Real-Time Rendering 4th 译文《二 图形管线》
第二章 图形管线
一条铁链的坚固程度取决于它最弱的一个环节
本章将介绍实时渲染的核心概念,渲染管线,或者被称为管线。管线最主要的功能就是根据一个虚拟的相机、3D的物件、光照等信息,渲染生成一个2D的图片。因此,渲染管线是实时渲染的基础工具。管线的整个过程如图2-1所示。图片中物件的位置和形状由它们的几何结构、环境的特性以及环境中的摄像机位置决定。物件的外表是由材质球、光照、纹理(应用于表面的图像)以及着色公式决定。
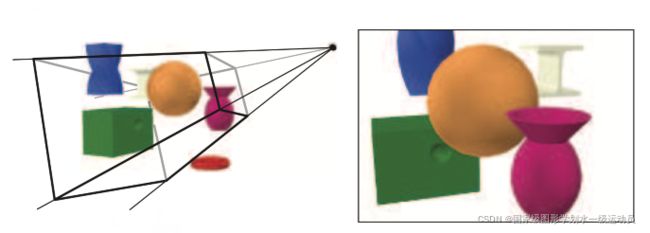
如上左图所示,虚拟相机位于金字塔的顶端(四条线在这里汇聚)。只有在视锥体内的图元会被渲染。对于以透视方式显示的图像(正如上图所示),视图体为锥形,即具有矩形底的截锥。上右图显示了摄像机看到的图片。注意上左图中红色圆环物件不在上右图的图片中,因为它位于视锥体之外。另外,上左图中蓝色物件也与视锥体的顶平面有交叉,所以被裁减。
下面,我们将介绍整个管线中的不同阶段,重点是功能而非具体实现。应用这些阶段的相关细节将在之后的章节中介绍。
2.1 渲染架构
在现实世界中,管线(流水线)被用于许多不同的场景,从工厂装配到快餐厨房。同样,它也适用于图形渲染。一个管线可以被分为若干阶段,每个部分都会执行一个大工程中的一部分。
渲染管线的各个阶段是并行执行的,每个阶段都依赖于前一阶段的结果。理想情况下,将一个非管线系统划分为n个管线阶段,可以加快n倍速度。性能的提高是使用管线的主要原因。比如:一组人可以很快准备好大量的三明治——一个准备面包,一个添加肉,一个添加配料。每个人将结果交给下一个人,然后就立即可以开始下一个三明治的制作了。如果每个人需要20秒完成他的工作,那么一分钟就可能完成3个三明治的制作了。管线的各个阶段并行执行,但是如果有一个阶段比较慢,其他阶段则会暂停等待。假设,准备肉的阶段最复杂,需要30秒,那么这个管线下一分钟最快可以生成2个三明治。针对这个管线,肉的阶段是瓶颈,因为它决定了整个生产的速度。配料阶段就需要等待肉阶段的完成(顾客也是如此)。

Figure 2.2 渲染管线的基本构造,包括四个阶段:应用阶段,几何化阶段,光栅化阶段,像素处理阶段。每一个阶段可能自己就是一个管线,如几何处理阶段的说明一样。或者也可能是多个管线并行的,就像像素处理阶段一样。在这个说法中,应用程序是一个单独的进程,但是这个阶段也能够扩展成为管线或者并行,注意,光栅化可以在基本对象中找到像素。
这种管线结构同样适用于实时渲染。如图2-2所示,实时渲染的管线大致被分为四个阶段:应用、几何处理、光珊化、像素处理。这个结构是用于实时渲染的渲染管线的核心,也是后续章节讨论的基础。这里的每个阶段本身也包含了若干个子阶段,比如下图中的几何处理。而像素处理阶段还可以部分平行化,应用程序阶段是一个单独的过程,但是这个阶段也可以是流水线并行,光珊化是在图元中(比如三角形)确认像素。在这里,我们把功能和具体实现区分开。一个功能阶段具有要执行的具体任务,但是并没有指定其在管线中执行任务的方式。一个具体的实现可以将两个功能阶段合成一个单元,也可以将一个复杂的功能阶段拆分成多个硬件单元去执行。
渲染速度可以通过每秒帧数(FPS)表示,即每秒渲染的图片数。也可以通过Hz表示,它只是表示1/s的符号,即更新频率。通常用ms来表示绘制一张图片的时长。然而绘制图片的时长通常会有所不同,这取决于每帧执行的计算复杂度。FPS可以用于表示特定帧的速率,或者一段时间内的平均性能。Hz用于硬件,比如设置为固定速率的显示器。
(译者心得:这里很重要)
顾名思义,应用阶段是由应用程序驱动,在CPU运行的软件中实现。这些CPU通常包括多个内核,这些内核能够并行处理多个执行线程。这使得CPU可以高效的运行应用程序阶段所负责的各种任务。一般CPU上执行的任务包括碰撞检测、全局加速算法、动画、物理模拟等,其它取决于应用程序类型的任务。下个阶段是几何处理,用于处理转换、投影以及其他类型的几何处理。这个阶段计算了渲染什么、如何渲染以及渲染在哪里。几何阶段通常在包含许多可编程核心和固定操作硬件的GPU上执行。光珊化阶段通常将三个顶点作为输入,组成一个三角形,然后找到其内部所有的像素,并将这些像素转发到下个阶段。最终,像素处理阶段逐像素的执行程序以确认其颜色,并执行深度测试确认它是否可见。还有可能去逐像素的执行比如blend等算法,将新计算的颜色与之前的颜色进行混合。光珊化和像素处理阶段也都在GPU中执行。所有的这些阶段以及其内部的管线都将在之后的四个部分介绍。关于GPU如何处理这些阶段的更多细节将在第三章介绍。
2.2 应用阶段
开发者可以完全控制应用阶段发生的事情,因为这个阶段基本都是在CPU上执行的。因此,开发者可以完全决定如何实现以及修改它来提高性能。这里的改动还会影响到之后阶段的性能。比如一个应用阶段的算法或者设置就可以减少渲染的三角形数量。
尽管这么说,一些应用阶段的工作也可以通过GPU中的特殊模块compute shader完成。这个模块将GPU当作一个高度并行的通用模块处理,而忽略其专门用于图形渲染的特殊功能。
将渲染所需要的几何数据传给几何处理阶段。都是一些可能会出现在屏幕上(或者正在使用的任何输出设备)的点、线、三角形等渲染图元。这是应用阶段最主要的任务。
这个阶段以软件为基础来实现结果是,它不分成几个子阶段。几何处理阶段,光栅化阶段和像素处理阶段也是如此,但是为了提高性能,这个阶段通常在多个处理器核心上并行执行。在CPU的设计中,这被称为超标量结构,可以在同一个阶段同时执行多个进程。第18.5节介绍了使用多处理器内核的各种方法。
碰撞检测基本都是在应用阶段完成。检测到两个物件的碰撞后,会生成反馈并将反馈发送给碰撞的物件,如同一个力反馈装置。应用阶段也处理其他输入来源(如键盘、鼠标、头戴式显示器等)的输入。根据这些输入,可以采取几种不同的操作。加速算法,比如特殊的剔除算法(第19章),以及管线其他部分无法实现的部分都在这里实现。
2.3几何处理
在GPU上的几何阶段:主要负责大部分三角形和每个顶点的处理。主要分为四个阶段,顶点着色,投影,裁剪,屏幕映射。(这里注意顺序)

Figure2.3 几何处理阶段按照功能分成了几个流水线。
2.4 顶点着色
顶点着色最主要有两个任务,计算每个顶点的位置以及计算程序员所希望得到的顶点数据,比如顶点法线、纹理坐标等。对每个顶点的位置、法线、灯光计算,然后逐顶点的保存计算出来的颜色信息,通过三角形三个顶点计算三角形中出颜色插值,所以,这个顶点处理单元被称为顶点着色器。然而随着现代GPU的发展,大部分着色计算都将逐像素进行,顶点着色器也就会根据开发者的意愿,可能不再包含着色算法了。顶点着色器也就成了一个专门设置与每个顶点关联的数据。比如,可以通过4.4和4.5节的内容实现顶点动画。
我们从如何计算顶点坐标开始说起,这里需要一系列的坐标系。从模型空间到屏幕空间,一个模型需要经历多个空间变换/坐标系变化。最初,一个模型位于其自身的模型坐标系,这个时候还没有开始被转换。每个模型都有自己的模型坐标转换矩阵,这样就可以被定位和转向。同一个模型可以有多个模型坐标系,这样的话,同一个模型就可以在同一个场景中复制多个副本,具有不同的位置、方向和大小,而无需复制多个基本几何图形。(理解为自己为原点的坐标系)
模型空间转换转换的是模型的顶点和法线。模型的坐标系被称为模型坐标系,而发生了模型空间转换后,该模型将位于世界坐标系/世界空间中。世界空间是独一无二的,也就是说当所有的模型根据自己的模型转换矩阵,完成模型到世界空间转换后,它们都将存在于同一个空间内。(理解为以地面一个点为原点的坐标系)
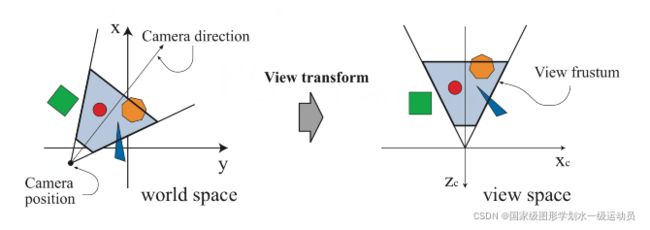
如前所述,只有相机/观察者能看到的物件才会被绘制。相机在世界空间有一个位置和方向,用于放置和瞄准相机。为了方便投影和裁剪,相机以及所有的物件都将被转换到视图空间。视图变换的目的是将摄像机放到原点并进行瞄准,使其向-z轴的方向进行观察,y轴向上,x轴向右。在这里,我们使用-z轴,而有的书使用+z轴,这些都不重要,它们之间的转换也很简单,最终的位置和方向都依赖底层API的实现。这样的空间被称为相机空间或者视图空间。图2-4展示了视图转换前后的相机和模型。模型转换和视图转换都可以通过4*4矩阵表示,这些将在第4章详细说明。最重要的是,需要意识到一个顶点的坐标和法线可以以程序员喜欢的任何方式计算。(理解为以相机为原点的坐标系)
下面,我们将介绍顶点着色的第二种类型的输出。因为如果想要展示一个真实的场景,只有物件的形状和位置是不够的,同时还需要构建它们的外观。这里包含了每个对象的材质,以及各种光照照射到对象上的效果。材质和灯光可以通过任何方式建模,从简单的颜色到详细的物理描述表达式。
决定灯光对材质球的影响的公式被称为着色。涉及到计算物体上不同顶点的着色方程。通常,其中一些计算是在模型顶点的几何处理过程中执行的,而其他一些计算是在逐像素处理过程中执行的。可以在每个顶点中存储各种材料数据,比如位置、法线、颜色等着色方程所需要的数值。顶点着色结果(比如颜色、法线、纹理坐标等其他类型的着色数据)随后被发送到光珊化和像素处理阶段,用于计算表面着色。
本书中还将继续深入介绍GPU顶点着色,尤其是第3和第5章。
然后,作为顶点着色的一部分,渲染系统还执行了投影和剪裁,将视图体转成了一个单位立方体,顶点位于(-1,-1,-1)和(1,1,1)。不同范围可以定义成一个相同的视图体,例如0<=z<=1,单位立方体也被称为规范视图体。首先通过GPU中的顶点着色器完成投影。完成投影有两种投影算法,正交投影(也叫做平行投影)和透视投影,如图2-5所示。实际上正交投影只是平行投影的一种,还有一些,比如建筑领域的斜投影和轴测投影,街机游戏zaxxon就是以后者命名的。

上左图为正交投影,上右图为透视投影
注意,投影是用矩阵来表示的,因此,它与几何转换有些关系
正交投影的视图体通常为一个矩形框,正交投影将其转成一个单元立方体。其主要特点就是变换后平行线要依然保持平行。这种变换是平移和缩放的组合。
透视投影就有点复杂了。在这种类型的投影中,对象离相机越远,投影后显示的对象越小。所以,平行线可能会在地平线处汇聚。透视投影变换模拟了我们感知物件大小的方式。几何上,视图体被称为截锥,也就是具有矩形底座的截锥。截锥也被转成了单位立方体。正交投影和透视投影都可以用4*4矩阵构造(第4章),并且在变换之后,模型都进入了裁剪空间/裁剪坐标系。这些实际上就是第4章所要说的齐次坐标系,然后进行除以w操作(w是(x,y,z,w)中的w,除以w使第四个数化为1)。GPU的顶点着色器必须输出这种类型的坐标,并将其传递给下一个功能阶段进行裁减,才能得到正确的结果。
尽管这些矩阵将一个空间转成到了另外一个空间,但是它们被称为投影是因为显示之后,z坐标将不会存储在生成的图像中,而是存在第2.5节提到的zbuffer(深度缓冲)中。这样,三维模型就被投影成了两维。
2.3.2 可选的顶点处理
每个管线都包含了上述所描述的那些步骤。但是除了这些步骤之外,GPU中还可以执行一些可选的操作,按顺序为:曲面细分、几何体着色、流输出。需要根据开发者的意愿以及硬件的能力(并非所有GPU都支持)去选择性的使用这些功能。它们之间相互独立,而且使用率不高。第3章会对这些逐一进行详细介绍
首先聊聊曲面细分。想象你有一个弹跳的球,如果用一组三角形表示,可能会遇到质量或者性能问题。如果面数少,那么在5米外看上去不错,但是靠近一看,特别是沿着轮廓看的话,不够精细的问题就会暴露出来。然而如果用更多的面数以提高质量,则当球远离摄像机,仅覆盖屏幕几个像素的时候,就会耗费大量的处理时间和内存。通过曲面细分,就可以生成适当数量的三角形。
上面我们讨论的是三角形,然而实际上,我们首先要先处理顶点。因为只有有了顶点,才能生成点、线、三角形或者其他物件,只有有了顶点,才可以描述曲面,比如球。曲面是由一组面片组成,然而每个面片都是由一组顶点组成。而曲面细分阶段也是由一系列的阶段组成:外壳着色、镶嵌单元、区域着色。将一组组的面片的顶点集转成更大的顶点集合,然后用于生成新的一组三角形。可以通过场景中的摄像机决定生成多少三角形:距离近的时候面片多,距离远的时候面片少。
然后我们聊下几何着色器。几何着色器比曲面细分着色出现的要早,所以在GPU中更加常见。和曲面细分类似,几何着色器可以接收各种类型的图元,然后生成新的顶点。这更加简单,因为创造的范围很有限,输出的图元类型也就很有限了。几何着色器最常用的地方是生成粒子。想象如果想模拟一场烟花爆炸,每个火球可以通过一个图元点,也就是一个顶点表示。几何着色可以将每个图元点转成一个面向观察者的方形(由两个三角形组成)覆盖多个像素,这样的话开发者就可以有更多空间会进行着色了。
最后我们来聊下流输出。这个阶段可以使我们将GPU当作几何处理引擎使用。也就是说,此刻我们可以选择将处理过的顶点输出到数组中进行下一步处理,而不是将处理过的定点按照管线发送给下一个阶段以供渲染到屏幕使用。这些数据可以由CPU或者GPU在之后的过程中使用。这个功能常被用于粒子模拟,比如我们的烟花实例。
这三个阶段的顺序为:曲面细分、几何着色器、流输出,不管我们使用哪个,每个都是可选择使用的。,如果我们接下来继续使用,就会获得一组齐次坐标的定点数据,这组数据将会从相机视角方向来检测是否可见。
2.3.3 裁剪
只有全部或者部分位于视锥体内的图元才会进入光珊化以及后面的阶段,然后会被渲染到屏幕上。完全在视锥体内的图元会被直接按照原样传递到下一个阶段。完全在视锥体外的图元不会被传递到下一个阶段,因为它们压根不会被绘制。只有部分位于视锥体内的图元才需要裁剪。比如:一根线的一个顶点在视锥体内,另外一个在视锥体外。那么在外面的顶点就会被线与视锥体交点的这个新的顶点所取代。投影矩阵的用处就是被转换后的图元会被裁剪到单位立方体上。在裁剪之前执行视图转换和投影转换的好处就是将裁剪问题一致化处理,将所有图元转换到单位立方体上然后再裁剪。
裁剪过程如图2-6所示。除了视锥体的六个裁剪平面之外,使用者还可以定义其他裁剪平面来裁剪物件。图19-1展示了这种可视化图像,这种方式被称为切片法。
图2.6 投影变换后,只需要将单位立方体内的基本体继续进行处理(对应于视锥体内的基本体),因此,立方体外部的元素将会被丢弃,而完全位于立方体内的元素将会被保留,与单位立方体相交的基本体将会根据单位地方体进行裁剪,从而生成新的定点,丢弃旧的定点。
裁剪这个步骤需要用到投影生成的4个值的齐次坐标来表示裁剪。透视空间的三角形无法进行线性插值,所以需要第4个坐标,以便在透视投影时正确插值和裁剪。最终,进行透视空间的分割后,将生成的三角形位置放置到三维归一化设备坐标中。如前所述,此视图体积的范围为(-1,-1,-1)到(1,1,1)。而几何阶段的最后一个步骤就是将这个空间下的坐标转换到屏幕空间坐标。
2.3.4 屏幕映射
只有裁剪过的视锥体内的图元会进入屏幕映射阶段,这个时候依然是三维坐标系空间中。图元的x和y坐标会被转成屏幕空间坐标,屏幕空间坐标和z坐标一起被称为窗口坐标。假设一个场景会被渲染到一个(x1,y1)到(x2,y2)的窗口中,其中x1 接下来,我们描述整数和浮点值与像素(和纹理坐标)的关系。给定一个水平像素数组并使用笛卡尔坐标系,最左边的像素的左边缘在浮点坐标中为0.0(OpenGL以及Dx10以及之后的版本都使用这个方案)。这个像素的中心为0.5。因此,像素范围[0,9]也就覆盖了[0,10)的范围。转换很简单, 其中d是分散的像素位置(整数),c是像素的值(浮点数)。 虽然所有的API表示像素值都是从左到右递增,但是从上到下递增或者递减在OpenGL和DirectX的定义不同。OpenGL符合笛卡尔坐标系,将左下角视为最小值,但是DirectX却视情况而定,有时会认为左上角为最小值。这个也不能说谁对谁错。但是如果是一个API移植到另一个API的时候,就必须考虑这个差异。 经历了转换和投影等这些几何处理后,每个顶点也都有了属于自己的属性,下一个阶段的工作任务就是找到所有渲染图元(比如三角形)内部的像素点。这个阶段被称为光珊化,共分为两个阶段:图元装配和三角形遍历。如图2-8所示。需要注意的是,这里也可以处理点和线,但是因为最常见的就是三角形,所以下面我们都用三角形来进行说明。光珊化,也被称为扫描转换,是将屏幕空间中的二维顶点(每个顶点也都包含一个z值信息以及其他顶点相关的着色信息)转换成屏幕中的像素点。光珊化也被认为是几何处理和像素处理的连接点,因为在此之前三角形是由三个顶点组成,然后被这个阶段遍历生成像素后,传给下面的像素处理阶段。 判断一个像素是否在三角形中取决于你如何设置GPU管线。比如,可以通过点采样来确定该像素是否在三角形内。最简单的办法就是对该像素的中心点进行点采样,看其是否在三角形内,如果在的话,就认为这个像素在三角形内。还可以通过针对每个像素多个采样点的超采样或者多采样抗锯齿技术(详见5.4.2节)。另外一种办法就是使用保守的光珊化,也就是如果该像素的至少一部分与三角形重叠,则判断该像素位于三角形内部。 这个阶段将会计算三角形的微分、边方程和误差。这些数据将用于三角形遍历(第2.4.2节),然后对几何阶段生成的各种着色数据进行插值。这个阶段的任务将通过硬件的固定管线完成。 在这里检查每个像素的中心点或者其他采样点是否被三角形覆盖,然后针对部分像素在三角形内部的像素生成片元。第5.4节会更详细的介绍采样方法。这个确定采样点或者像素是否在三角形内部的阶段被称为三角形遍历。每个三角形片元的属性(包括z值等集合处理阶段生成的着色数据)都会通过三角形的三个顶点插值数据生成(详见第5章)。图元中所有的像素或者采样都会被传入下一个像素处理阶段。 在这个时候,经过之前阶段的处理,所有三角形或者其他图元内部的像素都已经被发现了。像素处理阶段被分为像素着色和合并两个阶段,如图2-8所示。像素处理阶段是逐像素或者逐采样点的处理图元中的像素或者采样点。 在这里将执行逐像素的着色计算,将前面插值获得的着色数据作为输入。然后将一种或者多种颜色输出给下一个阶段。不同于使用专用硬件执行的三角形设置和三角形遍历,像素着色阶段使用的是可编程GPU内核。因此,开发者可以开发一套像素着色程序(在OpenGL中被称为片元着色器),再次进行所需的计算。在这里将包含大量的技术,最重要的就是纹理采样。第6章将对纹理采样进行详细介绍,简单的说,就是将一张或者多张图片,根据各种目的,粘合到该对象上。如图2-9所示就是一个简单的实例。图像可以是一维、二维、三维的,最常见的还是二维的。最简单的情况下,最终输出就是每个片元一个颜色值,然后该值会被传递到下一个子阶段。 每个像素的信息都存储在颜色缓冲区中,该缓冲区是一个矩形的颜色数组(每个颜色都有一个红、绿、蓝部分)。合并阶段的工作就是将像素着色器阶段生成的片元颜色和当前缓冲区存储的颜色相结合。这个阶段也被称为ROP,“即 raster operation (pipeline)/光栅操作”或“渲染输出单元 render output unit”。和着色阶段不同,执行此阶段的GPU子单元通常不完全可编程,但是,它通常高度可配置,因此可以实现多种效果。 这个阶段首先要判断像素的可见性。也就是说,当场景渲染完毕后,颜色缓冲区应该包含的是从相机角度可见的,场景中的图元的颜色信息。针对大部分甚至全部的图形硬件,这个工作是由z缓冲区或者深度缓冲区完成。z缓冲区的尺寸和形状和颜色缓冲区一致,每个像素存储的都是距离最近的图元的z值。也就是说,当一个图元被渲染到一个确定的像素的时候,先计算在那个像素上这个图元的z值,并将其和z缓冲区中同一像素的深度进行比较。如果新的z值小于z缓冲区上的z值的话,意味着该图元比之前该像素点上绘制的图元距离摄像机更近。然后,该z值和颜色值就会被拿去覆盖该像素点的颜色缓冲区和z缓冲区了。但是如果计算得到的z值大于z缓冲区上的z值,则该像素点的颜色缓冲区和z缓冲区则保持不变。z缓冲区的算法很简单,时间复杂度为O(N)(N为渲染的图元数量),且适用于所有能获得像素点z值的图元。且支持乱序渲染,这也是这个算法受欢迎的原因。然而,z缓冲区针对屏幕上的每一点都只能存储一个深度信息,所以不能将其用于半透明图元。半透明图元必须在渲染了所有不透明图元之后渲染,且按照从后到前的顺序,或者使用其他不依赖顺序算法(详见5.5节)。全透明渲染是z缓冲区的主要缺点之一。 我们已经提到了用于存储每个像素颜色的颜色缓冲区以及用于存储每个像素z值的z缓冲区。然而其实还有其他通道和缓冲区用于过滤和保存片元信息。比如alpha通道是与颜色缓冲区关联,保存每个像素的不透明度值(详见5.5节)。在老的API中,alpha通道还可以通过alpha 测试的功能选择性的丢弃像素。现在可以通过任何计算触发丢弃操作,alpha 测试是用于确保完全透明的片元不会影响到z缓冲区(详见6.6节)。 模板缓冲器是一个用于记录绘制图元位置的屏幕外缓冲区,一般每个像素会有8位。可以通过各种函数将图元渲染到模板缓冲区中,该缓冲区的内容也可以被用于控制往颜色缓冲区和z缓冲区的渲染。比如,假设将一个填充的圆形绘制到模板缓冲中,然后使用一个操作,可以使得只有该圆圈覆盖的范围内的图元,才能被绘制到颜色缓冲区中。模板缓冲可以被用于实现各种特殊的效果。这些在管线末端的功能被称为ROP(raster operations/光栅操作)或者混合操作。在这里,可以将当前颜色缓冲区中的颜色与当前三角形绘制的颜色进行混合。这样的话就可以实现半透明或者颜色累积等效果。如上所述,混合可以使用API配置,是部分可编程。然而,有些API支持光栅顺序可视化,也被称为像素着色器顺序,这样就可以实现可编程混合功能。 帧缓存是由系统中的所有缓存组成的。 当图元经过光栅化阶段后,相机视角所能看到的图元都会被显示到屏幕上。屏幕展示了颜色缓冲区中的内容。为了避免在光栅化的过程中就被人们看到,使用了双缓冲区机制。也就是说屏幕的渲染发生在屏幕外,在后缓冲中。当屏幕中的内容在后中被绘制完毕后,将后缓冲中的内容与之前在屏幕中展示的前缓冲中的内容进行交换。这个交换在垂直同步垂直扫描的时候进行,这个时候是做这个是安全的。 点、线、三角形是组成模型/物件的基本图元。想象一下该应用程序是一个(CAD)交互式计算机辅助设计应用程序,用户使用它来检查华夫饼制造机器的设计。我们使用这个例子来走完整个图形渲染流程,包含四个阶段:应用程序、几何处理、光栅化、像素处理。整个场景是通过透视的方式映射到屏幕上。在这个例子中,华夫饼机器包含线段(显示零件的边缘)和三角形(显示表面)。华夫饼机器有个可以打开的盖子。其中一些三角形上显示着制造商的2D图片logo。整个例子中,表面着色基本是由几何处理阶段完成,除了纹理采样是在光栅化阶段完成。 应用阶段 应用阶段该应用程序允许用户选择和移动模型的一部分。比如,用户可以选择盖子,然后通过移动鼠标来打开它。应用阶段就应该将鼠标移动转换为一个对应的旋转矩阵上,然后确保该矩阵在渲染时正确的应用于盖子上。另外一个例子:播放一个动画,使得相机沿着预定义的路径移动,从不同的视角观察华夫饼机器。然后,应用阶段必须根据时间更新摄像机的位置、方向等参数。每帧,应用阶段都应该将摄像机的位置、光照、模型的图元传递给管线中的下一个阶段:几何处理阶段。 应用阶段 几何处理阶段针对每个物件,应用阶段已经计算好了一个用于描述模型本身位置和方向的矩阵以及逐相机的视图转换矩阵和投影矩阵。在我们的例子中,华夫饼机器本身有一个矩阵,盖子还有一个矩阵。在几何处理阶段,模型的顶点和法线都将通过这个矩阵的计算,将物件转换到世界空间,然后再转换到视图空间中。然后将通过材质球和光源,针对顶点进行着色或者其他计算。然后通过用户提供的投影矩阵将物件转换到单位立方体空间用于展示眼睛所看到的内容。所有立方体之外的图元都将被抛弃。所有与立方体有交互的图元都将被裁剪,以得到一组完全位于立方体内部的图元。然后这些顶点将被映射到屏幕上。在执行了所有这些逐三角形和逐顶点的操作后,所有的数据都将被传递到光栅化阶段。 几何阶段 对于透视视角,我们假设应用程序阶段对每个物件提供了一个投影矩阵,这个矩阵用于描述模型的视图转换、位置和方向。在我们的例子中,华夫饼机器本身有一个矩阵,盖子也有一个矩阵。在几何处理阶段,模型的顶点和法线都将通过这个矩阵的计算,将物件转换到世界空间,然后再转换到视图空间中。然后将通过材质球和光源,针对顶点进行着色或者其他计算。然后通过用户提供的投影矩阵将物件转换到单位立方体空间用于展示我们眼睛所看到的内容。所有立方体之外的图元都将被抛弃。所有与立方体有交互的图元都将被裁剪,以得到一组完全位于立方体内部的图元。然后这些顶点将被映射到屏幕上。在执行了所有这些逐三角形和逐顶点的操作后,所有的数据都将被传递到光栅化阶段。 光栅化 经过上面的裁剪后,所有幸存的图元都将被进行光栅化,也就是图元中的所有像素都会被找出来,传递给管线中的下个流程进行像素处理。 像素处理 这一步的目的是计算出所有可见图元的所有可见像素的颜色。关联了纹理的三角形会在这里进行正确的采样。可见性是通过z缓冲区进行判断的,同步进行的还有可选的alpha 测试和模板测试。每个物件依次进行,然后就会在屏幕上看到最终的图片 总结 在过去的很多年中,开发者只能通过图形API提供的固定管线完成上述操作。之所以被称为固定管线,是因为当时的图形硬件是由一堆无法自由编程的组件组成。而最后一个主要使用固定管线的产品为2006年生成的任天堂的Wii。另一方面,可编程GPU使得我们可以精准的定义管线中每个子阶段的具体实现。由于这已经是本书的第4版了,所以我们假设所有的开发都是通过可编程管线完成。 更多资源
图2.7 在投影变换后,图元位于单位立方体中,屏幕映射过程负责在屏幕上查找坐标。 d = floor(c)
c = d+0.5。
2.4 光栅化

光栅化 像素处理
图形2.8 左边光栅化分为两个功能阶段,称为三角形设置和三角形遍历,右图,像素处理分为两个功能阶段,即像素着色和合并。2.4.1三角形设置
2.4.2 三角形遍历
2.5 像素处理
2.5.1 像素着色

图2.9 左上图为一个未经过纹理贴图的龙的模型,将右面的纹理贴图粘合到该模型上之后,就得到了左下图。2.5.2 合并
2.6 通过管线
当前这个管线是基于针对实时渲染数十年以来图形硬件和API发展来的。需要知道的是,这并非是唯一的渲染管线,离线渲染也经历了不一样的发展路线。针对电影产品的渲染之前是通过微多边形管线,而最近被光线追踪和路径追踪所取代。这些技术会在11.2.2进行介绍,这些可用于建筑和设计的视觉预览。
Blinn的《A Trip Down the Graphics Pepeline》是一本从头开始描述软件渲染器的老书。其中介绍了大量实现渲染管线微妙之处,并解释关键算法,比如裁剪和透视插值,是一本绝佳好书。OpenGL Programming Guide(也被称为红书)提供了相关的图形管线和算法的详细描述,这本书也很老,不过经常更新。本书的网站http://www.realtimerendering.com上也包含了大量的管线图片以及渲染引擎的具体实现等链接。