【C++初探:简单易懂的入门指南】三
【C++初探:简单易懂的入门指南】三
- 1.内联函数
-
- 1.1 宏定义
- 1.2 函数
- 1.3 内联
- 2. 指针空值(nullptr)

❤️博客主页: 小镇敲码人
欢迎关注:点赞 留言 收藏
任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。
❤️ 什么?你问我答案,少年你看,下一个十年又来了
1.内联函数
内联函数是将C语言宏定义和函数的优点都整合起来的一种函数。
1.1 宏定义
- 宏定义的优点
- 不用开栈帧,直接展开,节省了时间
- 宏定义的缺点
1.不能调试
1.2 函数
- 函数的优点
- 易于调试,方便我们找bug
- 函数的缺点
- 开了函数栈帧,时间上不具有优势。
1.3 内联
在函数的类型前加
inline关键字,这个函数就变成内联函数,至于是否会展开,要取决于编译器。
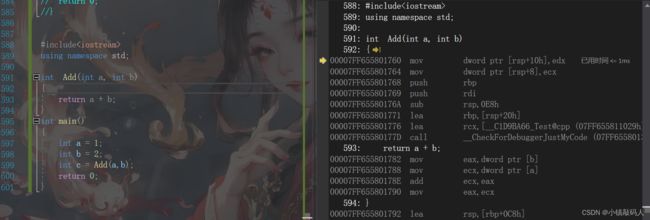
下面我们用Debug调试版本下的两段代码,来比较一下函数和内联:
#include函数汇编调试截图:
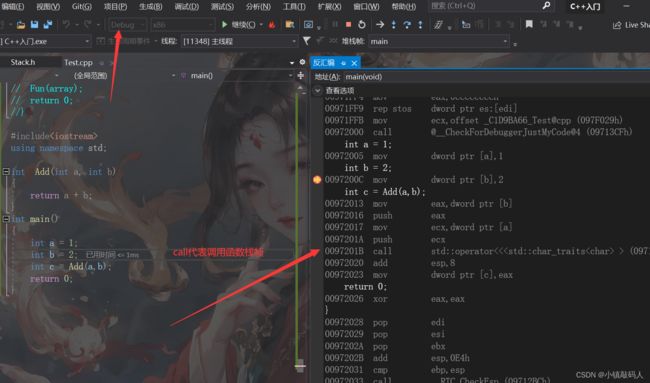
这里的call指令代表编译器调用了函数栈帧,继续执行光标就会执行到函数体里面。
内联:
#include内联汇编调试截图:
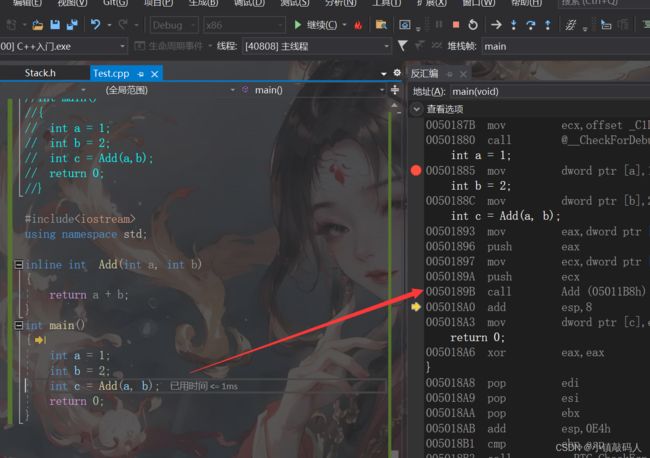
这里大家会有疑惑,为什么这里内联不直接展开,而是会调用函数栈帧呢,这是因为Debug调试版本下,编译器是默认关掉了内联函数直接展开的功能的,需要我们手动去打开,下面我来教大家如何在vs2019上打开这个功能:
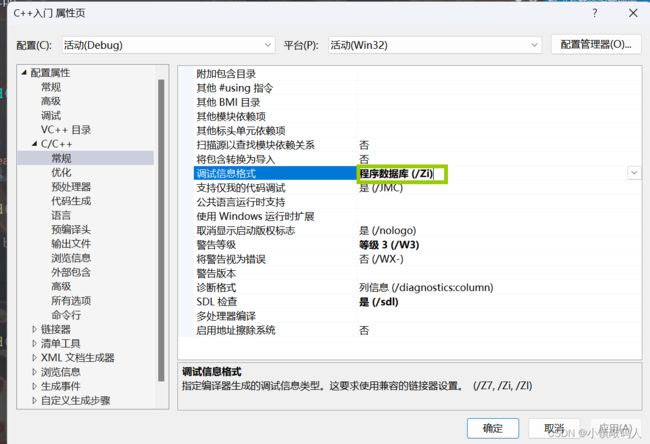
- 首先鼠标右键单击项目名称,点击属性。

- 点击C/C++常规,将调试信息格式改为->程序数据库。
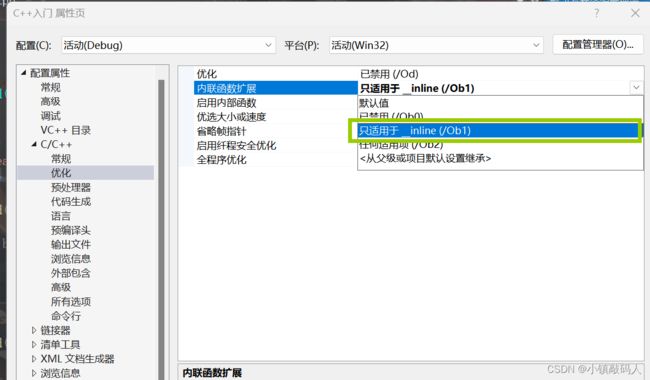
- 点击优化,将内联函数展开那项改为->只适用于_inline。
设置好之后我们再来看刚刚的内联函数的汇编代码:

此时神奇的事情发生了,内联函数和预期的一样没有调用函数栈帧,而是直接在那行代码下面展开了,那是不是不管我的函数代码有多大多长,只要打开了刚刚那个功能,Debug调试版本下的编译器都会直接展开呢,我们看看下面一个内联函数它的汇编调试结果如何吧:
#include汇编调试结果截图:

此时我们发现,由于这段内联函数太长,即使我们打开了内联展开的功能,编译器还是一意孤行,调用了函数栈帧。
这时我们得到结论:无论你是否打开了内联展开的功能,对于编译器来说都只是一个建议,因为内联函数本身就是一种空间换时间的做法,如果你的函数代码过长还展开的话,工程项目一大,调用的次数一多,就会导致可执行程序文件变得很大(后缀为.exe)。
为什么说是空间换时间呢?这是因为内联函数是在main函数里面直接展开,下次如果还调用这个函数还是会重复展开,如果是调用了100次,这个函数有10000行,那么总共就有10000*100行。但是如果是函数的话,调用函数栈帧,那份栈帧只需要一份就够了,它一直在栈区放着,就是(100+10000)行代码。源代码的行数增加会使可执行程序的大小增加,就像我们玩游戏里面的更新资源,如果是较大的函数也使用内联就会使这个资源包的内存变大,更新的就很慢,所以我们可以理解为什么有时候即使你打开了那个展开的功能,编译器也不会展开的原因了。
为什么使用函数调用栈帧会比内联直接展开要执行的慢呢,我们可以对比它们的汇编代码,相信你很快就可以得到答案。
这是函数的需要执行的汇编代码:
这是内联函数需要执行的汇编代码:

因为建立栈帧和传参需要一些工作,所以显然一次函数调用栈帧需要执行的代码会更多,用函数运行的时间会更长,如果你不相信,我们可以用下面代码来验证一下:
#include运行结果:
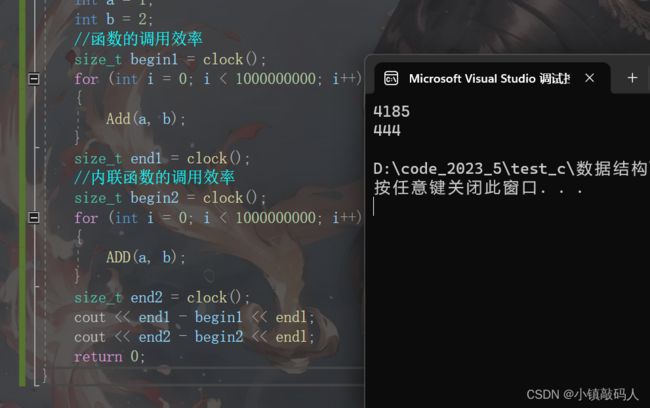
很显然,内联函数在展开时效率比函数开栈帧效率要高。
- 内联函数一般不支持声明和定义分离,因为内联函数在调用代码下直接展开,是不保存函数的地址的,下面一段代码希望可以帮助你的理解:
//stack.h
#include运行结果:

在链接的时候出问题了,编译器在符号表里面找不到Add函数的地址,这是因为内联函数直接展开,不会保存函数的地址,所以符号表里面找不到。
2. 指针空值(nullptr)
我们在学习C语言时,初始化指针经常会使用
NULL,C++引入nullptr是为了解决NULL带来的一些问题,具体请看下面的代码。
#include运行结果:
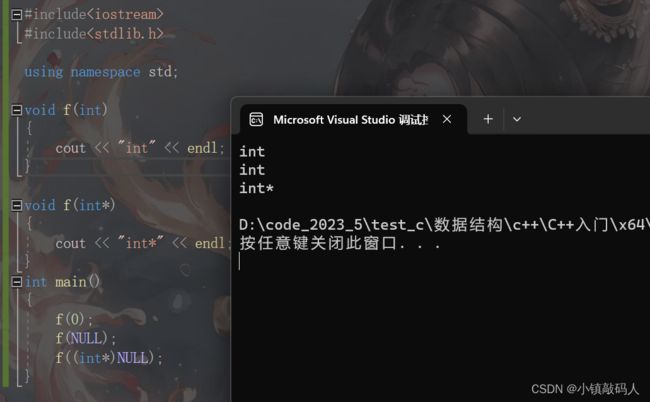
我们本意是想让f(NULL)去调用参数为int*的f函数,为什么会调用参数为int的f函数呢?我们可以进入传统的stdlib.h查看关于NULL的定义。

可以看到NULL实际上是一个宏,它可以看作0或者(void*)0,但是在C++98中字符0既可以是一个整形常量也可以是(void*)常量,这里编译器默认将其看为0,如果要将其看作指针,要进行强制转换。
但是如果是使用nullptr就不会出现这种问题,它是C++里面新引入的关键字,使用的时候不需要加头文件,为了代码的健壮性,一般指针赋初值都要赋为nullptr,sizeof(nullptr)和sizeof((void)*0)的大小相同(32位是4字节,64位是8字节)。
