MySQL(1):开始
概述
DB:数据库(Database)
即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
DBMS:数据库管理系统(Database Management System)
是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控
制。用户通过数据库管理系统访问数据库中表内的数据。
SQL:结构化查询语言(Structured Query Language)
专门用来与数据库通信的语言。
数据库是数据的集合,而数据库管理系统(DBMS)是用于管理这些数据的软件。 DBMS 允许用户对数据库进行操作、查询和维护。
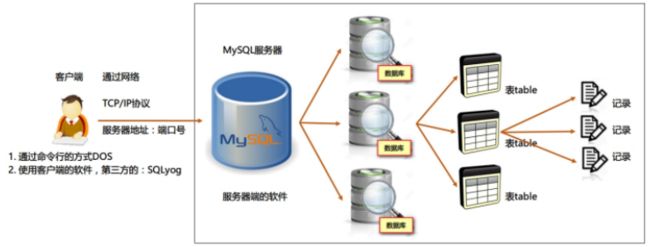
MySQL 概述
MySQL是一种流行的开源关系型数据库管理系统(RDBMS),最初由瑞典公司MySQL AB开发。随后,MySQL被Sun Microsystems收购,随后又被Oracle Corporation收购。MySQL以其易用性、稳定性、高性能和开源免费等特点而备受青睐。
特点:
开源性:MySQL是开源的,可以免费获取并在许多操作系统上使用。
跨平台:支持多种操作系统,包括Windows、Linux、macOS等。
性能优化:拥有高性能的存储引擎和优化功能,适用于大型和小型应用。
可扩展性:支持垂直和水平的扩展,适用于不同规模和需求的应用。
安全性:提供访问控制和加密功能,确保数据的安全性。
事务支持:支持事务处理,允许将操作打包成原子性工作单元。
SQL兼容:使用标准的SQL语言进行查询和管理数据。
主要功能:
数据存储:MySQL使用表格(table)来组织数据,支持多种数据类型。
索引:支持各种索引技术,包括B-tree索引、哈希索引等,用于加快查询速度。
视图:允许用户通过视图来虚拟化表,简化复杂查询和保护数据。
存储过程和触发器:支持存储过程和触发器,允许在数据库中执行预定义的程序和操作。
复制和故障转移:具有复制功能,允许将数据复制到其他服务器以实现高可用性。
分区功能:支持对大型表格进行分区,有助于提高查询和管理效率。
管理工具:提供多种管理工具,如MySQL Workbench等,用于管理数据库和执行查询。
关系型数据库(RDBMS)
数据结构:关系型数据库以行(row) 和 列(column) 的形式存储数据,以便于用户理解。其中每行代表一个记录,每列代表不同的数据字段。
SQL:使用结构化查询语言(SQL)进行数据管理和查询。
事务处理:支持事务处理,允许将操作打包为原子性的工作单元,保证数据库的一致性。
数据一致性:严格遵循ACID(原子性、一致性、隔离性、持久性)特性。
Schema:需要定义表结构,即预先定义表和其字段的结构,保证数据的完整性和一致性。
优势:
复杂查询——可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
事务支持——使得对于安全性能很高的数据访问要求得以实现
非关系型数据库(非RDBMS)
数据结构:Non-RDBMS使用多种数据结构,如文档、键值对、列族、图形等,来存储和组织数据。
查询语言:通常没有标准化的查询语言。一些提供了API来操作数据。
分布式系统:许多非关系型数据库是设计用于分布式系统,能够处理大量的数据和高并发。
灵活性:相较于RDBMS,非关系型数据库更加灵活,不需要严格的预定义模式(Schemaless),允许更自由的数据添加和修改。
水平扩展:更容易进行水平扩展,即通过添加更多的节点来扩展数据库系统,而不是依赖于单一节点的垂直扩展。
非关系型数据库:有键值型数据库、文档型数据库、搜索引擎数据库、列式数据库等。
1.键值型数据库(Key-Value Stores):
特点:基于键值对存储数据,每个数据项都由唯一的键和对应的值组成。键值型数据库适用于快速存储和检索大量简单数据,性能高,但通常不支持复杂的查询操作。
例子:Redis、DynamoDB、Riak等。
2.文档型数据库(Document Stores):
特点:存储的是类似文档的结构,通常使用类似JSON或XML的格式。这种数据库适合存储和查询结构化和非结构化的数据,支持嵌套式数据结构。
例子:MongoDB、Couchbase等。
3.列式数据库(Column-Family Stores):
特点:数据存储在列族中,而非传统的行结构。适用于需要快速读取大量数据的场景,尤其是针对大规模数据集的聚合操作。
例子:Apache Cassandra、HBase等。
4.图形数据库(Graph Databases):
特点:用于存储图形结构的数据,适合处理实体和它们之间复杂的关系。图形数据库用于解决关系非常复杂的数据模型。
例子:Neo4j、Amazon Neptune等。
5.搜索引擎数据库(Search Engine):
特点:专注于全文搜索和高效的文本检索,适合处理需要全文搜索功能的场景。
例子:Elasticsearch、Apache Solr等。
每种非关系型数据库类型都有其独特的特性和适用场景。选择数据库类型通常取决于数据模型、查询需求、性能要求以及应用程序的特定要求。这些数据库通常能够更好地适应大规模数据和分布式系统。
关系型数据库设计规则
一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。
表具有一些特性,这些特性定义了数据在表中如何存储,类似Java和Python中 “类”的设计。
表、记录、字段
E-R(entity-relationship,实体-联系)模型中有三个主要概念是: 实体集 、 属性 、 联系集 。
一个实体集(class)对应于数据库中的一个表(table),一个实体(instance)则对应于数据库表中的一行(row),也称为一条记录(record)。一个属性(attribute)对应于数据库表中的一列(column),也称为一个字段(field)。

ORM思想 (Object Relational Mapping)体现:
数据库中的一个表 <—> Java或Python中的一个类
表中的一条数据 <—> 类中的一个对象(或实体)
表中的一个列 <----> 类中的一个字段、属性(field)
表的关联关系
表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。
四种:一对一关联、一对多关联、多对多关联、自我引用。
1.一对一关联(One-to-One):
指两个表之间的关系,其中一个表的每个记录在另一个表中只有一个相关记录。
例如,在一个公司的数据库中,每个员工可能有唯一的员工编号,这可以与另一个表中的唯一身份证号相对应。
2.一对多关联(One-to-Many):
指两个表之间的关系,其中一个表的记录可以对应到另一个表中的多个记录。
例如,在一个订单和订单详情的关系中,一个订单可以对应多个订单详情,但一个订单详情只属于一个订单。
3.多对多关联(Many-to-Many):
指两个表之间的关系,其中一个表中的多个记录可以对应到另一个表中的多个记录。
这种关系需要通过中间表(连接表)来建立关联。例如,学生和课程之间的关系,一个学生可以选择多门课程,一门课程也可以被多个学生选择。
4.自我引用(Self-Referencing):
指一个表中的记录与该表中的其他记录建立关联。
例如,在员工表中,员工可能有上司,上司也是员工,因此可以在同一个表中使用自身的外键来表示员工和他们的上司之间的关系
设计规则
1.数据库范式化(Normalization):
目的是减少数据冗余,提高数据的一致性和完整性。
分解数据,确保每个表中的数据都是相关的,并且可以通过主键和外键关系连接起来。
2. 设定主键(Primary Key):
每个表应该有一个主键来唯一标识表中的每行数据。
主键应该是唯一且不可为NULL的。
3.设定外键(Foreign Key):
用来建立不同表之间的关联。外键通常是另一个表的主键。
外键用于维护表之间的引用完整性和数据一致性。
4.数据类型选择:
选择适当的数据类型来存储数据,例如整数、字符串、日期等。
使用适当的数据类型可以节省空间并提高查询性能。
5.数据约束(Constraints):
使用约束确保数据的有效性,如唯一性约束、非空约束、默认值约束等。
约束有助于维持数据的一致性和完整性。
6.正规化设计:
将数据分解成适当的表以消除重复数据,并使表结构更清晰、更灵活。
正规化设计有不同的范式,包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
7.性能优化:
设计数据库结构时要考虑查询和数据访问的性能。
使用索引来加速查询,但要避免过度索引影响写入性能。
8.文档化和维护:
记录数据库设计的文档,包括表结构、关系图等,以便日后维护和扩展数据库时参考
数据库学习视频:
【MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板】