【JAVA数据结构】哈希表-HashSet and HashMap
文章目录
- JAVA数据结构 & 哈希表 -HashSet and HashMap
-
- 引例
- 1. 哈希方法导致的冲突
-
- 1.1 冲突的避免(从整体减少冲突的次数)
- 1.2 冲突的解决
-
- 1.2.1 闭散列
- 1.2.2 开散列(哈希桶)
- 2. 基础简单的HashSet的模拟
-
- 2.1 属性
-
- 2.1.1 节点
- 2.1.2 已存放元素个数以及实际负载因子
- 2.2 方法
-
- 2.2.1 构造方法
- 2.2.2 放置方法
- 2.2.3 计算负载因子方法
- 2.2.4 扩容重塑方法
- 2.2.5 获取key键方法
- 3. HashMap的模拟
- 4. 数据类型为引用类型
- 5. 集合类的基本用途与使用
-
- 5.1 实例化Map
-
- 注意
- 5.2 实例化Set
-
- 5.2.1 迭代器
- 5.2.2 toArray()
- 注意
- 6. 哈希部分源码
-
- 6.1 HashMap
-
- 6.1.1 一些常量
- 6.1.2 哈希方法
- 6.1.3 调整容量
- 6.1.4 构造方法
- 6.1.5 LinkedHashMap
- 6.2 HashSet
JAVA数据结构 & 哈希表 -HashSet and HashMap
引例
-
在讲这个部分之前,请试着去做一下下面这道题。
-
题:给定一串序列(char[] (小写字母)),要求你将其排序并且不能出现重复也不能有一个缺席。
-
没错,我们可以这么做:
-
char[] arr = new char[26]; //假设ch 为某个小写字母; arr[ch - 'a']++; -
我们可以讲这个字母减掉’ ‘ a ’(即 97),这样a对应0,b对应1…
-
这样我们就只需要遍历一遍数组,只要不是’\u0000’(默认值),就打印or其他。
- 并且也可以快速知道对应字母的个数。
-
这样的思想就是“哈希思想”,把一个元素以特定的方法放进数组里,只要知道这个方法,就可以快速查找并且快速发现重复…
-
-
Set和Map的最大用处就是查找!
- 哈希的时间复杂度甚至达到了O(1)!
- 因为根据下标来找,太快了!
- 哈希的时间复杂度甚至达到了O(1)!
1. 哈希方法导致的冲突
- 细心的同学可能发现了,用同一个哈希方法的话,避免不了两个元素放在了同一个位置去了,那么我们就需要避免和解决。
1.1 冲突的避免(从整体减少冲突的次数)
- 这里要用到一个 负载因子常量的概念(其他地方可能有其他的说法)
- 这个负载因子就是哈希表中【已经放入的元素的个数 / 表最大容量】的最大值
一些实验数据事实表明:
-
哈希表越满越容易冲突
- 呈现出S型趋势

-
设计:
- 只需要让实际的负载因子时刻小于这个最大值,一旦大于等于这个最大值的时候,就让数组扩容。
- 也面临了另一个大问题,就是扩容后,需要重新将每个元素按照原本的哈希方法放进哈希表。
-
public static final double Load_FACTOR = 0.75;//一直处于七五分满
1.2 冲突的解决
1.2.1 闭散列
- 散列这个说法一些书籍仍在使用【哈希表的意思】
- 那么闭散列就是在顺序表内部解决这个问题
- 至于用顺序表是因为下标访问快
- 线性探测法
- 发现用哈希方法解析后的下标,已经被占用,那么从左往右探测,第一个空的就可以放上去
- 缺点很大:放的效率很低,取的时候效率也低,要找的那个位置不是我们要的数据,那么就要“线性探测”从左往右遍历找我们的数据。
- 并且我们很难去区分这个位置是否有元素,比如int[] 可能值就是0,引用类型也可能值就是null,怎么就能说明那个位置空了呢?
- 很容易达到负载值而需要重新扩容
- 这个方法很少用,最多出道题恶心人。
- 例如问,按照线性探测法找,需要多少步?
- 发现用哈希方法解析后的下标,已经被占用,那么从左往右探测,第一个空的就可以放上去

- 二次探测法
-
本质上跟【线性探测法】的思路是一致的,放在顺序表的其他空的位置。
-
但是这个方法是按照一个规律去实现的
- Hi = (H0 + i2) % m【m为表的大小,H代表哈希值(后面会讲)】
- Hi = (H0 - i2) % m【或者是这种】
-
【i】就是“跳跃的次数”,即第一次发现该位置有人,跳一次,此时 i为1
- 跳一次后发现位置还是有元素,再次跳一次,此时 i为2
- 注意:放置的时候发现没有元素,即 i为0
-
如下图所示(e代表元素element):
-

-
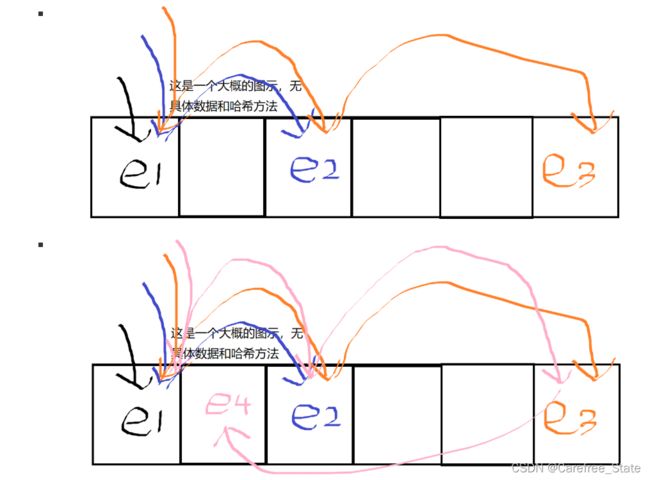
-
-
这种方法是线性探测法的优化,加快了放置查找的速度
- 其他缺点依旧一个不落的继承
1.2.2 开散列(哈希桶)
-
也就是在顺序表“外”
-

-
如图所示,让数组的类型为“链表的节点”,遇到该位置已经被占用,就头插进去就好
- 用带头+尾插的技巧也是完全可以的,因为插入的时候都是要检测是否重复的,自然到达链尾很容易
-
有些地方用二叉搜索树,甚至高度平衡的二叉树【即红黑树】
-
如下图所示:
-

-
是否是就很像一个一个的“桶”
- 所以才叫哈希桶
2. 基础简单的HashSet的模拟
- 用简单的 int(基本数据类型)
- 如下图的大概模板
- 属性:
- 节点数组
- 已存放元素个数
- 负载因子最大值
- 方法:
- 构造方法
- 放置方法(重复则覆盖)
- 扩容重塑方法
- 计算负载因子方法
- 获取key键方法(这里可以认为是判断是否存在)
- 这里如果是Map,则对应返回的应该是键值对key对应的value值
- 属性:
public class HashBuck {//哈希桶法
static class Node {
}
public Node[] array;
public int useSize;
public static final double Load_FACTOR = 0.75;//"全局"常数
public HashBuck() {
array = new Node[10];
}
public void put(int key) {
}
private void resize() {
}
private double calculateLoadFactor() {
}
public boolean get(int key) {
}
}
2.1 属性
2.1.1 节点
//静态内部类
static class Node {
public int key;
public Node next;
public Node(int key) {
this.key = key;
}
}
public Node[] array;
2.1.2 已存放元素个数以及实际负载因子
public int useSize;
public static final double Load_FACTOR = 0.75;//"全局"常数
2.2 方法
2.2.1 构造方法
public HashBuck() {
array = new Node[10];//默认大小为10
}
2.2.2 放置方法
- 哈希方法我并没有直接做一个方法出来,一般就是一条表达式而已
- 这里是
int index = key % array.length;【取模法是很常见的】
public void put(int key) {
int index = key % array.length;
Node cur = array[index];
//检测
while(cur != null) {
if(cur.key == key) {
return;
}else {
cur = cur.next;
}
}
//头插
Node newOne = new Node(key);
newOne.next = array[index];
array[index] = newOne;
//已存放元素+1,并且计算是否超过负载因子最大值,若超过,则扩容重塑
useSize++;
if(calculateLoadFactor() > Load_FACTOR) {
resize();
}
}
2.2.3 计算负载因子方法
private double calculateLoadFactor() {
return (double) useSize / array.length;
}
2.2.4 扩容重塑方法
- 只需要遍历节点数组【哈希表】,null一定代表没有数据
- 不是null的就将该链表遍历一遍,每一个键值重新放置
- 这里拿一个新的数组放的原因是,重新放置可能会放在前面也可能放置到后面,那么这个值等一下可能又会被遍历到。
- 不是null的就将该链表遍历一遍,每一个键值重新放置
private void resize() {
//扩容两倍,当然可以其他倍数(系统为1.5倍,随后细说)
Node[] newArr = new Node[array.length * 2];
//重塑
for (int i = 0; i < array.length; i++) {
while(array[i] != null) {
int index = array[i].key % newArr.length;
Node cur = newArr[index];
Node newOne = new Node(array[i].key);
if(cur == null) {
newArr[index] = newOne;
}else {
// 尾插法 while(cur.next != null) {
// cur = cur.next;
// }
// cur.next = new Node(array[i].key, array[i].val);
newOne.next = cur;
newArr[index] = newOne;
}
array[i] = array[i].next;
}
}
//指向新的节点数组
array = newArr;
}
2.2.5 获取key键方法
public boolean get(int key) {
int index = key % array.length;
Node cur = array[index];
while(cur != null) {
if(cur.key == key) {
return true;
}
cur = cur.next;
}
return false;
}
- 我在这里就不测试了
3. HashMap的模拟
- 在【2】的基础下,只需要让节点多一个成员,则多出一层“映射关系”,这就是Map映射
- 如下代码,大致与上面相似
- key为自变量,不能重复,重复则覆盖(value值更改)
public class HashBuck {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
public Node[] array;
public int useSize;
public static final double Load_FACTOR = 0.75;//"全局"常数
public HashBuck() {
array = new Node[10];
}
public void put(int key, int val) {
int index = key % array.length;
Node cur = array[index];
while(cur != null) {
if(cur.key == key) {
cur.val = val;
return;
}else {
cur = cur.next;
}
}
Node newOne = new Node(key, val);
newOne.next = array[index];
array[index] = newOne;
useSize++;
if(calculateLoadFactor() > Load_FACTOR) {
resize();
}
}
private void resize() {
Node[] newArr = new Node[array.length * 2];
for (int i = 0; i < array.length; i++) {
while(array[i] != null) {
int index = array[i].key % newArr.length;
Node cur = newArr[index];
Node newOne = new Node(array[i].key, array[i].val);
if(cur == null) {
newArr[index] = newOne;
}else {
// 尾插 while(cur.next != null) {
// cur = cur.next;
// }
// cur.next = new Node(array[i].key, array[i].val);
newOne.next = cur;
newArr[index] = newOne;
}
array[i] = array[i].next;
}
}
array = newArr;
}
private double calculateLoadFactor() {
return (double) useSize / array.length;
}
public int get(int key) {
int index = key % array.length;
Node cur = array[index];
while(cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;
}
}
4. 数据类型为引用类型
- 我们刚才用的是int[ ] ,如果是String类型,自定义类型呢?
- 那么这里就需要用到一个方法
hashcode(),这个方法可以获取到哈希值(引用类型的身份证),这样就可以进行取模运算了- 如果是自定义类型,我们得自己重写
hashcode()方法,String系统已经重写了 - 一定一定要重写equals()方法,否则我们认为相同的两个引用,哈希值也会不同
- 如果是自定义类型,我们得自己重写
- 下面是泛型版本:
public class MyHashMap <K, V> {
//如果用到泛型的话,记住要重写一些方法,如equals 和 hashCode
//以及在特定位置补上自己的哈希方法
static class Node<K, V> {
public K key;
public V val;
public Node<K, V> next;
public Node(K key, V val) {
this.key = key;
this.val = val;
}
}
public Node<K, V>[] array;
public int useSize;
public static final double Load_FACTOR = 0.75;//"全局"常数
public MyHashMap() {
array = (Node<K,V>[])(new Node[10]);
}
public void put(K key, V val) {
int index = key.hashCode() % array.length;
Node<K, V> cur = array[index];
while(cur != null) {
if(cur.key.equals(key)) {
cur.val = val;
return;
}else {
cur = cur.next;
}
}
Node<K, V> newOne = new Node<>(key, val);
newOne.next = array[index];
array[index] = newOne;
useSize++;
if(calculateLoadFactor() > Load_FACTOR) {
resize();
}
}
private void resize() {
Node<K, V>[] newArr = (Node<K,V>[]) (new Node[array.length * 2]);
for (int i = 0; i < array.length; i++) {
while(array[i] != null) {
int index = array[i].key.hashCode() % newArr.length;
Node<K, V> cur = newArr[index];
Node<K, V> newOne = new Node<>(array[i].key, array[i].val);
if(cur == null) {
newArr[index] = newOne;
}else {
// 尾插 while(cur.next != null) {
// cur = cur.next;
// }
// cur.next = new Node(array[i].key, array[i].val);
newOne.next = cur;
newArr[index] = newOne;
}
array[i] = array[i].next;
}
}
array = newArr;
}
private double calculateLoadFactor() {
return (double) useSize / array.length;
}
public V get(int key) {
int index = key % array.length;
Node<K, V> cur = array[index];
while(cur != null) {
if(cur.key.equals(key)) {
return cur.val;
}
cur = cur.next;
}
return null;
}
}
-

- 数组的构建参考的是hashMap源码
- 数组的构建参考的是hashMap源码
-
下面是随便一个自定义类:
-
class student { char[] name; int id; int score; }
-

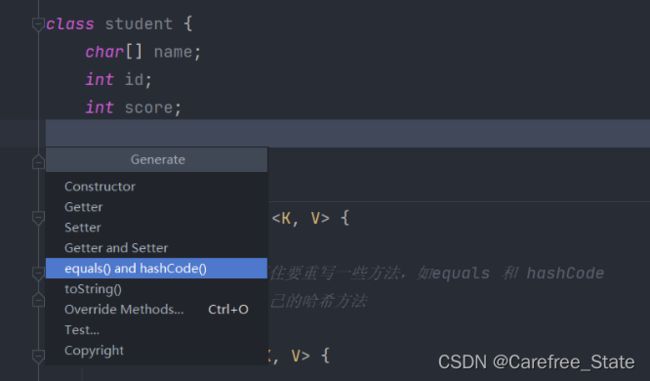
- 【Alt + insert】后点击这个东西,一路next就好了
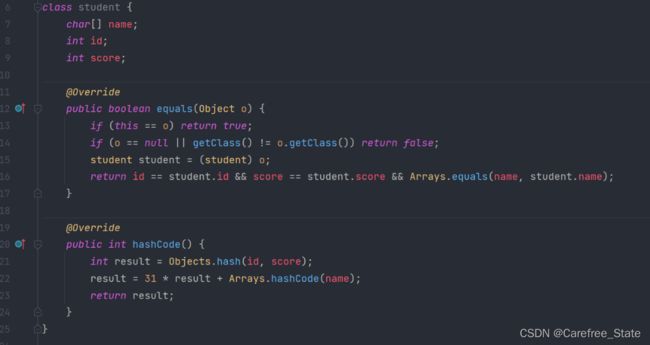
- 我们也可以自己去决定“怎么样才算相等”,自己重写equals()
5. 集合类的基本用途与使用
5.1 实例化Map
-
一般用普通类实例化接口的形式,这样这个引用的功能更加具有针对性。
-
接下来来看看Map的一些基本功能(高亮即重点)
-
方法 解释 V get(Object key) 返回key对应的value值 V getOrDefault(Object key, V defaultValue) 返回对应value,不存在则返回defaultValue V put(K key, V value) 放置键值对(key重复则覆盖) V remove(Object key) 根据唯一的key删除键值对 Set keySet() key不重复,将所有key值放在Set里并返回 Collection values() 将所有values放在集合中并返回 Set 返回所有键值对集(entry即条目) boolean containsKey(Object key) 是否存在key值 boolean containsValue(Object value) 是否存在value值 -
其中还有一个特别重要的静态内部接口,Entry
-
这里我们可以理解为,将key和value打包起来了,成为一个独立的引用,其实里面
-
方法 解释 K getKey() 获取键值对的key值 V getValue() 获取键值对的value值 V setValue(V value) 设置键值对的value值 Set<Map.Entry<Integer, Integer>> set = hashMap.entrySet(); Map.Entry<Integer, Integer>[] entry = (Map.Entry<Integer, Integer>[]) set.toArray();//把map的 key 和 value 组装成一个整体 entry[0].getKey(); entry[0].getValue(); entry[0].setValue(); -
无法设置key,转化为Set有什么用,等一下将Set的时候细说!
-
接下来解答一些疑惑,就是为什么返回类型是接口/抽象类型,但是仍然可以正常使用?
- 原因就是,重写方法的规矩除了完全相等以外,还有一个例外
- 就是,返回类型呈现继承/实现关系,【父亲方法的返回类型】被【子类方法的返回类型】继承或者实现,也是重写!
- 这样,返回类型就可以是普通类啦,并且哈希实现就是哈希,树实现就是树。
- 原因就是,重写方法的规矩除了完全相等以外,还有一个例外
-
至于Entry的本质
-

-
这是源码,Entry被Node实现后,
- 只要被Node实例化,【对应的引用就有了对应的Node】,也就有了对应的【key,value】
- 这是因为,方法被重写后,访问key和value并非private
- 这样就能够在父类访问子类成员了!
- 这样,使用Entry的get…方法,就相当于有对应的Node引用使用了get…方法,就获取到了对应的key,value值
-
对于entrySet()方法
-
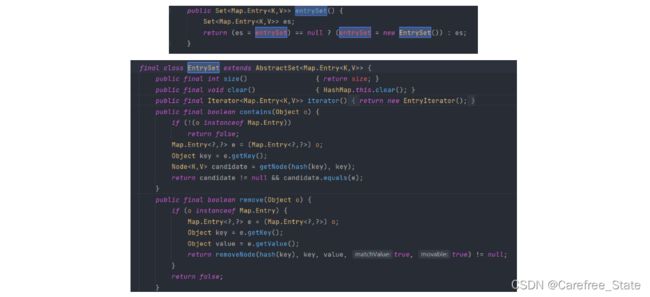
-
看不懂不重要,重要的是解决了我们的疑问
- 就是,Entry被一个特定的Node实例化后,Node被删除,还访问得到吗?
- 明确的告诉你,还可以,因为这里的节点被(深)拷贝了一份,Entry是被这份拷贝实例化的!
-
注意
- key唯一,value不唯一,key不可被设置,只能删掉重新放置
- 哈希里是可以存放null的,而树不可以(因为null不能比较,会抛异常的)
- Map并不是”Collection家族“的
5.2 实例化Set
-
下面是Set的基本功能(高亮即重点)
-
方法 解释 boolean add(E e) 增加元素,重复则会失败,返回false void clear() 清空集合 boolean contains(Object o) 查看元素是否存在 Iterator iterator() 返回迭代器 boolean remove(Object o) 删除对应元素 int size() 返回集合大小 boolean isEmpty() 集合是否为空 Object[] toArray() 转化为数组(非基本数据类型数组!) boolean containsAll(Collection c) 查询c集合的所有元素是否个个都存在 boolean addAll(Collection c) 添加一整个集合的所有元素,去重作用(完全不重复则返回true)(有现成的集合类的时候适用) 5.2.1 迭代器
-
这个“工具”的作用就是遍历集合
-
用法如下:
-
hasNext() 与 next()这两个方法打配合
-
-
public static void main(String[] args) { Map<String, Integer> hashMap = new HashMap<>(); hashMap.put("小卡拉", 3); hashMap.put("马拉圈", 4); hashMap.put("芜湖", 5); System.out.println(hashMap.get("小")); Set<Map.Entry<String, Integer>> set = hashMap.entrySet(); //for-each 语法遍历 for(Map.Entry<String, Integer> s : set) { System.out.print(s.getKey() + " " + s.getValue() + " "); } //迭代器遍历法 Iterator<Map.Entry<String, Integer>> iter = set.iterator(); //Iterator 用通配符也可以 while(iter.hasNext()) { System.out.print(iter.next() + " "); } }
-
5.2.2 toArray()
-
这个方法有两个用法
-
(T[])set.toArray(); //需要强制类型转化!由于擦除机制,数组的返回是Object[] -
set.toArray(arr); //这个arr必须是对应的非基本数据类型数组!或者父类数组 //set里面的元素被整合到arr里了 //返回值可以不接收,接收的话,方式跟上面一样 -
需要重点强调的一点是,基本数据类型的数组与其包装类的数组不能直接相互转化(自然也不存在自动拆箱装箱),必须遍历一遍!!!
其他方法相对简单,不细说
注意
- Set是Collection家族的接口类
- key值唯一,Set重点在于除重
- key要修改,必须删除再添加
- 树的key不能是null,因为需要比较
- TreeSet/HashSet底层由Map实现,value为Object类型的一个默认对象,key就是key
- 节省功夫嘛

- Set和Map 还可用 LinkedHashSet和LinkedHashMap实例化
- 这维护了双向链表,可以记录元素的插入次序
6. 哈希部分源码
- 刚才已经接触了一些源码了,接下来只有一些补充了
6.1 HashMap
6.1.1 一些常量
-

-

- 这个是默认的表的默认容量
-

- 这个是表的最大容量
-

- 这个是负载因子默认最大值
-

- 这个哈希桶树化临界值
- 即桶内节点达到8,就会折叠成红黑树(原本只是链表)
- 这个哈希桶树化临界值
-

- 这个是哈希桶退化为链表的临界值
- 即桶内节点被删除到6,就会退化成链表(原本是红黑树)
- 这个是哈希桶退化为链表的临界值
-

- 这个是哈希桶树化前提的前提
- 就是,表的容量很少时,可能会导致桶内的东西太多了【就是冲突次数多】
- 那么规定一个值,当表的已有元素总数(节点总个数)达到这个值的时候,才考虑折叠链表为红黑树,其他情况直接扩容即可【其他情况是指,桶内元素达到界值后不选择树化,而是扩容哈希表】
- 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 *
TREEIFY_THRESHOLD
- 这个是哈希桶树化前提的前提
-
树化方法
treeifyBin就不带大家看了
-
6.1.2 哈希方法

- 此方法的作用是让值放的更分散
6.1.3 调整容量
-
这个操作是将容量调整为最接近的二进制数(较大)
- 即2, 4, 8, 16…
- 原理就是,让二进制序列最左边的1之后的位都变成1,
- 【10101】= =》【11111】= =》【100000】
- 右移按位与是让这个位【1】成倍数往后扩展
- 就是原本可能只有一个1扩展为两个1,扩展到四个1,这样最快

- 就是原本可能只有一个1扩展为两个1,扩展到四个1,这样最快
-
在一个构造方法中有用到
- 用途:搭配哈希方法降低冲突率
6.1.4 构造方法

- 提供容量和负载因子
- 提供容量
- 什么都不提供
- 提供一个Map,将整个Map的所有元素(拷贝成新的一个引用)
6.1.5 LinkedHashMap
- 在HashMap中并没有实例化对象LinkedHashMap的构造方法,但是有继承它的…
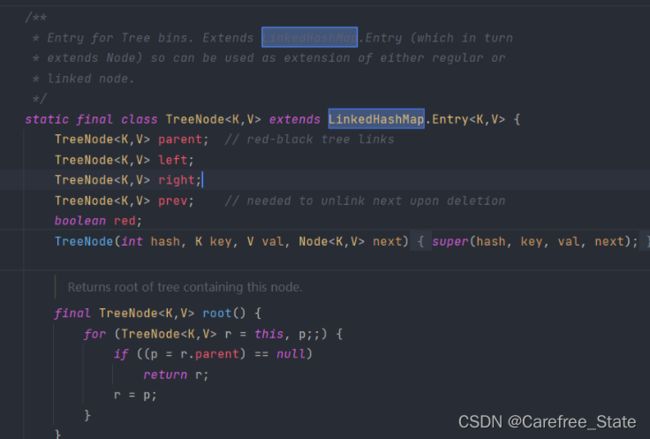
- 了解即可
6.2 HashSet
- 底层也是Map,key就是key,value是一个Object默认值
- 主要带大家看看构造方法

- 不带参数构造方法
- 提供一个集合引用,将所有元素导入Set里
- 提供容量和负载因子
- 提供容量
- 提供容量,负载因子以及布尔类型
-
这个类型并没有什么用,只是区分其他构造方法而已
-

-
就是构造LinkedHashMap( )
-
本质上LinkedHashSet就是用到的就是这个方法
-
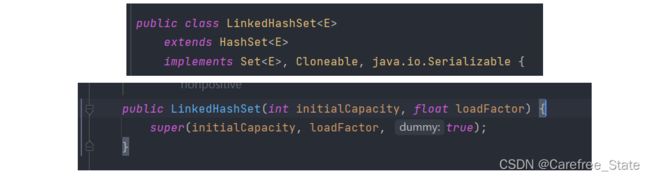
-
文章到此结束!谢谢观看
可以叫我 小马,我可能写的不好或者有错误,但是一起加油鸭!这是我的代码仓库!(在马拉圈的23.2里)代码仓库
Map&Set · 代码位置