Java修仙传之Kafka篇
大道三千,最近修Kafka
架构图及基本概念
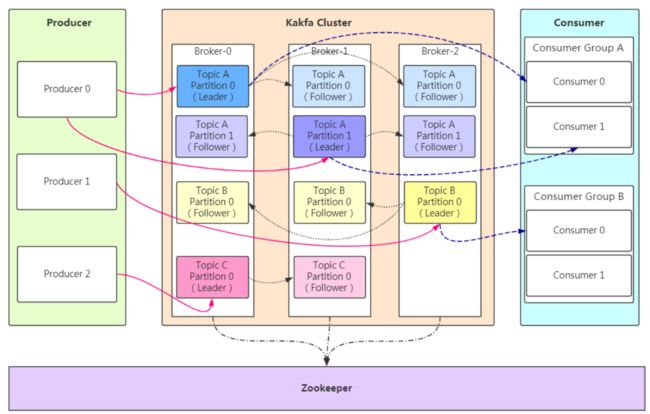

每台服务器,可以拥有一个或多个broker
每个broker可以拥有一个或多个主题
每个主题可以拥有多个分区(每个分区有序存储一部分数据,即:每个分区数据不同)
每个分区拥有一个或多个副本
一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
早期:broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
现在:kafka不需要ZooKeeper来维护集群状态
一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错生产者
org.apache.kafka
kafka-clients
2.4.1
public class MyProduce {
public static void main(String[] args) {
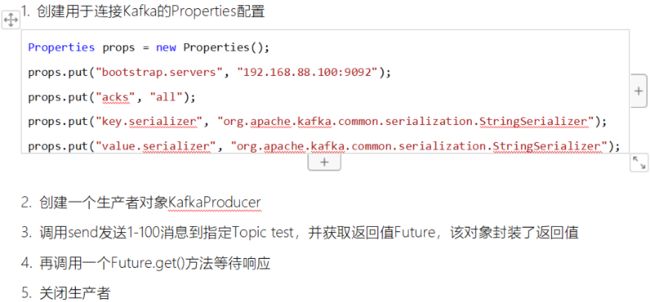
//1:添加配置
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.88.100:9092");
//指定Broker地址。如有多个Broker,逗号间隔"192.168.88.100:9092,192.168.88.101:9092,192.168.88.102:9092...
props.put("acks", "all");
// 消息应答机制.
// 0:管发不管收,存在消息丢失风险。
// 1:主节点保存后,返回成功消息,存在消息丢失风险。因为子节点可能还没保存,主节点就宕机了
// all(-1):主节点及所有子节点都保存成功后,返回成功消息,理论上不丢消息(但性能拉跨)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定了消息Key和Value的序列化器,: 这里用的String类型序列化器.消息发送接收时均为String类型. String消息->字节数组->String消息
//2:创建生产者,并植入配置
KafkaProducer producer = new KafkaProducer<>(props);
//3:封装消息,并指定topic,key,value(消息本体),patation分区. key和Partition 都是为了分区,只要有一个即可
ProducerRecord msg = new ProducerRecord<>("myTopic", "myKey", "msg");
// new ProducerRecord("myTopic", 1, "mykey", "myMsg"); 1=Partition
try {
//4:生产者对象调用send方法,并发送消息.返回一个Future对象(可基于Future对象获取消息结果). 这里抛异常代表消息发送失败
Future future = producer.send(msg);
//future.isDone();
//isDone():判断消息是否已经发送完成,即是否已经收到了发送结果。返回 true 表示发送完成,返回 false 表示还未完成。
//get():阻塞当前线程,直到接收到发送结果,然后返回结果。如果发送成功,它会返回 RecordMetadata 对象;如果发送过程中发生异常,它会抛出异常。
//get(long timeout, TimeUnit unit):阻塞当前线程,最多等待指定的时间,直到 [Something went wrong, please try again later.]
//5:调用一个Future.get()方法等待响应. 是否获取对象都可以,对象为元数据信息,包含主题,偏移量等
RecordMetadata recordMetadata = future.get(); //这里抛异常说明发送失败
//RecordMetadata是Kafka提供的一个类,表示消息的元数据信息,包括消息所属的Topic、Partition、Offset等
// recordMetadata.offset();
// recordMetadata.partition();
// recordMetadata.topic();
}catch (Exception e){
e.printStackTrace();
}
//6:关闭生产者
producer.close();
}
}
异步使用带有回调函数方法生产消息
简述:producer.send(msg, new Callback() {
...
}
即:在普通发送消息时,send里new出Callback匿名函数。
通过Exception:获取异常
通过RecordMetadata:获取出现问题的主题分区等.
发送失败:RecordMetadata返回失败的主题分区等
发送成功:RecordMetadata返回成功的主题分区等
package cn.itcast.kafka;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
public class MyProduce {
public static void main(String[] args) {
//1:添加配置
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.88.100:9092");
//指定Broker地址。如有多个Broker,逗号间隔"192.168.88.100:9092,192.168.88.101:9092,192.168.88.102:9092...
props.put("acks", "all");
// 消息应答机制.
// 0:管发不管收,存在消息丢失风险。
// 1:主节点保存后,返回成功消息,存在消息丢失风险。因为子节点可能还没保存,主节点就宕机了
// all(-1):主节点及所有子节点都保存成功后,返回成功消息,理论上不丢消息(但性能拉跨)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定了消息Key和Value的序列化器,: 这里用的String类型序列化器.消息发送接收时均为String类型. String消息->字节数组->String消息
//2:创建生产者,并植入配置
KafkaProducer producer = new KafkaProducer<>(props);
//3:封装消息,并指定topic,key,value(消息本体),patation分区. key和Partition 都是为了分区,只要有一个即可
ProducerRecord msg = new ProducerRecord<>("myTopic", "myKey", "msg");
// new ProducerRecord("myTopic", 1, "mykey", "myMsg"); 1=Partition
try {
//4:生产者对象调用send方法,并发送消息.返回一个Future对象(可基于Future对象获取消息结果). 这里抛异常代表消息发送失败
Future future = producer.send(msg, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null) {
System.out.println("发送消息出现异常");
}
else {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
System.out.println("发送消息到Kafka中的名字为" + topic + "的主题,第" + partition + "分区,第" + offset + "条数据成功!");
}
}
});
//future.isDone();
//isDone():判断消息是否已经发送完成,即是否已经收到了发送结果。返回 true 表示发送完成,返回 false 表示还未完成。
//get():阻塞当前线程,直到接收到发送结果,然后返回结果。如果发送成功,它会返回 RecordMetadata 对象;如果发送过程中发生异常,它会抛出异常。
//get(long timeout, TimeUnit unit):阻塞当前线程,最多等待指定的时间,直到 [Something went wrong, please try again later.]
//5:调用一个Future.get()方法等待响应. 是否获取对象都可以,对象为元数据信息,包含主题,偏移量等
RecordMetadata recordMetadata = future.get(); //这里抛异常说明发送失败
//RecordMetadata是Kafka提供的一个类,表示消息的元数据信息,包括消息所属的Topic、Partition、Offset等
// recordMetadata.offset();
// recordMetadata.partition();
// recordMetadata.topic();
}catch (Exception e){
e.printStackTrace();
}
//6:关闭生产者
producer.close();
}
}
消费者
备注:不使用死循环接收消息,则需关闭消费者kafkaConsumer.close();
public class MyConsumer {
public static void main(String[] args) {
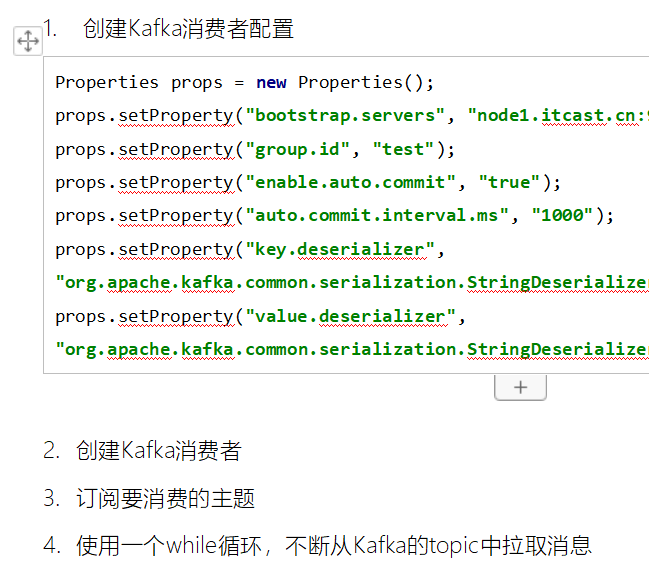
//1 创建消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1.itcast.cn:9092");
//消费者要连接到的kafka地址(必填)
props.setProperty("group.id", "test");
//消费者所属的消费者组的唯一标识符。相同 group.id 的多个消费者将协同处理消息。(必填)
props.setProperty("enable.auto.commit", "true");
//开启自动化提交消费位移(offset),根据下面一条定时提交. 如果设置为flase,则需要手动提交,手动提交存在重复消费问题(手动编写代码提交逻辑)
props.setProperty("auto.commit.interval.ms", "1000");
//自动提交消费位移间隔.单位是毫秒 offset:消费位移,偏移量。记录消费者,消费到的条数位置(当前条数,下一条).方便后续消费
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//消息的key跟Value的反序列化.字节数组转化后为字符串
//2 创建kafka消费者并植入配置 KafkaConsumer = KafkaConsumer需要与上文的反序列化其匹配
KafkaConsumer kafkaConsumer = new KafkaConsumer<>(props);
//3 消费者订阅主题(从哪个主题拉数据) 生产者发到一个主题,消费者自然要从对应的主题拉取
kafkaConsumer.subscribe(Arrays.asList("MyTopic")); //这里需要填写一个主题集合,即可以选订阅一个主题,也可以选择订阅多个主题
// kafkaConsumer.poll(Duration.ofSeconds(10)); 每个10秒从鼓起拉取一次消息。 如果10S内没有消息,则拉取到一个空对象
// kafkaConsumer.commitSync(); 同步提交当前偏移量。这个方法将等待服务器确认提交成功。 一般手动提交用此(或者下面一条)
// commitAsync(OffsetCommitCallback callback):异步提交当前偏移量,并在提交完成时调用回调函数。该方法立即返回,不必等待服务器响应。
// kafkaConsumer.commitAsync(new OffsetCommitCallback() {
// @Override
// public void onComplete(Map offsets, Exception exception) {
// if (exception != null) {
// // 处理提交偏移量时出现的异常
// } else {
// // 处理提交成功的情况
// }
// }
// });
// kafkaConsumer.seek(new TopicPartition("my-topic", 0), 100); 将消费者的读取位置设置为一个特定的偏移量(从哪个主题,哪个分区,的哪个偏移量开始读取)
// 我们将消费者的读取位置设置为名为 "my-topic" 的主题的第 0 分区(TopicPartition)的偏移量为 100 的位置。这意味着消费者将从该偏移量处开始读取消息。
// kafkaConsumer.assignment():获取当前消费者负责的所有主题分区。
// kafkaConsumer.unsubscribe():取消订阅消费者订阅的所有主题,停止消费消息
// 4.使用一个while循环,不断从Kafka的topic中拉取消息
while (true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来 consumerRecord:相当于分页查询的Record,很多信息都封装在这
for (ConsumerRecord consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// key\value
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();//线程休眠异常。 InterruptedException:线程休眠时,被外部程序打断,抛此异常
}
}
}
} 卡夫卡工具Kafka Tools
连接kafka
创建topic
kafka概念详解
producer(生产者)
l 生产者负责将数据推送给broker的topic
consumer(消费者)
l 消费者负责从broker的topic中拉取数据,并自己进行处理
consumer group(消费者组)
l consumer group是kafka提供的可扩展且具有容错性的消费者机制
l 一个消费者组可以包含多个消费者
l 一个消费者组有一个唯一的ID(group Id)
l 组内的消费者一起消费主题的所有分区数据
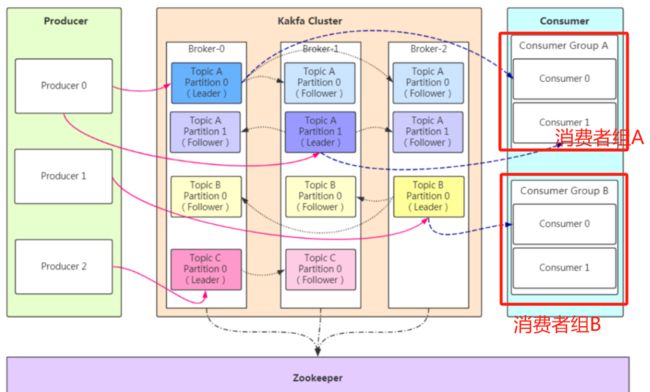
分区(Partitions)
在Kafka集群中,主题被分为多个分区
一个主题下,有多个分区,每个分区都存储着这个主题的一部分数据
图上:broker0,分为1,2分区,每个分区存储一部分数据
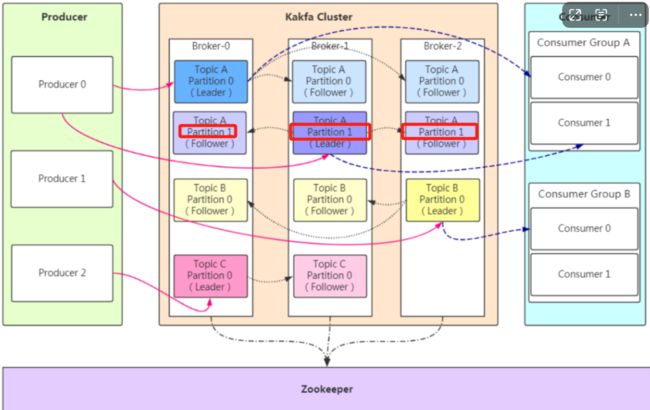
副本(Replicas):就是一主两从的从
l 副本可以确保某个服务器出现故障时,确保数据依然可用
就是子节点,主写从读,主挂了从选举新主
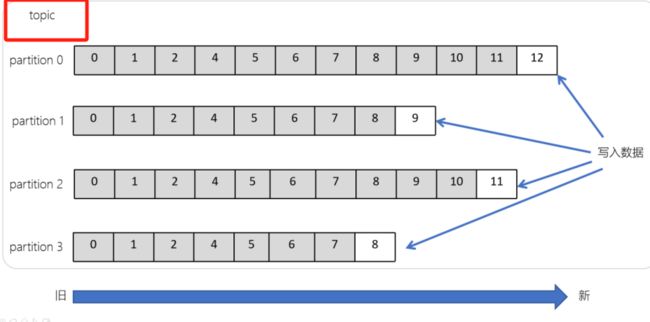
主题(Topic)
大白话:一类消息的一个题目.A类消息往A主题发,B类往....
l 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
l Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
l 在主题中的消息是有结构的,一般一个主题包含某一类消息
l 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
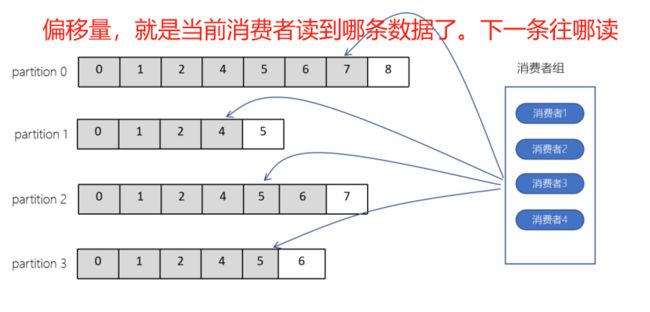
偏移量(offset)
l offset记录着下一条将要发送给Consumer的消息的序号
l 默认Kafka将offset存储在ZooKeeper中
l 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
l 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
A消费者读到第10条断了,下次再从这第10条开始读,读取11条。这个10就是偏移量
Kafka生产者幂等性与事务
幂等性:多次操作结果一致。
增:多次操作,出现相同数据,则可能出现问题(如重复名称) 这种就不具备幂等性
删:删一次库里没了,再删仍然没了,再删也一样,幂等性
改:可能会出现重复名称等信息
不具备幂等性的卡夫卡现象:一条消息如果未及时回复ACK,则会被再次发送,重复保存
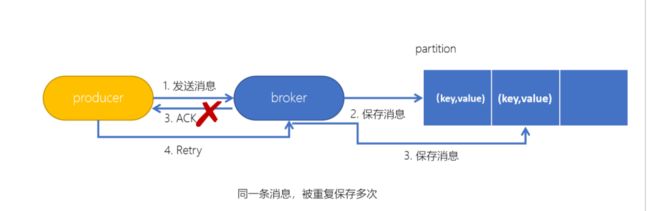
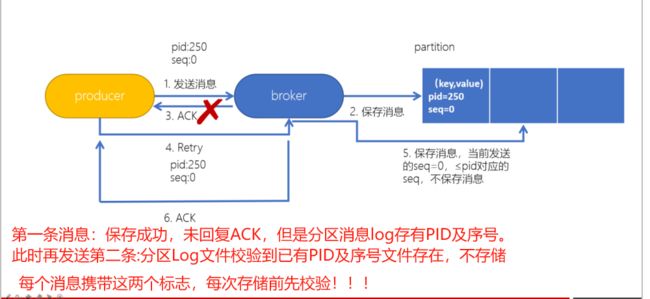
kafka解决幂等性的方式:基于PID(生产者唯一ID),Sequence Number(特定生产者发送到指定分区的递增消息序号)
大白话:存储前校验消息的PID及序列号。如果库里有就不存了,直接让broker返回ACK
Kafka事务(手动编写提交,且发生问题回滚)
Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。
这五个方法全部由生产者对象调用

生产者配置
生产者负责开启事务,配置事务id
// 配置事务的id,开启了事务会默认开启幂等性
props.put("transactional.id", "first-transactional");
// 1. 配置生产者带有事务配置的属性
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.200.130:9092");
props.put("acks", "all");
// 开启事务必须要配置事务的ID
props.put("transactional.id", "dwd_user");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 构建生产者
KafkaProducer kafkaProducer = new KafkaProducer<>(props); 消费者配置
消费者需要设置隔离级别及关闭自动提交(因为事务都是手动提交的)
// 1. 消费者需要设置隔离级别
props.put("isolation.level","read_committed");
// 2. 关闭自动提交
props.put("enable.auto.commit", "false");
// 1. 配置消费者的属性(添加对事务的支持)
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.200.130:9092");
props.setProperty("group.id", "ods_user");
// 配置事务的隔离级别
props.put("isolation.level","read_committed");
// 关闭自动提交,一会我们需要手动来提交offset,通过事务来维护offset
props.setProperty("enable.auto.commit", "false");
// 反序列化器
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2. 构建消费者对象
KafkaConsumer kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅一个topic
kafkaConsumer.subscribe(Arrays.asList("ods_user")); 使用案例
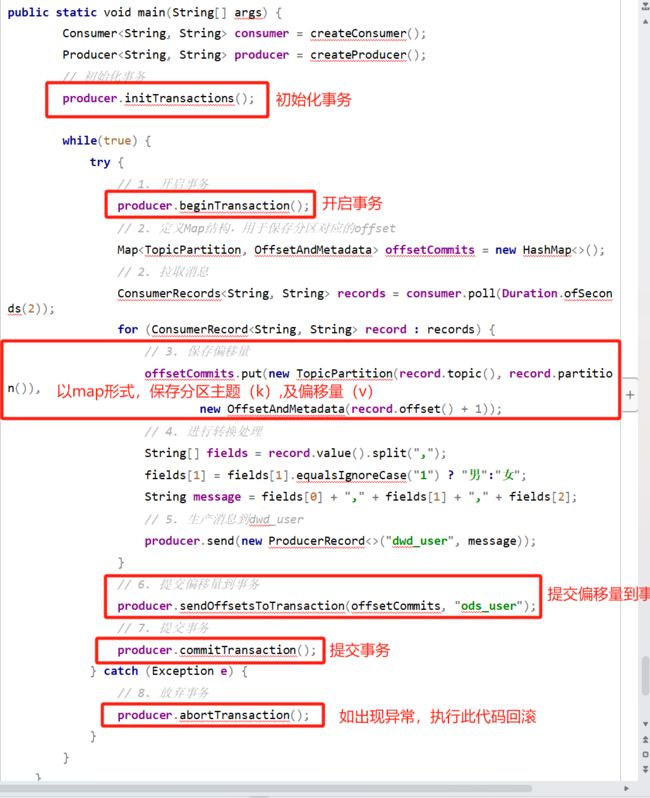
public static void main(String[] args) {
Consumer consumer = createConsumer();
Producer producer = createProducer();
// 初始化事务
producer.initTransactions();
while(true) {
try {
// 1. 开启事务
producer.beginTransaction();
// 2. 定义Map结构,用于保存分区对应的offset
Map offsetCommits = new HashMap<>();
// 2. 拉取消息
ConsumerRecords records = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord record : records) {
// 3. 保存偏移量
offsetCommits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
// 4. 进行转换处理
String[] fields = record.value().split(",");
fields[1] = fields[1].equalsIgnoreCase("1") ? "男":"女";
String message = fields[0] + "," + fields[1] + "," + fields[2];
// 5. 生产消息到dwd_user
producer.send(new ProducerRecord<>("dwd_user", message));
}
// 6. 提交偏移量到事务
producer.sendOffsetsToTransaction(offsetCommits, "ods_user");
// 7. 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 8. 放弃事务
producer.abortTransaction();
}
}
} 生产者分区写入策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中
1. 轮询分区策略 (存在乱序问题)
2. 随机分区策略 (存在乱序问题)
3. 按key分区分配策略 (有序,但存在分配不均问题)
4. 自定义分区策略
乱序问题:
随机:因为随机所以乱序
轮询:本来是在一个分区1,2,3,4,5的数据,被分配到三个分区,A1 B2 C3,下一轮A14 C25,可不就乱序了吗
分配不均问题:
有的key消息多,有的key消息少,
都发一个key去了,这个分区消息爆了
其他分区一条没有,闲得慌,可不是分配不均吗
自定义分区策略实现:
步骤:
1:新建类,并实现Partitioner 接口
2:重写configure,partition,close三个方法
3:partition,接收配置。 partition:分区逻辑。 close:分区关闭清理数据
// 备注:此处为自定义分区类.如某个生产者希望使用这个方式进行分区存储。
// 请加入配置:props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyRandomPartitionerPattern.class.getName());
public class MyRandomPartitionerPattern implements Partitioner {
private Random random;
@Override
public void configure(Map map) {
random = new Random();
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//luster.partitionCountForTopic表示获取指定topic的分区数量
//random.nextInt(1000):随机返回一个0-1000之间的整数
//合起来:随机整数对分区数量取余(求得索要存储的分区)
return random.nextInt(1000) % cluster.partitionCountForTopic(topic);
}
@Override
public void close() {
}
//configure(Map map) 方法:
//
//该方法在分区器初始化时被调用,用于进行一些配置和初始化操作。
//在这个例子中,configure 方法接收一个 Map 对象作为参数,用于传递配置信息。但是在代码中,并没有使用这个参数。
//在 configure 方法中,通过实例化 Random 对象来初始化 random 成员变量,以便后续的分区计算中使用。
//partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) 方法:
//
//这是分区器的核心方法,用于根据指定的主题、键和值等信息计算消息应该发送到哪个分区。
//topic 是消息所属的主题名称。
//key 和 keyBytes 是消息的键,可以为空。
//value 和 valueBytes 是消息的值,以字节数组形式提供。
//cluster 是一个 Kafka 集群对象,用于获取有关集群的元数据信息,例如分区数量等。
//在这个例子中,通过调用 random.nextInt(1000) % cluster.partitionCountForTopic(topic) 的方式,根据随机数和主题的分区数量来计算将消息发送到哪个分区。
//返回的结果是一个整数,代表分区的编号。
//close() 方法:
//
//这个方法在分区器关闭时被调用,用于进行一些清理操作。
//在这个例子中,close 方法为空,即没有实际的清理操作。
//通过实现 Partitioner 接口,并定义这三个方法,可以自定义 Kafka 分区器的行为。根据实际需求,可以编写适合特定场景的分区逻辑,以满足消息的分发需求。
}
消费组Consumer Group Rebalance机制(再分配)
- 再均衡:在某些情况下,消费者组中的消费者消费的分区会产生变化,会导致消费者分配不均匀(例如:有两个消费者消费3个,因为某个partition崩溃了,还有一个消费者当前没有分区要削峰),Kafka Consumer Group就会启用rebalance机制,重新平衡这个Consumer Group内的消费者消费的分区分配。
- 触发时机
-
- 消费者数量发生变化
-
-
- 某个消费者crash
- 新增消费者
-
-
- topic的数量发生变化
-
-
- 某个topic被删除
-
-
- partition的数量发生变化
-
-
- 删除partition
- 新增partition
-
- 不良影响
-
- 发生rebalance,所有的consumer将不再工作,共同来参与再均衡,直到每个消费者都已经被成功分配所需要消费的分区为止(rebalance结束)
消费者的分区分配策略
分区分配策略:保障每个消费者尽量能够均衡地消费分区的数据,不能出现某个消费者消费分区的数量特别多,某个消费者消费的分区特别少
range分配策略:
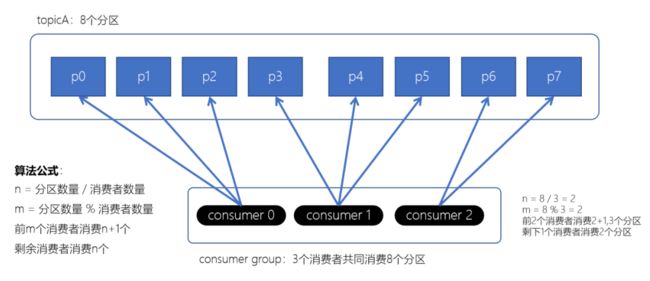
1. Range分配策略(范围分配策略):Kafka默认的分配策略
-
- n:分区的数量 / 消费者数量
- m:分区的数量 % 消费者数量
- 前m个消费者消费n+1个分区
- 剩余的消费者消费n个分区
-
2. RoundRobin分配策略(轮询分配策略)
-
- 消费者挨个分配消费的分区
-
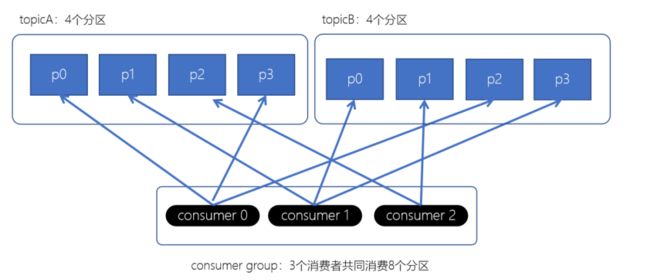
3. Striky粘性分配策略
-
- 在没有发生rebalance跟轮询分配策略是一致的
- 发生了rebalance,轮询分配策略,重新走一遍轮询分配的过程。而粘性会保证跟上一次的尽量一致,只是将新的需要分配的分区,均匀的分配到现有可用的消费者中即可
- 减少上下文的切换
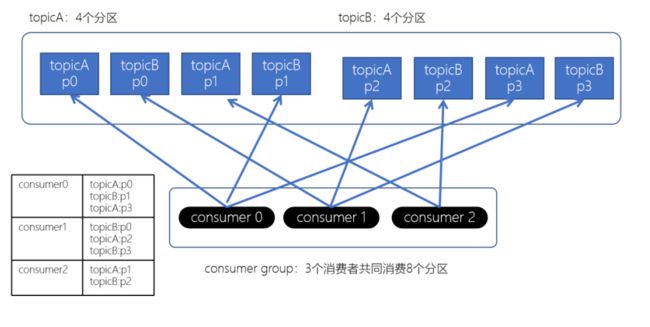
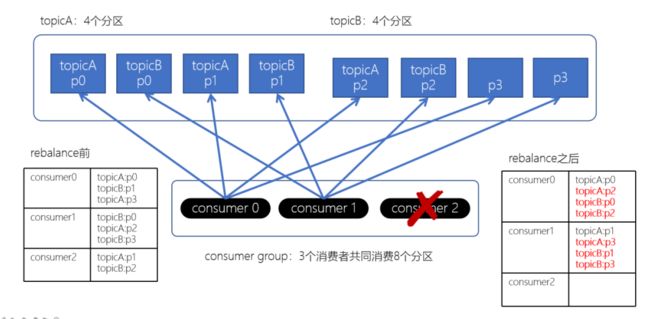
上面如果consumer2崩溃了,此时需要进行rebalance。如果是Range分配和轮询分配都会重新进行分配,例如:
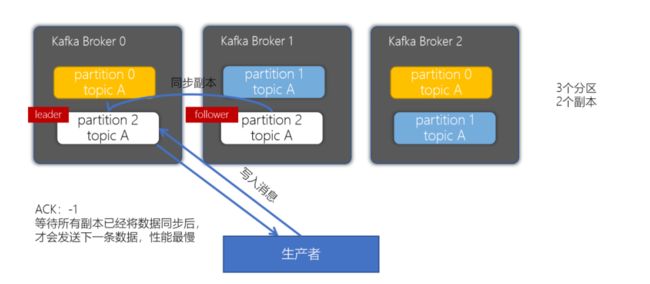
副本机制(保存机制,从节点如何保存,ACK如何返回)
props.put("acks", "all");
acks配置为0(管发不管收)
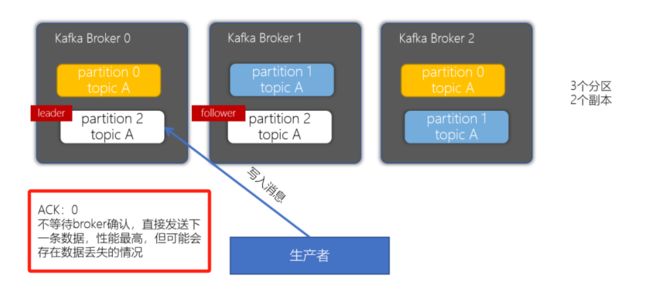
acks配置为1(只管主节点保存,不管从节点是否保存)
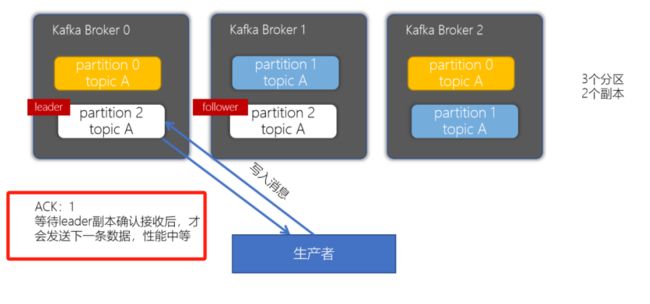
acks配置为-1或者all(主从节点都保存完好,才返回ACK)
高级(High Level)API与低级(Low Level)API
高级(High Level):自动化
l 上面是之前编写的代码,消费Kafka的消息很容易实现,写起来比较简单
l 不需要执行去管理offset,直接通过ZK管理;也不需要管理分区、副本,由Kafka统一管理
l 消费者会自动根据上一次在ZK中保存的offset去接着获取数据
l 在ZK中,不同的消费者组(group)同一个topic记录不同的offset,这样不同程序读取同一个topic,不会受offset的影响
高级API的缺点
l 不能控制offset,例如:想从指定的位置读取
l 不能细化控制分区、副本、ZK等
public class _2ConsumerTest {
public static void main(String[] args) {
// 1. 创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.88.100:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2. 创建Kafka消费者
KafkaConsumer consumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
consumer.subscribe(Arrays.asList("test"));
// 4. 使用一个while循环,不断从Kafka的topic中拉取消息
while (true) {
// 定义100毫秒超时
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} 低级(Low Level):半自动(手动)
通过使用低级API,我们可以自己来控制offset,想从哪儿读,就可以从哪儿读。而且,可以自己控制连接分区,对分区自定义负载均衡。而且,之前offset是自动保存在ZK中,使用低级API,我们可以将offset不一定要使用ZK存储,我们可以自己来存储offset。例如:存储在文件、MySQL、或者内存中。但是低级API,比较复杂,需要执行控制offset,连接到哪个分区,并找到分区的leader。
手动消费分区数据(基于assign消费)
我们需要指定要消费的分区,例如:
l 如果某个程序将某个指定分区的数据保存到外部存储中,例如:Redis、MySQL,那么保存数据的时候,只需要消费该指定的分区数据即可
l 如果某个程序是高可用的,在程序出现故障时将自动重启(例如:后面我们将学习的Flink、Spark程序)。这种情况下,程序将从指定的分区重新开始消费数据。
1.不再使用之前的 subscribe 方法订阅主题,而使用 「assign」方法指定想要消费的消息
String topic = "test";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
2.一旦指定了分区,就可以就像前面的示例一样,在循环中调用「poll」方法消费消息注意
1. 当手动管理消费分区时,即使GroupID是一样的,Kafka的组协调器都将不再起作用
2. 如果消费者失败,也将不再自动进行分区重新分配