高性能消息中间件 - Kafka3.x(三)
文章目录
-
- 高性能消息中间件 - Kafka3.x(三)
-
- Kafka Broker ⭐
-
- Kafka Broker概念
- Zookeeper(新版本可以不使用zk了)⭐
-
- Zookeeper的作用
- Kafka的选举1:Broker选举Leader⭐
- Broker核心参数⭐
- 案例:服役新节点和退役旧节点(重要)⭐
-
- 服役新节点⭐
- 退役旧节点⭐
- Kafka的副本⭐
-
- 副本的基本概念⭐
- Kafka的选举2:副本选举Leader⭐
- 手动调整分区副本⭐
- 分区自动再平衡机制
- 增加kafka的副本⭐
- Kafka的存储
-
- 基本概念
- 文件清理策略
- Kafka高效读取数据⭐
-
- 1:顺序写磁盘
- 2:页缓存与零拷贝
- Kafka消费者⭐
-
- Kafka消费者的消费模式
- 消费者组⭐
- Kafka的选举3:消费者组选举Leader⭐
- Java Api消费者的重要参数⭐
- Java Api操作消费者⭐
-
- 手动提交Offset⭐
- 生产调优5:消息积压⭐
高性能消息中间件 - Kafka3.x(三)
Kafka Broker ⭐
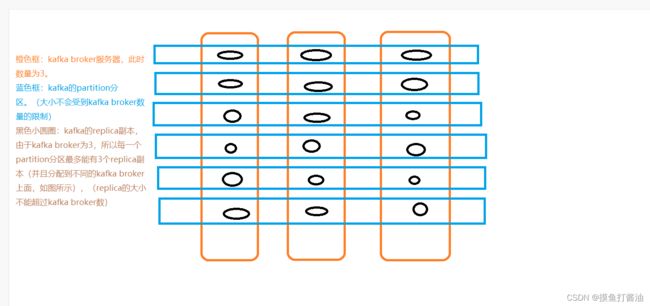
Kafka Broker概念
- kafka broker说白了就是kafka服务器。我们在生产环境下通常要搭建kafka broker集群。
- partition(分区)和replica(副本)的区别:
- 前提条件:假设我们的kafka集群数量(broker)为3。(也就是说我们集群只有3台kafka)。
- 此时Partition分区可以指定的数量是(无限制)的(也就是说可以指定10、100)。
- 但是replica副本数最多只能指定为3(3、2、1),否则就会报错。(因为我们的kafka broker数量就是3,replica不能超过这个值!!!!!)
- 前提条件:假设我们的kafka集群数量(broker)为3。(也就是说我们集群只有3台kafka)。
大致图如下:(partition和replica和kafka broker的关系图)
Zookeeper(新版本可以不使用zk了)⭐
Zookeeper的作用
- zookeeper的作用有:
- 1:保存kafka元数据。
- 2:保存broker注册信息。(有哪些broker可用)
- 3:记录每一个分区副本有哪些?并且每一个分区副本的leader是谁?
- 4:辅助选举leader。
- 5:保存主题、分区信息,等等。
Kafka的选举1:Broker选举Leader⭐
- broker选举leader规则:
- 每一个broker都有一个唯一的broker id,broker在启动后会去zookeeper的controller节点中竞争注册,哪个broker先注册,那这个broker就是leader。
Broker核心参数⭐
| 参数 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR,并移动到OSR。该时间阈值,默认 30s |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡(再平衡)。 |
| leader.imbalance.per.broker.percentage | **默认是 10%。**每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index文件里面记录一个索引 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
案例:服役新节点和退役旧节点(重要)⭐
服役新节点⭐
先只启动kafka01和kafka02机器,然后创建topic,副本数设置为2。然后再启动kafka03机器,然后让这个kafka03节点服役到集群中。
- 1:只启动kafka01和kafka02机器,并创建topic:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --partitions=3 --replication-factor=2 --create
- 2:查询mytopic001详情(发现副本只存在于kafka01和kafka02节点上):
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe
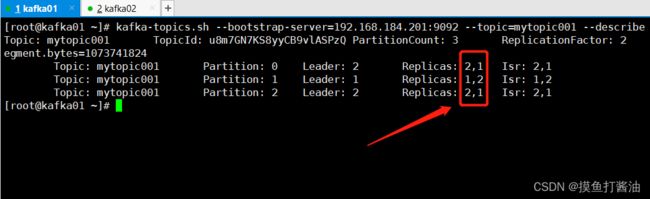
- 3:启动kafka03机器的zk和kafka,再次查询mytopic001详情(发现还是一样,副本只存在于kafka01和kafka02节点上,而不存在于kafka03节点上):
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe

- 4:开始服役新节点了!!
vim topics-to-move.json
内容如下:(topics下面的topic设置为想要服役的topic主题名称,其他不变)
{
"topics": [
{"topic": "mytopic001"}
],
"version": 1
}
- 5:生成新的负载均衡计划:(并复制下面如图所示的计划)
- –bootstrap-server:kafka集群地址
- –topics-to-move-json-file:刚刚创建的json文件名
- –broker-list:假如服役节点后的broker编号列表(3为kafka03的broker编号)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1,2,3" --generate

- 6:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(就是刚刚复制的新的负载均衡计划)
{"version":1,"partitions":[{"topic":"mytopic001","partition":0,"replicas":[3,2],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":1,"replicas":[1,3],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":2,"replicas":[2,1],"log_dirs":["any","any"]}]}
- 7:执行副本计划:(–reassignment-json-file负载均衡计划文件)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
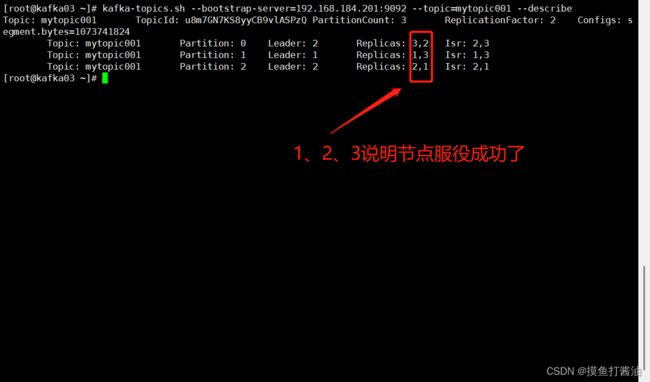
- 8:再次查看mytopic001详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe
退役旧节点⭐
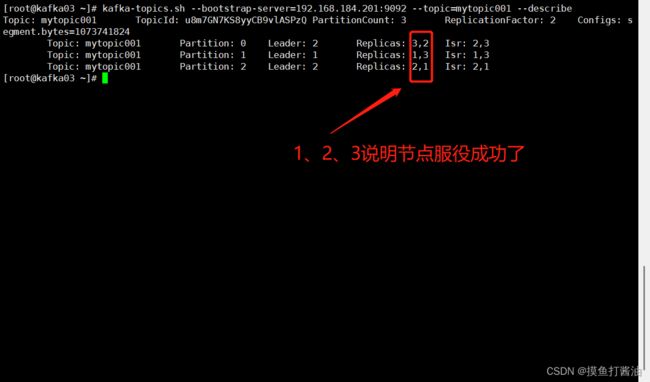
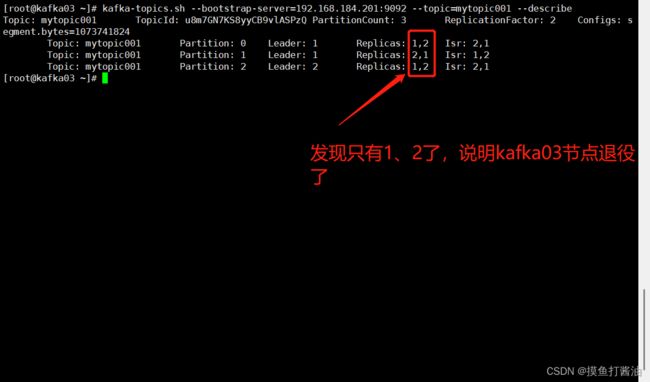
- 1:经过上面的服役新节点,我们可以看到副本被分配到1、2、3号机器上了。下面我们要把kafka03节点删去。
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe
- 2:开始退役节点了!!
vim topics-to-move.json
内容如下:(topics下面的topic设置为想要退役的topic主题名称,其他不变)
{
"topics": [
{"topic": "mytopic001"}
],
"version": 1
}
- 3:生成新的负载均衡计划:(并复制下面如图所示的计划)
- –bootstrap-server:kafka集群地址
- –topics-to-move-json-file:刚刚创建的json文件名
- –broker-list:假如服役节点后的broker编号列表(1、2代表着kafka03节点要退役了)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "1,2" --generate
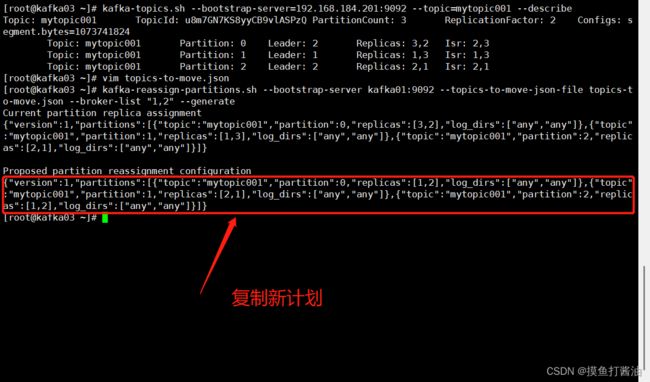
- 6:创建副本存储计划:
vim decr-replication-factor.json
内容如下:(就是刚刚复制的新的负载均衡计划)
{"version":1,"partitions":[{"topic":"mytopic001","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":1,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"mytopic001","partition":2,"replicas":[1,2],"log_dirs":["any","any"]}]}
- 7:执行副本计划:(–reassignment-json-file负载均衡计划文件)
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file decr-replication-factor.json --execute
- 8:再次查看mytopic001详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic001 --describe
Kafka的副本⭐
副本的基本概念⭐
-
replica(副本):为了防止集群中机器故障导致数据丢失,所以副本出现了。kafka的每一个topic在每一个分区都可以有多个replica副本,副本分为leader副本和follower副本。
- leader副本:生产者和消费者只于leader副本交互。每一个topic中的每一个分区都有一个leader副本。
- follower副本:负责实时从leader副本同步数据,当leader副本故障了,则会重新选举,使follower副本变成leader副本。
-
AR:分区中的所有 Replica 统称为 AR = ISR +OSR
-
ISR:所有与 Leader 副本保持一定程度同步的Replica(包括 Leader 副本在内)组成 ISR
-
OSR:与 Leader 副本同步滞后过多的 Replica 组成了 OSR
Kafka的选举2:副本选举Leader⭐
-
选举规则:以ISR队列存在为前提,选举AR队列中的第一个副本为leader副本。
-
如果leader副本故障下线,则也会以ISR队列存在为前提,选举AR队列第一个为leader(第一个不行则第二个,一直轮询直到选出leader)。
手动调整分区副本⭐
- 1:创建一个新的topic:(指定为3个分区1个副本)
kafka-topics.sh --bootstrap-server kafka01:9092 --create --partitions 3 --replication-factor 1 --topic mytopic002
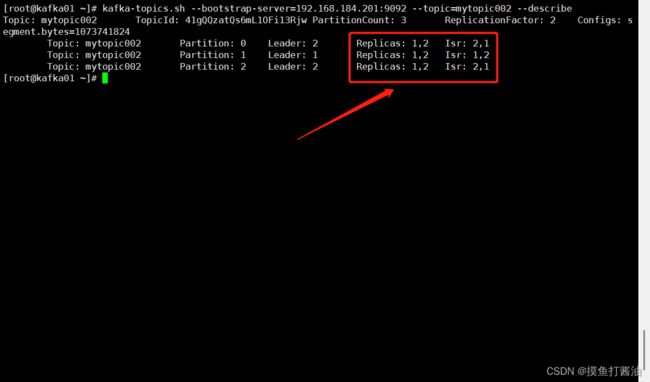
- 2:查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

- 3:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(修改topic和replicas)
{
"version":1,
"partitions":[
{"topic":"mytopic002","partition":0,"replicas":[1,2]},
{"topic":"mytopic002","partition":1,"replicas":[1,2]},
{"topic":"mytopic002","partition":2,"replicas":[1,2]}
]
}
- 4:执行副本存储计划:
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
- 5:再次查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe
分区自动再平衡机制
一般情况下,我们的分区都是平衡散落在broker的,随着一些broker故障,会慢慢出现leader集中在某台broker上的情况,造成集群负载不均衡,这时候就需要分区平衡。
- 为了解决上述问题kafka出现了自动平衡的机制。kafka提供了下面几个参数进行控制:
- auto.leader.rebalance.enable:自动leader parition平衡,默认是true;
- leader.imbalance.per.broker.percentage:每个broker允许的不平衡的leader的比率,默认是10%,如果超过这个值,控制器将会触发leader的平衡
- leader.imbalance.check.interval.seconds:检查leader负载是否平衡的时间间隔,默认是300秒
- 但是在生产环境中是不开启这个自动平衡,因为触发leader partition的自动平衡会损耗性能,或者可以将触发自动平和的参数leader.imbalance.per.broker.percentage的值调大点。
增加kafka的副本⭐
- 1:创建一个新的topic:(指定为3个分区1个副本)
kafka-topics.sh --bootstrap-server kafka01:9092 --create --partitions 3 --replication-factor 1 --topic mytopic002
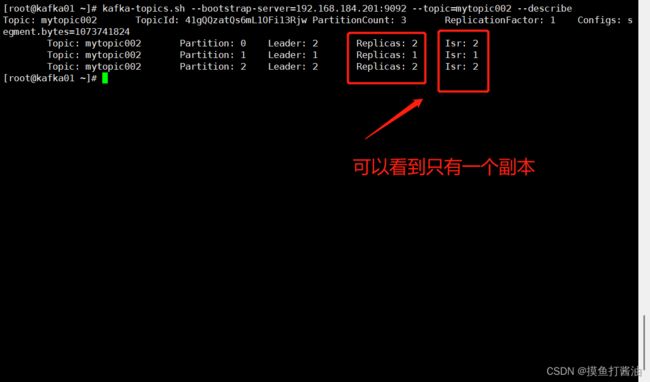
- 2:查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe
- 3:创建副本存储计划:
vim increase-replication-factor.json
内容如下:(修改topic和replicas)
{
"version":1,
"partitions":[
{"topic":"mytopic002","partition":0,"replicas":[1,2]},
{"topic":"mytopic002","partition":1,"replicas":[1,2]},
{"topic":"mytopic002","partition":2,"replicas":[1,2]}
]
}
- 4:执行副本存储计划:
kafka-reassign-partitions.sh --bootstrap-server kafka01:9092 --reassignment-json-file increase-replication-factor.json --execute
- 5:再次查看mytopic002详情:
kafka-topics.sh --bootstrap-server=192.168.184.201:9092 --topic=mytopic002 --describe

Kafka的存储
基本概念
-
每一个partition分区都对应着一个log文件。Producer生产的数据会被不断追加到该log文件末端
-
kafka为了提高效率,把每一个log文件拆分成多个segment(每个segment大小默认是1G),可以通过
log.segment.bytes去修改。 -
该文件命名规则为:topic名称+分区号
-
当log文件写入4kb大小数据(这里可以通过
log.index.interval.bytes设置),就会写入一条索引信息到index文件中,这样的index索引文件就是一个稀疏索引,它并不会每条日志都建立索引信息。
文件清理策略
-
日志清理策略有两个:
- 日志删除(delete) :按照一定的保留策略直接删除不符合条件的日志分段。
- 日志压缩(compact) :针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本。
- 可以通过修改broker端参数
log.cleanup.policy来进行配置
-
kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
- log.retention.hours:最低优先级小时,默认7天
- log.retention.minutes:分钟
- log.retention.ms:最高优先级毫秒
- log.retention.check.interval.ms:负责设置检查周期,默认5分钟
- file.delete.delay.ms:延迟执行删除时间
- log.retention.bytes:当设置为-1时表示运行保留日志最大值(相当于关闭);当设置为1G时,表示日志文件最大值
Kafka高效读取数据⭐
- kafka之所以读写性能高,是因为:
- 1:kafka是一个分布式的中间件,采用了多分区架构、以及消费者集群(消费者组),有利于抗住高并发、大流量场景。
- 2:kafka底层存储采用稀疏索引(每写入4kb数据才会加上1条索引),不仅能够节约索引占用的空间,也可以让我们快速定位数据。
- 3:顺序写磁盘
- 4:采用页缓存和零拷贝
1:顺序写磁盘
- kafka底层写入log日志数据采用的就是末尾追加的方式写入数据(这种就是顺序写磁盘),顺序写磁盘的效率比随机写磁盘的效率高了很多。
2:页缓存与零拷贝
-
kafka大量使用了页缓存(PageCache),分为以下两个场景:
- 1:读操作:当我们要读取数据的时候,首先会去页缓存里面找有没有该数据,如果有则返回,如果没有则会去磁盘中寻找,并把数据存到页缓存中。
- 2:写操作:首先会判断如果页缓存没有该条数据,则会把数据写入页缓存。如果有这条数据则修改这个页缓存数据,此时这个页缓存中的数据页就是脏页,操作系统会在特定时间把脏页写入磁盘,保证了数据一致性。
-
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。
- 当数据从磁盘经过DMA 拷贝到内核缓存(页缓存)后,为了减少CPU拷贝的性能损耗,操作系统会将该内核缓存与用户层进行共享,减少一次CPU copy过程,同时用户层的读写也会直接访问该共享存储,本身由用户层到Socket缓存的数据拷贝过程也变成了从内核到内核的CPU拷贝过程,更加的快速,这就是零拷贝。
Kafka消费者⭐
Kafka消费者的消费模式
- 1:poll(拉):消费者主动从kafka broker中拉取数据。(kafka默认采用)
- 2:push(推):kafka broker主动推送数据给消费者。
消费者组⭐
-
一个相同消费者组的消费者,它们的groupid是相同的。
-
一个分区只能由同一个消费者组的一个消费者所消费。
-
消费者组之间互不影响。
Kafka的选举3:消费者组选举Leader⭐
-
首先要选择出coordinator,如下:
- groupid的hashcode值%50(-consumer_offsets的分区数)。
- 比如groupid的hashcode值为2,则2%50=2,也就是说coordinator的2号分区在哪个kafka broker上就选择哪个节点的coordinator作为这个消费者组的boss,以后这个消费者组提交的所有offsets就往这个分区提交。
-
后面由coordinator负责选出消费组中的Leader
Java Api消费者的重要参数⭐
| 参数 | 描述 |
|---|---|
| bootstrap.servers | Kafka集群地址列表。 |
| key.deserializer 和value.deserialize | 反序列化类型。要写全类名 |
| group.id | 消费者组id。标记消费者所属的消费者组 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka提交的频率,默认 5s。 |
| auto.offset.reset | earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。 |
| max.poll.records | 一次 poll拉取数据返回消息的最大条数,默认是 500 条 |
Java Api操作消费者⭐
- 注意:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。例如:my-consumer-group 这个就可以运行
package com.kafka02.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;
public class MyConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
//1:基本配置
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.201:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//2:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。my-consumer-group
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"my-consumer-group");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 存放需要消费的topic名称
Set<String> topicSet=new HashSet<>();
topicSet.add("java-api-test");
// 订阅这个topic集合
kafkaConsumer.subscribe(topicSet);
System.out.println("等待拉取数据------");
//循环消费消息
while (true){
//kafka消费者的消费模式就是poll。指定1s拉取一次数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
//输出消息
consumerRecords.forEach(record -> {
System.out.println("--");
System.out.println(record);
});
}
}
}
手动提交Offset⭐
- 手动提交offset有两个方法:(二选一)
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。 阻塞线程,一直到提交到成功,会进行失败重试
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。没有失败重试机制,会提交失败
package com.kafka02.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;
public class MyConsumerCommit {
public static void main(String[] args) {
Properties properties = new Properties();
//1:基本配置
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.184.201:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//2:指定消费者组id。注意指定my-consumer-group01会出现无反应现象。最好别加数字。my-consumer-group
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"my-consumer-group");
//3:关闭自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
// 存放需要消费的topic名称
Set<String> topicSet=new HashSet<>();
topicSet.add("java-api-test");
// 订阅这个topic集合
kafkaConsumer.subscribe(topicSet);
System.out.println("等待拉取数据------");
//循环消费消息
while (true){
//kafka消费者的消费模式就是poll。指定1s拉取一次数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
//消费消息
consumerRecords.forEach(record -> {
System.out.println("--");
System.out.println(record);
});
//消费结束后手动提交offset
kafkaConsumer.commitSync(); //同步提交
}
}
}
生产调优5:消息积压⭐
-
解决方案1:可以增加partition分区数和增加消费者组中的消费者数量,使partition分区数=消费者组中的消费者数量。
-
解决方案2:提高每批次拉取消息的数量(
max.poll.records),默认是500条,可以提高到1000条。