如前文图数据Neo4j导论所提,Neo4j是一个具有原生处理(native processing)功能和原生图存储(native graph storage)的图数据库(上文)。本文将继续探秘图数据库Neo4j,从其内部构造来讨论它的实现,展示它们与其他对复杂的、结构可变的、紧密关联的数据的存储方法和查询方法的不同之处。
1. Neo4j 原生图处理
在前文中我们已经讨论过图数据库的一些基本概念。本文假设读者应该对节点通过命名的和有方向的联系关联、节点和联系都作为属性的容器这些概念有所熟悉。
虽然图模型在图数据库的各种表现基本上是一致的,但在数据库引擎的实现方式缺失百花齐放。对于很多不同的引擎体系结构,如果图数据库存在免索引邻接属性(index-free adjacency field) ,那么行业上通常认为它具有原生处理能力。
在免索引邻接的数据库引擎中,每个节点都会维护其对相邻节点的引用。因此每个节点都表现为其附近节点的微索引,这比使用全局索引代价小很多。这意味着查询时间与图的整体规模无关,它仅和所搜索图的数量成正比。
相反,一个非原生图数据库引擎使用(全局)索引连接各个节点,如下图所示。这些索引对每个遍历都添加一个间接层,因此会导致更大的计算成本。原生图处理的拥护者认为免索引邻接至关重要,因为它提供快速、高效的图遍历。
相对于RDBMS的关系查询,图数据库的改进在于:
免索引邻接使用遍历物理关系的方法查找,比全局索引来说代价小很多。查询一个索引的时间复杂度一般为
O(log(n)),而遍历物理关系的时间复杂度仅为O(1)。如果我们要遍历一个m步的网络,索引方法需要花费O(mlogn)的时间,这面对成本仅为O(m)的免索引邻接就显得相形见绌了。RDBMS当索引建立后,试图反向遍历时,建立的索引就会不起作用了,需要再反向建立索引。而免索引邻接机制就不会有问题。
上图展示了非原生图处理方法的工作原理。要寻找Alice的朋友,我们必须首先执行索引查找,成本为O(logn)。这对于偶尔的或浅层的查找来说可能是可以接受的,但当我们改变遍历方向时,它的代价很快变得昂贵起来。如果相对于寻找Alice的朋友,我们想要寻找的是和Alice交朋友的人,我们将不得不执行多个索引来完成查找,每个节点所代表的人都可能把Alice当作他的朋友。这使得成本更高。找到Alice的朋友的代价是O(logn),而找到和Alice交朋友的人的代价则是O(m log n)。索引查找在小型网络中可以工作,但对于大图的查询代价太高。具有原生图处理能力的图数据库在查询时不是使用索引查找来扮演联系的角色,而是使用免索引邻接来确保高性能遍历的。下图显示了联系是如何消除索引查询的需求的。
在通用图数据库中,可以以极小的代价双向(从尾部到头部或者从头部到尾部)遍历关系,上图中寻找ALICE的朋友,直接向外寻找friend就可以。其遍历的成本为O(1),要寻和Alice交朋友的人,我们只需要所有指向ALICE的friend关系联系在一起即可,这样的成本是O(1).
2. Neo4j 原生图处理存储
免索引邻接是图数据实现高效遍历的关键,那么免索引邻接的实现机制就是neo4j底层存储结构设计的关键。能够支持高效的、本地化的图存储以及支持任意图算法的快速遍历,是使用图数据库的重要原因。
2.1 存储文件
从宏观角度讲,neo4j只存在两种数据类型:
- 节点:节点类似于ER图中的实体,每一个实体可以有零个或多个属性,这些属性以key-value对的形式存在,属性没有特殊类别的要求,同时每个节点还具有相应的标签,用来区分不同类型的节点。
- 关系:关系也类似ER图中的关系,一个关系有起始节点和终止节点,另外,关系也能够有自己的属性和标签。
这样的数据结构的好处:Neo4j节点和关系的存储文件只关系图的基本存储结构而不是属性数据。这两种记录都使用固定大小的记录,能方便根据ID快速计算存储位置。并且节点和关系记录变得相当轻量级。下面我们来看下具体文件存储。
neo4j 在磁盘上会分不同的 store file 存储
- neostore.nodestore.db:存储 node
- neostore.propertystore.db:存储属性
- neostore.relationshipstore.db:存储关系
一个重要的设计点是 store 中存储的 record 都是固定大小的,固定大小带来的好处是:因为每个 record 的大小固定,因此给定 id就能快速进行定位。
节点与关系的存储文件的物理结构图 上图第一个是 node record 的结构:
1byte:in-use flag,表明该 node 是否在使用
4byte:第一个 relation id(-1表示无)
4byte:第一个 property id(-1表示无)
5byte:label 信息(可能直接 inline 存储)
1byte:reversed
图中的节点和联系的存储文件都是固定大小的,每个记录长度为9字节,因此可以可以在O(1)的时间复杂度下计算位置。
节点(指向联系和属性的单向链表,neostore.nodestore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表关联到这个节点的第一个关系的ID,再接着的4个字符,代表第一个属性ID,后面紧接着的5个字符是代表当前节点的标签,指向该节点的标签存储,最后一个字符作为保留位.
关系(双向链表,neostore.relationshipstore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表起始节点的ID,再接着的4个字符,代表结束个节点的ID,然后是关系类型占用5个字节,然后依次接着是起始节点的上下联系和结束节点的上下节点,以及一个指示当前记录是否位于联系链的最前面.
同时还有属性存储(neostore.propertystore.db)也是固定大小,每个属性记录包括4个属性块(一个属性记录最多容纳4个属性)和指向属性链中下一个属性的ID. 属性记录包括属性类型和指向属性索引文件的指针(neostore.propertysotre.db.index). 同时属性记录中可以内联和动态存储,在属性值存储占用小时,会直接存储在属性记录中,对于大属性值,可以分别存储在动态字符存储(neostore.propertysotre.db.strings)和动态数组存储(neostore.propertysotre.db.arrays)中,由于动态记录同样由记录大小固定的记录链表组成,因此大字符串和大数组会占据多个动态记录.
节点存储文件用来存储节点的记录。每个用户级的图中创建的节点最终会终结于节点存储,其物理文件是"neostore.nodestore.db"。像大多数Neo4j存储文件一样,节点存储区是固定大小的记录存储,每个记录长度为9字节。通过大小固定的记录可以快速查询存储文件中的节点。 一个节点记录的第一个字节是“是否在使用”标志位。它告诉数据库该记录目前是被用于存储节点,还是可回收用于表示一个新的节点。接下来的4字节表示关联到该节点的第一个联系,随后4字节表示该节点的第一个属性的ID。标签的5字节指向该节点的标签存储(如果标签很少的话也可以内联到节点中)。最后的字节extra是标志保留位。这样一个标志是用来标识紧密连接节点的,而省下的空间为将来预留。节点记录是相当轻量级的:它真的只是几个指向联系和属性列表的指针。 相应的,联系被存储于联系存储文件中,物理文件是neostore.relationshipstore.db。像节点存储一样,联系存储区的记录的大小也是固定的。每个联系记录包含联系的起始点ID和结束节点ID、联系类型的指针(存储在联系类型存储区),起始节点和结束节点的上一个联系和下一个联系,以及一个指示当前记录是否位于联系链最前面。
节点存储文件和关系存储文件都只关心图的结构而不是属性数据,两种文件存储都是使用了固定大小的记录,以便文件内部任何记录都可以根据ID快速计算偏移量而被定位。这也是Neo4j高性能的关键。
2.2 图的构建
如下图,两个节点记录都包含一个指向该节点的第一个属性的指针和联系链中第一个联系的指针。要读取节点的属性,我们从指向第一个属性的指针开始遍历单向链表结构。要找到一个节点的联系,我们从指向第一个联系(在示例中为LIKES联系)的节点联系指针开始,顺着特定节点的联系的双向链表寻找(即起始节点的双向链表或结束节点的双向链表),直到找到感兴趣的联系。一旦找到了我们想要的联系记录,我们可以使用和寻找节点属性一样的单向链表结构读取这种联系的属性(如果有的话),也可以使用联系关联的起始节点ID和结束节点ID检查它们的节点记录。用这些ID乘以节点记录的大小,就可以立即算出每个节点在节点存储文件中的偏移量。
上图中包括2个标签为Person的点:Node 1和Node 2,Node 1有2个属性,分别为name:bob,age:25;Node 2有1个属性name:Alice。bob喜欢Alice,通过LIKES这条边来表示。由于2个点仅存一条边,所以LIKES边的起点和终点的下一条边指针为空。
2.3 双向存储
关系是属于两个节点的,和起始节点与结束节点都有关系。
比如这种 partner 的关系天然就是双向的,但是在neo4j存储的时候,真的要存储两个关系吗,如下图:
答案是否定的,这种存储就是一种浪费。 neo4j 以任意一个节点为开端,另一个为尾端,即存储成为单向的关系
在 neo4j 中任意的关系都有一个 start node 和一个 end node,而且 start node 和 end node 都会有个关联的双向链表,这个双向链表中就记录了从该节点出去和进入的所有关系。因此可以neo4j存储可以通过双向列表在任意一方快速迭代,并进行高效的插入和删除联系。
如果是要寻找关系,neo4j选择顺着关系链表中的任意一端开始遍历另一个关系,直到找到合适候选关系,并返回ID,业务上根据ID乘以记录大小,找到具体位置。
2.4 具体存储实例
在这个例子中,A ~ E表示Node 的编号,R1~R7 表示 Relationship 编号,P1~P10 表示Property 的编号。
Node 的存储示例图如下,每个Node 保存了第1个Property 和 第1个Relationship:
关系的存储示意图如下:
从示意图可以看出,从 Node-B 开始,可以通过关系的 next 指针,遍历Node-B 的所有关系,然后可以到达与其有关系的第1层Nodes,在通过遍历第1层Nodes的关系,可以达到第2层Nodes,...
3. 缓存优化
有一种高效的存储布局只是成功的一半。尽管存储文件已经为了快速遍历而进行了优化,但硬件的考量仍然对性能有着重大影响。近几年来,尽管内存容量已显著增加,一些非常大的图仍然无法完全存储在主存储器中。旋转型磁盘按位数寻道需要毫秒级的时间,这以人类的标准来说虽然已经很快,但在计算机领域中它仍然显得笨拙而缓
慢。周态磁盘(SSD)则要快得多(因为没有显著的等待盘片旋转的寻道时间),但CPU和磁盘之间的路径仍然要比CPU到L2高速缓存或主存储器的路径存在更多的延迟,理想的情况下我们更想使用后者来操作图。
为了缓解机械、电子类大容量存储设备的性能特点带来的延迟,许多图数据库使用内存缓存提供图的概率性低延迟访问。Neo4j从版本2.2开始使用堆外缓存(Off Heap Cache)来提升性能(Neo4j本身是以java开发的,原本只是用JVM内的资源)。 关于堆外缓存,可以参见本Java堆外缓存OHC的实现与应用;
[图片上传失败...(image-49fa3e-1650531416890)]
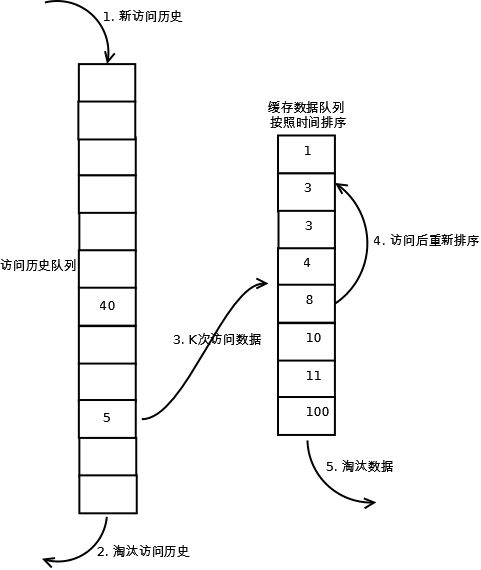
Neo4j从版本2.2开始使用最近最少使用(LRU-K)页缓存算法。这种页缓存是LRU-K约束页缓存,意味着高速缓存将每个存储划分成离散的区域,然后每个存储文件持有固定数量的区域。页的高速缓存置换基于最不经常使用(LFU)缓存策略,根据页的常用程度进行微调。也就是说,即使有些页在近期没有被使用过,但由于此前使用次数很多,也会先淘汰那些不常用的页并留在缓存中。该策略确保了缓存资源的统计学上的最优使用。关于LRU-K的相关信息,可以查看LRU与LRU-K算法实现
4. 参考文献
- 图数据库NEO4J 底层分析;
- 图数据库neo4j存储设计和免索引邻接
- Java堆外缓存OHC的实现与应用
- LRU与LRU-K算法实现
- LRU-K和2Q缓存算法介绍