在ubuntu18.04上安装和使用k8s集群
在ubuntu18.04上安装和使用k8s集群
-
- 一、配置虚拟机
- 二、安装docker
- 三、安装k8s
-
- 1.关闭虚拟内存
- 2.安装kubernetes
- 3.设置开机启动
- 4.查看`kubectl`版本
- 四、配置k8s集群
-
- 1.克隆两台虚拟机
- 2.配置虚拟网络
-
- 1)配置主节点
- 2)配置每台机器的`/etc/netplan/50-cloud-init.yaml`
-
- 问题一
- 3)修改`/etc/hosts`
- 4)重启
- 3.配置Master节点
-
- 1)使用`kubeadm init`进行初始化操作
-
- 问题二
- 问题三
- 2)启动k8s
- 3)查看启动状态
-
- 问题四
- 4.配置内部通信 flannel 网络
-
- 1)下载kube-flannel.yml
- 2)加载配置文件
- 5.配置 node节点
-
- 1)启动kubelet
- 2)配置ssh
- 3)拷贝配置文件
- 4)加入节点
- 5)在master中查看
-
- 问题五
一、配置虚拟机
1.官网下载VMware16
2.下载Ubuntu18.04桌面版,配置虚拟机。2核 3G 20G
3.配置root登录
https://blog.csdn.net/m0_46128839/article/details/116133371
二、安装docker
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
apt update && apt install docker-ce
docker run hello-world
三、安装k8s
1.关闭虚拟内存
sudo swapoff -a #暂时关闭
nano /etc/fstab #永久关闭,注释掉swap那一行,推荐永久关闭
2.安装kubernetes
#使用root用户操作
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install kubelet kubeadm kubectl kubernetes-cni
其中kubeadm用于初始化环境,kubectl用于操作kubelet。
3.设置开机启动
sudo systemctl enable kubelet && systemctl start kubelet
4.查看kubectl版本
root@ubuntu:/home/fanb# kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.2", GitCommit:"092fbfbf53427de67cac1e9fa54aaa09a28371d7", GitTreeState:"clean", BuildDate:"2021-06-16T12:59:11Z", GoVersion:"go1.16.5", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
四、配置k8s集群
1.克隆两台虚拟机
刚刚已经装好一台虚拟机的k8s,现在要配置2台额外的虚拟机,总共3台,形成k8s集群。
推荐的做法是直接使用vmware自带的克隆功能,这样可以免去重装的烦恼。
共3台机器,分别为 master, node1, node2.
master 192.168.139.131
node1 192.168.139.132
node2 192.168.139.133
2.配置虚拟网络
1)配置主节点
在master的/etc/hostname中配置主节点为master
在node1的/etc/hostname中配置主节点为node1
在node2的/etc/hostname中配置主节点为node
2)配置每台机器的/etc/netplan/50-cloud-init.yaml
把DHCP的IP改为固定IP:
network:
ethernets:
ens33:
addresses: [192.168.139.131/24]
dhcp4: false
gateway4: 192.168.139.2
nameservers:
addresses: [192.168.139.2]
optional: true
version: 2
问题一
在这里发现虚拟机重启之后IP会变化,需要将其配置为静态。
解决方法:
-
点击“编辑” --> “虚拟网络编辑器” --> 选择 “vmnet8" --> 取消勾选 ”使用本地DHCP服务器将IP地址分配给虚拟机“
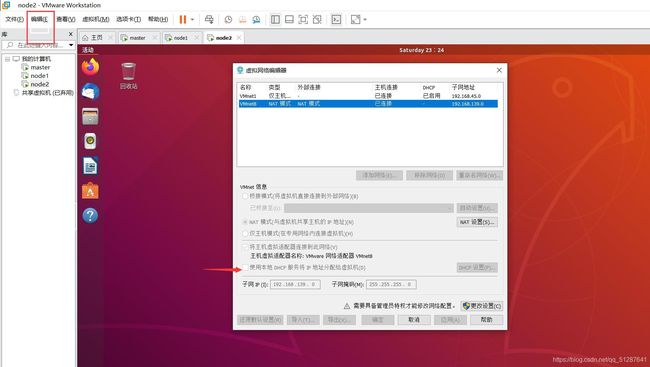
-
进入虚拟机 --> 右上角”有线连接“ --> ”有线设置“ -->设置图标
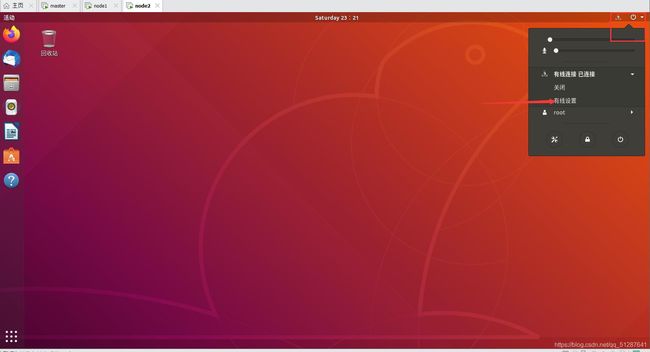

- 选择”IPV4“ --> 选择手动 --> 在地址栏,第一栏输入你想要的静态IP --> 第二栏是255.255.255.0, --> 第三栏是你的网关 --> dns也输入你的网关 --> 应用

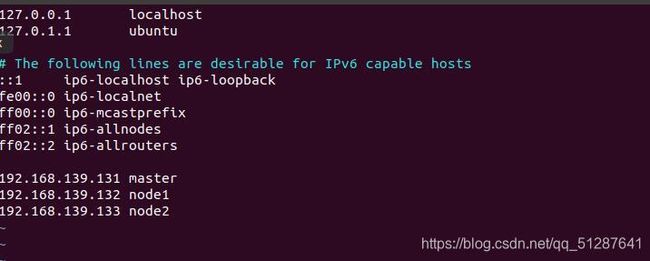
3)修改/etc/hosts
192.168.139.131 master
192.168.139.132 node1
192.168.139.133 node2
4)重启
重启机器后能互相ping表示配置成功:
root@node1:~# ping master
PING master (192.168.139.131) 56(84) bytes of data.
64 bytes from master (192.168.139.131): icmp_seq=1 ttl=64 time=0.434 ms
64 bytes from master (192.168.139.131): icmp_seq=2 ttl=64 time=0.587 ms
root@node1:~# ping node2
PING node2 (192.168.139.133) 56(84) bytes of data.
64 bytes from node2 (192.168.139.133): icmp_seq=1 ttl=64 time=0.917 ms
64 bytes from node2 (192.168.139.133): icmp_seq=2 ttl=64 time=0.551 ms
root@node2:~# ping master
PING master (192.168.139.131) 56(84) bytes of data.
64 bytes from master (192.168.139.131): icmp_seq=1 ttl=64 time=0.572 ms
64 bytes from master (192.168.139.131): icmp_seq=2 ttl=64 time=0.585 ms
root@master:~# ping node1
PING node1 (192.168.139.132) 56(84) bytes of data.
64 bytes from node1 (192.168.139.132): icmp_seq=1 ttl=64 time=0.259 ms
64 bytes from node1 (192.168.139.132): icmp_seq=2 ttl=64 time=0.636 ms
3.配置Master节点
1)使用kubeadm init进行初始化操作
#查看需要的镜像及其版本
root@master:/etc/docker# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.21.2
k8s.gcr.io/kube-controller-manager:v1.21.2
k8s.gcr.io/kube-scheduler:v1.21.2
k8s.gcr.io/kube-proxy:v1.21.2
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
root@master:/etc/docker# kubeadm init --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --kubernetes-version=v1.21.2
[init] Using Kubernetes version: v1.21.2
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image registry.aliyuncs.com/google_containers/coredns:v1.8.0: output: Error response from daemon: manifest for registry.aliyuncs.com/google_containers/coredns:v1.8.0 not found: manifest unknown: manifest unknown #ImagePull报错
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
问题二

解决方法:如果直接从k8s.gcr.io 拉取镜像的话,国内会被墙,所以可以从DockerHub的其它拥有所需版本的仓库拉取
编写脚本
root@master:/home# vim pull_k8s_images.sh
set -o errexit
set -o nounset
set -o pipefail
##这里定义版本,按照上面得到的列表自己改一下版本号
KUBE_VERSION=v1.21.2
KUBE_PAUSE_VERSION=3.4.1
ETCD_VERSION=3.4.13-0
DNS_VERSION=v1.8.0
##这是原始仓库名,最后需要改名成这个
GCR_URL=k8s.gcr.io
##这里就是写你要使用的仓库
DOCKERHUB_URL=gotok8s
##这里是镜像列表,新版本要把coredns改成coredns/coredns
images=(
kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns/coredns:${DNS_VERSION}
)
##这里是拉取和改名的循环语句
for imageName in ${images[@]} ; do
docker pull $DOCKERHUB_URL/$imageName
docker tag $DOCKERHUB_URL/$imageName $GCR_URL/$imageName
docker rmi $DOCKERHUB_URL/$imageName
done
授予执行权限
root@master:/home# chmod +x ./pull_k8s_images.sh
执行脚本
root@master:/home# ./pull_k8s_images.sh
查看镜像

发现没有k8s.gcr.io/coredns/coredns:v1.8.0
需要在dockerhub另外找一个有所需版本的仓库
https://hub.docker.com/r/coredns/coredns/tags?page=1&ordering=last_updated
这里只缺一个k8s.gcr.io/coredns/coredns:v1.8.0,所以就不写脚本,自己手动操作了
#拉取 coredns/coredns:1.8.0
root@master:/home# docker pull coredns/coredns:1.8.0
#重命名
root@master:/home# docker tag coredns/coredns:1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0
#删除原来拉取的镜像
root@master:/home# docker rmi coredns/coredns:1.8.0
现在再查看镜像

现在再kubeadm init
问题三
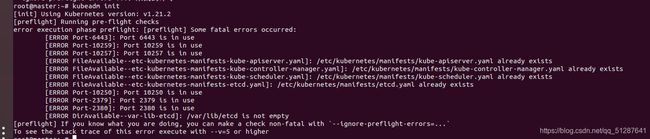
可以看到有三个类型的错误:[ERROR: Port XXX is in use] ,[ERROR: **.yaml already exists], [ERROR : /var/lib/etcd is not empty]
解决方法:
- 对于第一类和第二类问题,使用 kubeadm reset 命令,一路yes通过就行。
- 第三个问题,先进入 /var/lib/etcd目录,再使用 rm -rf 命令,清空etcd库的文件。
- ps:还有一个问题忘记记录了
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd".
解决方法:
vim /etc/docker/daemon.json
#加入以下内容
{
"exec-opts":["native.cgroupdriver=systemd"]
}
#重启docker
systemctl restart docker
systemctl status docker
现在再来使用 kubeadm init
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.139.131:6443 --token 4hani6.n42f6r1hima8id77 \
--discovery-token-ca-cert-hash sha256:59ddaf8680ca87c33a1745f22a6e459862087519999a7e201ffef81f6433f1b7
成功!
2)启动k8s
非root用户执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
root用户执行(仅本次有效),这个文件包含了登陆kubectl的验证信息:
export KUBECONFIG=/etc/kubernetes/admin.conf
可以设置永久的环境变量,这样下次登陆,kubectl就能直接连上本机的server,而不用再设置一次环境变量:
vim /etc/profile
#文件末尾添加
export KUBECONFIG=/etc/kubernetes/admin.conf
启动kubelet 设置为开机自启动
root@master:/var/lib/etcd# systemctl enable kubelet
启动k8s服务程序
root@master:/var/lib/etcd# systemctl start kubelet
3)查看启动状态
root@master:/var/lib/etcd# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane,master 36m v1.21.2
#现在只有一个master节点。
root@master:/var/lib/etcd# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}
问题四
可以发现上面 kubectl get cs 后有两个unhealthy
解决方法: 注释掉/etc/kubernetes/manifests下的kube-controller-manager.yaml和kube-scheduler.yaml的- --port=0。
root@master:/etc/kubernetes/manifests# vim kube-controller-manager.yaml
root@master:/etc/kubernetes/manifests# vim kube-scheduler.yaml
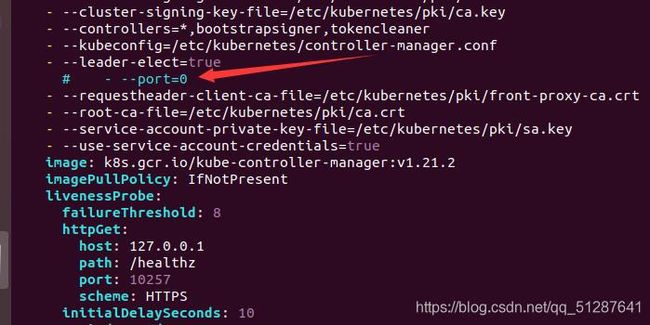
现在重新kubectl get cs,可以发现没有问题
root@master:/etc/kubernetes/manifests# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
4.配置内部通信 flannel 网络
master和node都要配
1)下载kube-flannel.yml
-
由于直接下载会被墙,所以先在/etc/hosts文件添加一条
199.232.68.133 raw.githubusercontent.com -
然后通过wget下载
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
2)加载配置文件
root@master:/etc# kubectl apply -f kube-flannel.yml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
此时状态变为ready
root@master:/etc# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 24h v1.21.2
5.配置 node节点
1)启动kubelet
root@node1:~# systemctl enable kubelet
root@node1:~# systemctl start kubelet
2)配置ssh
#三个虚拟机都安装ssh
apt-get install openssh-server
#配置密钥
##在master中执行 ssh-keygen -t rsa 一路回车
###将master中/root/.ssh/id_rsa.pub内容拷贝到node1和node2的/root/.ssh/authorized_keys中
root@master:~# cat /root/.ssh/id_rsa.pub
root@node2:~/.ssh# vim authorized_keys
3)拷贝配置文件
root@master:~# scp /etc/kubernetes/admin.conf root@node1:/home/fanb/
root@master:~# scp /etc/kubernetes/admin.conf root@node2:/home/fanb/
4)加入节点
root@node1:/home/fanb# kubeadm join 192.168.139.131:6443 --token 4hani6.n42f6r1hima8id77 --discovery-token-ca-cert-hash sha256:59ddaf8680ca87c33a1745f22a6e459862087519999a7e201ffef81f6433f1b7
root@node2:/home/fanb# kubeadm join 192.168.139.131:6443 --token 4hani6.n42f6r1hima8id77 --discovery-token-ca-cert-hash sha256:59ddaf8680ca87c33a1745f22a6e459862087519999a7e201ffef81f6433f1b7
5)在master中查看
root@master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 3h50m v1.21.2
node1 NotReady <none> 3h40m v1.21.2
node2 NotReady <none> 93s v1.21.2
问题五
发现为notready,通过 查看日志发现 node节点上可能缺少文件
root@node1:/home/fanb# journalctl -f -u kubelet
-- Logs begin at Fri 2021-07-09 23:05:52 PDT. --
Jul 14 03:28:27 node1 kubelet[15305]: I0714 03:28:27.380762 15305 cni.go:239] "Unable to update cni config" err="no networks found in /etc/cni/net.d"
需从master机器上拷贝文件过来
root@master:/etc/cni# scp -r /etc/cni root@node1:/etc
root@master:/etc/cni# scp -r /etc/cni root@node2:/etc
现在再查看,发现都为ready了
root@master:/etc/cni# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 5h16m v1.21.2
node1 Ready <none> 5h6m v1.21.2
node2 Ready <none> 87m v1.21.2
到这里,k8s集群搭建完毕。