达梦:dmfldr 数据装载
dmfldr(DM Fast Loader)是 DM 提供的快速数据装载命令行工具。用户通过使用 dmfldr 工具能够把按照一定格式排序的文本数据以简单、快速、高效的方式载入到 DM 数 据库中,或把 DM 数据库中的数据按照一定格式写入文本文件。
1.dmfldr 系统结构
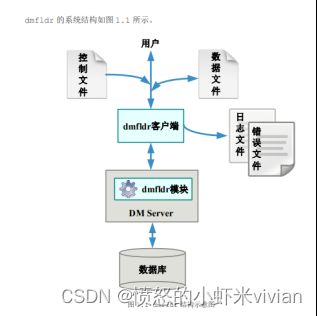
如图所示,dmfldr 实际上除了客户端工具,还包含一个在数据库服务器的 dmfldr 功能模块,它们共同完成 dmfldr 的各项功能。
当进行数据载入时,dmfldr 客户端接收用户提交的命令与参数,分析控制文件与数据文件,将数据打包发送给服务器端的 dmfldr 模块,由服务器完成数据的真正装载工作。并分析服务器返回的消息,必要时根据用户参数指定生成日志文件与错误数据文件。当进行数据导出时,dmfldr客户端接收用户提交的命令与参数,分析控制文件,将用户要求转换成相应消息发送给服务器端的 dmfldr 模块。服务器解析并打包需要导出的数据,发送给dmfldr客户端,客户端将数据写入指定的数据文件,必要时根据用户参数指定生成日志文件。
2. dmfldr使用
2.1 启动dmfldr
进入达梦数据库安装目录的bin目录下,找到dmfldr并指定相关参数进启动数据装载功能。(dmfldr 的使用必须指定必要的参数,否则工具会报错“无效的参数个数”并退出)

2.2 查看dmfldr参数
进入bin目录,使用dmfldr help 查看dmfldr参数信息,如下:
格式: dmfldr.exe KEYWORD=value
例程: dmfldr.exe SYSDBA/SYSDBA CONTROL='c:\fldr.ctl'
USERID 必须是命令行中的第一个参数
CONTROL 必须是命令行中的第二个参数
字符串类型参数必须以引号封闭
关键字 说明(默认值)
--------------------------------------------------------------------------------
USERID 用户名/口令, 格式:{[/] | /}[@][ 2.3 dmfldr 参数说明
注意:USERID必须是第一个参数,CONTROL必须是第二个参数,这两个参数都 不能省略;其余参数均为可选参数,可以不指定,指定时也无顺序要求。
| dmfldr参数名 |
使用说明 |
选项情况 |
| USERID |
USERID 用于指定数据库的连接信息。必选参数,且必须位于参数位置的第一个。 |
必选 |
| CONTROL |
控制文件的路径,字符串类型。必选参数,且必须位于参数位置的第二个。 |
必选 |
| LOG |
dmfldr 的日志文件路径,字符串类型。默认日志文件名为 fldr.log。日志文件记录 了 dmfldr 运行过程中的工作信息、错误信息以及统计信息。 |
可选 |
| NULL_STR |
指定数据文件中 NULL 值的表示字符串,字符串类型,默认忽略此参数。 若设置了 NULL_STR,则此参数值将成为数据文件中 NULL 值的唯一表示方式。 NULL_STR 区分字符串大小写,并且长度不允许超过 128 个字节。 |
可选 |
| BADFILE |
记录错误数据的文件路径,字符串类型。默认的错误文件名为 fldr.bad。文件记录 的信息为数据文件中存在格式错误的行数据以及转换出错的行数据 |
可选 |
| SKIP |
跳过数据文件起始的逻辑行数,整型数值。默认的跳过起始行数为 0 行。如果用户指 定了多个文件,且起始文件中的行数不足 SKIP 所指定的行数,则 dmfldr 工具会扫描下 一个文件直至累加的行数等于 SKIP 所设置的行数或者所有文件都已扫描结束 |
可选 |
| LOAD |
装载的最大行数,整型数值。默认的最大装载行数为数据文件中的所有行数。LOAD 指 定的值不包括 SKIP 指定的跳过的行数 |
可选 |
| ROWS |
每次提交的行数,整形数值。默认的提交行数为 50000 行。提交行数的值表示提交到 服务器的行数,并不一定代表按照数据文件中的数据顺序的行数。用户可以根据实际情况调 整每次提交的行数,以达到性能的最佳点。 |
可选 |
| DIRECT |
数据装载方式,布尔值。默认为 TRUE。DIRECT 指定了装载的方式,当为 TRUE 时, dmfldr 选择快速的载入模式,通过数据的转换和数据的封装直接对 B 树进行操作,省去 了普通插入方式下各个操作符之间的跳转,提升了装载的效率,但对于约束的检查等由用户 保证,dmfldr 将不处理有约束冲突的数据。当为 FALSE 时,dmfldr 选择普通的插入方 式装载数据,可以保证数据的正确性和约束的有效性,效率比前者要低。 |
可选 |
| SET_IDENTITY |
设置自增列选项,布尔值。默认为 FALSE。如果指定 SET_IDENTITY 选项值为 TRUE, 则 dmfldr 将把从数据文件中读取的自增列值作为目标值插入数据库表中,用户应当保证 每一行的自增列的值符合自增列的规则。如果 SET_IDENTITY 选项值设置为 FALSE,则 dmfldr 将忽略数据文件中对应自增列的值,服务器将自动生成自增列的值插入每一行的对 应列。 |
可选 |
| ERRORS |
最大的容错个数,整形数值。取值范围为[0,4294967295],默认为 100。当 dmfldr 在插入过程中出现错误的个数超过了 ERRORS 所设置的数目,则 dmfldr 会停止 载入,当前时间点的所有正确数据将会被提交到服务器。如果载入过程中不允许出现错误则 可以设置 ERRORS 为 0,如果允许所有的错误出现,则可以设置 ERRORS 为一个非常大的 数。ERRORS 所统计的错误包含在数据转换和数据插入过程中所产生的数据错误。 |
可选 |
| CHARACTER_CODE |
数据文件中数据的编码格式,字符串类型。默认为 GBK。CHARACTER_CODE 的可选项 有 GBK、GB18080、UTF-8、SINGLE_BYTE 和 EUC-KR 五种 |
可选 |
| MODE |
dmfldr 的装载模式,字符串类型。默认值为 IN。MODE 的可选项有 IN、OUT 和 OUTORA 三种 |
可选 |
| NULL_MODE |
指定载入和导出数据时对 NULL 字符串和空值的处理方式,布尔类型,默认为 FALSE。 若 NULL_MODE 为 TRUE,数据载入时将 NULL 字符串处理为空值,数据导出时则空值 处理为 NULL 字符串;若设置为 FALSE,数据载入时将 NULL 字符串处理为字符串,数据 导出时将空值处理为空串。 |
可选 |
| TASK_THREAD_NUMBE |
指定 dmfldr 在数据载入时处理用户数据的线程数目,整数类型,范围为 1~128。默 认情况下,dmfldr 将该参数值设为系统 CPU 的个数,但无论设定值是多少,dmfldr 至 少会创建 2 个任务线程。在多核 CPU 环境下,增大 TASK_THREAD_NUMBER 值可以提升 dmfldr 装载性能 |
可选 |
| BDTA_SIZE |
BDTA(Batch DaTA)的大小,整数类型,范围为 100~10000,默认为 5000。 BDTA 代表 DM 数据库批量数据处理机制中一个批量,在内存、CPU 允许的条件下,增 大 BDTA_SIZE 能加快装载速度;在网络是装载性能瓶颈时,增大 BDTA_SIZE 影响不大。 |
可选 |
| COMPRESS_FLAG |
指定是否压缩 BDTA,布尔类型,默认为 FALSE。 压缩 BDTA 能节省网络带宽,但同时也会加重 CPU 的负担,用户应根据具体应用情况 考虑是否制定压缩。 |
可选 |
| DATA |
指定数据文件路径,字符串类型。 |
可选 |
| SQL |
用户指定 SQL 查询语句,用于导出自定义查询结果数据,仅导出模式有效。 |
可选 |
3 控制文件语法
[OPTIONS(
=
……
)]
LOAD [DATA]
INFILE < | >
[BADFILE ]
[APPEND|REPLACE|INSERT]
::=参数
::=值
::= [LIST] [] [,
[]]
::= DIRECTORY []
::=文件地址
::=STR [X]
::= {}
::=INTO TABLE [.]
[EP ]
[WHEN ]
[FIELDS [TERMINATED BY] [X] ]
[]
[]
::=模式名
::=表名
::=()
::=整型数字列表,以逗号分隔
::= { AND }
::= [(] [)]
::= | (p1:p2)
::= = | <> | !=
::= [X] '<字符串常量>' | BLANKS | WHITESPACE
::='<字符串常量>'
::=({ ,})
::= [FILLER][][][]
[][][]
::=列名
::= | NULL
::=position(p1:p2) | position(p1)
::=DATE FORMAT '<时间日期格式串>'
::= TERMINATED [BY]
::= WHITESPACE|[X]
::= [OPTIONALLY] ENCLOSE [BY] [X]
::= CONSTANT "<常量>"
::= "函数名称()" 4 dmfldr 简单实操
4.1 dmfldr导出数据
在控制文件中指定数据文件,编辑控制文件test.ctl信息:
#控制文件中导出TEST用户下TEST表,并保存/dmdbms/test.txt在文件中
LOAD DATA
INFILE '/dmdbms/test.txt'
INTO TABLE TEST.TEST
FIELDS '|'dmfldr载出数据:
$ dmfldr userid=SYSDBA/SYSDBA:5236 control='/dmdbms/test.ctl' mode='out'4.2 dmfldr导入数据
在目标端数据库创建相同的text表结构:
CREATE TABLE "TEST"."TEST"
(
"ID" INT IDENTITY(1, 1) NOT NULL,
"C1" VARCHAR(80),
"C2" VARCHAR(80),
"C3" VARCHAR(80),
"CREATE_TIME" TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP NOT NULL,
"UPDATE_TIME" TIMESTAMP(6) DEFAULT CURRENT_TIMESTAMP NOT NULL,
NOT CLUSTER PRIMARY KEY("ID")) STORAGE(ON "MAIN", CLUSTERBTR) ;将导出的txt文档传到目标数据库服务器,并导入目标表中:
LOAD DATA
INFILE '/dmdbms/test.txt'
INTO TABLE TEST.TEST
FIELDS '|'修改test.txt文件属主和属组:
chown dmdba:dinstall /dmdbms/test.txtdmfldr导入数据:
./dmfldr userid=SYSDBA/SYSDBA:5237 control=\'/dmdbms/test..ctl\' mode=\'in\'注意:mode默认是in,所以载入的时候,mode可以省略。
linux下单引号’是特殊符号,需要用\转移,否则报错。
更多内容,请访问达梦社区地址:https:eco.dameng.com