网络爬虫之Requests库详解(含多个案例)
网络爬虫是一种程序,它的主要目的是将互联网上的网页下载到本地并提取出相关数据。网络爬虫可以自动化的浏览网络中的信息,然后根据我们制定的规则下载和提取信息。
网络爬虫应用场景:搜索引擎、抓取商业数据、舆情分析、自动化任务。
HTTP基础
HTTP(Hyper Text Transfer Protocol,超文本传输协议)是互联网上应用最广泛的一种网络协议。所有的网络文件都必须遵守这个标准,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法,HTTP是一种基于"请求与响应"模式的、无状态的应用层协议。
HTTP协议采用URL(Uniform Resource Locator,统一资源定位器)作为定位网络资源的的标识符。URL由4部分组成:协议、主机、端口、路径。URL的一般语法格式为: protocol://hostname[:post]/[path]
- protocol:协议名,例如HTTP、HTTPS、FTP等
- hostname:合法的Internet主机域名或 ip地址
- port:端口号,默认为80
- path:请求资源的路径
例如:
https://ke.qq.com/course/package/29718
https://blog.csdn.net/Dream_Gao1989
可以简单的把HTTP请求理解为从客户端到服务器端的请求消息。无论是人在操作浏览器还是爬虫,当希望从服务器请求服务或信息时,就需要首先向服务器端发出一个请求,然后服务器返回响应,最后连接关闭,这就是Web服务的流程。

HTTP对资源的操作方法及说明

以上方法中,GET、HEAD是从服务器获取信息到本地,PUT、POST、PATCH、DELETE是从本地向服务器提交信息。
请求头:包含许多有关客户端环境和请求正文的有用信息。一般网站服务器最常见的反爬虫措施就是通过读取请求头部的用户代理(UserAgent)信息来判断这个请求是来自正常的浏览器还是爬虫程序。
常见的请求头及其含义

requests库详解
requests 库是用Python语言编写,用于访问网络资源的第三方库,它基于urllib,但比 urllib更加简单、方便和人性化。通过requests库可以帮助实现自动爬取HTML网页页面以及模拟人类访问服务器自动提交网络请求。
(1)安装requests库:pip install requests
(2)导入requests库:import requests
(3)构造一个向服务器请求资源的request对象,例如:requests.get(url)
(4)获取一个包含服务器资源的response对象,例如:res=requests.get(url)
(5)获取响应内容,例如:res.text、res.content 等
requests库的主要方法

通过查看源代码,可知get()、post()、head()、put()、patch()、delete()方法内部其实都是调用了request()方法,只是传递的method参数不同。
request(method, url,**kwargs):用于创建和发送一个Request请求。method参数用于指定创建Request请求的方法,有GET、POST、OPTIONS、PUT、HEAD、PATCH、DELETE等。url表示拟访问页面的网址,kwargs表示控制访问的可选参数,有params、data、json、headers、cookies、files、auth、timeout、allow_redirects、proxies、verify、stream、cert 等。该方法最终返回一个Response对象。
Kwargs可选参数
-
params:字典类型,作为参数增加到url中,例如get方法传递参数;
-
data : 字典、字节序列或文件对象,作为Request对象的内容;
-
json:JSON格式的数据,作为Request的内容;
-
headers:字典类型,HTTP定制头,例如设置User-Agent ;
-
cookies: 字典或CookieJar, Request中的cookie;
-
auth : 元组,支持HTTP认证功能;
-
files: 传输文件,字典类型,键为参数名,值为文件对象;
-
timeout: 设定超时时间,单位为秒;
-
proxies: 字典类型,设定访问代理服务器;
-
allow_redirects : 是否允许重定向,默认为True;
-
stream: 是否以字节流的形式获取内容并下载,下载文件时经常用到;
-
verify: 是否验证SSL证书,默认为True;
-
cert:本地SSL证书路径。
response对象的主要属性

对于encoding属性来说,如果header中不存在charset,则认为编码是ISO-8859-1,text属性根据encoding属性的编码方式显示网页内容,当编码方式不一致时,可能会出现乱码。apparent_encoding属性根据网页内容分析出的编码方式,可以看做是encoding属性的备选。
requests访问时可能的异常
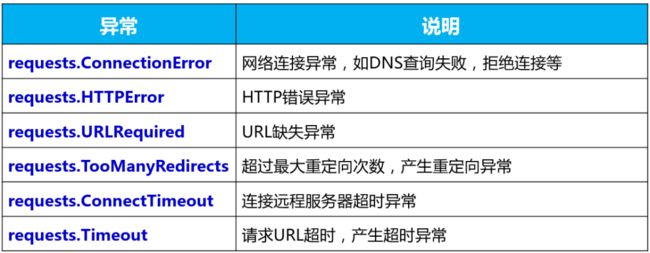
response对象中提供了一个raise_for_status()方法,该方法内部对状态码status_code进行判断,如果状态码不是200,将会抛出 HttpError异常。
代码实践
(1)使用requests访问网页的通用框架
def get_text_from_web(url):
"""获取网页内容,url表示网址"""
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)"} # 构建请求头
try: # 访问网络可能发生异常
res = requests.get(url, headers=headers, timeout=20) # 发送请求,响应时间为20秒
res.raise_for_status() # 如果状态码不是200则抛出异常
res.encoding = res.apparent_encoding # 设置编码格式,避免乱码
print(res.request.headers)
return res.text # 返回获取的内容
except Exception as e: # 捕获异常
print("产生异常", e)
print(get_text_from_web("https://baidu.com"))(2)使用requests下载图片
def download_img(target_url):
file_name = target_url.split(r"/")[-1] # 获取文件名
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'} # 构建请求头
try:
res = requests.get(target_url, headers=headers) # 发送请求
res.raise_for_status()
with open(file_name, mode="wb") as fp:
fp.write(res.content)
except Exception as e:
print("抛出异常,", e)
url = "https://www.shanghairanking.cn/_uni/logo/86350223.png"
download_img(url)(3)使用requests发送get请求传递参数
def get_schools(province_code, school_type, page="1"):
url = "https://kaoyan.cn/school/index"
params = {"province_code": province_code, "pro_school_type": school_type, "page": page}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'} # 构建请求头
try:
res = requests.get(url, params=params, headers=headers)
res.encoding = res.apparent_encoding
res.raise_for_status()
print(res.request.url) # 输出请求网址
return res.text
except Exception as e:
print("抛出异常,", e)
print(get_schools("11", "综合类", 2)) # 11 北京市, 2 表示第2页(4)使用requests发送post请求传递参数
def get_train_info(start, end):
url = "https://huoche.911cha.com/"
data = {"chufa": start, "daoda": end}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'} # 构建请求头
try:
res = requests.post(url, data=data, headers=headers) # 发送 post 请求
res.encoding = res.apparent_encoding
res.raise_for_status()
print(res.request.headers)
return res.text
except Exception as e:
print("抛出异常,", e)
print(get_train_info("南昌", "九江"))(5)使用requests下载视频并显示下载进度
def down_video(url, video_type="mp4"): # 下载视频,默认类型为mp4
file_name = str(time.time()) + "." + video_type # 保存的文件名
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)"}
r = requests.get(url, headers=headers, stream=True) # 发送请求
r.raise_for_status() # 验证状态
content_length = int(r.headers["content-length"]) # 获取视频文件大小
print("文件大小为:{} 字节".format(content_length))
buffer_size = 2048 # 缓存大小,即每次读取的字节数
size_downloaded = 0 # 记录下载内容大小
with open(file_name, "wb") as fp: # 将下载的数据保存到文件
for data in r.iter_content(buffer_size): # 迭代获取数据
fp.write(data) # 向文件中写入数据
size_downloaded += len(data) # 统计已下载数据大小
print("\r当前下载进度为:{:.2f} %".format(size_downloaded / content_length * 100), end="")
print("\r下载完成!")
except Exception as e:
print("抛出异常:", e) # 打印异常信息
target_url = "http://asset.greedyai.com/course/RGZNXLY/videos-ch1-Intro_ai_intro.mp4"
down_video(target_url)相关代码资源,可关注Python资源分享 微信公众号,回复 request 即可获取。
完整的课件下载地址:Python网络爬虫课件(含多个实例)-Python文档类资源-CSDN下载