异常检测--笔记一--概述
异常检测--笔记一--概述
- 什么是异常检测
-
- 异常检测的类别
- 异常检测任务分类
- 异常检测场景
- 异常检测方法简介
-
- 基于统计学的方法
- 线性模型
- 基于邻近度的方法
- 集成方法
- 机器学习
- 李宏毅老师:异常检测
-
- 异常检测不能简单的看成二分类
- 参考资料
什么是异常检测
根据相关场景,寻找出不符合预期的情况(数据)。识别如信用卡欺诈,工业生产异常,网络流里的异常(网络侵入)等问题。
异常检测的类别
①点异常(point anomalies)指的是少数个体实例是异常的,如下图中的离群点
②条件异常(conditional anomalies),又称上下文异常,指的是在特定情境下个体实例是异常的,在其他情境下都是正常的
③群体异常(group anomalies),又称集合异常,指定是个体实例自身可能不是异常在群体,但在集合中的个体实例出现异常的情况。

#图源于知乎作者:VoidOc
异常检测任务分类
有监督:训练集的正例和反例均有标签
无监督:训练集无标签
半监督:在训练集中只有正例,异常实例不参与训练
为什么3种监督都有呢?
我的理解:
因为异常检测的数据不好收集、不好处理
当数据集能够准确的人工标注,通过有监督可以通过机器学习等方法训练出分类器
当数据集无标签,或者难以准确无误的标注,只能使用无监督和半监督
异常检测场景
故障检测
医疗日常检测
网络入侵检测
欺诈检测
工业异常检测
时间序列异常检测
视频异常检测
日志异常检测
异常检测方法简介
基于统计学的方法
统计学方法对数据的正常性做出假定。它们假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。统计学方法的有效性高度依赖于对给定数据所做的统计模型假定是否成立。
异常检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。
线性模型
如PCA主成分分析方法,它的应用场景是对数据集进行降维。降维后的数据能够最大程度地保留原始数据的特征(以数据协方差为衡量标准)。其原理是通过构造一个新的特征空间,把原数据映射到这个新的低维空间里。PCA可以提高数据的计算性能,并且缓解"高维灾难"。
基于邻近度的方法
这类算法适用于数据点的聚集程度高、离群点较少的情况。同时,因为相似度算法通常需要对每一个数据分别进行相应计算,所以这类算法通常计算量大,不太适用于数据量大、维度高的数据。
基于相似度的检测方法大致可以分为三类:
①基于集群(簇)的检测,如DBSCAN等聚类算法。
聚类的主要目的通常是为了寻找成簇的数据,而将异常值和噪声一同作为无价值的数据而忽略或丢弃,在专门的异常点检测中使用较少。
②基于距离的度量,如k近邻算法。
③基于密度的度量,如LOF(局部离群因子)算法。
集成方法
基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。
Feature bagging:与bagging法类似,只是对象是feature。
孤立森林:假设我们用循环随机使用一个超平面来切割数据空间,切一次可以生成两个子空间,直到每个子空间只有一个数据点为止。那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
机器学习
在有标签的情况下,可以使用树模型(gbdt,xgboost等)进行分类,缺点是异常检测场景下数据标签是不均衡的,但是利用机器学习算法的好处是可以构造不同特征。
李宏毅老师:异常检测
异常检测不能简单的看成二分类
既然是异常检测,那就是存在两种情况:有异常和无异常,容易想到二分类的解决方案
但是李宏毅老师说不能将异常检测简单的看做二分类
原因:
①无法穷举所有异常,异常这个类别的数据特征可能变化很大,十分影响模型的分类效果(如下图中,李宏毅老师做了一个实验,看输入是否宠物小精灵的角色,可以看到异常数据有可能是不同动漫中的人物,可能是水壶… 无法穷举所有这些异常数据,导致异常这个类别的特征难以学习)
②难以收集数据(我理解是 异常数据不容易找出来打标签)

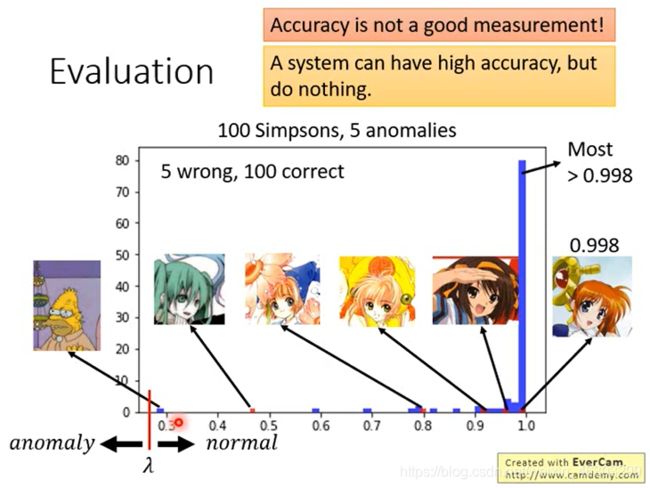
李宏毅老师还做了一个关于辛普森家族的异常检测(看输入是否是辛普森动漫中的人物)
做法是训练一个分类器,会将输入的图片预测是动画中的哪一个人物并输出概率(所有类别中最高的),当这个概率若小于一个设定的阈值则最终判断位异常。
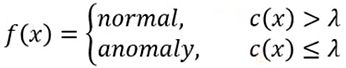

从图可以直观看出最终分类的效果并不好,同时阈值难以设置
参考资料
datawhale:https://github.com/datawhalechina/team-learning-data-mining/tree/master/AnomalyDetection
【李宏毅机器学习:异常检测 】Anomaly Detection(合辑)(中文):https://www.bilibili.com/video/BV1mb411q7b5?p=1
时间序列异常检测(一)—— 算法综述:https://zhuanlan.zhihu.com/p/142320349