机器学习笔记(含图像处理)
一、回归
1. 梯度下降
- 梯度下降是通过不断更新各个变量的参数得到代价函数的全局最小值,更新方式为:原来的参数-步长×代价函数对参数的偏导。
注意:迭代次数和步长需要由自己设定。 - 越接近最小值时,代价函数对参数的偏导(即斜率)就越小,则达到最小值就越慢。

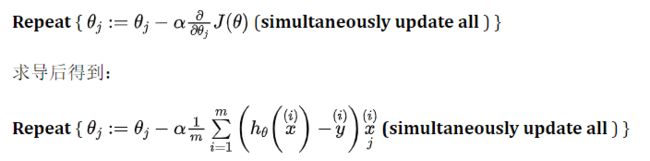
- 代码:
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost
2. 特征归一化
- 与正态分布的的标准化变形相似,因此可能与中心极限定理有关。
在概率论中,习惯于把和的分布收敛于正态分布这一类定理都叫做中心极限定理。

- 代码:
data2 = (data2 - data2.mean()) / data2.std()
data2.head()
3. 正规方程
- 公式:
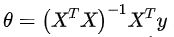
- 代码:
# 正规方程
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y#X.T@X等价于X.T.dot(X)
return theta
- 梯度下降与正规方程的比较:
梯度下降:需要选择学习率 α,需要多次迭代,当特征数量 n 大时也能较好适用,适用于各种类型的模型。
正规方程:不需要选择学习率 α,一次计算得出,需要计算
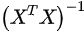
如果特征数量 n 较大则运算代价大,因为矩阵逆的计算时间复杂度为
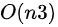
通常来说当小于 10000 时还是可以接受的,只适用于线性模型,不适合逻辑回归模型等其他模型。
二、逻辑回归
1. 代价函数
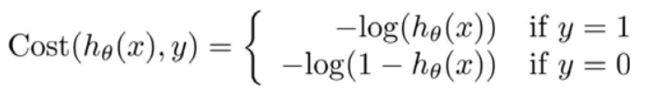
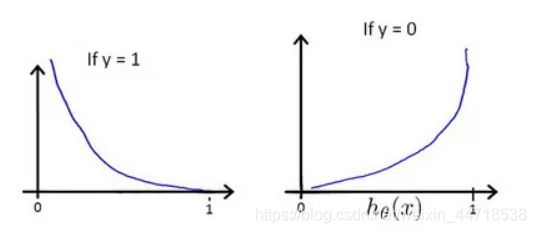

- 当标签值为1时,则只有当h(x)接近1时,代价函数才接近0;
- 当标签值为0时,则只有当h(x)接近0时,代价函数才接近0;
- 算法通过梯度下降,最终会选择代价函数值小的参数。
2. 正则化
- 线性回归
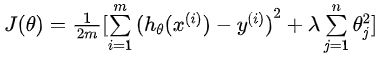
- 逻辑回归
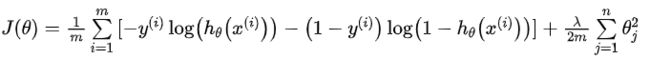
- 正则化的基本方法是在一定程度上减小参数的值。我们需修改代价函数,在参数中设置一点惩罚,这样算法寻找最小化代价值时也需要将这个惩罚纳入考虑中,最终导致选择较小的参数值。
- 从梯度下降更新参数的步骤可直观发现参数还减去了额外的值,因此最后得到的参数值也会更小。

- 如果选择的正则化参数λ过大,则会把所有的参数都最小化了,θ(不包括θ0)都会趋近于 0,这样我们所得到的只能是一条平行于x轴的直线。导致模型变成
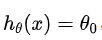
造成欠拟合。所以对于正则化,我们要取一个合理的 λ 值,这样才能更好的应用正则化。 - 代码 :
def gradient(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:,i])
grad[i] = np.sum(term) / len(X)
return grad
实际上我们没有在这个函数中执行梯度下降,而仅仅在计算一个梯度步长。我们可以用 SciPy 的“optimize”命名空间即 SciPy’s truncated newton(TNC)来实现寻找最优参数。
import scipy.optimize as opt
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
result
三、支持向量机
1. 代价函数

- C=1/λ
- C较大时,相当于λ较小,可能会导致过拟合,高方差。C较小时,相当于λ较大,可能会导致低拟合,高偏差。
- 有别于逻辑回归输出的概率,支持向量机最小化代价函数,获得参数时,所做的是用它来直接预测的值等于 1还是等于 0。
2.核函数
四、神经网络
1. 线性分类器
- 线性分类器是n维空间中的线性边界,在一维空间中是一个点,在二维空间中是一条直线,在三维空间中是一个平面,在高维空间中是超平面。是神经网络的第一个处理模块(每个神经元都会用到)。
- 对每个像素点有多少个权重,就表示有多少个不同的分类。
- 可以用交叉验证的方法对超参数进行评估。把训练集分成k折,分别把每一折单独作为验证集,其他折作为训练集,把在验证集上的准确率相加求平均,得到此超参数的准确率。遍历所有的K,找到准确率最高的点,便可找到最佳的模型超参数。如此可在较小的数据集上更准确地避免偶然误差,得到一个模型的评估性能。
- 线性分类器无法对非线性的数据分布进行拟合。如异或型,同心圆型,多峰型的分布。
2.铰链损失函数(hinge loss/svm loss)

合页损失函数(支持向量机的损失函数,没有正则化项)会惩罚与正确类别分数相近的错误类别,与正确类别分数较远的错误类别的分数对损失函数的结果没有影响。


3. softmax分类器
- 对铰链损失函数求指数,再归一化(各自分数/和,相当于概率)。

- 图形分类问题都是用softmax作为最终的分类结果。
4.交叉熵损失函数/对数似然函数
- 对分类正确的概率求对数。
- 凸函数只有一个全局最优解,无局部最优解
- 非凸函数,有许多局部最优解
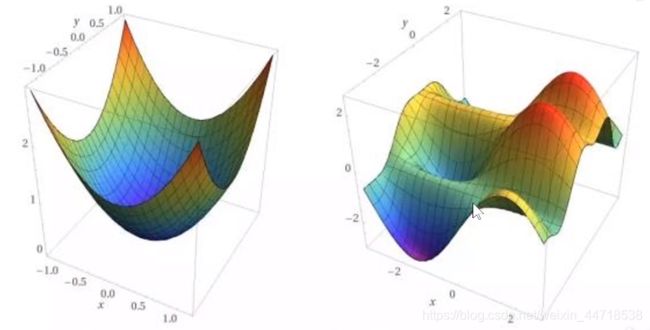
5. 反向传播
- 反向传播实际上就是用复合函数的链式求导法则,求出损失函数对各个权重的偏导。
- 然后权重根据梯度更新参数。
五、卷积神经网络
1. 卷积层
- 卷积的作用是把原图中符合卷积核定义的特征提取出来。如果符合,则chmap的值就大。
2. 池化层
- 从chmap里选出某些值出来。(最大值或者平均值)
- 池化的作用:减少参数量,防止过拟合,使神经网络具备平移不变性。
- 不需要权重。
3. 全连接层
- 简单神经网络
4. 其他
- 卷积神经网络训练的参数包括卷积核的权重和偏置项目和全连接层权重和偏置项。
- 使用数据驱动的方法,使用梯度下降和反向传播的方法求得损失函数对每一个权重的梯度,更新优化梯度,使得损失函数最小化。
- 底层的卷积核关注的是底层的信息,如边缘、转角、颜色、斑点块,越高级的卷积核就进行了特征的融合和汇总,获取的信息就变得越来越高级,比如说纹理、人脸、眼睛、轮胎、圆形,到了高层,提取到什么特征,人类也无法解释清楚了,所以深度学习的一个弊端,就是可解释性不强。到分类层就完全进行了特化,神经网络正是因为我们神经科学和生物认知科学上的启发,视觉是分层的,同时每一个神经元只看图像中的一小部分区域,进行了仿生,最后得出了这么一个模型。
5. 深度学习与传统神经网络的区别

- Adam

6. cnn网络进化

7. cnn结构的演化
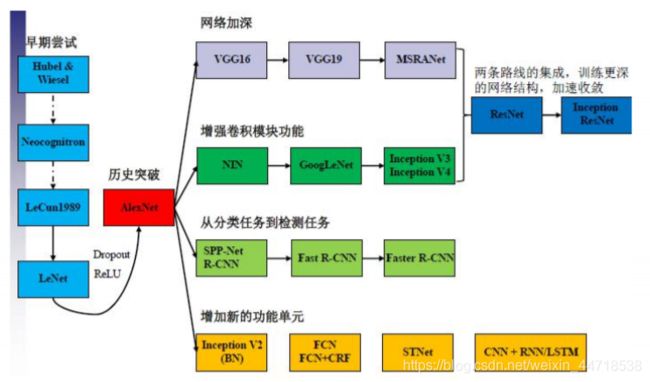
- 每个卷积核都负责提取不同尺度不同样子的特征,总有一款特征能匹配得到。
- 平移不变形来自于下采样和池化
- 深度学习三巨头
- ACM(国际计算机学会)宣布,有“深度学习三巨头”之称的Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖,这是图灵奖1966年建立以来少有的一年颁奖给三位获奖者。
- https://blog.csdn.net/zephyr_wang/article/details/105736103
- ImageNet Large Scale Visual Recognition Challenge(imagenet大规模视觉识别挑战赛)
- 是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。
- AI研究员李飞飞从2006年开始研究ImageNet的想法。在大多数AI研究专注于模型和算法的时候,李飞飞则希望扩展和改进可用于训练AI算法的数据。2007年,李飞飞与普林斯顿大学教授克里斯蒂安·费尔鲍姆(Christiane Fellbaum)会面讨论了该项目,他是WordNet的创建者之一。之后李继续从WordNet的单词数据库开始构建ImageNet,并使用了其许多功能。作为普林斯顿大学的助理教授,李飞飞组建了一个研究团队,致力于ImageNet项目。他们使用Amazon Mechanical Turk来帮助分类图像。他们在2009年美国佛罗里达州举行的计算机视觉与模式识别会议(CVPR)上首次以学术海报的形式展示了自己的数据库
- ILSVRC旨在延续2005年起举办的较小规模的PASCAL VOC挑战赛,后者仅包含约2万张图像和20个对象类别。为了使ImageNet“民主化”,李飞飞向PASCAL VOC团队提出了一项合作,从2010年开始,研究团队将在给定的数据集上评估他们的算法,并在几项视觉识别任务上争夺更高的准确率。由此产生的年度竞赛现在称为ImageNet大规模视觉识别挑战赛(ILSVRC)。ILSVRC使用仅1000个“整理后的”图像类别,其中包括完整的ImageNet类别的120个犬种中的90个。
- Alexnet
- 出现ReLuc和Dropout
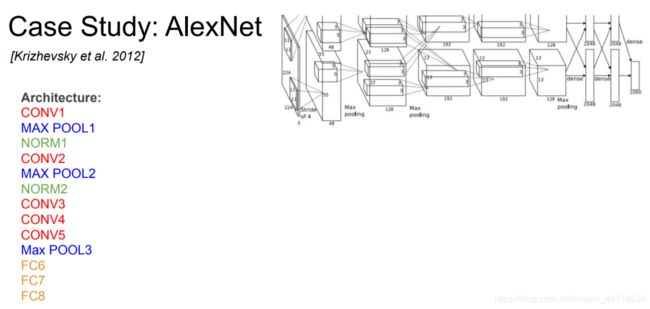
- 出现ReLuc和Dropout
- VGG
- 用3个3×3卷积代替一个7×7卷积,减少参数量,且卷积核都是3×3,步长为1。有16层和19层的VGG,一张224×224×3的图片前向传播参数四亿多个,占内存96M。反向再×2=138M
- 参数量大

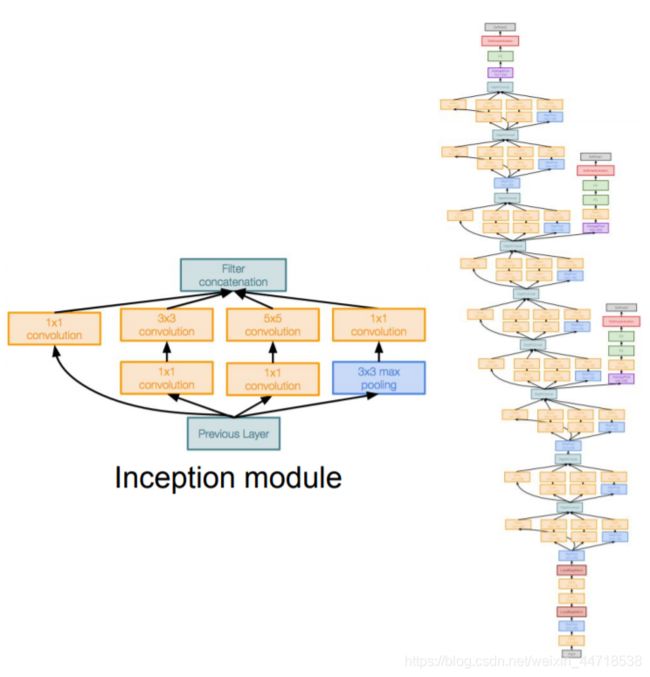
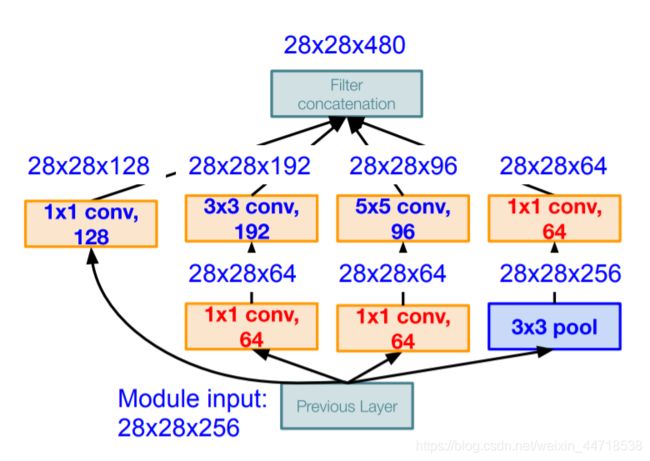
- GoogleNet
- inception模块:用不同大小的卷积核可以提取到图片中不同大小的物体。
- 1×1卷积作用:升维或降维、跨通道信息交融、减少参数量、增加模型深度,提高非线性表示能力
- 22层,500万个参数,参数减少,AlexNet的1/12,VGG的1/27
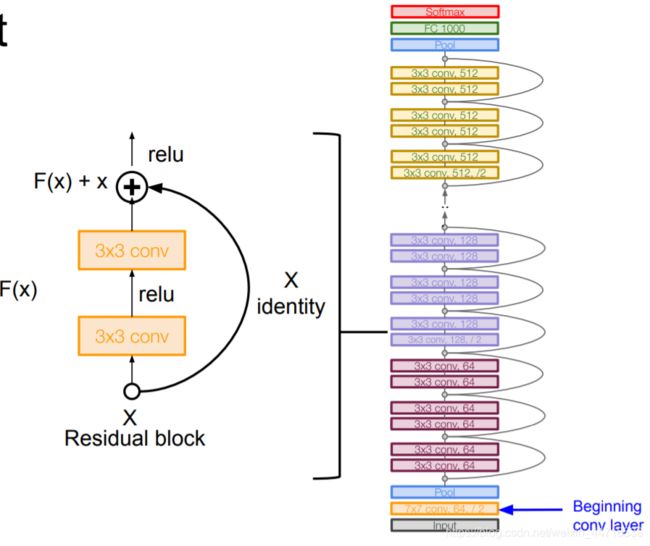
- ResNet
- 网络不是越深越好,越深会造成梯度小时,网络退化现象。
- 跨层传递。
- 首次超过人类水平。
8.反卷积
- 上采样
- 将缩小的图像像素进行线性组合。
六、pytorch框架
1. 什么是PyTorch?
- PyTorch是一个基于Python的科学计算库,它有以下特点:
- 类似于NumPy,但是它可以使用GPU
- 可以用它定义深度学习模型,可以灵活地进行深度学习模型的训练和使用
- Tensors
- Tensor类似与NumPy的ndarray,唯一的区别是Tensor可以在GPU上加速运算。
2. PyTorch常用函数
- torch.utils.data.DataLoader使用方法
数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。
在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。 - PyTorch提供了两个类来计算二分类交叉熵(Binary Cross Entropy),分别是BCELoss() 和BCEWithLogitsLoss()
- 在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
- optimizer.step()和scheduler.step()的区别
optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对,可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。通常我们有
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.9)
scheduler = lr_scheduler.StepLR(optimizer, step_size = 100, gamma = 0.1)
model = net.train(model, loss_function, optimizer, scheduler, num_epochs = 100)
- 在scheduler的step_size表示scheduler.step()每调用step_size次,对应的学习率就会按照策略调整一次。所以如果scheduler.step()是放在mini-batch里面,那么step_size指的是经过这么多次迭代,学习率改变一次。
七、计算机图像
- 数字华包括采样和量化两个过程:
- 采样是将模拟图像中连续分布的图像元素转换成空间离散分布的像素的过程。
- 像素:数字图像是由有限个图像元素构成,数字图像中的图像元素称为像素(离散)/模拟图像
- 灰度:量化是用离散的数值来近似表示原来连续可变的像素明亮程度的过程,这个近似表示明亮程度的离散数值称为像素的灰度值。
1. 图像预处理
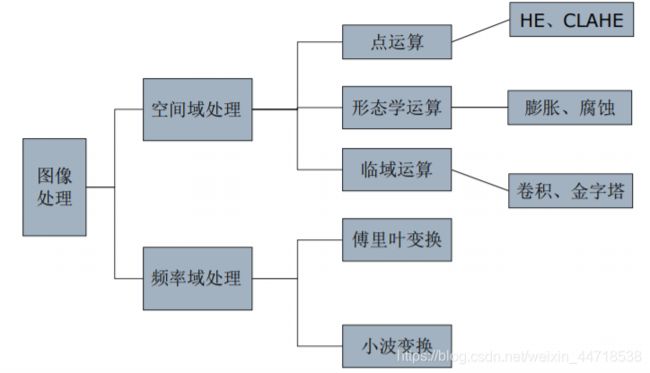
(1)图像的运算
- 图像的点运算
- 点运算是指,输出图像每个像素的灰度值仅仅取决于输入图像中相对应像素的灰度值。
- 图像的算术运算
- 图像的几何运算
- 图像的逻辑运算
(2)图像形态学处理
- 膨胀:膨胀是将图像中与目标物体接触的所有背景点合并到物体中的过程,结果是是目标增大、孔径缩小,可以增补目标中的空间,使其形成连通区域。(模板在边缘外侧滑动)
- 腐蚀:腐蚀具有使目标缩小、目标内孔径增大以及消除外部孤立噪声的效果。模板在边缘内侧滑动)
- 开运算:开运算操作通过去除边缘处细小的凹陷不平达到平滑边缘的目的。开运算具有消除图像中细小物体,并在物体影像纤细处分离物体和平滑较大物体边界的作用。
- 闭运算:闭运算通过去除边缘上细小的凸起达到平滑边缘的目的。闭运算具有填充物体影像内细小空间、连接邻近物体和平滑边界的作业。
(3)空间域处理
-
卷积/滤波
- 平滑高斯滤波,使图像变模糊,对缩放图像有用
- 均值滤波
- 中值滤波
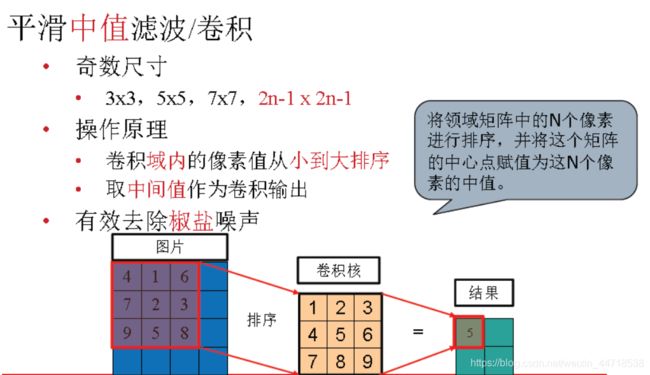
-
金字塔
(4)频率域处理
- 傅里叶变换
- 小波变换
(5)图像增强
- 平滑、去噪(卷积的应用)
- 边缘检测(卷积的应用)
- 边缘锐化(卷积的应用)
- 灰度调整(对比度增强)
- 直方图增强
- 直方图
- 直方图均衡化
- 图像均衡化是指利用图像直方图对对比度进行调整的方法
(6)图像分割
传统的图像分割方法
- 基于阈值
- 基于边缘
- 灰度
- 颜色
- 纹理
- 基于区域
- 区域生长法
- 区域分裂合并法
- 分水岭法
- 基于图论
- Graph Cuts分割
- GMM
- K-means
语义分割
- FCN
- DeepLab
2. 图像特征
(1)颜色特征
- 量化颜色正发图
- 聚类颜色直方图
(2)几何特征
- 边缘
- 边缘定义:像素值函数快速变化的区域-》一阶导数的极值区域
- 关键点
- Harris角点
Fast角点检测算法 - 斑点
(3)局部特征
- SIFT
- SURF
- ORB
(4)其他特征
- LBP
- Gabor
3. 图像分类
4. 目标检测
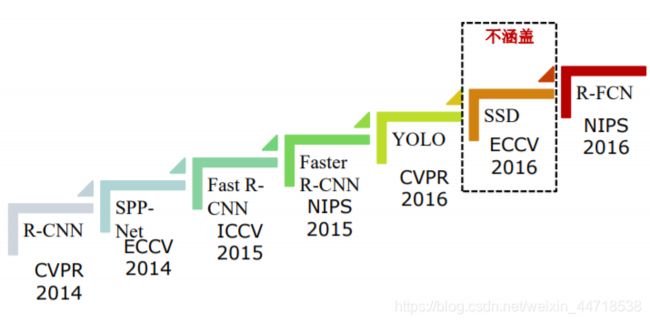
(1)区域卷积网络系列
- 模型进化
5. 医疗影像分割
- Unet(是全卷积神经网络)
- 3D-Unet
- Vnet
- DenseNet
八、视频质量检测&&分析
https://blog.csdn.net/zhulong1984/article/details/78304907
1. 亮度异常检测
https://www.cnblogs.com/wqvbjhc/p/3768984.html
- 一般包括偏暗检测和偏亮检测,也有称过暗过亮检测。只需要一帧图像的亮度值作为判断。
- 原理
- 把彩色图像转化为灰度图像
- 求图像的平均灰度值G(整幅或ROI区域),该值就是图像的亮度值
- 定义阈值A,B。当G∈[0,A]认为图像偏暗,当G∈[B,255]认为图像偏亮
2. 偏色检测/色度异常检测
https://www.cnblogs.com/wqvbjhc/p/3768985.html
- 一般称为偏色检测。 即图像为某一范围颜色值分布过多而导致图像整体偏色的情况。
- 原理
- 提取图像的色度分量H
- 计算色度分量H的直方图
- 求最方图(最优直方图)最大bin(组)占整个直方图的比例,该比例值就为偏色值
- 色三属性:色相、亮度和色度
- 色相(hue):或称色彩、色泽。物体的颜色。白、灰、黑色没有色彩,称无彩色;黄色、绿色、红色等有色彩,称为彩色。颜色差别称为色相。
- 亮度(value):颜色的明暗程度。由反射率100%的洁白色到完全没有反射的(反射率0%)的黑色之间分成亮度不同的等级。明亮的颜色亮度高,暗的颜色亮度低。白色与黑色中间的亮度称为中性灰,约18%的反射率,称为标准反射率。
- 色度(chroma):颜色的鲜艳程度,又称色品度,色饱和度。同一色相中鲜艳的色度高,不鲜艳的色度低。
- 在色的分辨中色相容易区别,但亮度和色度容易弄错。色度随色相和亮度而变化,一般色度高的多为中间亮度的色。当然根据色相不同也不完全一样。亮度过高或过低的色,色度都低。
- 色度学基础知识




3.图像噪声检测:雪花噪声检测
https://www.cnblogs.com/wqvbjhc/p/3768994.html
- 雪花噪声即椒盐噪声,以前黑白电视常见的噪声现象。
- 原理
- 准备0°,45°,90°,135°4个方向的卷积模板。
- 用图像先和四个模板做卷积,用四个卷积绝对值最小值Min来检测噪声点。
- 求灰度图gray与其中值滤波图(median)。
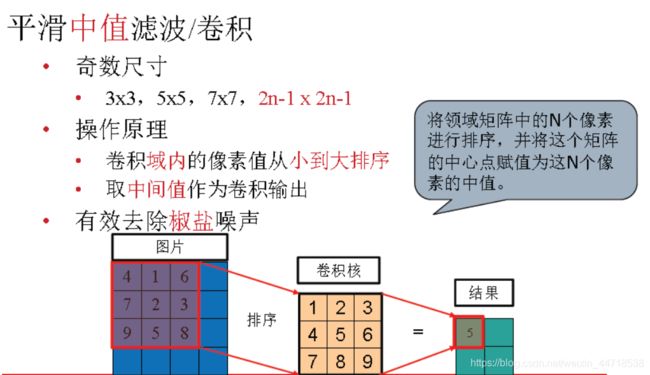
- 判断噪声点:fabs(median-gray)>10 && min>0.1。
- 噪声点占整幅图像的比较即为雪花噪声率。
4.条纹噪声检测是带条状的噪声。
https://www.cnblogs.com/wqvbjhc/p/3768995.html
- 条纹噪声是带条状的噪声。
- 原理
- 提取彩色图像的色度分量。
- 对色度分量求DFT(离散傅里叶变换)频谱图。
- 计算频谱图的异常亮点数,若大于A则认为发生条纹检测。
- https://blog.csdn.net/qq295456059/article/details/50354222
- CTFS、DTFS、CTFT、DTFT公式

5. 清晰度检测/模糊检测
https://www.cnblogs.com/wqvbjhc/p/3768995.html
- 模糊一般是摄像头焦距没调好造成的画面模糊。
- 原理
- 把图像分割成N*M的区域。
- 求每个区域的对比度:(max-min)/max.
- 求总的平均对比度即为模糊率。
6.信号丢失检测
https://www.cnblogs.com/wqvbjhc/p/3769008.html
- 也称无信号检测,一般当DVR/NVR某些通道没接上摄像头时,会显示黑屏无信号。而IPC无信号里无法返回任何图像信息,也就无法通过图像算法检测到。
- 原理
-
把彩色图像二值化,偏黑的部分为前景,其他部分为背景。
-
对前景进行连通区域检测,求得最大连通区域面积。

-
该面积整幅图像面积的比较即为信号丢失率。
-
7. 视频抖动检测/遮挡检测
https://www.cnblogs.com/wqvbjhc/p/3768996.html
- 遮挡检测一般是摄像头被异物遮挡,呈现出整个场景或某一部分场景看不到的情况。被遮挡住的部分一般都呈偏黑色。
- 原理
把彩色图像二值化,偏黑的部分为前景,其他部分为背景。
对前景进行连通区域检测,求得最大连通区域面积。
该面积整幅图像面积的比较即为遮挡率。
8. 画面冻结检测
https://www.cnblogs.com/wqvbjhc/p/3769017.html
- 画面冻结是由于画面场景没有变化,而仅仅是画面中的时间有变化的情况。此现象需要多帧图像才能检测出来。
- 原理
每隔T帧从视频中取一帧(防止相邻帧太相似引起误检)。
对所取的每帧求直方图。
求相邻2帧直方图的相似度。
当相似度大于A时认为二帧一致,当一致的帧达到B时认为画面发生冻结
9. 视频滚动检测/PTZ云台运动检测
https://www.cnblogs.com/wqvbjhc/p/3769016.html
- 是通过配合云台运动的功能检测云台运动是否正常。
- 原理
取云台运动前N帧图像,进行背景建模,得到运动前背景A。
设备发送云台运动指令,让云台进行运动,改变场景。
取云台运动后N帧图像,进行背景建模,得到运动后背景B。
对比A,B颜色直方图的相似度,大于K时认为PTZ云台运动有故障
10. 画面抖动检测
https://www.cnblogs.com/wqvbjhc/p/3769018.html
- 当摄像头立杆不稳或因车辆引起地面振动时,视频画面就会发生抖动。
- 原理
每隔N帧取一帧。
对取到的每帧进行特征点提取。
对检测的相邻2帧进行特征点匹配。
得到匹配矩阵,当匹配矩阵大于A时认为这2帧画面有抖动。
当抖动帧数大于B时认为画面发生抖动。