java安全入门(一)
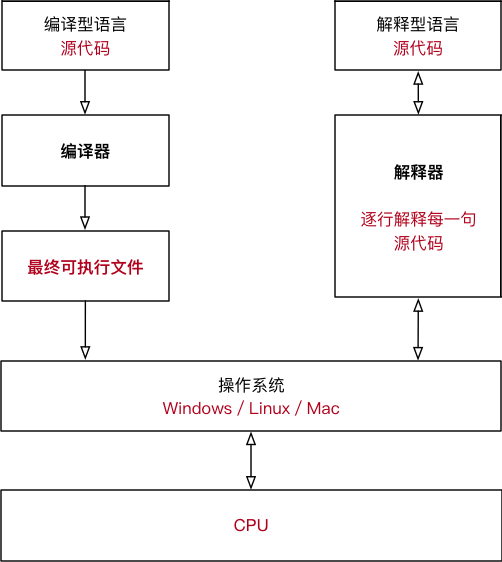
编译型语言和解释性语言
大家之前都或多或少接触过python与php,刚开始可能接触过一些C,但是其实这几种是不同的语言
- 有的编程语言要求必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序(Windows 下的 .exe),比如C语言、C++、Golang、Pascal(Delphi)、汇编等,这种编程语言称为编译型语言,使用的转换工具称为编译器
- 有的编程语言可以一边执行一边转换,需要哪些源代码就转换哪些源代码,不会生成可执行程序,比如 Python、JavaScript、PHP、Shell、MATLAB等,这种编程语言称为解释型语言,使用的转换工具称为解释器。
简单理解,编译器就是一个“翻译工具”,类似于将中文翻译成英文、将英文翻译成俄文。但是,翻译源代码是一个复杂的过程,大致包括词法分析、语法分析、语义分析、性能优化、生成可执行文件等五个步骤,期间涉及到复杂的算法和硬件架构。解释器也是一样,可以参考《编译原理》
但是,我们要学的java和c#属于半编译半解释型的语言,
根据这种特性,源代码需要先转换成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中执行。Java 引领了这种风潮,它的初衷是在跨平台的同时兼顾执行效率;C# 是后来的跟随者,但是 C# 一直止步于 Windows 平台。
下面用一张图来说明一下
我们学习php的时候,最核心的一步其实是命令执行,只有RCE成功,我们才算真正拿下了这台主机,所以,java这里,我们先学习一下命令执行。
命令执行
首先介绍最基本的 java中的命令执行
我们以后,最常用的poc,就是下面的这条
import java.io.IOException;
public class Calc {
//当前执行命令无回显
public static void main(String[] args) throws IOException {
Runtime.getRuntime().exec("calc.exe");
}
}
这里,在额外普及一下,如果需要回显怎么办的问题,主要是用IO流将命令执行后的字节加载出来,然后最基本的按行读取,就可以了。
在进行网站开发入JSP的时候,我们使用的JSP一句话木马也是根据这个原理进行编写的。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Ping {
//我们需要执行有回显得命令
public static void main(String[] args) throws IOException {
Process process = Runtime.getRuntime().exec("ping baidu.com");
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
StringBuilder stringBuilder=new StringBuilder();
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
stringBuilder.append(line);
System.out.println(line);
}
inputBufferedReader.close();
inputBufferedReader=null;
inputStreamReader.close();
inputStreamReader=null;
inputStream.close();
inputStream=null;
}
}
Runtime的其他用法
我们在进行命令执行的时候,是需要区分操作系统的,不同的操作系统所执行的命令方式绝对是不一样的,
Windows下
windows 我们可以调用 cmd或者powershell去执行命令,但是powershell一般会限制执行策略,所以使用cmd一般是比较保险的
https://docs.microsoft.com/zh-cn/powershell/module/microsoft.powershell.core/about/about_execution_policies?view=powershell-7.2
String [] cmd={"cmd","/C","calc.exe"};
Process proc =Runtime.getRuntime().exec(cmd);
linux下
对于linux的话,我们一般可以使用bash进行命令的执行,通常情况下是会有的,但是有的情况,可能没有bash,我们就可以使用sh来进行替代,
String [] cmd={"/bin/sh","-c","ls"};
Process proc =Runtime.getRuntime().exec(cmd);
于是乎,在后面我们写exp或者一些工具的时候,就需要根据主机的操作系统进行甄别
最简单的办法就是使用getProperty函数进行os的名称
System.getProperty("os.name");
初步demo
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) throws IOException {
String property = System.getProperty("os.name");
String [] cmd1={"cmd","/C","start calc.exe"};
String [] cmd2={"/bin/sh","-c","ls"};
String [] cmd = null;
System.out.println(property);
if (property.contains("Windows")){
cmd= cmd1;
}
else {
cmd= cmd1;
}
Process process =Runtime.getRuntime().exec(cmd);
//取得命令结果的输出流
InputStream inputStream = process.getInputStream();
//用输出读取去读
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
//创建缓冲器
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
StringBuilder stringBuilder=new StringBuilder();
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
stringBuilder.append(line);
System.out.println(line);
}
inputBufferedReader.close();
inputBufferedReader=null;
inputStreamReader.close();
inputStreamReader=null;
inputStream.close();
inputStream=null;
// return stringBuilder;
// 这里如果要返回的值的话,返回的应该是stringBuilder
}
}
反射
我们为什么必须使用反射
回想一下 java 中的基本操作,我们可以知道,类是对象的模板,对象是类的实例。一般我们都使用new的方式来创建一个对象,比如
Student stu1 = new Student();
//假设定义类之后,进行无参构造
那么,反射,为什么需要反射呢?
java有四个基本特征,封装,继承,多态,抽象
Java的反射(reflection)机制是指在程序的运行状态中,可以构造任意一个类的对象,可以了解任意一个对象所属的类,可以了解任意一个类的成员变量和方法,可以调用任意一个对象的属性和方法。本质上其实就是动态的生成类似于上述的字节码,加载到jvm中运行
关键点:动态获取
反射获取对象
正常的new对象的过程如下,我们可以看到,首先编译出了Student的类,而Student.class 经过JVM的内存中,就始终存在一个(一个类只会存在一个class对象),

补一张jvm的图

双亲委派机制
1->2->3->4
由于java语言动态的特性,在程序运行后,所运行的类,就已经在JVM的内存中,我们就可以直接调用已经加载好的类去实现我们的方法操作。
在很大一部分情况下,公司上线的产品都是以jar包或者war包部署到Tomcat下运行的,我们如果有源码,能审查链以后,就可以直接利用加载在JVM中的类进行操作。
- Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。
- Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。
- 反射调用方法时,会忽略权限检查,可以无视权限修改对应的值—>因此容易导致安全性问题,(对安全研究人员来说提供了不小的帮助,hhhh)
反射举例
我们最常见的反射举例,是加载数据库驱动时的
Class.forName("com.mysql.jdbc.Driver");//动态加载JDBC驱动
Connection conn = DriverManager.getConnection(url, user, password);
反射常用的方法有
Java.lang.Class;
Java.lang.reflect.Constructor;
Java.lang.reflect.Field;
Java.lang.reflect.Method;
Java.lang.reflect.Modifier;
基本使用
获得Class
- 类名.class,如:com.student.Student.class。
- ClassLoader.getSystemClassLoader().loadClass(“com.student.Student”)
- Class.forName(“com.student.Student”)
于是乎,我们通过反射可以这样获取Runtime类
String className = "java.lang.Runtime";
Class runtimeClass1 = Class.forName(className);
Class runtimeClass2 = java.lang.Runtime.class;
Class runtimeClass3 = ClassLoader.getSystemClassLoader().loadClass(className);
获取构造器
这里,有两个方法
- getDeclaredConstructor()
- getConstructor()
其中,getDeclaredConstructor()可以获得构造方法,也就是我们常用的private方法,其中Runtime的构造方法是private,我们无法直接调用,我们需要使用反射去修改方法的访问权限(使用setAccessible,修改为 true)
Constructor constructor = runtimeClass1.getDeclaredConstructor();
constructor.setAccessible(true);
通过获取的构造器进行实例化对象
// Object类是所有类的父类,有兴趣的同学可以在双亲委派机制中去搞明白
Object runtimeInstance = constructor.newInstance();
//这里的话就等价于
Runtime rt = new Runtime();
获取方法
Method runtimeMethod = runtimeClass1.getMethod("exec", String.class);
当我们想获取当前类的所有成员方法时们可以使用
Method[] methods = class.getDeclaredMethods()获取当前类指定的成员方法时,
Method method = class.getDeclaredMethod("方法名"); Method method = class.getDeclaredMethod("方法名", 参数类型如String.class,多个参数用","号隔开);
执行方法
Process process = (Process) runtimeMethod.invoke(runtimeInstance, "calc");
这里简单解释一下 invoke方法
method.invoke(方法实例对象, 方法参数值,多个参数值用","隔开);
- invoke就是调用类中的方法,最简单的用法是可以把方法参数化invoke(class, method)
这里则是使用了 class.invoke(method,“参数”)的一个方式
- 还可以把方法名存进数组v[],然后循环里invoke(test,v[i]),就顺序调用了全部方法
(之后会介绍)
回显结果,不需要回显的话就忽略
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
StringBuilder stringBuilder=new StringBuilder();
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
stringBuilder.append(line);
System.out.println(line);
}
inputBufferedReader.close();
inputStreamReader.close();
inputStream.close();
获取成员变量(Demo中没有用到)
反射还可以对成员变量进行操作
//获取类中的成员们变量
Field fields = class.getDeclaredFields();
//获取当前类指定的成员变量
Field field = class.getDeclaredField("变量名");
//获取成员变量的值
Object obj = field.get(类实例对象);
//修改成员变量的值
field.set(类实例对象, 修改后的值);
完整代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class RuntimeTest {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, IOException {
Class runtimeClass1 = Class.forName("java.lang.Runtime");//相当于 import
Constructor constructor = runtimeClass1.getDeclaredConstructor();//相当于编写无参构造类
constructor.setAccessible(true);//取消private的限制
Object runtimeInstance = constructor.newInstance();//有了无参构造类以后,我们new了一个对象
Method method = runtimeClass1.getMethod("exec",String.class);//编写类的方法
Process process = (Process) method.invoke(runtimeInstance,"calc");//调用了类的方法
//接下来就是回显的结果
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
StringBuilder stringBuilder=new StringBuilder();
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
stringBuilder.append(line);
System.out.println(line);
}
inputBufferedReader.close();
inputStreamReader.close();
inputStream.close();
}
}
深入理解反射


反射的作用和意义
我胡诌的:
对于安全人员来说,使用反射,可以更加高效的利用项目本身的属性类,而不借助其他外部类去实现一些漏洞的挖掘,这也是我们挖掘gadget的基本思路
序列化和反序列化
为什么需要使用序列化
和php使用序列化的情况一样,
但很多情况下,我们需要保存某⼀刻某个对象的信息,来进⾏⼀些操作。⽐如利⽤反序列化将程序运 ⾏的对象状态以⼆进制形式储存与⽂件系统中,然后可以在另⼀个程序中对序列化后的对象状态数据 进⾏反序列化恢复对象。可以有效地实现多平台之间的通信、对象持久化存储。
应用需求
想要实现序列化需要满足几个条件
-
该类必须实现
java.io.Serlalizable接口 -
该类的所有属性必须是可序列化的,如果⼀个属性是不可序列化的,则属性必须标明是短暂的。
比如:static,transient 修饰的变量不可被序列化
用于的场景业务
- 把对象的字节序列永久地保存到硬盘上,通常存放在⼀个⽂件中;
- 在⽹络上传送对象的字节序列
服务器启动后,就不会再关闭了,但是如果逼不得已需要重启,⽽⽤⼾会话还在进⾏相 应的操作,这时就需要使⽤序列化将session信息保存起来放在硬盘,服务器重启后,⼜重新加载。 这样就保证了⽤⼾信息不会丢失,实现永久化保存。
最常⻅的是Web服务器中的Session对象,当有 10万⽤⼾并发访问,就有可能出现10万个Session 对象,内存可能吃不消,于是Web容器就会把⼀些seesion先序列化到硬盘中,等要⽤了,再把保 存在硬盘中的对象还原到内存中。
举例
序列化:
-
ObjectOutputStream类 -> writeObject()
该⽅法对参数指定的obj⽂件进⾏序列化把字节序列写到⼀个⽬标输出流中,按照java标准是 给⽂件⼀个 ser 的扩展名
反序列化
-
ObjectInputStream类-> readObject()
该⽅法是从⼀个输⼊流中读取字节序列,再把他们反序列化成对象,将其返回
Java反序列化时会执⾏readObject()⽅法,所以如果readObject()⽅法被恶意构造 的话,就有可能导致命令执⾏。
package com.Serializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class User implements Serializable {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
private void readObject(ObjectInputStream in ) throws IOException, ClassNotFoundException {
in.defaultReadObject();
Runtime.getRuntime().exec("calc.exe");
}
}
package com.Serializable;
import java.io.*;
public class Test {
public static void main(String args[]) throws Exception{
User user = new User();
//这里设不设置属性无所谓,主要看当时的情况
user.setName("Wuming");
//序列化
OutputStream outputStream = new FileOutputStream(new File("C:\\Users\\12451\\Desktop\\Java-Learn\\src\\main\\java\\com\\Serializable\\test.ser"));
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(user);
//反序列化
InputStream inputStream = new FileInputStream(new File("C:\\Users\\12451\\Desktop\\Java-Learn\\src\\main\\java\\com\\Serializable\\test.ser"));
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
User test = (User) objectInputStream.readObject();
// //把object对象储存为字节流的形式
// FileOutputStream fos = new FileOutputStream("object");
// ObjectOutputStream os = new ObjectOutputStream(fos);
// //将对象写⼊object⽂件
// os.writeObject(user);
// os.close();
// //从⽂件中反序列化obj对象
// FileInputStream fis = new FileInputStream("object");
// ObjectInputStream ois = new ObjectInputStream(fis);
// //恢复对象
// User user1 = (User) ois.readObject();
// System.out.println(user1.getName());
// ois.close();
}
}
关于serialVersionUID(序列号)
当我们没有自定义序列化ID
如果我们没有自定义序列化id,当我们修改User 类的时候,编译器又为我们User 类生成了一个UID,而序列化和反序列化就是通过对比其SerialversionUID来进行的,一旦SerialversionUID不匹配,反序列化就无法成功。在实际的生产环境中,如果我们有需求要在序列化后添加一个字段或者方法,应该怎么办?那就是自己去指定serialVersionUID。
设置序列化ID
序列化运行时将一个版本号与每个称为SerialVersionUID的可序列化类相关联,在反序列化过程中使用该序列号验证序列化对象的发送方和接收方是否为该对象加载了与序列化兼容的类。如果接收方为对象加载的类的UID与相应发送方类的UID不同,则反序列化将导致InvalidClassException. 可序列化类可以通过声明字段名来显式声明自己的UID。
它必须是static、final和long类型。例如
(public/private/protected/default) static final long serialVersionUID=42L;
如果可序列化类没有显式声明serialVersionUID,则序列化运行时将根据类的各个方面为该类计算默认值,如Java对象序列化规范中所述。但是,强烈建议所有可序列化类显式声明serialVersionUID值,因为它的计算对类细节高度敏感,这些细节可能因编译器实现而异,因此类中的任何更改或使用不同的id都可能影响序列化的数据。
还建议对UID使用private修饰符,因为它作为继承成员没有用处。
IDEA设置自动生成UID的方式请参考https://blog.csdn.net/gnail_oug/article/details/80263383