB)
• Prometheus (TSDB)
• Apache Kafka
• dump-to-file (mostly for diagnostics purposes)
管道:如何开始
有两种方法可以在Linux服务器上安装管道:
- 从Github克隆或下载
- 作为Docker容器安装
“ Pipeline.conf”包含配置收集器所需的所有内容。 它包含几个输入部分(可以在其中定义希望收集器与路由器交互的方式)和不同的输出部分(以定义要将处理的数据发送到何处)。
“ Metrics.json”是您需要定义要插入TSDB(InfluxDB,Prometheus)的位置。
管道是管道收集器的二进制文件,可以在“ bigmuddy-network-telemetry-pipeline / bin”目录中找到。
要使管道运行,必须启动二进制文件。有几种方法可以做到这一点:
- 最简单的方法就是按原样启动二进制文件。为此,您需要转到“ bigmuddy-network-telemetry-pipeline”目录并发送此命令“ ./bin/pipeline”。启动Pipeline之后,系统将在当前目录中检查“ pipeline.conf”文件(因此,要从“ / bin”目录启动Pipeline,您需要在此复制“ pipeline.conf”文件。) ,也许从主目录开始更容易)
- 还有另一种方法可以使用另一个(您自己的)“ pipeline.conf”配置文件版本启动管道。例如,您要快速检查新的管道配置,但不想更新当前的有效配置。您可以只创建“ pipeline.conf”的副本,进行所有必要的更改,然后使用以下命令运行该管道以指定该文件:./bin/pipeline -config =“ pipeline_test.conf”
- 当您想查看内部日志消息时,一个很好的选择就是以这种方式启动:./bin/pipeline -log = --debug。
选项3对于测试非常有用,当您想检查路由器如何连接到管道(或管道连接到路由器)或出现问题时,可以检查日志消息,因为这将加快故障排除活动。 当您准备好迁移到扩展环境时,最好尽可能简化管道操作,并使用选项1或2启动它。
管道:metrics.json
IOS XR模型驱动遥测基于YANG模型,因此从路由器推送的遥测数据也是分层的。 时间序列数据库(InfluxDB,Prometheus等)通常期望数据采用简单的平面格式。 管道采用基于YANG的分层数据,并将其转换为平面格式以供TSDB使用。 为了执行此转换,管道使用“ metrics.json”文件。 “ metrics.json”文件是一系列JSON对象,每个配置的传感器路径一个。 每个对象都遵循相应的YANG模型,您可以指定要添加的字段(计数器)。
可以在GitHub存储库中找到“ metrics.json”文件的示例。 它已经包含以下模型:
- 接口状态(通用计数器)。
- MPLS-TE隧道自动带宽。
- QoS输出统计信息。
- 处理内存信息。
- RAM /可用空间/系统内存信息。
- CPU利用率。
最初似乎很难创建“ metrics.json”文件的内容,但是一旦开始使用它,您就会发现背后的逻辑。 标头始终保持相同的格式,只需更新传感器路径即可。 最后,您遵循YANG模型并选择您要关注的字段(尊重模型的层次结构)。 举例来说,让我们看看将单跳IPv4 BFD YANG模型转换为“ metrics.json”对象后的外观。 这是YANG模型以及我们感兴趣的具体路径:
vosipchu$ pyang -f tree Cisco-IOS-XR-ip-bfd-oper.yang --tree-path bfd/ipv4-single-hop-summary
module: Cisco-IOS-XR-ip-bfd-oper
+--ro bfd
+--ro ipv4-single-hop-summary
+--ro session-state
+--ro total-count? uint32
+--ro down-count? uint32
+--ro up-count? uint32
+--ro unknown-count? uint32
这就是您可以在“ metrics.json”文件中构建内容的方式:
{
"basepath" : "Cisco-IOS-XR-ip-bfd-oper:bfd/ipv4-single-hop-summary",
"spec" : {
"fields" : [
{"name":"session-state",
"fields" : [
{"name":"down-count"},
{"name":"total-count"},
{"name":"unknown-count"},
{"name":"up-count"}
]
}
]
}
},
在我们的下一期教程中,我们将共享“ metrics.json”文件,其中包含用于许多流行传感器路径的JSON对象,以及用于方便和更快采用Telemetry的用例!
管道:内部监控
管道已经带有一个基本配置,该配置在端口5432上接受基于TCP的遥测,并将处理后的数据转储为JSON格式的文件。 (我们将在本教程的后面部分介绍所有配置)。 除此之外,用于管道监控的内部状态导出也处于活动状态。 除此之外,您无需配置其他任何内容,但这可用于Prometheus时间序列数据库。 这并不意味着您仅需对所有其他传感器路径使用Prometheus,但应使其运行。 您还可以使用Pipeline GitHub存储库中的脚本来启动Prometheus进行监视。
这是负载下管道的快照(下面未显示所有受监视的参数):
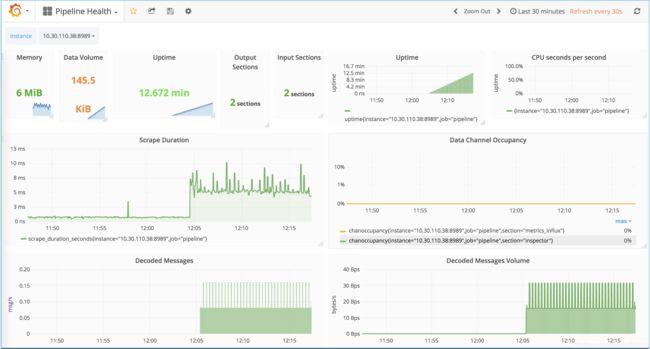
如果由于某种原因禁用了内部监视,则需要确保在“ Pipeline.conf”文件的[default]部分下有这两行(您可以在文件的开头找到它):
metamonitoring_prometheus_resource = /metrics
metamonitoring_prometheus_server = 10.1.1.1:8989 ## put the IP address and port of your Prometheus server
管道:TCP拨出
如前所述,管道有几种输入方法。 让我们从TCP Dial-OUT模式配置开始。 在这种情况下,您将TCP用作流式遥测数据传递的传输协议。 并且默认启用此模式! 为了确保Pipeline接受并处理遥测数据,您需要确保路由器上的配置与Pipeline上的配置相对应。
这是要对TCP Dial-OUT模式进行的配置:
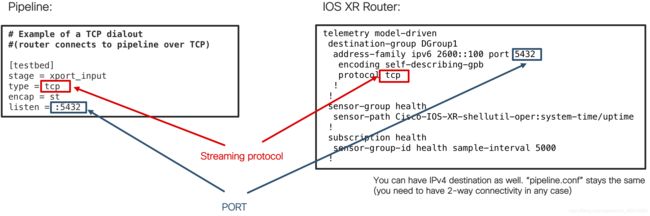
如您所见,配置非常简单。 您可以使用IPv6或IPv4目标地址,管道与两者都可以正常工作。 TCP的主要要求是双向连接,因为TCP是面向连接的协议。 您需要确保路由器上的目标端口等于管道上的侦听端口。 如果服务器上有多个IP地址/ NIC,则Pipeline将侦听每个接口上的指定端口。 如果要具体说明,还可以在“管道”配置中添加IP地址。 IPv4地址的格式为:
listen = ipv4_address:port
IPv6地址的格式为:
listen = [ipv6_address]:port
到目前为止,IOS XR支持多种编码协议:
- 紧凑型GPB
- 键值GPB
- JSON格式
您可以继续进行任何喜欢的编码,但是在管道方面,配置始终保持为:
encap = st
这个小功能会让您的生活更轻松!
如果一切配置正确,双向连接已建立,并且您在调试模式下运行Pipeline,则应该在stdout中得到类似的消息:
INFO[2017-11-15 14:07:41.898128] TCP server accepted connection encap=st keepalive=0s local="[2600::100]:5432" name=testbed remote="[2222:beaf:13::3]:55137" tag=pipeline
这是启动并运行TCP Dial-OUT模式所需的所有知识!
管道:UDP拨出
IOS XR 6.2.x版本中增加了IOS XR模型驱动的遥测中的UDP拨出支持,它可能是使用流遥测进行快速测试的不错选择。 UDP是无连接协议,因此,您只需与收集器建立单向连接。 缺少从管道返回到路由器的反馈以及不可靠的数据包传递是在生产环境中使用基于UDP的流遥测的两个主要问题。
UDP拨出模式配置类似于TCP拨出模式。 这是UDP拨出模式的配置:

与TCP拨出一样,您可以使用IPv6或IPv4地址到达“管道”。 您可以在路由器上使用任何可用的编码协议(GPB,KVGPB或JSON),管道中的编码配置将保持不变(“ encap = st”),因为没有与之建立连接,因此在管道中的stdout中不会出现任何消息传递 UDP。
这是启动和运行UDP拨出模式所需的所有知识!
gRPC:有关的知识
在继续使用其他输入模式之前,让我们先简短介绍一下gRPC。 gRPC是跨客户安装的最流行的传输协议。原因是它基于HTTP / 2并具有许多优点:
- 拨入和拨出支持
- 二进制模式
- 加密支持
- 应用程序层的窗口机制(收集器和路由器之间的速度协商)
要运行gRPC,您需要在路由器和收集器之间建立双向连接。这听起来很合理,但是您应该始终记住,IOS XR路由器中的gRPC代码在Linux中作为第三方应用程序运行(要了解有关IOS XR中应用程序托管的更多信息,请在此处查看),因此,这就是为什么基于32位QNX的XR上的gRPC支持!)。因此,这意味着您需要从那里准确检查连接!
以下是检查连接性所需执行的步骤:
- 在CLI执行模式下,键入“ bash”(这将使您进入gRPC应用程序)
- 从那里使用“ ip route show” Linux命令检查路由表
- 如果没有到达目的地的路线,则必须添加它。否则,请尝试ping(并希望得到您的回声回复!)
这是上述步骤的示例:
RP/0/RP0/CPU0:NCS5502_bottom#bash
Wed Feb 21 09:06:47.963 PST
[NCS5502_bottom:~]$ ip route show
default dev fwdintf scope link src 172.16.0.3
10.30.110.32/27 dev Mg0_RP0_CPU0_0 proto kernel scope link src 10.30.110.43
[NCS5502_bottom:~]$ ping 10.30.110.38
PING 10.30.110.38 (10.30.110.38) 56(84) bytes of data.
64 bytes from 10.30.110.38: icmp_seq=1 ttl=64 time=0.751 ms
64 bytes from 10.30.110.38: icmp_seq=2 ttl=64 time=0.962 ms
^C
在深入解释如何解决没有正确路线到达收集器的情况之前,让我们看一下上面的路由表输出。该输出应该与在使用gRPC启用MDT之后将看到的输出非常相似。默认路由(蓝色)用于所有通过数据平面端口流出的遥测流量。在路由器上配置了第一个环回后,它将自动创建(如果还没有环回,则不会自动创建)。洋红色显示的路由表示流经管理端口的所有流量,并且还会自动为您创建。
让我们考虑一下两种可能的情况,其中可能需要更改路由表。第一个是您的收集器位于数据端口后,但无法通过选定的环回接口访问。还有另一种情况,即您的管理网络中有收集器,但没有到该目标的路由(您仅通过管理端口具有直接连接的网络,而默认路由是通过数据端口)。在这两种情况下,您都需要更新TPA路由表。实现此目的的最佳方法是在IOS XR中的TPA配置下配置所需的源接口。这是更改通过管理端口的默认路由的示例:
tpa
vrf default
address-family ipv4
update-source MgmtEth0/RP0/CPU0/0
!
!
!
更改的结果是:
RP/0/RP0/CPU0:NCS5502_bottom#bash
Wed Feb 21 11:37:13.271 PST
[NCS5502_bottom:~]$ ip route show
default dev fwdintf scope link src 10.30.110.43
10.30.110.32/27 dev Mg0_RP0_CPU0_0 proto kernel scope link src 10.30.110.43
如您所见,默认路由已使用管理端口的IP地址更新。 您可以在我们以前的文章中阅读更多有关gRPC技巧的信息。 值得一提的是,您正在此处使用Linux,并且可以使用Linux命令添加路由:
route add –net ip_address netmask mask gw your_gw_address
但是在这种情况下,它将在第一次重新启动之前可用(然后您需要重新配置它或使此过程自动化)。
该部分中描述的所有内容对于拨入和拨出模式均很重要。 双向连接意味着路由器应该能够到达收集器,反之亦然,收集器将需要具有通往路由器的路径。
管道:gRPC拨出(无TLS)
当今,遥测最常见的模式是不加密的gRPC拨出(无TLS选项)。 之前已经说明了此选项,因此让我们快速回顾一下配置并指出先前版本的几个更新。
这是gRPC拨出(无TLS)模式要完成的配置:
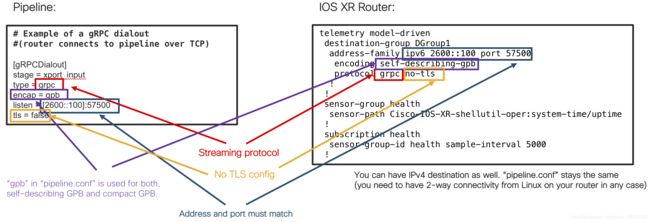
有几个时刻需要更多注意。 在路由器上配置“ self-describing-gpb”(键值GPB)或“ gpb”(紧凑型GPB)时,始终在“ pipeline.conf”文件中配置“ encap = gpb”。 如果要使用JSON编码,则必须在“ pipeline.conf”文件中包含以下行:
“encap = json”
其他所有内容均遵循与先前模式相同的逻辑。 只需确保检查路由器和管道中是否禁用了TLS。
如果一切配置正确,双向连接已建立,并且您在调试模式下运行Pipeline,则应该在stdout中得到类似的消息:
INFO[2017-11-15 14:20:26.098695] gRPC: Receiving dialout stream encap=json name=grpcdialout peer="[2500::3]:59206" server=[2600::100]:57500 tag=pipeline type="pipeline is SERVER"
这是启动gRPC拨出(无TLS)模式所需的所有知识!
管道:gRPC拨出(TLS)
gRPC具有SSL / TLS集成,并促进使用SSL / TLS对服务器进行身份验证并加密客户端与服务器之间交换的所有数据。它类似于SNMPv3(增加了安全性)。在拨出模式下,路由器是“客户端”,管道是“服务器”。因此,在TLS握手中,管道需要发送证书以对路由器进行身份验证。路由器使用签署该证书的根证书颁发机构(CA)的公共证书来验证管道的证书,然后生成会话密钥以对会话进行加密。以这种模式运行需要您拥有证书并准备好基础设施。但是,如果您只想尝试此模式,则可以使用两种方法:
-
请遵循本教程中的步骤,或者
-
请遵循本文档中的步骤。从这里开始下载包含三个文件的档案
下载存档并从中提取文件之后,请按照下列步骤操作: -
将“ dialout.pem”和“ dialout.key”文件放在运行Pipeline的服务器上您喜欢的任何文件夹中。记住路径(稍后将在“ pipeline.conf”文件中使用该路径)
-
将路由器上的“ ca-chain.cert.pem”文件放置到以下目录:“ / misc / config / grpc / dialout”文件夹(从CLI - exec模式使用“ run”进入Linux,然后进入标准SCP命令)。
-
将“ ca-chain.cert.pem”文件的名称从第二步更改为“ dialout.pem”。
完成上述所有步骤之后,请确保您在路由器和管道上具有正确的配置(目标,编码和类型与在gRPC Dial-OUT no TLS模式下保持相同):
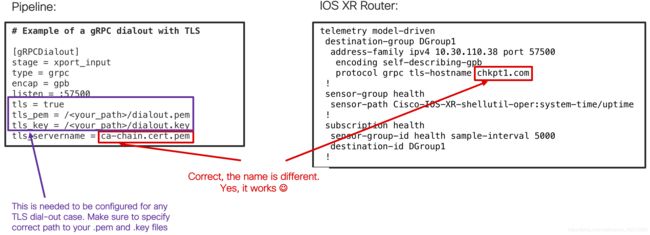
您需要指定服务器上“ dialout.pem”和“ dialout.key”文件的完整路径。 这就是Pipeline如何知道在哪里可以找到所需证书的方式。
如果按照这些步骤进行操作,则应该在调试模式下看到管道的类似输出:
INFO[2017-11-17 20:45:54.732520] gRPC: Receiving dialout stream encap=gpb name=grpcdialout peer="10.30.110.43:59914" server=10.30.110.38:57500 tag=pipeline type="pipeline is SERVER"
这是路由器成功连接的指示:

TLS模式下的gRPC拨出最常见的问题是证书错误。 如果发生这种情况,您将从管道中看到类似的消息:
2017/11/17 15:51:20 grpc: Server.Serve failed to complete security handshake from "10.30.110.43:58954": remote error: tls: bad certificate
这是启动gRPC拨出(TLS)模式并运行所需的一切!
管道:gRPC拨入(无TLS)
gRPC使收集器可以拨入路由器并请求将遥测数据流式传输。 如果您希望采用集中方式在网络中进行配置和请求操作数据,则此模式可能对您方便。
路由器端需要进行一些更改以支持Dial-IN模式。
首先,您需要确保为gRPC会话打开了一个端口:
grpc
port 57500
address-family ipv6 ## this is only needed if you plan to use IPv6
在gRPC配置下指定的端口号应等于在收集器(管道)上配置的端口。 我们的示例基于IPv6,因此,它也必须在gRPC配置下指定(对于IPv4情况,请跳过该行)。
当管道连接到路由器时,需要进行身份验证。 换句话说,管道需要提供在路由器内具有适当权限的登录名/密码对。 在我们之前的教程中,对管道身份验证有很好的概述和描述。 为了使操作更简单,更快捷,我们只需创建一个登录名/密码对并添加“ root-lr”组即可:
username
group root-lr
group cisco-support
secret 5 $1$uuqh$Pl5K1G.aaZUtPlV4LouAk/
提交上述配置后,其余遥测配置与其他情况类似:
telemetry model-driven
sensor-group health
sensor-path Cisco-IOS-XR-shellutil-oper:system-time/uptime
!
subscription health
sensor-group-id health sample-interval 5000
如您所见,不需要“目标组”部分。 这是正确的,并且对于Dial-IN模式是预期的,因为要使用的编码和预订将在gRPC调用中进行。 这是采用KV-GPB编码模式的拨入(无TLS)的管道配置的样子:
[grpc_in_mymdtrouter]
stage = xport_input
type = grpc ## transport is gRPC
encoding = gpbkv ## Key-Value GPB encoding
encap = gpb ## use “gpb” for both, compact and key-value GPB
server = [2500::3]:57500 ## IP address and port of the router
subscriptions = health ## specify the subscription to be used (it has to be configured)
tls = false ## no TLS
有几件事值得您注意:
-
传输始终是“ grpc”(唯一支持Dial-IN的协议)。
-
端口号应与路由器上配置的端口号相同。 (对于IPv4地址,您无需包括方括号,只需键入:“ server = IP_address:port”)
-
您可以指定多个订阅,并用逗号分隔它们,例如 “订阅= health1,health2,health2”
拨入模式可以有不同的编码:GPB,KV-GPB和JSON。 这是您需要在拨入模式下为不同的编码配置管道的方法: -
GPB编码:“ encap = gpb”和“ encoding = gpbcompact”
-
KV-GPB编码:“ encap = gpb”和“ encoding = gpbkv”
-
JSON编码:“ encap = json”和“ encoding = json”
下一步是启动管道。 启动后,将要求您输入路由器的登录名/密码对(与路由器上定义的相同):
$ bin/pipeline -config pipeline.conf
Startup pipeline
Load config from [pipeline.conf], logging in [pipeline.log]
CRYPT Client [grpc_in_mymdtrouter], [[2500::3]:57500]
Enter username: cisco
Enter password:
Wait for ^C to shutdown
如果您不想执行此步骤(手动输入),则可以将登录名/密码对存储在“ pipeline.conf”文件中,但是密码将不能以明文形式存储。 有一种方法可以加密“ pipeline.conf”文件中的密码,完整的描述在这里。 如果gRPC调用成功,您将在屏幕上看到类似的输出(管道应处于调试模式):
INFO[2017-11-15 16:51:09.093983] gRPC: Connected codec=gpb encap=gpb encodingRequest=gpbkv name="grpc_in_mymdtrouter" server=[2500::3]:57500 subscriptions=[health] tag=pipeline type="pipeline is CLIENT" username=cisco
您还可以另外检查路由器上的状态:
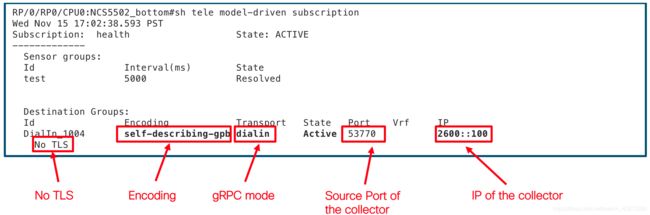
这是启动gRPC拨入(无TLS)模式并运行所需的一切!
管道:gRPC拨入(TLS)
在Dial-IN模式下,管道充当TLS握手中的“客户端”。 因此,路由器将需要发送证书以对管道进行身份验证。 与以前的模式一样,您需要在路由器上配置gRPC端口,但是这次您需要添加“ tls”支持:
grpc
port 57500
tls
使用TLS配置提交此gRPC后,路由器将生成一个自签名证书,您需要将其复制到运行Pipeline的服务器:
RP/0/RP0/CPU0:NCS5502_bottom#run
Fri Nov 17 20:54:21.285 PST
[xr-vm_node0_RP0_CPU0:~]$cd /misc/config/grpc
[xr-vm_node0_RP0_CPU0:/misc/config/grpc]$ls
dialout ems.key ems.pem ## copy ems.pem to the server with Pipeline
要进行复制,可以使用Linux中的标准SCP命令:
[xr-vm_node0_RP0_CPU0:/misc/config/grpc]$scp ems.pem your_username@pipeline_server:/some/remote/directory
其余配置与以前的gRPC Dial-IN no TLS模式相同。
这是管道配置的外观:
[grpc_in_mymdtrouter]
stage = xport_input
type = grpc
encoding = gpbkv
encap = gpb
server = 10.30.110.43:57500
subscriptions = health
tls = true ## TLS is enabled
tls_pem = /somepath/ems.pem ## specify the path to the ems.pem certificate
tls_servername = ems.cisco.com ## specify the name
本示例基于IPv4配置,只是为了显示与以前方案的区别。 配置保持与gRPC拨入(无TLS)模式相同,但是这次您需要激活TLS模式并定义证书的路径。
启动管道并输入登录名/密码对后,您将看到类似的日志消息:
INFO[2017-11-17 21:11:42.987607] setup authentication authenticator="10.30.110.43:57500" name=grpcdialout pem= tag=pipeline username=cisco
DEBU[2017-11-17 21:11:42.987942] Conductor watching for shutdown... config=pipeline.conf debug=true logfile= tag=pipeline
INFO[2017-11-17 21:11:42.988039] gRPC starting block encap=gpb encodingRequest=gpbkv name=grpcdialout server=10.30.110.43:57500 subscriptions=[health] tag=pipeline type="pipeline is CLIENT" username=cisco
INFO[2017-11-17 21:11:42.988976] gRPC: Connected codec=gpb encap=gpb encodingRequest=gpbkv name=grpcdialout server=10.30.110.43:57500 subscriptions=[health] tag=pipeline type="pipeline is CLIENT" username=cisco
INFO[2017-11-17 21:11:43.024879] gRPC: Subscription handler running encap=gpb encodingRequest=gpbkv name=grpcdialout reqID=7821695275122717908 server=10.30.110.43:57500 subscription=health subscriptions=[health] tag=pipeline type="pipeline is CLIENT" username=cisco
您还可以在路由器上检查状态:

这是启动gRPC拨入(TLS)模式并运行所需的一切!
本节总结有关输入模块的信息。 现在让我们讨论一下您可以在管道中使用的输出模块。
管道:转到“ dump.txt”
有几种方法可以配置要从管道中推出的数据。 当您刚开始探索管道时,转储到文件可能是开始的最佳选择。 您将能够看到路由器正在流式传输的数据内容,并且可以更轻松地继续使用TSDB。 下载管道时,默认情况下转储到文件是活动的。 在这种模式下,每个遥测数据包都会通过管道进行转换,并写入“ dump.txt”文件。 需要先手动创建此文件,然后才能在其中写入任何信息。 这是该模式的管道配置:
[inspector]
stage = xport_output
type = tap
file = /home/pipeline/bin/dump.txt ## the full path to the file is needed
encoding = json
## countonly = false
如您所见,配置很简单。 关于此模式有一些重要的评论:
- 您需要指定“ dump.txt”文件的完整路径,并且需要在启动管道之前创建此文件。 否则,您将看不到任何东西。
- 有一个选项可以禁用遥测数据转换,同时仍保持与路由器的连接处于UP模式,并且仅计算进入的遥测数据包的数量。当您要测试遥测速度并且不想进行故障排除时,该模式非常有用 在运行管道的服务器上处理缓慢。 要启用此模式,请将“ countonly = false”更改为“ countonly = true”。
这是syslog传感器路径中“ dump.txt”文件中成功记录的示例:
Summary: GPB(common) Message [10.30.110.41:60914(NCS5501_top)/Cisco-IOS-XR-infra-syslog-oper:syslog/messages/message msg len: 2214]
{
"Source": "10.30.110.41:60914",
"Telemetry": {
"node_id_str": "NCS5501_top",
"subscription_id_str": "test",
"encoding_path": "Cisco-IOS-XR-infra-syslog-oper:syslog/messages/message",
"collection_id": 72000,
"collection_start_time": 0,
"msg_timestamp": 1516238643814,
"collection_end_time": 1516238643814
},
"Rows": [
{
"Timestamp": 1516238643811,
"Keys": {
"message-id": 1600
},
"Content": {
"card-type": "RP",
"category": "SECURITY",
"group": "SSHD",
"message-name": "INFO_USER_LOGOUT",
"node-name": "0/RP0/CPU0",
"process-name": "SSHD_",
"severity": "message-severity-informational",
"text": "SSHD_[68638]: %SECURITY-SSHD-6-INFO_USER_LOGOUT : User 'cisco' from '10.154.161.88' logged out on 'vty20' \n",
"time-of-day": "Jan 17 17:24:00.240 : ",
"time-stamp": 1516238640000,
"time-zone": "PST"
}
},
浏览“ dump.txt”文件的内容可以给您路由器流出的计数器的图片。
请注意,如果以很高的速度流式传输大量数据,则“ dump.txt”将占用大量空间(不压缩,如在时间序列数据库中一样,文本按原样存储)。
这就是将数据推送到“ dump.txt”文件模式配置时所需要了解的一切!
管道:到InfluxDB
最受欢迎的选项是将数据流式传输到InfluxDB(时间序列数据库或TSDB)中。 在这里,您将存储遥测数据,以便以后由其他工具(例如Grafana)检索。 InfluxDB和Grafana配置说明将在以后的单独教程中介绍。 如果您想立即获得一些初步信息,请在此处查看。
InfluxDB的管道配置非常简单:
[metrics_influx]
stage = xport_output
type = metrics ## specify the type of the file to be used to select data to be accepted into the TSDB
file = /home/pipeline/metrics.json ## define the location of this file
datachanneldepth = 10000 ## optionally, specify a buffer for the data
output = influx ## destination is InfluxDB
influx = http://10.30.110.38:8086 ## address and port of InfluxDB (can be IPv6 as well)
database = mdt_db ## the database within InfluxDB (you will have to create it)
workers = 15 ## a number of threads working internally (bigger means more threads to be activated)
#dump = metricsdump.txt ## a local dump file for InfluxDB
如您所见,InfluxDB的Pipeline配置非常简单。有几个时刻需要您注意:
- 您应该指定“ metrics.json”文件的完整路径。
- 未在“ metrics.json”中定义的所有内容都将被删除,并且不会插入InfluxDB中。
- 您需要在InfluxDB内部指定一个特定的数据库。该数据库不是由自己创建的,一旦安装了InfluxDB,就应该创建此数据库。
- 当您刚刚开始测试InfluxDB时,启用对插入数据库的所有数据的本地日志记录(启用“转储”)可能会有所帮助。您将能够快速检查“ metrics.json”文件是否正确以及是否包含所有需要的信息(以后,随着您更加自信,您将能够直接进入InfluxDB并在其中检查信息)。与SQL非常相似且易于使用的InfluxDB查询语言。
请注意,如果以非常高的速度流式传输大量数据,“ metricsdump.txt”文件将占用大量空间(不涉及压缩,并且文本另存为字符串,而InfluxDB则执行有效的压缩数据同时存储)。
这就是开始将数据推送到InfluxDB并使其启动并运行所需的一切!
管道:到Prometheus
第二个可能的时间序列数据库是Prometheus。 默认情况下,Prometheus更喜欢基于拉取的指标集合。 这意味着Prometheus将定期收集指标并将其存储在其数据库中。 这种方法与遥测目标不符,因此,您需要再添加一个将度量标准直接推送到Prometheus的工具。 该工具是PushGW。 考虑到这些信息,我们可以继续进行管道配置:
[metrics_influx]
stage = xport_output
type = metrics ## specify the type of the file to be used to select data to be accepted into the TSDB
file = /home/pipeline/metrics.json ## define the location of this file
datachanneldepth = 10000 ## optionally, specify a buffer for the data
output = prometheus ## this is where you specify that the destination is Prometheus
pushgw = 10.30.110.38:9091 ## address and port of PushGW
jobname = telemetry ## Specify a jobname to be used
statsensorcount = 1000 ## must be set for any stats to be exported
如您所见,这里没有什么困难。 这就是开始将数据推送到Prometheus并使其启动并运行所需的一切!
管道:到Kafka
涉及管道的最后一个选项是如何将数据流式传输到Kafka总线。 如果您只想在某处流式传输数据并让几个客户端连接到它,则可能会很有用。 在这种情况下,您将转换后的数据推送到总线上,然后使用者订阅它。
这是将数据推送到Kafka的管道配置:
[output_kafka]
stage = xport_output
type = kafka ## specify the type of the output
encoding = json ## JSON is used as the encoding
brokers = 10.30.110.38:32768 ## specify a Kafka broker
topic = telemetry ## specify a name of the topic
这就是开始将数据推送到Kafka总线并使其启动并运行所需的一切!
这么多方法……最好的方法是什么?
管道中有许多选项供您选择。 创建本教程的目的是帮助您更好地理解管道,其好处和可能性。 如果您觉得自己有些迷茫,并在思考最佳入门方法,请尝试查看此堆栈:IOSXR-> Pipeline-> InfluxDB-> Grafana。 它已通过许多试验证明,并且很容易安装和运行。
结论
Pipeline是一种轻量级但功能非常强大的工具,您可以立即下载并开始使用。 它使您可以灵活地探索遥测,了解遥测的工作原理以及YANG模型的速度和广泛覆盖范围带来的好处。 仍有许多问题有待解决,我们将竭尽所能,以确保您详细了解在[近]实时监控和自动化过程中可能需要的所有内容。 在接下来的教程中,我们将介绍激活遥测时的期望,遥测在内部的工作方式以及有趣的用例,您可以自己下载和尝试。 和我们在一起!
向开源大神致敬