人脸识别loss系列推导过程及演变
人脸识别网络结构

一般的人脸识别网络,在使用的时候,只包括了上图中 feature及其上面的部分。输入经过人脸检测以及对齐的待识别图片,经过CNN后得到这个图片相应的特征(feature),通过特征间的比对来判断个人信息。性能良好的人脸识别网络是可以令同一个人的不同图片输出类似的特征,而属于不同人的图片会输出差异较大的特征,目前通常判断两个特征是否相识,是通过计算两者的余弦距离来确定,也就是两个向量的叉乘再除以两个向量的模长。
要实现良好的人脸识别性能,就需要先进行训练。训练时加入一个FC层以及loss函数,这个FC层是一个长为class(训练ID个数)的输出向量。FC层的输出是通过weight参数直接生产,显然这个参数的长宽为:feature*class,这个是后续的基础。对于最终的FC输出,做分类训练,这个训练使得网络有能力对很多的训练数据进行准确的分类,那当需要对非训练集中的人进行特征提取然后分类,也是可以达到良好效果的。而近年来对人脸识别的学术研究,主要是集中在训练部分,对训练的研究主要是集中在loss函数部分。下面,我就介绍目前的一些常见的loss。包括有softmax loss、centernet loss、L-softmax loss、A-softmax loss(sphereface)、cosineface、Arcface、regularface等等, 其中softmax loss的后面的loss的最初形式,而center loss是加入了欧式距离来缩小类内距离,其他的几个Loss都是基于类的向量夹角的思路来进行改进的,这个也是最近几年的主流方向。本文就主要说一下其中有代表性的几个,其他的几个,也是差不多的思路,直接去看函数公式也是问题8大的。
注意:训练的本质是得到两个目的:缩小类内距离、增大类间距离。对于每个loss函数都应该思考它们是如何达到这两个目的,因为这个是分类的最本质指导方向。
softmax loss:
先假设训练集有3个ID,每个ID有几张图,而特征长度设为2,因此weight参数shape是3*2,如下图:

其中Y就是最终的FC层输出,分类的softmax方式就是让Y中对应那个类的位置数值很大,而其他位置的数值很小,而依照这个思想的loss为:
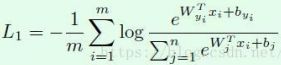
其中的Wx+b代表的是图中的Y的一个值(shape:1,1),W是weight的一个参数(shape:1,2),x是feature(shape:2,1),b是偏置量,很多情况下会不要这个偏置量。由于假设了是3个ID,那n就代表3,Y的输出有3个值Y0,Y1,Y2,从分类的思想来看,就是要训练的ID标签对应的Yi值很大,同时其他的值很小(如下图中①),式中分子部分就代表了标签对应的Yi。最直接的方式就是让标签对应的Yi占比很大,无限接近于1 。因为Y的几个输出可能会出现负数的情况,这种情况会影响到占比的计算方式。为了防止这种情况,就引进e的幂函数,这样就可以让幂函数过后的值保持为正数(如下图中②),并且其占比的计算结果保持在0~1的范围内。为了使得占比取向于1,同时Loss函数本身在训练的时候一直下降,那在占比的基础上,加上-log函数(如下图中③),即可让输出保持为不断下降的正数,而占比趋向于1 。这里涉及到的幂函数、对数等,可以自己画个函数图理解一下。

至此,softmax loss就可以让模型形成分类功能,但是这个loss并不是很关注类跟类之间到底隔得有多开,类里面的元素隔得有多近等方面,后续的函数将会继续研究这个。后续的函数,也会继续沿用这上述的分类数量、网络结构的假设,在softmax loss上面继续发展。
SphereFace loss
首先,我们先抛弃偏置b,这个可要可不要。Y输出就剩下的是Wx,两个向量的叉乘(shape:1,2 x 2,1),可以从几何角度理解为两个模长和夹角余弦的乘积,如下:
![]()
上式的等式,突显出了余弦值,即两个向量之间的夹角余弦值。为了公式更简洁,将Wj进行归一化(相对于除以一个整数而已)。如果是标签对应的Y值(例如Y1),那Wj归一化之后仍然是想这个Y值很大,其他Y值很小。从几何角度来说,就是cos值很大,即θ值小,两者的夹角小。所以就是特征x和相应的Wj的夹角很小,而和其他位置的Wj的夹角很大。为了让x与所对应的Wj夹角的余弦值有更强的响应,就个θ加上一个大于1的系数,就形成了sphereface的表达式了:


上图是softmax和sphereface的几何对比,很明显,在θ处加上了系数,令两个类别的间隔斜率大了。
cosineface loss
对于上述的sphereface中的xi的模,为了方便起见,cosineface直接将这个模长固定,用参数s代替(通常为64),这就更体现出x和W的余弦距离了。同时,加入正则化的思想,在余弦距离上减去m,使得余弦距离更加严。为保持斜率一致,也不加上θ的系数了,这就形成了cosineface的公式:

arcface loss
上面是通过加大两个向量间的余弦距离来让分类间隔更大,而Arcface的想法是用更加直接的角度距离来处理,给θ来做正则化。这样就会使得损失函数更直接的映射到空间位置上。公式如下,而几何结构来看,这两个loss的形状很像,但Arcface的是直接和θ相关的loss,论文中也指出这个Arcface训练出来的模型准确率更高。
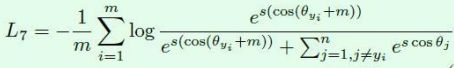

regularface loss
这个方法是最近论文出现的,我觉得其最闪光的点是,提出类间对类间距离的操作,将类间距离扩得更开,更均匀。因为上述的很多loss函数,都是让类间距离有一个m的安全距离,如下图,但是即使保证了有安全距离,还是不能保证类和类隔得足够开,足够均匀,所以这就回到了最本质的思路,对类间和类内距离的操作。首先用什么来表示类间距离呢,那应该就是用类的中心直接,和其他最近的那个类中心的距离,就可以代表了。然后,怎么去找到类中心呢,其实在上述的loss推导中,我已经有所暗示了。继续用角度信息来代表分类模型,刚才说每个特征x和对应标签的Wj的夹角就是表示类内,是要缩小的对象。那每个类的所有图片的特征,都要去和Wj缩小夹角,那可以将Wj视为中心角度,然后同类的特征往这个中心角度去靠拢。所以就是Wj和相邻的Wj去计算余弦值,余弦值越小,则代表角度越大。

具体操作来说,就是每个Wj求和其他Wj的都归一化之后的叉乘,选出值最大的那个作为离最近的中心点的余弦值。例如说如果现在的weight的是(3,2)的矩阵,就是矩阵乘法乘自己的转置矩阵,得到一个(3,3)的矩阵,第一行就代表第一个中心分别和包括自己的3个中心的余弦距离,去掉每一行的和自己的乘积之后的最大值,就是这个类到其他类的最近距离。论文里面是将这几个距离的和作为类间距离的代表,同时用centerface或者sphereface作为类内距离的代表,两个加起来,作为最终的loss。
![]()

这里的λ是类间距离的系数,范围是0到1,越训练到后面越大。目前作者对这个方法的类间距离计算方式有一个pytorch的实现,也比较简单的。我用在方法在pytorch和mxnet都训练过一下。