论文阅读 - Detecting Social Bot on the Fly using Contrastive Learning

目录
摘要:
引言
3 问题定义
4 CBD
4.1 框架概述
4.2 Model Learning
4.2.1 通过 GCL 进行模型预训练
4.2.2 通过一致性损失进行模型微调
4.3 在线检测
5 实验
5.1 实验设置
5.2 性能比较
5.5 少量检测研究
6 结论
https://dl.acm.org/doi/pdf/10.1145/3583780.3615468
摘要:
社交机器人检测正在成为社会安全领域广泛关注的任务。一直以来,社交机器人检测技术的发展都因缺乏高质量的标注数据而受到阻碍。此外,人工智能生成内容(AIGC)技术的快速发展正在极大地提高社交机器人的创造力。例如,最近发布的ChatGPT[2]可以以74%的概率欺骗最先进的人工智能文本检测方法[3],这给基于内容的机器人检测方法带来了巨大的挑战。为了解决上述缺点,我们提出了一种对比学习驱动的社交机器人检测框架(CBD)。 CBD 的核心特点是两阶段模型学习策略:对比预训练阶段,从大量未标记的社交图中挖掘泛化模式,然后是半监督微调阶段,对潜藏在社交图中的特定任务知识进行建模,只需少量标注。上述策略赋予我们的模型在标记数据极度匮乏的情况下具有良好的检测性能。在系统架构方面,我们提出了智能反馈机制以进一步提高检测性能。对真实机器人检测数据集的综合实验表明,对于使用很少(5 个镜头)标记数据的少镜头机器人检测,CBD 始终大幅优于 10 个最先进的基线。 CBD已上线:robot-monitor
引言
大规模多媒体社交网络的普及使人们更多地参与日常生活。因此,人们不可避免地会受到社交网络的影响。与此同时,人工智能(AI)的快速发展在许多领域取得了惊人的成就,但也带来了挑战,例如恶意社交机器人。社交机器人是在社交媒体上自主通信的软件代理[43],而人工智能驱动的恶意机器人越来越多地在社交媒体上像人类一样思考、交谈和社交,这被用来从事破坏活动。在过去的十年中,恶意机器人被证明可以传播虚假信息和虚假新闻来影响公众情绪和股市[36, 37]。在COVID-19大流行期间,机器人被发现传播错误信息,例如质疑COVID-19的威胁、宣扬反疫苗阴谋论等,严重影响疫情防控[38, 49]。研究人员还发现,机器人被用来参与俄罗斯-乌克兰信息战[19]并干扰全国选举[44],即机器人被用来扰乱选举并攻击对手,例如2017年的法国大选总统选举[11]、2018年美国中期选举[47]等。马斯克斥资440亿美元收购Twitter的计划一度被终止,因为他质疑Twitter首席执行官声称的不到5%的虚假账户的准确性[40]。社交机器人带来的这些威胁严重危害社会安全。因此,迫切需要高效、有效的社交机器人检测方法来促进社会的和平与安全。
在社交机器人检测的早期阶段,常用的机器人检测方法是基于特征的,即根据用户属性[48]、推文特征[15]、行为特征[34]等从专家知识和统计信息构建特征。然而,基于特征的方法很容易受到基于对抗策略的特征的影响,即机器人创建者可以通过伪造特征来逃避检测[7]。由于社交机器人通常通过传播虚假信息来进行恶意活动,因此研究人员基于快速发展的自然语言处理(NLP)技术提出了基于内容的方法,利用内容挖掘技术来识别真实性和意图。例如,Kudugunta 等人[24] 使用长短期记忆(LSTM)处理推文并检测社交机器人。然而,大规模语言模型(LLM)的快速发展和应用使社交机器人具有更强的内容创造能力。例如,对于由 ChatGPT 生成的文本,只有 26% 的文本可以被识别[3],从而降低了基于内容的检测方法的性能。最近,由于图神经网络(GNN)在处理非欧几里得空间数据(如社交网络)方面的优越性,基于图的模型(如[ 9 ]、[ 4 ]等)被提出用于检测社交机器人,并有望解决复杂网络下的机器人群组攻击等问题。然而,近年来社交机器人的发展速度非常快[7],这导致高质量的标记数据非常稀缺。这使得传统监督模型(也包括基于 GNNs 的模型)无法满足训练需求成为一大挑战。换句话说,标签稀缺问题阻碍了bot检测的发展,使得有监督模型容易受到新社交bot的影响。
为了应对上述挑战,我们提出了一种对比学习驱动的社交bot检测框架(CBD),该框架由离线训练和在线检测两部分组成,支持少量学习。具体来说,它在预训练阶段采用图对比学习(只需使用未标记数据来学习包含语义信息的节点表征)来学习有价值的知识,并在微调阶段采用一致性损失来提高模型在标记数据极少的情况下的性能。
对于 CBD 的系统架构,我们提出了一种智能反馈策略,以进一步提高检测性能。因此,通过采用 CBD,只需要少量的标签数据(少量学习)就可以学习到足够的知识,并建立一个具有良好准确性的bot检测平台。而当遇到未知类型的bot时,我们的模型可以通过比较它们与已知类型社交账号的差异来增强效果,从而获得有效的检测结果。当然,预训练的特征提取器还可以与其他模型相结合,以提高其性能。我们将主要贡献总结如下:
我们提出了对比学习驱动的社交机器人检测框架--CBD,该框架支持少量学习,由两部分数据交互组成:离线训练和在线检测。
对于 CBD 的检测模型,我们在预训练阶段采用对比学习,从未标明的数据中提取有价值的知识;在微调阶段采用一致性损失,在标注数据极度缺乏的情况下提高检测性能。
在一个全面的社交bot检测数据集上进行的广泛实验证明了对比学习方法和一致性损失在社交bot检测中的有效性,以及 CBD 与最先进的基线模型相比的优越性。
3 问题定义
社交网络可以自然地表示为有向图 G = (V, E),其中 V = {v1, v2, ..., vN} 是社交网络中用户帐户组成的节点集,E ⊂ V × V 是描述用户之间关注关系的有向边集。节点的邻居集合表示为 ![]() 。令 X = [x1, x2, . , xN ]⊤∈RN ×d 表示节点特征矩阵,G的第i个节点的特征向量可以表示为
。令 X = [x1, x2, . , xN ]⊤∈RN ×d 表示节点特征矩阵,G的第i个节点的特征向量可以表示为![]() ,d表示特征维度。我们用 A∈R N×N 表示邻接矩阵,每个元素 A_ij = 1 表示节点 之间存在一条边,否则 A_ij = 0。D∈R N×N 是 A 的对角度矩阵,其中 D_ii =
,d表示特征维度。我们用 A∈R N×N 表示邻接矩阵,每个元素 A_ij = 1 表示节点 之间存在一条边,否则 A_ij = 0。D∈R N×N 是 A 的对角度矩阵,其中 D_ii = ![]()
在本文中,社交bot检测可被视为一项二元分类任务,其目标是预测给定的社交账号v_i∈ V 是否是社交bot。更正式地说,节点的标签向量表示为 Y∈{0, 1} ,其中 Y∈{0, 1} 表示基本事实。 这里,Y = 1 表示是社交bot,否则 Y = 0。因此,bot检测模型的工作是学习一个函数:(G,X)-→ Y。
4 CBD
4.1 框架概述
图 1 显示了 CBD 的架构,包括离线训练和在线检测。该框架通过离线训练和在线检测之间的持续数据交互,实现了实时bot检测和智能反馈。框架的工作流程介绍如下
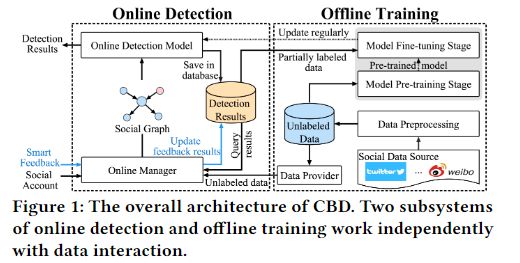
离线训练。这部分主要负责数据预处理和模型训练两大功能。数据预处理包括数据采集、整合和存储,数据源涵盖 Twitter、微博等几大社交网络。具体来说,它提供了数据采集工具、信息处理方法和数据持久化组件,所有这些组件都可以分布式部署。模型训练包括预训练和微调,可采用不同的训练策略.
在线检测。这部分提供对社交机器人的在线实时检测,并处理用户提交的反馈。具体来说,注册用户可以针对可疑的检测结果向系统提交反馈。如果反馈通过,则会在检测结果数据库中更新,从而为模型的微调提供基于反馈的注释数据。![]()
在线检测模型会定期从离线端更新,以确保模型学到的最新知识能及时应用到实时检测中。除了网页端检测,它还提供bot检测应用程序接口(API),开发人员可以利用这些应用程序接口为自己的应用程序提供bot检测功能。
4.2 Model Learning
模型学习在我们的框架中扮演着核心角色,其目的是从收集到的数据中挖掘潜在的模式来检测社交机器人。如图 1 右上方所示(深色背景突出显示),模型训练包括两个阶段(如图 2 所示):模型预训练和模型微调。前者是基于历史非标注数据的对比学习过程;后者则采用半监督式微调过程,利用基于标注数据的在线反馈注释信息。这种两阶段模型训练设计使我们的框架能够同时受益于大规模未标注数据和动态增量标注数据,从而使其具有良好的性能。下面我们将详细介绍这两个学习阶段。

4.2.1 通过 GCL 进行模型预训练
CBD 的预训练阶段遵循 GCL 的通用范式,即通过最大化来自同一输入图的两个不同视图之间的表征 MI 来实现自我监督。具体来说,两个图视图是通过对输入图随机执行数据增强而生成的。然后,优化对比目标,强制同一节点的增强表示相互一致,但与其他节点的表示不同 .
图增强 对于输入的社交图 G = (X,A),通过从 G 中删除边,生成两个视图 ![]() ,其中
,其中 ![]() 表示第m个视图的相邻矩阵。然后将两个视图输入 GNN 编码器,生成它们的表示。具体来说,对于
表示第m个视图的相邻矩阵。然后将两个视图输入 GNN 编码器,生成它们的表示。具体来说,对于 ![]() ,第l个 GNN 层的过程可以简化为
,第l个 GNN 层的过程可以简化为 ![]() ,其中表示 ReLU 激活;
,其中表示 ReLU 激活;![]()
![]() 是采用重正化技巧的卷积信号矩阵[22],
是采用重正化技巧的卷积信号矩阵[22], ![]() 是
是 ![]() 的对角度矩阵。
的对角度矩阵。![]() 代表
代表 ![]() 的第 l 层节点表示,特别是
的第 l 层节点表示,特别是 ![]() .通过迭代执行
.通过迭代执行 ![]() L次,我们获得编码表示:
L次,我们获得编码表示:
![]()
对比目标。通过两个视图表示法 H(1)和 H(2),对比目标用于区分同一节点的表示法和其他节点的表示法。具体来说,对于节点来说,它在两个视图 H(1)和 H(2)中的表示构成一对正样本,而其他节点在两个视图中的表示被视为负样本。那么正样本对的 InfoNCE 损失[29]计算公式为

其中,S (-, -) 表示两个代表之间的相似性, 是温度超参数。 Neg代表负对影响,其定义为
是温度超参数。 Neg代表负对影响,其定义为

其中,第一项和第二项分别惩罚视图内和视图间负对之间的相似性。由于两个视图是对称的,因此另一个视图的损失函数也类似。需要最小化的总体对比度目标定义为

4.2.2 通过一致性损失进行模型微调
在对未标记的社交图进行预训练后,根据在线检测和反馈结果(将在第 4.3 节中详细介绍),通过对社交图进行微调,进一步增强了预训练的 GNN 模型。为此,CBD 采用了半监督一致性学习策略,旨在通过增强模型对随机性的鲁棒性来学习更有把握的表征。如图 2 下部所示,给定一个带有部分注释的社交图 G = (X,A),通过将 G 送入预先训练好的模型并随机丢弃M次,生成 G 的M种不同表示 ![]() [39]。然后,M种不同的表征被发送到 MLP,以产生相应的输出:
[39]。然后,M种不同的表征被发送到 MLP,以产生相应的输出:![]() 。然后,我们对
。然后,我们对 ![]() 进行优化,对已注释节点 Ω_a 和未注释节点 Ω_u 分别采用监督损失和置信度感知一致性损失进行优化。
进行优化,对已注释节点 Ω_a 和未注释节点 Ω_u 分别采用监督损失和置信度感知一致性损失进行优化。
监督损失。监督损失被形式化为带注释的节点在M次表征上的平均交叉熵:![]() 其中 H (·,·) 表示交叉熵函数,Y ∈ R 是节点 的 one-hot ground-truth 标签。
其中 H (·,·) 表示交叉熵函数,Y ∈ R 是节点 的 one-hot ground-truth 标签。
置信感知一致性损失。为了以半监督的方式进一步利用未注释数据背后的信息模式,我们设计了一种置信感知一致性损失,它将表示的预测与锐化的平均预测对齐。具体来说,我们计算平均预测并使用以下公式对其进行锐化:![]()
![]() 其中,Normalize(-) 将非负矩阵的每一行归一化为合法分布,并代表锐化系数,即系数越小,分布越锐利。有了锐化后的平均预测值
其中,Normalize(-) 将非负矩阵的每一行归一化为合法分布,并代表锐化系数,即系数越小,分布越锐利。有了锐化后的平均预测值 ![]() ,置信度感知一致性损失会将所有预测值与置信度阈值
,置信度感知一致性损失会将所有预测值与置信度阈值 ∈ [0, 1] 以上的
∈ [0, 1] 以上的 ![]() 保持一致:
保持一致:

其中 D (-, -) 可以是任何距离度量,如 KL 散度和 L2 准则。指示函数 ![]() 会过滤掉所有置信度较低的
会过滤掉所有置信度较低的 ![]() ,以降低误差风险。
,以降低误差风险。
因此,结合 ![]() 会产生最终的微调损失:
会产生最终的微调损失:![]() ,其中
,其中 是权衡超参数。算法2总结了模型微调的过程。
是权衡超参数。算法2总结了模型微调的过程。

4.3 在线检测
在线检测模块提供实时社交僵尸检测和智能反馈两大功能,由在线管理器和在线检测模型两大部分管理。其工作流程和实现原理介绍如下
实时社交机器人检测。当用户在社交活动中遇到可疑账号时,可以在检测网页的文本框中输入该账号,然后提交检测。在线管理器收到并识别该账号检测请求后,首先从检测结果数据库中查询该账号的检测结果。如果找不到结果,它将重新向数据提供者查询账户数据,并向在线检测模型进行在线检测。具体来说,构建包含目标账户的社交图谱 G,并将其输入在线检测模型进行检测。在线检测模型利用社交图 G 检测目标账户及其邻居,并返回检测结果.
智能反馈。除了实时检测,在线模块还提供智能反馈,以进一步提高检测性能,图 1 中的蓝线就是智能反馈的标志。当注册用户对检测结果有疑问时,可以就某个账号是否为社交僵尸的概率提出反馈意见。然后,在线管理员会收到这些反馈,并由系统和人工进行审核。如果审核通过,反馈结果将被更新到检测结果数据库中。同时,反馈结果将用于离线微调,以便更新检测模型,获得更准确的结果。
5 实验
5.1 实验设置
数据集。我们的模型在 TwiBot-22 [ 10] 上进行了评估,在该数据集中,我们随机选取了 81,433 个人类作为正例,81,432 个机器人作为负例,以保持它们的比例相对平衡,从而得到了 162,865 个社交账号。我们随机将训练集、验证集和测试集按 7:2:1 的比例进行划分,以确保比较实验的公平性。
基线。为了构建 CBD 模型,我们选择了两个具有代表性的基于 GNNs 的模型 GCN [ 22] 和 GIN [ 45 ] 作为编码器,并在实验中将它们与十个基线模型进行比较。这些基线模型包括五个通用 GNN: GCN [ 22]、GAT [42]、JKNet (GCNJK) [46]、APPNP [23]、R-GCN [35];四种最新方法: LINKX[28]、MixHop[1 ]、GPR-GNN[6 ]、H2GCN[50];一种具有异质性的僵尸检测方法: Feng等人[ 9 ]。所有实验都使用了相同的输入特征,包括用户的 1) 用户属性:用户名、描述、位置、注册时间、验证状态、关注数、粉丝数、列表数、推文数;2) 内容信息:推文内容、评论;3) 社交关系信息:关注者和粉丝的好友列表;4) 社交关系信息:关注者和粉丝的好友列表;5) 社交关系信息:关注者和粉丝的好友列表;6) 社交关系信息:关注者和粉丝的好友列表;7) 社交关系信息:关注者和粉丝的好友列表。
实施细节。基于社交网络的交互特性,我们将社交数据构建为有向图。实验采用 AdamW 优化器 [ 21 ] 进行训练和优化。预训练阶段的学习率和权重衰减分别为 10-3 和 10-5。在微调阶段,我们采用权重衰减为 3 × 10-5 的分层学习率策略,其中预训练 GNN 层的学习率设置为 10-4,其他层的学习率设置为 10-3。为了避免过拟合,我们在训练时使用了 dropout [39] 和早期停止技术。
网格搜索用于找到 CBD 预测的最佳超参数。具体来说,该模型在三个编码通道上采用了两个隐藏层,隐藏层大小为 512.锐化参数、可信阈值和一致性损失的距离函数分别设为 0.3、0.6 和 L2 准则。其他基线方法的模型配置沿用了之前的研究[9, 28 , 35]。F1 分数、准确率和 ROC-AUC 用于评估我们的模型和基线模型。我们使用 PyTorch Geometric(MIT 许可)[12] 和 PyTorch(BSD 许可)[30]来实现实验,所有实验均在 Tesla A100 GPU(80GB 内存)上进行。
5.2 性能比较
在比较实验中,我们对每个实验进行 5 次随机权重初始化,并报告测试集上的平均值和标准偏差,其中 CBD 与 10 个基线模型进行了比较。实验结果如表 1 所示。从测试结果来看,我们的模型达到了最先进的僵尸检测性能,此外,使用 GIN 作为编码器的模型的性能优于使用 GCN 作为编码器的模型,达到了前 2 名的性能。

5.5 少量检测研究
对于新的社交机器人,只能获得很少的标签。有鉴于此,我们进一步探讨了 CBD 的少量检测能力。具体来说,我们只从训练集中随机抽取每个类别的标签来微调模型,然后在测试集中进行测试。表 3 显示了实验结果。不出所料,当取值减小到 1 时,即单次检测时,性能下降,方差增大。 然而,随着k增加,其性能呈上升趋势,并且可以超越所有每个类别只有五个标签的基线模型(五次检测),这归功于预训练阶段从未标记数据中学到的宝贵知识以及一致性损失进一步减少了依赖在微调阶段的标签上。

6 结论
本文研究了社交机器人检测任务,该任务面临着标签数据缺乏和 LLM 导致机器人内容创作能力不断增强的挑战。为了解决这些难题,我们提出了 CBD,它在预训练中采用对比学习,从无标签数据中提取有价值的知识;在微调中采用一致性损失,进一步减少对标签的依赖,从而在标签数据极度匮乏的情况下,在算法层面提高模型性能。此外,在系统架构层面,还采用了智能反馈策略来进一步提高检测性能。广泛的实验表明,在一个全面的僵尸检测基准上,CBD 始终优于最先进的基准模型。其他研究进一步证明了我们模型的有效性。到目前为止,我们已经在线部署了 CBD,并得到了广泛关注和使用。据我们所知,CBD 目前在谷歌和百度搜索中排名第一。我们希望我们的框架能帮助人们免受社交机器人及其传播的错误信息的影响,从而创建一个更安全的社交网络。