【实时渲染】RTR4 简要问答版
第二章 图形渲染管线
(1)渲染管线可分为哪4个阶段?
第一个是应用程序阶段,第二个是几何处理阶段,第三个是光栅化阶段,第四个是着色阶段(Pixel Processing)。
(2)渲染管线分为几个阶段,每个阶段主要是做什么?
渲染管线主要分为四个阶段,分别是应用程序阶段、几何处理阶段、光栅化阶段、着色阶段。在应用程序阶段,主要进行碰撞检测,动画,物理模拟。在几何处理阶段,主要决定哪些物体以哪些方式在哪里被绘制。在光栅化阶段,主要判断哪些像素在三个顶点形成的三角形内。在着色阶段,主要是对每个像素进行着色,并执行深度测试判断该片元是否可见。
(3)几何处理阶段主要做的事情?
主要分为四个部分,顶点处理,投影,裁剪,屏幕映射。
(4)几何处理阶段可以额外做的事情?
按顺序来说还有细分,几何着色器以及stream output。
(5)光栅化阶段主要做的事情?
光栅化阶段主要有两部分。第一部分是Triangle Setup,该部分作用是计算出下一部分操作所需要的数据,比如微分计算,edge function的计算等等。第二部分是Triangle Traversal,主要是确定哪个采样点或像素在三角形内。
(6)着色阶段(Piexl Processing)所要做的事情?
第一部分是像素着色阶段(Piexl Shading),主要是对每个像素进行光照计算等着色操作。第二部分是Merge阶段(merge 阶段), 将像素着色阶段计算出的颜色合并到颜色缓冲中,比如混合操作和z-test。
(7)双缓冲(double buffer)的作用?
渲染管染采用双缓冲来防止Merging阶段的Color buffer被用户看到,整个场景在一个离屏缓冲中进行绘制。当绘制结束后,前后缓冲在垂直扫描(vertical retrace)时交换角色。
PS:在交换双缓冲的时候,前缓冲需要保持被用户看到,后缓冲需要保持数据不变,所以在这段时间内系统不能访问缓冲。关于该问题的解决见图形硬件一章(23章)中关于三缓冲的介绍。
第三章 图形处理单元
(1)单指令单数据(SISD)与单指令多数据(SIMD)的区别?
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。
(2)GPU中的warp与thread?
单个顶点,像素或片元等元素的计算通过thread来完成,和CPU中的thread不同,GPU中的thread包含一些内存,用于存放输入数据和着色器执行所需的寄存器空间。多个使用同一着色器程序的thread成组执行后则被称为warp(NVIDIA叫法,在AMD中为wavefronts)。
(3)warp读取内存时执行的操作?
当一个warp需要内存读取时,warp中所有的thread都会停止,因为它们执行的是相同的指令。读取内存就意味着该warp拥塞,正在等待它的结果。这时系统会切换到另一个warp继续执行。因为两个warp之间没有数据交互,所以切换到另外一个warp中并不会消耗时间。
(4)影响SIMD执行效率的几个因素?
第一个因素是着色器程序结构,由于寄存器总量是有限的,那么一个着色程序的thread所需要的寄存器的数量越多,那么threads的数量越少,进而导致留在GPU中warp的数量也会越少。过少的warp意味着当发生拥塞时,GPU中可能不再存在空闲的warp,也就不能靠切换warp(switch)来减轻问题。
另外一个因素是动态分支,由于每个warp执行的指令都是相同的,如果该warp的所有thread执行相同的分支,那么warp就不需要考虑其他分支,如果有一个thread执行了不同分支,那么整个warp中所有其他thread都需要遍历这些分支。
(5)渲染管线各阶段的可编程程度?
渲染管线中可编程的部分为顶点着色器,细分,几何着色器与片元着色器(Piexl Shader)。细分和几何着色器为可选编程,并非所有GPU都支持这两部分,比如移动设备。
可以设定状态的部分为屏幕映射和merge,完全不可编程的部分为裁剪与光栅化。后续可以送到光栅化阶段,或者完全不进行后续的光栅化,而是将其作为一个非图形的stream processor。处理后的数据可以被再次送回到管线中,这种操作对流体模拟或其他粒子效果很有用。
(5)stream output阶段的作用?
在顶点处理阶段之后,可以选择将输出的顶点以有序数组的方式送到stream中。后续Stream output 阶段让GPU可以当做几何引擎使用,该阶段可以将数据出处到数组中,供CPU使用,也可以接着给GPU使用。这个阶段可以用来做物理模拟。
stream out返回的数据只是浮点形式,所以应注意一下它的内存消耗。由于stream out作用于三角形图元上,而非顶点,所以原始网格的拓扑关系都会消失。因此,我们送往渲染管线的数据都是点集。在OpenGL中,stream out阶段被称作transform feedback。输出的图元数据顺序和输入的顺序是保证相同的。
(6)如何避免数据的race condition?
数据的race condition就是多个着色程序都竞争地想去影响一些值,导致了结果的不确定。GPU通过某个着色器独有的原子单元来避免该问题,不过原子同样意味着另外一个着色器访问一个正在被修改的内存时发生了拥塞。
(7)简述ROVs(Rasterizer order views)?
ROVs在DX11.3引入,它指定了程序执行的顺序,不论片元着色器计算出结果的顺序是怎么样的,ROVs都会将结果按三角形输入顺序排序送到merge stage。这有利于半透明物体的渲染。ROVs和UAVs很像,不过ROVs指定了数据被访问的顺序。ROVs使开发者可以定义自己的blend 方法,因为ROVs的任何地方都是可以被访问和修改的,这样也不需要merge阶段了。ROVs的代价就是,如果遇到一个无序的访问,那么pixel shader可能会一直拥塞到当前顺序前的所有调用执行完成。
(8)early-z算法?
假如片元着色器(Piexl Shader)计算出fragment后发现这个fragment无法通过z-test,那么所有在片元着色器中的计算都是无效的。为了避免这种浪费,许多GPU会在片元着色器执行前进行提前深度测试。
第四章 变换
(1)如何在任意点p绕z轴旋转 ϕ \phi ϕ?
X = T ( p ) R z ( ϕ ) T ( − p ) X=T(p)R_z(\phi)T(-p) X=T(p)Rz(ϕ)T(−p)
首先移动到原点 T ( − p ) T(-p) T(−p),再旋转 ϕ \phi ϕ,最后移动回去即可 T ( p ) T(p) T(p)。
(2)图形系统中的常用变换顺序?
因为矩阵乘法运算不满足交换律,所以不同运算顺序对结果的作用也不同。在图形系统中常用的交换顺序为C=TRS。即TRSp=T(R(S§))。虽然矩阵乘法运算不满足交换律,但满足结合律,也就是TRSp=(TR)(Sp)。
(3)OpenGL中lookAt函数使用的矩阵推导?
M = [ r x r y r z 0 u x u y u z 0 v x v y v z 0 0 0 0 1 ] [ 1 0 0 − t x 0 1 0 − t y 0 0 1 − t z 0 0 0 1 ] = [ r x r y r z − t r u x u y u z − t u v x v y v z − t v 0 0 0 1 ] M=\begin{bmatrix} rx & ry &rz&0\\ ux & uy &uz&0\\vx & vy &vz &0\\0&0&0&1\end{bmatrix}\begin{bmatrix} 1 & 0 &0&-t_x\\ 0 & 1 &0&-t_y\\0 & 0 &1 &-t_z\\0&0&0&1\end{bmatrix}=\begin{bmatrix} rx & ry &rz&-tr\\ ux & uy &uz&-tu\\vx & vy &vz &-tv\\0&0&0&1\end{bmatrix} M=⎣⎢⎢⎡rxuxvx0ryuyvy0rzuzvz00001⎦⎥⎥⎤⎣⎢⎢⎡100001000010−tx−ty−tz1⎦⎥⎥⎤=⎣⎢⎢⎡rxuxvx0ryuyvy0rzuzvz0−tr−tu−tv1⎦⎥⎥⎤
为了从世界空间变换到相机空间,首先进行平移,将世界空间坐标变换到以相机为中心,之后进行基向量的变换,将 X = [ x , y , z ] X=[x,y,z] X=[x,y,z]变换到以r,u,v为基向量的坐标系中。
[ r x r y r z u x u y u z v x v y v z ] [ x y z ] = r X + u X + v X \begin{bmatrix} rx & ry &rz\\ ux & uy &uz\\vx & vy &vz \end{bmatrix}\begin{bmatrix} x\\ y\\z \end{bmatrix}=rX+uX+vX ⎣⎡rxuxvxryuyvyrzuzvz⎦⎤⎣⎡xyz⎦⎤=rX+uX+vX
(4)如何正确的变换normal?
原始的做法是使用变换矩阵的伴随矩阵的转置,又因为矩阵的逆等于伴随矩阵除以原矩阵的行列式,所以计算矩阵的逆的转置即可。当然,如果行列式为0便没有逆矩阵了。
计算伴随矩阵的消耗很大,并且这不是必要的步骤。因为normal是一个向量,所以平移对它是没有影响的,只需要计算变换矩阵左上角的3X3的伴随矩阵即可。
甚至这个伴随矩阵也不需要计算,因为transform可以分解为平移旋转缩放,平移对法线没有影响,均匀的缩放只影响法线的长度,所以只需要考虑旋转矩阵了。旋转矩阵是正交阵,其转置就是它的逆矩阵,所以它的逆矩阵的转置还是它本身。
综上所述,对于均匀缩放,只需要乘上原始的矩阵即可,最后通过归一化或者除上缩放比例就得到了正确的法线。对于没有缩放的变换,就不需要第二步。
对于非均匀缩放,则需要进行下面的操作
Normal = mat3(transpose(inverse(model))) * Normal;
(5)渲染管线中计算逆矩阵的几种技巧?
1.如果矩阵是一系列的简单变换组合成的,它的逆矩阵可以通过翻转参数得到,即 M = T ( t ) R ( ϕ ) M=T(t)R(\phi) M=T(t)R(ϕ), M − 1 = R ( − ϕ ) T ( − t ) M^{-1}=R(-\phi)T(-t) M−1=R(−ϕ)T(−t)
2.如果矩阵是正交阵,那么它的逆就等于它的转置。比如,一系列仅有旋转变换组成的矩阵还是正交阵。
3.如果上述方法都不行,可以采用的是克莱姆法则或伴随矩阵方法,因为它们涉及的if分支更少。
4.如果逆矩阵是为了变换向量,那么只需要左上3x3矩阵的逆矩阵即可,因为平移对向量没有影响。
(6)如何根据深度缓冲中的值还原出它在相机空间中的z值?
OpenGl中的透视矩阵如下所示

透视投影带来的结果就是深度值不再是线性的了,将该矩阵作用于相机空间中的p点,得到:

其中
![]()
![]()
再除以w后就得到下面的式子,在OpenGL中 Z N D C Z_{NDC} ZNDC属于 [ − 1 , 1 ] [-1,1] [−1,1]

以上推导给出了深度缓冲中的z值与相机空间中的z值的关系。
首先将深度缓冲从[0,1]变换到[-1,1],得到NDC空间中的值
z N D C = d e p t h × 2 − 1 z_{NDC}=depth\times2-1 zNDC=depth×2−1
再将 z N D C z_{NDC} zNDC的值带入上式
p z = 2 f n Z N D C ( f − n ) + ( f + n ) p_z=\frac{2fn}{Z_{NDC}(f-n)+(f+n)} pz=ZNDC(f−n)+(f+n)2fn
(7)骨骼蒙皮算法?
骨骼蒙皮算法主要分为三步,第一步是将模型空间中的某个顶点变换到关联的所有关节空间中,在此之后,顶点在关节空间的坐标保持不变。第二步是移动关节到当前姿势,第三步是将顶点变换到模型空间,并加权形成新的顶点。
整个流程的空间变换为模型空间->关节空间->模型空间。就类似于先将世界空间中的顶点变换到相机空间,在相机空间内进行变换,之后再回到世界空间,不同的是,骨骼蒙皮算法的一个顶点要绑定到多个关节。
在该算法中,每个顶点需要存储要绑定的关节索引,一般存储四个,因为超出四个之后效果提升就不是很大了。对于每个绑定的关节,同时存储一个权重因子,以表示该关节对最终顶点的影响。
第五章 着色基础
(1)走样产生的几种类型?
主要分为三种类型,第一种是几何走样,它是由于对几何图形的可见性函数采样不足导致。第二种是着色走样,它是由于着色阶段对连续的着色函数采样不足导致的。第三种是时间走样,它由于渲染帧率的限制使其对运动过程的采样不足导致的走样。比如车轮效应。可以采用动态模糊解决。
(2)各种基本的抗锯齿算法及其变种算法?
第一种是全屏反走样(SSAA||FSAA),它的变种算法为HRAA。第二种是多采样抗锯齿(MSAA),它的变种算法为英伟达的CSAA和AMD的EQAA。第三种是形态反走样,它的变种算法为SRAA、SMAA、FXAA。除此之外还有时间抗锯齿(TAA)等方法。
(3)超采样反走样(全屏反走样SSAA||FSAA)?
FSAA对场景以一个更高分辨率进行渲染,然后对相邻的采样点去平均值得到最终图像。对相邻点的采样有许多方式,英伟达的高分辨率反走样(HRAA)就是在FSAA的基础上采用五点采样模式得到的。该类算法解决了几何走样与着色走样。
(4)多采样抗锯齿(MSAA)?
MSAA的思想是将可见性测试分离出来,每个像素关联着多个子采样点,每个子采样点都存储着对应的深度值,模板值和颜色值。不过,对于颜色值,如果三角形覆盖了一个像素中的多个采样点,该像素只会进行一次着色计算,并将计算结果复制给每个被覆盖的采样点。
对于每个通过深度和模板测试的子采样点,其深度和模板值将被写入到缓冲区。而颜色值则为着色器计算出的结果乘以该像素点的覆盖率,覆盖率是由几何图形所占区域中所有可见的子采样点与总采样点之比。
(5)MSAA与FSAA对比?
相对于全屏反走样,MSAA在着色阶段进行的计算更少,因而性能更好。全屏反走样可以解决几何和着色走样,而MSAA只可解决几何走样。
(6)MSAA中的质心采样?
在MSAA中,像素着色器根据像素点中心的位置计算颜色值。如果一个三角形在某个像素内的子采样点没有覆盖像素中心,那么着色计算就会得出错误的结果。为了解决该问题,像素着色器使用的采样位置可以调整到覆盖区域中某个点的位置,这种技术就被称作质心采样。对于一个被几何图形覆盖的像素点,它首先从像素中心寻找,如果中心点没被几何图形覆盖,则向外延伸直到找到一个被覆盖的子采样点,以该点的位置作为着色计算时的位置。
(7)EQAA和CSAA相对于MSAA的改进思路?
MSAA将覆盖率与深度值放在一起,将颜色值计算分开。前面两种算法将覆盖率、深度值、颜色值都分开计算
(8)CSAA?
MSAA相对于FSAA减少了计算量,但是内存占用并没有减少,为了准确计算覆盖率,需要许多子采样点,每个子采样点都需要存储深度值和颜色值。
CSAA使用一个二进制结构的数组蒙版表示覆盖率,这个覆盖率比子采样点具有更高的分辨率。在光栅化阶段,光栅器首先投影几何图形到该蒙版以计算覆盖率,所有被覆盖的子采样点共用同一覆盖率。然后对子采样点计算深度,模板以及颜色值。
CSAA将覆盖率单独计算,从而可以使用更少的采样点得到更准确的覆盖率,并同时降低了内存占用。
(9)EQAA?
在MSAA中四个采样点都需要存储颜色值和深度值。EQAA的2f4x模式只存储两个颜色值和深度值来供四个采样点使用。深度值和颜色值不再存储附在四个采样点上而是用一个专门的表存储,原来的四个采样点则存储对应表的索引。如果一个像素覆盖超过三种颜色,则表中一项及其对应采样点索引会被删除。
(10)形态学反走样(MLAA)?
MLAA主要包含三步,
1.寻找给定图像中不连续的像素。
2.确定边缘类型。
3.对周围临近的像素按照混合权重进行混合计算求出轮廓上像素的颜色值。
边缘线段可以被分成LZU三种类型。一条直线可能是多个像素的边,对于起点和终点,它们所在的线段和这条直线是重合的,连接起点和终点所在线段的终点就得到了轮廓线。轮廓线经过的每个像素都被分成两个题型,根据这两个梯形的面积计算覆盖率,并确定最终颜色。
从本质上讲,MLAA以 图像处理的方式进行反走样,它并没有对几何走样或着色走样做出解决,而是近似抗锯齿后的图像,这种特性使得它可以与其他抗锯齿算法结合到渲染管线中。
(11)时间抗锯齿(TAA)?
TAA的思路是将采样点分布到多个帧中,可以解决几何走样和着色走样,这使得它几乎呈现和全屏反走样(FSAA)一样的效果。
为了获得多个采样点,在不同的帧中相同的像素应当使用一个抖动操作,以使当前帧的像素被移动到一个超采样中子采样的位置。抖动操作一般发生在顶点着色器中,通过直接修改投影矩阵,将原本正常的位于像素点中心的采样点修正到偏移位置。
Project[2][0]+=(SampleX*2.0-1.0)/ViewRect.Width();
Project[2][1]+=(SampleY*2.0-1.0)/ViewRect.Height();
最后对这些子采样点求加权平均值: s t = 1 n Σ k = 0 n − 1 x t − k s_t=\frac{1}{n}\Sigma_{k=0}^{n-1}x_{t-k} st=n1Σk=0n−1xt−k
这种方式虽然简单,然而它要求帧缓存存储n个时间帧的结果,内存消耗极大。
解决方法是直接使用当前渲染结果和之前所有帧混合的经过反走样处理的历史结果进行混合 s t = α x t + ( 1 − α ) s t − 1 s_t=\alpha x_t+(1-\alpha)s_{t-1} st=αxt+(1−α)st−1
α \alpha α决定着图像由走样到平滑过渡的快慢,较小的值收敛慢,但最终图像由更多采样点决定,图像质量高。较大的值则反之。
(12)TAA在动态场景中的三个主要问题?
TAA中的三个主要问题是重投影,重采样和重影。
(13)重投影方法?
重投影的主要目的是找到当前像素在上一帧颜色缓冲中的纹理坐标。为了得到该结果,需要两帧的MVP矩阵和两帧帧的抖动值。
首先计算出两帧在屏幕空间中的坐标:
p o s n o w = p × M V P n o w pos_{now}=p\times MVP_{now} posnow=p×MVPnow
p o s l a s t = p × M V P l a s t pos_{last}=p\times MVP_{last} poslast=p×MVPlast
再去除抖动偏移:
p o s n o w − = o f f s e t n o w pos_{now}-=offset_{now} posnow−=offsetnow
p o s l a s t − = o f f s e t l a s t pos_{last}-=offset_{last} poslast−=offsetlast
m o t i o n v e c = p o s l a s t − p o s n o w motion_{vec}=pos_{last}-pos_{now} motionvec=poslast−posnow
就得到当前像素在上一帧颜色缓冲中的纹理坐标
u v l a s t = u v + m o t i o n v e c uv_{last}=uv+motion_{vec} uvlast=uv+motionvec
(14)重采样问题的解决方法?
TAA的模糊来源于在每次迭代中,对历史颜色纹理采样使用了双线性纹理过滤器,这样历史颜色的采样值来源于该像素周围4个像素颜色值的加权和,而这些加权像素来源于更早历史像素周围的加权和,随着时间增加,参与加权的像素范围就越来越大。
重采样的方差表示如下:
σ v 2 = σ G 2 + 1 − α α v x ( 1 − v x ) + v y ( 1 − v y ) 2 \sigma^2_{v}=\sigma^2_{G}+\frac{1-\alpha}{\alpha}\frac{v_x(1-v_x)+v_y(1-v_y)}{2} σv2=σG2+α1−α2vx(1−vx)+vy(1−vy)
σ G 2 \sigma^2_{G} σG2是一个常数项,表示产生抖动的随机数方差,v表示像素中心距离每个子采样点的差值。
根据上式,有两种减缓模糊的方法
1.减小 σ G 2 \sigma^2_{G} σG2和v,即减少每个子采样点到像素中心点的距离v
2.增大 α \alpha α。UE4使用自适应的方法控制 α \alpha α,当周围像素对比度低时,非边缘,增加该值。对比度高时,是边缘,减小该值。
或者最后使用拉普拉斯算子进行锐化也可以。
(15)重影问题的解决方法?
当原来的可见区域变为不可见,历史可见颜色就会被混合进不可见区域形成重影。解决方法是邻域裁剪,该算法基于如下假设:图像中的颜色是连续的,历史颜色缓存中的颜色应该位于当前时间帧邻域像素颜色的范围内。
步骤如下:
1.对当前像素周围的若干像素,在颜色空间上(RGB空间或其他,UE4使用的是YCoCg)用一个2D多边形(三角形或其他凸包)包围住周围像素的颜色值。
2.如果查询到的历史颜色在该范围内,则认为该颜色合法。
3.否则,选择下面的方法之一进行处理
(1)直接丢弃,会带来视觉上的瑕疵
(2)寻找范围内与该像素最相近的颜色。
(16)全屏抗锯齿(FSAA)、多采样抗锯齿(MSAA)、形态抗锯齿(MLAA)和时间抗锯齿都解决了哪中走样类型,有哪些优缺点?
FSAA解决了几何走样和着色走样,缺点是计算量和内存消耗大。MSAA解决了几何走样,计算量更少,其变种算法CSAA和EQAA也可以降低内存消耗。形态抗锯齿(MLAA)以图像处理的方式近似抗锯齿后的图像,它的优点是可以很好的与其他抗锯齿算法结合。时间抗锯齿(TAA)解决了几何走样和着色走样。
(17)uniform,RGSS,Quincunx,flipquad四种采样模式对比?
uniform采样模式平均每个像素需要4个采样点。Quincunx采样模式平均每个像素需要2个采样点。由于人眼对接近垂直或水平的锯齿更加敏感,RGSS将uniform的采样模式旋转45度,使得四个采样点接近水平,该模式平均需要4个采样点。flipquad结合了RGSS和Quincunx的优点,每个像素只需要两个样本点,并且采样点接近水平和垂直。
(18)blend操作中的over操作和under操作?
1.over操作
c o = α s c s + ( 1 − α s ) c d c_o=\alpha_sc_s+(1-\alpha_s)c_d co=αscs+(1−αs)cd
c s c_s cs是半透明物体的颜色(source), α \alpha α是该物体的透明度。 c d c_d cd是混合前像素的颜色(destination), c o c_o co是最终结果的颜色。
2.under操作
c o = α d c d + ( 1 − α d ) α s c s c_o=\alpha_dc_d+(1-\alpha_d)\alpha_sc_s co=αdcd+(1−αd)αscs
a o = ( 1 − α d ) α s + α d = α s − α s α d + α d a_o=(1-\alpha_d)\alpha_s+\alpha_d=\alpha_s-\alpha_s\alpha_d+\alpha_d ao=(1−αd)αs+αd=αs−αsαd+αd
under操作需要源颜色和目标颜色都具有透明度,而over操作则不必。也就是说,under操作中的目标颜色是透明的。under操作中的源颜色和目标颜色是可以互换的,即顺序无关(order-independent)。
(19)depth peeling(深度剥离)算法?
该算法需要两个深度缓冲
第一步:渲染场景中所有物体的深度到第一个深度缓冲中,包括透明物体。
第二步:
对于每个Pass渲染所有透明物体:
1.对于第0层,第一个深度缓冲禁止深度测试,第二个深度缓冲清空后写入最近的深度,通过第二个深度缓冲的颜色即为第0层的结果。
2.对于第1层,交换上一步得到的两个缓冲,只有那些比上一步得到的深度缓冲的值远且在最近的片元通过深度测试,并写入到层1中,该层的深度值同样写入到第2个深度缓冲,交换缓冲并重复上述过程。
可以理解为如果该片元不属于第0层,并且深度最近,那么该片元属于第1层。以此类推。
(20)depth peeling的两个变种算法?
第一个变种算法是back-to-front方法,该方法从远向近剥离深度层,它的优点之一是可以立即进行混合,而原始算法则需要全部剥离完成后再混合。不过back-to-front方法需要一个额外的Pixel Draw Counter来表明一个像素被绘制了多少次,当该值降到0时则停止剥离。
第二个变种算法:Peeling depth每个层都需要绘制所有透明物体,效率较低,改进的算法是,每次剥离两层,最前面的和最后面的。缺点是需要一定的内存保证各层的顺序存储。
(21)k-buffer算法?
另外一个透明渲染的方法就是对每个Piexl维持一个fragment链表,每个fragment按从前到后的顺序排列,最终将所有颜色混合在一起,这种方法的缺陷是一个像素对应的fragment链表在某些特定情况下可能非常大(比如一个充满烟的场景)。
解决方法就是采用k-buffer,其思想是,只有前面k层按顺序存储,后面的层则使用加权和直接混合。混合公式如下:
c o = Σ i = 1 n ( α i c i ) + c d ( 1 − Σ i = 1 n α i ) c_o=\Sigma_{i=1}^n(\alpha_ic_i)+c_d(1-\Sigma_{i=1}^n\alpha_i) co=Σi=1n(αici)+cd(1−Σi=1nαi)
其中,n是透明物体数量, c i c_i ci和 α i \alpha_i αi是不透明物体的参数, c d c_d cd是透明物体的参数。
weighted-sum的缺点是可能导致生成的颜色值大于1而产生错误效果,解决方法是改用下面的方程:

k-buffer算法之后还有很多细小的改进,比如考虑距离对权重的影响,这里不再叙述。
第六章 纹理管线
(1)Minification(缩小)问题?
Minification问题是由于屏幕空间中的一个像素对应多个纹理空间中的纹素而造成。该问题可以通过双线性插值或最近邻插值解决,对于双线性插值,如果一个像素对应超过四个纹素,则产生锯齿。
(2)如何确定采样Mipmap中哪个层级?
该问题的核心是找出纹理空间中多少个纹素影响到屏幕空间中的一个像素。对于屏幕空间中的一个正方形像素,可以通过变换得到该正方形对应纹理空间中的矩形。
第一种方法是以纹理空间中对应矩形较长的边作为Mipmap的d轴。
第二种方法是计算纹理空间中的uv对屏幕空间中xy的导数,比如u对x的偏导就是屏幕空间中x方向的一个像素单位对应纹理空间中多少u值的变化。计算出四个偏导之后带入到公式中即可计算出d(见笔记版)。
(3)Mipmap中的SAT算法(summed-area table)?
上面两种方法的缺点是如果一个像素对应纹理空间中u方向上的范围很大,对于v方向则很小,那么就会选择层级更高的mipmap,使得图像模糊。
SAT可以解决该问题,首先创建一个和纹理大小相同的数组,数组中每个值存储从该点坐标到(0,0)的面积,假设现在已经建立起了屏幕空间中一个正方形像素和纹理空间中矩形范围的对应关系。纹理查找时,在纹理空间用一个轴对齐矩形包围住Pixel Cell对应的矩形纹素范围。
之后用包围体的四个点到原点的面积计算出c,以此选择mipmap层级。
(4)各向异性滤波方法选择Mipmap层级?
纹理空间中对应四边形较短的边用来决定Mipmap的层级,较长的边决定采样线,根据长宽比确定采样多少点,比如四边形长宽比1:2就是在采样线上采样2个点,然后将采样到的点反向投影到像屏幕空间。也就说一个像素的纹理采样由多个采样点决定。
(5)Cube Map采样过程?
Cube Map通过一个三维向量对立方体纹理进行采样。采样时,根据采样向量绝对值最大的维度确定采样面,剩下的两个维度除以该绝对值,并变换到[0,1]的范围。
对于(-3.2,5.1,-8.4),以绝对值最大的维度作为采样面,这里是-z面,剩下的两个维度除以abs(-8.4),得到 ( ( − 3.2 / 8.4 + 1 ) / 2 , ( ( 5.1 / 8.4 + 1 ) / 2 ) ((-3.2/8.4+1)/2,((5.1/8.4+1)/2) ((−3.2/8.4+1)/2,((5.1/8.4+1)/2),约为(0.31,0.8)用该坐标对相应纹理进行采样。
(6)减少纹理状态切换的几种方法?
第一种方法是使用atlas,即几张小的图片组成一张大的图片。该方法有两个缺点,第一个是在超出给定范围采样时,无法正常进行截断、镜像、重复等操作。第二个是生成Mipmap时各个小图片边缘会相互影响。
第二种犯法是使用texture arrays,数组中每个纹理需要具有相同大小格式Mipmap层级。
第三种方法是使用bindlesss Texture,普通纹理的缺点是纹理单元的总量是有上限的,bindless Texture则没有,因为每一个texture都对应着一个64位的指针,该指针可以通过多种方式访问,比如 uniform data,varying data。普通纹理是由驱动保证纹理还在GPU中,bindlesss Texture由应用程序来确定。bindlesss Texture可以减少驱动在绑定上的消耗,从而使渲染更加迅速。
(7)BC1压缩算法?
BC1算法每4X4个进行压缩,需要存储两步分的内容,第一部分是两个基准颜色,每个颜色占16位,格式为R5G6B5,两个共32位。第二部分是插值因子的索引,总共有四种插值模式,故需要两位,16个像素共32位。两部分合起来需要64位,即8B。
(8)BC2-BC5压缩算法?
BC2增加了alpha通道,alpha值采用4位存储,16个像素共64位。其他部分和BC1相同,总共需要128位,即16B。
BC3每个颜色占24位,R5G6B5A8,两个共48位。第二部分中颜色通道插值索引和BC1相同,需要32位,alpha通道为3条插值线8个索引,需要3位存储,16个像素需要48位。总共需要128位,即16B。
BC4和BC5只存储一个或两个通道,其余和BC1相同。
(9)BC6H和BC7压缩算法?
BC1-BC5压缩算法的缺点是,第一,精度不够,每个基准颜色只用16位存储。第二,4x4的quad只有4种颜色可选。第三,所有的颜色都在同一条插值线上,如果原来颜色空间不在一条线上,那么压缩效果很差。
BC6H和BC7通过两种措施解决上述问题,第一个是用更多位数存储基准颜色,第二个是.对4x4的quad划分成多种集合,用划分集ID表示集合类型。
BC6H用于HDR格式,BC7用于LDR。
(10)ETC1压缩算法?
4x4个像素分成两个2x4quad,水平或垂直分裂,用1位表示。每个quad有一个基准颜色,有两种基准颜色存储方式,用1位表示。第一种基准颜色存储方式是R4G4B4,两个共24位。第二种方式是其中一个颜色用R5G5B5存储,另一个基准颜色存储与第一个准颜色的差值R3G3B3,同样共24位。然后用3位存储8种索引集,16个像素每个像素需要2位存储索引。总共64位。
(11)两个透明物体相互交叉如何渲染?
知乎上可以理解的有两个答案第一个是OIT,用depth peeling,第二个是从后向前绘制,如果前面和后面相交,则把前面相交的部分裁掉。
RTR4中说的是用discard操作,也就是当alpha值小于某个阈值时直接丢弃。不过还没弄清楚这个方法是怎么真正实现的。
(12)在生成Mipmap的时候alpha值要如何处理?
如果单纯的通过取平均计算下一级的alpha值会带来错误,比如假设现在有四个像素的alpha值为(0,1,1,0),如果简单的对它们取平均,下一级的alpha值为(0.5,0.5),假定alpha testing规定大于0.75的通过测试,那么第0层有一般的通过,第1层则没有通过的。
方法一(rescaled alpha value):
方法一是使两层的覆盖率尽量相同,也就是如果第0层有一般通过,那么第1层也尽量有一般通过。为此,我们需要对第其他层的alpha值进行缩放,是它们通过阈值的比例尽量相等。
首先计算出第0层的通过率,也就是通过测试的数量除以总数量。我们想要的是寻找一个缩放因子s,使得两层的通过率相等 c 0 = c k = 1 n k Σ i ( s × α ( k , i ) > α t ) c_0=c_k=\frac{1}{n_k}\Sigma_i(s\times\alpha(k,i)>\alpha_t) c0=ck=nk1Σi(s×α(k,i)>αt)。
但是该缩放因子没有解析解,并且没有上界。解决方法是将上式的s移到右边,得到新的阈值 α k \alpha_k αk,它一定在[0,1]范围内,采用二分法可以找到近似解。之后用原阈值除以新阈值就得到了缩放系数s。
方法二:
将丢弃准则改为随机丢弃
if(texture.a<random())discard;
比如,上面例子中,第0层(0,1,1,0)平均结果为每四个留2个,即0.5。第一层(0.5,0.5)平均结果为留下来一个,同样为0.5,该算法的优点是每层丢弃率相同,而rescaled alpha value中则每层大多不同。缺点是第0层的某个像素被丢弃,而对应于第1层的像素可能被保留,从而导致质量问题。
(13)凹凸映射(bump map)?
方法一
使用一张凹凸纹理,每个纹素中存储了法线在u和v方向上的偏移bu和bv,最终结果等于原始法线加上u乘以bu和v乘以bv得到新法线。
方法二
用一张高度图代表表面凹凸程度。法线从高度图中计算,计算方法是通过sobel算子求梯度,或者使用中心差分来计算。
(14)视差映射(Parallax Mapping)?
normal/bump map的缺点是物体的凹凸不会随视角变化,它们之间也没有遮挡关系。Parallax map将物体表面的高度与视角的关系考虑了进去。
执行视差映射时,首先将将视线v转换到切线空间,并对v进行归一化。之后通过纹理坐标找到原始采样点p,查询p点的值h。最后根据h计算出新的采样点坐标 p a d j p_{adj} padj,查询该坐标的值作为最终高度h2
第一种方式是通过相似来计算新旧坐标差值,也是就原始采样点的高度值比上归一化后视线方向的z值等于新旧坐标差值比上视线在xy维度上的长度。
第一种方式的问题,当视线接近水平时,即使发生很小的一点变化也会造成高度的激烈变换。
解决方法,该问题的原因是视线接近水平时z值很小,也就是它所在的分母很小,解决方法是把分母的z值固定为1。
(15)视差遮挡映射(Parallax Occlusion Mapping)?
视差遮挡映射是一种更精确的方式,它的思想是沿视线的投影方向采样,一旦找到一个点满足视线上样本点的高度小于对应纹理的高度,那么用当前采样点和前一个采样点计算交点,求得最终高度。
第七章 阴影
(1)如何绘制平面阴影?
绘制平面阴影的思想是把物体投影到对应的平面上,然后用黑色绘制该物体。也就是说需要将整个场景绘制两遍,其中一遍绘制阴影。
(2)如何解决平面阴影中由于精度不足引起的条纹状阴影?
第一个方法是朝实现方向添加一个bias,第二个方法是首先绘制投影平面,接着禁止深度测试并绘制阴影,最后正常绘制物体。
(3)平面阴影绘制时阴影落在接收平面外怎么处理?
使用模板缓冲,第一步,绘制阴影接收平面,写入模板缓冲,第二步,禁止深度测试,仅在模板缓冲为1的地方绘制阴影,最后正常绘制物体。
(4)不考虑性能,平面阴影如何产生Ground-truth的软阴影效果?
把光源当做相机,把接收阴影的矩形平面当做远裁剪面,这样整个屏幕就相当于矩形平面,绘制出的图像当做矩形平面的纹理贴图。绘制方法是,相机沿光源表面采样多次,每次都绘制投射阴影的物体,颜色为阴影色,将多次得到的结果平均起来。生成的阴影纹理和矩形本来纹理混合在一起贴到矩形平面上。
(5)如何将平面阴影算法拓展到曲面?
将相机移动到光源位置,绘制遮挡体为黑色,其他为白色,生成一张阴影纹理。然后将该纹理贴到阴影接受体上。该方法的缺点是,第一,需要指定遮挡物体和对应的阴影接收体。第二,需要保证光源离遮挡体足够远。第三,遮挡体自身无法处在阴影中。
(6)阴影体算法(ShadowVolume)?
1.寻找物体在光源空间中的边界
2.根据边界构建阴影体
3.渲染场景,不过此时假设场景全部处在阴影中,也就是用黑色绘制
4.禁止深度写入和颜色写入,允许模板写入
5.裁掉后向面,绘制前向面,如果depth pass,模板值加一
6.裁掉前向面,绘制后向面,如果depth pass,模板值减一
7.正常绘制场景,不过只在那些模板值非0的地方绘制
(7)阴影体算法的缺点?
最主要的缺点是性能问题,这是该算法无法广泛使用的原因。其次是如果相机在阴影体中会该算法会失效,解决方法是采用zfail。
(8)阴影图算法(ShadowMap)?
该算法主要分为两步,第一步,以光源为视角绘制场景,存储深度图,但并不存储颜色值。第二步,正常以摄像机为视角绘制场景,在绘制某一点p时,首先将其变换到光源空间中,根据深度图查找在光源空间中的深度d,和p在摄像机空间中的深度z进行比较,如果z>d,那么p点就在阴影中,反之不在阴影中。
(9)如何解决shadow map算法中由于精度不足引起的self-shadow问题?
主要有两种方法,第一种是基于bias的方法,第二种是基于多层深度计算的方法。对于bias方法,在比较场景深度和光源深度时,将光源深度减去一个bais再进行比较。
(10)bias方法的问题及解决方法?
该方法在阴影接接收体表面的法线与光线方向几乎垂直时不适用。
解决方法是在光源空间中绘制阴影图的时候,将物体向远离光源的方向偏移一点,偏移的大小和表面法线与光源的角度成正比。不过当表面法线和光源方向平行时bias为0,所以需要在原始偏移的基础上还需要加一个常数的偏移。
(11)second-depth-shadow与mid point shadow?
second-depth-shadow方法在绘制阴影图的时候只绘制遮挡体的背面,它的缺点是,一些物体的正面和背面都会被渲染,进行面剔除可能会出现错误
mid point shadow方法在渲染物体到阴影图中时,始终追踪离光源最近的两个面,最后用两个layer的平均值作为阴影图。
(11)两种方法漏光(light leak)现象?
对于bias方法,如果偏移过大,会使得物体边缘处阴影产生异常偏移,使得物体看起来就像飘起来了一样。对于多层深度的方法,虽然不会产生漂浮现象,但是在深度断裂的地方可能会产生漏光。
(12)级联阴影(CSM)?
将摄像机的视锥体分成几份,在对这几个子视椎体分别绘制深度图,在绘制深度图的过程中,使光源的视锥体尽量紧密的包含相机的子视锥体,并且根据视锥体的远近选择不同分辨率,在相机空间绘制时,根据物体所在的相机子视锥体到不同的深度图中进行查找。
(13)如何更好的划分各子视锥体?
可以根据前一帧的深度缓冲划分,方法有两种,第一种是通过GPU中的reduce操作,寻找最大个最小的z-depth,依此作为远近平面划分依据。第二个是通过histogram操作,选择没有物体的缝隙处作为划分点。
(14)当相机移动时,如果一个物体属于不同层级,进而导致闪烁现象,入射处理?
使各子视锥体稍微重合,查询重合区域时使用两个阴影图中的混合值。
(15)CSM方法的一些优化?
1:如果某个子视锥体没有发生变化,那么其阴影图也不必重新计算。
2:对于每个光源,预计算哪些光源方向可见和能够投射阴影且有阴影接收体的物体
3:可以使用LOD近似计算第2步
4:不考虑小的遮挡体
5:物体越远,阴影图更新频率越低,而不是每帧都更新。物体越远意味着越不重要,不过需要小心大的物体。
6:CSM生成多个阴影图意味着要渲染多次场景,可以通过复制物体数据在几何着色器中将其送到多个视角中进行生成。可能的缺点是所有阴影图的遮挡体必须被发送到管道中,而不是与每个阴影图相关的集合。
(16)PCF算法的思想?
一种估算某点p被遮挡的程度的方法是,对面积光进行采样,发出若干射线,计算未遮挡射线和全部射线的比例,依此作为被遮挡的程度。
在实时渲染中,考虑到机器性能,我们将这个过程反过来,也就是PCF算法的思想,不对光源进行采样,而对p点周围的一小块区域进行采样,以此计算被遮挡的程度。
(17)如何解决PCF中的锯齿现象?
采用泊松采样或高斯加权采样等方式进行采样。
(18)PCF将p点周围的区域近似成了一个平面,这有什么问题,如何解决?
PCF将p点周围的区域近似成了一个平面,在非常陡峭的表面上,p周围的采样点p’可能远低于其在表面对应点上的高度,也可能反之。
解决方法是根据p点的信息构建一个虚拟的表面进行采样,有三种构建虚拟表面的方式,。第一种,根据中心点P构建一个虚拟锥体表面,周围的每个采样点移向锥体。第二种,根据中心点p所在的平面构建一个虚拟平面,周围的每个采样点移向虚拟平面。这种方法在物体是凸包时效果很好。第三种,每个采样点向中心点p所在平面的法线方向移动,移动大小正比于 s i n ( n , l ) sin(n,l) sin(n,l)。
(19)PCSS?
PCSS算法分为三步,第一步是寻找遮挡体,计算平均遮挡距离,第二步根据平均遮挡距离计算采样大小,第三步是根据采样大小进行PCF。
(20)PCSS算法的优化?
优化1:该方法需要对阴影图中相当大的一块区域进行检测以寻找遮挡体。使用Possion disk sample pattern可以减缓采样过少带来的问题。
优化2:在运动的情况下上面的采样模式并不稳定,采用介于抖动和随机之间的采样模式效果更好。
优化3:给定1张阴影图,生成两个mipmaps,分别存储最大和最小深度。比如对于min mipmap中,一个像素的值为原始纹理中2x2范围内(或4x4等)的最小值,当PCSS查询遮挡体时,首先和两张mipmap中的值对比,如果小于最小者,或者大于最大值,则可以判定该区域完全处在阴影中或者完全不在阴影中,不需要半影计算了。
(21)方差阴影图(VSM)?
VSM生成的阴影图可以进行滤波,这意味着MSAA、模糊和mipmap等方法可以作用于阴影图上。
VSM方法的步骤如下,第一步,在光源空间绘制阴影的时候存储深度值M1和深度值的平方。第二步,在相机空间绘制场景时首先计算p点在光源空间中的深度值t。之后先和M1比较若t pmax等于深度图的方差除以(方差加光源场景深度之差的平方)。 (22)如果一个阴影区域被多层物体遮挡,那么第二层遮挡物体会产生漏光,如何解决? (23)指数阴影图(ESM)? 它的步骤和阴影图相似,只不过存储的数据不同。第一步在在光源空间中计算 e c d e^{cd} ecd,存储在深度图中,参数c控制模糊程度,d为深度。第二步将相机空间转换到光源空间,计算 e − c z e^{-cz} e−cz,z为深度。将深度图中的结果乘上这个值,在01区间内截断并返回。 (24)ESM的改进? 改进方法: 1.在光源空间中返回 d d d ∑ i = 0 N w i e c d i \sum_{i=0}^N w_i e^{cd_i} ∑i=0Nwiecdi ∑ i = 0 N w i e c d i = e c d 0 e ln ( w 0 + ∑ i = 1 N w i e c ( d i − d 0 ) ) \sum_{i=0}^N w_ie^{cd_i} = e^{cd_0}e^{\ln\left(w_0+\sum_{i=1}^N w_ie^{c(d_i-d_0)}\right)} ∑i=0Nwiecdi=ecd0eln(w0+∑i=1Nwiec(di−d0)) c d 0 + ln ( w 0 + ∑ i = 1 N w i e c ( d i − d 0 ) ) cd_0 + \ln\left(w_0+\sum_{i=1}^N w_ie^{c(d_i-d_0)}\right) cd0+ln(w0+∑i=1Nwiec(di−d0)) (25)卷积阴影图(ConvolutionSM)? (1)Display Encode的目的? 它的目的是计算的值和显示的radiance呈线性关系,即计算值翻倍,radiance也翻倍。为了实现该目标,需要先把纹理中颜色的非线性数值进行decoding,变成线性值,着色器计算完成后,在encoding还原。 (2)如何进行Display Encode? 所以为了保证着色计算是在线性空间内进行的,从纹理到着色计算需要进行display transfer function变换,计算完成后还需要进行display transfer function逆变换。 由于display transfer function计算较复杂,所以在实现时一般采用简化版,即伽马校正,在移动端使用更加简化的版本,即采用根2函数进行映射。 后面的内容是颜色空间与HDR的内容,问答版描述起来不容易,还是看笔记版吧。 这一部分公式太多,看笔记版吧 (1)反射方程中n点乘l项的意义? 施利克方程只有两个参数可以调节,这使得它不能很好地匹配一些材质,后续有人再加了两个参数以更好模拟,分别为F90和指数项的次数。 (4)几何衰减系数项的组成? 几何衰减项一般由两部分组成,第一部分是微表面反射的光被另一表面阻挡的比例,这部分被称作遮蔽函数。第二部分是光线射入时被阻挡的光线比例,这部分被称作阴影项。 (5)Smith遮蔽函数? (6)Smith分离式阴影-遮蔽函数? (7)分离式阴影-遮蔽函数的缺点? 极端地想,当视线和光线重合时,入射光线不可能被阻挡,因为此时看不到阴影,没有阴影区域,所以阴影函数为结果为1,只考虑反射光被遮挡的情况,最终 G 2 = G 1 G_2=G_1 G2=G1,也就是 m i n ( G 1 , 1 ) min(G_1,1) min(G1,1).分离式函数结果却是 G 2 = G 1 × G 1 G_2=G_1\times G_1 G2=G1×G1,显然错误。 (12)Blinn-Phone,beckmann,GGX法线分布函数对比? 第一,在效果上,相对于beckmann,GGX的拖尾更长,Blinn则几乎没有。而在现实世界中的拖尾一般都长于GGX,这也是GGX受欢迎的原因。 第二,在参数与粗糙度的对应中,beckman使用参数 α b \alpha_b αb控制粗糙度。Blinn中参数 α p \alpha_p αp可以任意大。并且它不是线性的,数值和视觉感受上并不匹配。为了解决该问题,在参数和粗糙度之间引入一个映射, α p = m s \alpha_p=m^s αp=ms,s在0到1之间,m是 α p \alpha_p αp的上界。GGX的粗糙度也不是线性的,blurey提出以下映射 α g = r 2 \alpha_g=r^2 αg=r2,r是0-1之间控制粗糙度的参数。 第三,Blinn-Phone不具备形状不变性,其余两个具备形状不变性。 第四,Blinn-Phone NDF计算性能更优,在某些设备上运行效果更好。 (13)GGX优化? (14)Lambert模型的漫反射BRDF项? Oren-Nayar model Hammon momdel (18)微表面模型中如何对法线贴图进行滤波(法线长度方法)? 如果四个像素的法线平均后没有normalize,平均法线的长度与法线分布的宽度成反比。也就是说,原始图像法线方向越不相同,平均起来长度越短,粗糙度也就越大。 可以通过原始粗糙度和法线长度计算出新的粗糙度,也就是法线纹理直接平均,新的粗糙度纹理根据法线纹理和旧的粗糙度纹理计算。 (19)法线长度方法的问题? (20)微表面模型中如何对法线贴图进行滤波(方差映射方法)? (1)光泽表面如何模拟区域光的高光部分(roughness modification)? 粗糙度修改方法的缺点是对于很平滑的表面,区域光的着色会产生错误,因为是靠调整粗糙度来近似的,这样导致表面看起来不平滑了。 这个积分计算起来比较消耗性能,解决方法从积分中值定理出发,从积分区域中选择一个积分函数中值最大的点作为代表点。 先找到n点乘l最大的点,这个点在法线垂直方向上的投影最小。接着找到距离的平方的最小值点,该点到着色表面的距离最小。找到这两个点后从它们的连线上选择一个插值点作为代表点,这个插值系数可由美术人员指定。 对于同一粗糙度N,该模型作为预过滤的核函数 ( r ⋅ l ) N (r\cdot l)^N (r⋅l)N是相同的,。由于该模型只与反射方向有关,因此这里使用反射方向来索引预过滤的环境贴图。 除此之外,还需要考虑对不同粗糙度表面的预过滤,这需要对每个粗糙度系数N做一个单独的预过滤以生成一个不同的反射贴图,这样会面临比较大的存储压力。实践中,这些指数形式的粗糙度往往被转换为多级纹理的形式,即以渐进的方式生成一系列预过滤的环境贴图,并存储在mip map中,其中mip map中的每一级使用相对前一级具有2倍标准差的高斯函数, σ j + 1 = 2 σ j \sigma_{j+1}=2\sigma_j σj+1=2σj。 (1)Lambert模型表面环境遮挡系数? 改进的方式是将交点距离考虑进去,即令 ρ ( l ) = v ( l ) \rho(l)=v(l) ρ(l)=v(l),与v(l)只返回两种值0和1不同, ρ ( l ) \rho(l) ρ(l)根据交点距离范围结果,当交点距离大于dmax,返回1,小于的话返回0到1之间的值。该方法的问题是dmax需要手动确定。 Steawrt则直接令入射光的辐照度直接等于出射光的辐照度,即 L i = L o L_i=L_o Li=Lo,这中近似则将递归方程中止,直接得到了Ka解析表达式。 (5)屏幕空间环境遮挡计算有哪两种基本方法(SSAO)? uniform weight 直接这样做的问题是相邻的两个物体最近的cube map不同,导致它们的反射结果完全不同。对此,它们的解决方法是由美术人员手工分配cube map。 第二个问题:待着色表面离environment map中心的的距离越远,着色效果看起来越不真实。如下图右边,解决方法是,将场景用一个近似物体包裹起来,然后以p点为起点,向反射方向发射光线,计算得到交点,environment map的采样向量为从environment map到交点的向量。 光线在世界空间中均匀前进,当检测到相交,通过二分法精确地计算相交点。 问题1: 解决方法1: 优化: 问题2: 解决方法: 问题3: 解决方法: (13)如何用Hiz的思路改进上述SSR算法以提升效率? (1)GPU双边滤波? 如下图,第二张图的kernel在蓝色三角形上,在红色三角形上的采样点则忽略,对剩余权重则进行归一化,使它们和为1. Gjøl and Svendsen则首先生成一个深度缓冲,然后对lens flare要出现的区域进行32次采样,取平均值作为衰减量,乘在flare texture上。将sprite放在世界空间中光源的位置,在顶点着色器进行可见性采样。 有两个缺点,第一个是当一个物体属于多个区域时产生明显分界,第二个缺点是采用的模糊方法是均匀模糊,没有考虑到距离信息。 光线通过光圈的分布通常为均匀分布,而不是高斯分布。 低质量的相机会产生五角形的模糊,而非完美的圆形。 渲染时可采用六边形的模糊,该形状使用分离的two-pass后期模糊是比较容易实现的。 这个方法中模糊圈有两个用处,第一个是分离近景区域,第二个是对分裂的图像和原始的图像进行插值。 2/3步主要是为了产生覆盖效果。 实现该效果的方法是,检测高对比度的区域,对这些区域用sprite渲染以产生相应形状,其余区域正常进行景深处理。 改进方法:当前帧等于当前帧和前一帧的混合。比如,假定生成运动模糊效果需要8帧平均起来,现在已经生成了1-8帧,在第九帧的时候渲染两次,第一次是当前帧,将其放到累计缓冲中,第二次是第一帧的场景,将累计缓冲的结果减去第一帧的结果。该方法需要每帧渲染两次。 仅当相机移动时,径向模糊,以注意物体为中心。 (1)ToonShading? 缺点:比如一个绘制一个完全朝向摄像机物体,沿法线法向移动背向面会使左右上下四个面有非常明显的分离。 原因:对于这些顶点,每个面的法线都是不同的,所以这不是真正的shell,即使对上面的那个示意图,如果顶点在不同面的法线不同,也会产生错误。 解决方法1:强制同一位置的顶面具有相同的法线。 步骤 第二步骤检测方法 有时会错误地检测出边缘,比如根据法线检测边缘,在绘制一个圆柱体时,如果从近处看,中间表面的法线变化不大,可是如果离得远了,由于分辨率问题,可能会产生错误。 改进方法:对法线或深度图的梯度进行处理,而不是直接对值本身进行处理 有两种方法,第一种是暴力求解,然后对求解过程进行优化。遍历所有边的列表进行上述检测。 优化1:在上面的边列表中去掉一些不可能成为contour edge的边,比如,如果某边的相邻三角形在同一平面上,则该边不可能成为contour edge 优化2:如果该物体表面封闭,则凹陷的边也不会是侯选边。 优化3:每帧都进行检测很消耗性能,如果每一帧相机或物体移动都比较小,我们有理由假定前一帧的contour edge仍为有效边。 Aila为每个contour edge附加一个额外信息,以表明摄像机和物体最多还可移动多少使得状态不变。 第二种方法是只追踪contour edge loop。Markosian 首先检测出contour edge loop的集合,随后当相机变动时使用随机搜索算法更新该集合,在模型改变方向使需要对contour edge loop进行更新或删除。该方法虽然会带来速度上的提升,但准确率下降了。 (1)管线瓶颈? 第一个定位方法是增加一个顶点附带的数据,比如每个顶点多发送一些数据,观察性能变化。第二个定位方法是在顶点着色器中对顶点进行更多操作,使程序更长,观察性能变化 1.程序中连续访问的数据应当连续存储。基于空间局部性原理,当渲染一个三角形网格的时候,如果访问的顺序是:纹理坐标#0、法线#0、颜色#0、顶点#0、纹理坐标#1、法线#1 等,那么在内存中也应该按这个顺序连续存储。 2.。 尽量避免指针的间接、跳转,以及函数调用,因为它们很容易显著降低CPU 中缓冲的性能。比如当一个指针指向另一个指针,而这个指针又指向其他指针时,以此类推,类似典型的链表和树结构,而这将导致数据缓存未命中(cache misses for data)。为了避免这种情况,应该尽可能使用数组来代替。 3.对数据结构对齐。 4.某些系统中,默认的内存分配和删除功能可能比较慢,因此,在启动时最好为相同大小的对象分配一个大的内存池,然后使用自己分配或空闲部分来处理该池的内存 5.尽量尝试去避免在渲染循环中分配或释放内存。例如,可以单次分配暂存空间(scratch space),并且使用栈、数组等其他仅增长的数据结构(也可以使用标志位来标识哪些元素应该被视为已删除)。 pixel overdraw指的是真正有多少表面被绘制,它同时表示了浪费在绘制隐藏面的计算。 如果两个三角形覆盖了一个像素,其depth complexity为2,同时必定有一个三角形的绘制对最终效果没有影响,即overdraw为1。一个像素n个物体平均绘制次数为: 当深度复杂度很低时,重绘量会急剧增加,但增加速度也会逐渐减少。深度复杂度为 4,平均绘制 2.08 次,深度复杂度为 11,平均绘制3.02 次,但深度复杂度为 12367,平均绘制 10 次。 (15)Paralell Processing? (16)task-based Multiprocess? 某个部分可以被分解成task的几条准则: (1)八叉树算法中,如果一个物体在划分时属于多个区域如何处理? blinn指出两种方式在几何上是相同的,只不过计算空间不同,相较来说,屏幕空间计算更为安全 方法如下:在屏幕空间用一个包围盒包围住该三角形,如果任何维度上最小值和最大值四舍五入后相等,则可以裁掉,也就是该维度上跨度小于一个像素。注意:像素点的中心在(0.5,0.5)处。 两种,第一种是基于遮挡查询的遮挡剔除算法,第二种是基于层次zbuffer(Hierarachical Z-Buffer)的遮挡剔除算法。 第二个缺点是,它需要将查询结果回读到系统内存里,这就意味着VRAM->System RAM的操作,走的是比较慢的PCI-E。 为了解决这个问题,比较常用的的方法是让CPU回读前一帧的occlusion query的结果,用来决定当前帧某个物体是否visible,对于相机运动较快的场景,用上一帧的结果可能会导致出错,但由于一般是用包围盒,本身就是保守的剔除,所以总体来说影响不明显,UE4默认使用的就是这样的遮挡剔除方案。 可以加一些额外测试,来保证进入下一级的zbuffer测试是有用的。方法是,再加一个通过取最小值生成的z-pyramid(之前是用取最大值方式生成的),用包围盒投影中最大的z值zmax和对应层级的z-pyramid-near比较,若zmax小于全部采样点的z值,则不再进行下一级,直接绘制。否则进入下一级z-pyramid-further进行测试。 RTR4后面至少还提了5种改进方法,这里就不介绍了。 问题:每帧需要绘制两个层级的LOD 该方法的几个问题 假设有一个复杂的模型,首先生成一个简化模型,同时在两模型的顶点中存储复杂模型的顶点(红色)经过边折叠后对应的简单模型的顶点(绿色)。 从复杂模型过渡到简化模型则通过对复杂模型的顶点插值得到,如上图牛模型的简化过程,中间为过渡图,虽然它和左边简化的模型看起来一样,事实上它的顶点数量和三角形数量和右边复杂模型一样。 在过渡完成后,则使用简化模型。 问题:当物体在 r i r_i ri附近来回移动的话,使得物体LOD不停的切换。 解决:添加一段滞后区域。距离增加的话,按上面的划分选择LOD,距离减小的话,按下面的划分选择LOD。 这里只介绍球包围盒选择LOD的方法,RTR4中还提到了其他方法 该包围盒覆盖的像素大小为 π p 2 w h \pi p^2wh πp2wh,wh为屏幕分辨率。根据面积就可以选择LOD了。
裁掉pmax小于0.1的部分,将剩余部分由[0.1,1]缩放到[0,1]
ESM用了这个公式, f ( d , z ) = e − c ( z − d ) = e c d e − c z f(d,z)=e^{-c(z-d)}=e^{cd}e^{-cz} f(d,z)=e−c(z−d)=ecde−cz,当该值大于1时返回1,小于1时返回结果即可。
ESM在c值较小的时候会产生漏光效果,c值越大越好,但是 e x e^{x} ex函数增长迅速,在c=88左右就会达到最大值。
2.在相机空间中做一下处理
2.1计算p点在阴影图中的深度d0
2.2计算p点在相机空间中的深度z
2.3对p点周围进行高斯模糊,计算 w 0 + ∑ i = 1 N w i e c ( d i − d 0 ) w_0+\sum_{i=1}^N w_ie^{c(d_i-d_0)} w0+∑i=1Nwiec(di−d0)
2.3计算 c d z = c d 0 + ln ( w 0 + ∑ i = 1 N w i e c ( d i − d 0 ) ) − c z cdz=cd_0 + \ln\left(w_0+\sum_{i=1}^N w_ie^{c(d_i-d_0)}\right)-cz cdz=cd0+ln(w0+∑i=1Nwiec(di−d0))−cz
2.4计算 e c d z e^{cdz} ecdz,并将其作为结果
它的思想是将阴影深度encode到一系列傅里叶函数中,后续和ESM差不多。第八章 颜色空间和HDR
从纹理到显示总共分为四个部分,分别是纹理,着色计算,颜色缓冲和显示,从颜色缓冲到屏幕显示进行转换时,硬件会自动进行display transfer function,一般的纹理会存储时会提前进行display transfer function的逆变换。第九章 基于物理的着色
radiance Li的意义是单位面积在方向w上接收到的能量,n点乘l则表示有效接收面积,当光源与表面垂直时为1。
(2)Lambertian模型的BRDF?

(3)Fresnel方程?
Fresnel方程描述了反射率与视角的关系。原始的菲涅尔方程很复杂,在实时渲染中一般以较少的参数近似该方程。在施利克方程中需要的参数为F0和n点乘l。其中F0为光线垂直于表面时反射光的比例。
Smith遮蔽函数通过一个符号函数比上一加 Λ \Lambda Λ函数得到, Λ \Lambda Λ函数需要从给定的法线分布函数中推导。
Smith分离式阴影遮蔽函数简单的将阴影函数与遮蔽函数结果相乘,该函数可以看做微表面反射的光被另一表面阻挡的比例直接乘上光线射入时被阻挡的光线比例。
该函数简单的认为遮蔽和阴影相互独立,互不影响,这显然是错误的,基于该基础的函数使得场景显得更暗。
(8)方向相关阴影-遮蔽函数?
方向相关阴影-遮蔽函数将l和v之间的关系考虑了进去,其实它的思想就是在完全独立与完全相关两种极端情况之间进行插值,分离式函数是完全独立的情况,min函数是完全相关时的情况,两者之间的插值函数的参数是l和v的相位角。
(9)高度相关阴影-遮蔽函数?
除了l和v之间的关系外,如果一个点很低的话,那么处在阴影中的概率和被遮挡的概率都会很大。该方法的思想也很简单,与分离式相比就是分母少了个 Λ ( l ) Λ ( v ) \Lambda(l)\Lambda(v) Λ(l)Λ(v),在前面我们有知道 Λ ( v ) \Lambda(v) Λ(v)表示微表面斜率上的积分,如果倾斜很大的话,积分就会很大。
(10)什么是形状不变性?
Heitz定义:如果一个各向同性的NDF具有形状不变性,那么缩放粗糙度参数相当于通过倒数拉伸微观几何。
(11)形状不变性的优点?
第一,具有形状不变形的函数可以改写成特定形式,利用该形式可以推导出各项异性的NDF。
第二,可以比较容易推导出几何衰减项。
由于GGX的广泛使用,人们提出了很多方法来简化GGX的计算,主要方法其实就是把GGX推导出的几何衰减函数G和BRDF分母的两项进行约分来减少计算。
在此基础上,还可以对遮蔽函数或者阴影函数做近似以获得更好的效果。
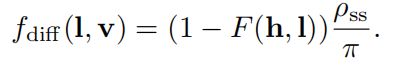
(15)Lambert模型的漫反射BRDF项的缺点?
该模型认为出射光的分布是均匀的,并且没有考虑到v,也就是漫反射颜色不随视线方向而变化。

上面是一种改进措施,将v结合了进去。该式从Schlick Fresnel推导得出。该模型的一个缺点是在这一对系数中,diffuse项只在specular项是完美的Fresnel mirror的时候可以使用。
(16)Oren-Nayar模型与Hammon模型推导的三个前提?
1.NDF:sphericalGaussian NDF
2.Torrance-Sparrow “V-cavity” masking-shadowing function
3.微表面的BRDF f u f_u fu,Lambertian micro-BRDF
1.isotropic GGX NDF
2. height-correlated Smith masking-shadowing function
3. 改进的Lambertian微表面BRDF
(17)Lambertian模型的法线贴图如何滤波?
一般来说,法线和着色颜色之间的关系并非是线性的,标准的滤波操作可能会带来锯齿。不过lambertian表面是例外,它的normal map和着色的关系几乎是线性的。
l ⋅ ( Σ n j n ) = Σ ( l ⋅ n j ) n l\cdot(\frac{\Sigma n_j}{n})=\frac{\Sigma(l\cdot n_j)}{n} l⋅(nΣnj)=nΣ(l⋅nj)
所以Lambert模型对normal map进行滤波产生的效果几乎是正确的,但是存在的一个问题是, m a x ( l ⋅ n , 0 ) max(l\cdot n,0) max(l⋅n,0)是非线性的,进而导致高光区略暗,不过总体上的效果是可以接受的。
如果直接对法线纹理和粗糙度纹理直接滤波会产生错误效果。
新粗糙度的计算公式是从blinn NDF推导而来,由于beckmann和blinnNDF存在映射关系,所以该方法也可用于beckmann。
GGX分布没有映射与blinn的映射关系,不过最终使用的时候将beckmann与BlinnNDF的映射关系接着用到GGX上,虽然理论上不行,但最终效果其实还不错。
该方法分为两步,第一步是在生成法线纹理的mipmap时存储由于平均法线而产生的variance(方差/差别??)。第二步是用variance修改粗糙度纹理的mipmap。
它的在程序运行时动态生成第十章 局部光照
由于增大光源面积和增大粗糙度效果是差不多的,所以粗糙度修改方法的核心是找一个锥体来最大程度上覆盖住区域光入射方向的范围,然后选择一个粗糙度,使它的BRDF的lobe和这个锥体差不多。
(2)光泽表面如何模拟区域光的高光部分(most representative point)?
代表点方法的思想是在球形光源上找一个离反射光线最近的点作为代表点进行着色。当反射光不在区域光源入射光线组成的cone中时,将区域光简化为点光源。
(3)四边形光源如何模拟高光部分(card light)?
假定光照模型是Lambert模型,它的高光部分等于对n点乘l在除以距离的平方的积分,得到的结果在乘以光照强度。
(4)环境映射的步骤?
1:生成或者载入一张表示环境的纹理
2:根据视角和表面法线计算反射方向
3:根据反射方向查找environment map
4:查找到的值代表在该视线的反射方向入射辐射度Li,进行着色计算
(5)基于图像的光照(Image-Based Lighting)中phong模型光泽表面的环境纹理如何生成?
对于最简单的phong模型,它是各向同性的,并且它的反射函数形状只与粗糙度有关,而与反射方向和表面法线无关,这使得在同一粗糙度下,该模型的BRDF是固定的。
L p h o n g ( r ) = ∫ H ( r ⋅ l ) N n ⋅ l L ( l ) ( n ⋅ l ) d l = k s ∫ H ( r ⋅ l ) N L ( l ) d l L_{phong}(r)=\int_H\frac{(r\cdot l)^N}{n\cdot l}L(l)(n\cdot l)dl=k_s\int_H(r\cdot l)^NL(l)dl Lphong(r)=∫Hn⋅l(r⋅l)NL(l)(n⋅l)dl=ks∫H(r⋅l)NL(l)dl
(5)IBL中复杂模型光泽表面的环境纹理如何生成?
L o = ∫ H L ( l ) D ( h ) G ( l , v , h ) F ( v , h ) 4 ( n , v ) d l ≈ ( ∫ H L ( l ) D ( h ) d l ) ( ∫ H G ( l , v , h ) F ( v , h ) 4 ( n ⋅ v ) d l ) L_o=\int_HL(l)\frac{D(h)G(l,v,h)F(v,h)}{4(n,v)}dl\approx (\int_HL(l)D(h)dl)(\int_H\frac{G(l,v,h)F(v,h)}{4(n\cdot v)}dl) Lo=∫HL(l)4(n,v)D(h)G(l,v,h)F(v,h)dl≈(∫HL(l)D(h)dl)(∫H4(n⋅v)G(l,v,h)F(v,h)dl)
在实际使用的时候一般采用分裂求和的形式,原始的积分项为光照强度乘上BRDF再乘上衰减系数n点乘l,计算时d点乘l和BRDF的分母进行约分,然后分裂成两项,第一项是对光照强度乘法线分布函数的积分。第二项是对几何衰减成菲涅尔项再除以n点乘v的积分。
(5)分裂求和方法的第二项如何计算?
分裂求和方法的第二项不含光照强度,对于同一着色模型,它们的积分结果都是相同的。所以这一项可以进行预计算,在索引的时候需要三个参数,分别是n和v的夹角 θ \theta θ,粗糙度 α \alpha α,以及F0。为了降低维度,可以把第二项中的F0单独提出来,,变成 F 0 × a + b F_0\times a+b F0×a+b的形式,这样只需要一个二维纹理存储对应a和b的值。
(6)分裂求和方法的第一项如何计算?
第一项的被积函数有两部分,第一部分是光照强度,这个直接采样纹理的颜色值就可得到。第二部分是预计算法线分布函数,它需要表面法线,入射和反射向量,由于我们不知道实现方向,所以我们假定这三个向量都等于反射向量进行计算。
(7)grazing angle处异常产生的原因?
在着色点位于掠射角的时候,反射lobe中有一半其实是不应算入到结果中的,因为它们处在表面的下方,这导致边缘异常的亮。在实际使用的时候一般忽略这个问题。
(8)Lambert表面漫反射环境纹理的生成?
∫ H L ( l ) ( n ⋅ l ) π d l \int_H\frac{L(l)(n\cdot l)}{\pi}dl ∫HπL(l)(n⋅l)dl
Lambert表面的被积函数是光照强度L乘以n点乘l再除上pi,积分区域是整个半球。对于每个给定的法线,都生成对应的积分结果,最后着色的时候使用表面法线进行索引。第十一章 全局光照
Lambert模型表面环境光辐照度的被积函数为光照强度乘以衰减系数n点乘l,积分区域为着色点法线朝向的半球,Lambert模型的光照强度为常数,故积分结果等于pi乘上环境光强度。
这些步骤没有考虑可见性函数,将可见性函数添加到被积函数中得到环境遮挡系数。也就是说,环境遮挡系数的被积函数是可见性函数乘上衰减系数,最后再归一化。环境光最终等于pi乘以环境遮挡系数再乘以环境光强度。
(2)bent normal?
称余弦加权的所有未遮挡光线方向的平均为bent normal,即为 n b e n t n_{bent} nbent。
(3)封闭环境中遮挡系数计算存在的问题及解决方法?
假设在一个封闭的环境里存在一个物体,它环境遮挡系数Ka的计算结果始终为0,因为所有方向一定会和场景有交。
(4)多次反射产生的环境光如何模拟?
上面几种方法都存在的一个缺点是都假定来自遮挡方向的radiance为0,这种假设使得场景变得更暗。
第一种是基于遮挡率的方法,第二种是horizon-based,如HBAO和GTAO。
(6)基于遮挡率的SSAO?
Crytek最先提出SSAO,它们只使用了z-buffer计算,方法如下,以片元所在世界空间中的位置为中心形成一个球面,在球内进行采样,将采样到的点投影到屏幕空间,根据得到的坐标对深度缓冲进行查询,若该值大于查询值,则该点被遮挡。用未被遮挡的采样点数目除以总采样点数目就得到了环境遮挡系数Ka。
(7)朴素的SSAO的缺点?
有两个缺点,第一个缺点是丢失了cos项,导致平面区域平均只有一半未被遮挡,即遮挡系数为0.5,而边缘区域相对平面区域更亮。第二个缺点是double-shadowing问题,它对某些情况的遮挡计算错误。
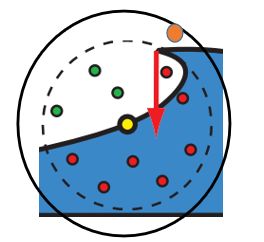
(8)朴素SSAO的变种算法?
朴素SSAO是通过球形采样区域内未遮挡采样点比上总采样点来计算遮挡率,第一个变种方法则直接计算球形区域内未被遮挡的体积除以总体积,与朴素SSAO在相机空间中采样不同,变种算法直接在屏幕空间中的xy维度上做积分。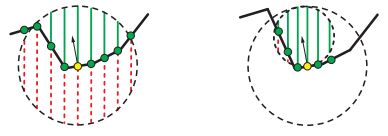
第二个变种算法是基于第一种变种算法改进的,第一种算法的精确率虽然提高了,但是并没有考虑到cos,同样会出现朴素SSAO的问题,第二种算法则直接在cos空间中计算体积比。
(9)基于horizon的SSAO(HBAO)?
HBAO认为深度图代表着连续的高度场,这简化了问题,但对于不连续的情况效果就不是很好了。HBAO对double-shadowing问题解决的很好。
HBAO首先根据法线确定出切平面,在切平面上进行360度的采样,在某个采样方向 ϕ \phi ϕ上,以 h ( ϕ ) h(\phi) h(ϕ)的最大值作为参数1, h ( ϕ ) h(\phi) h(ϕ)是该采样点与切面的夹角大小,以 t ( ϕ ) t(\phi) t(ϕ)作为参数2。
HBAO的被积函数有两部分,第一部分是衰减项,在距离为球体半径时衰减到0,第二部分是cosθ。对于给定采样方向φ,φ所在半圆面的积分直接取h(φ)的最大值进行计算,这样就可以不进行内层积分了。

(10)基于horizon的SSAO(GTAO)?
GTAO相对HBAO的变化主要有两部分,第一部分是加入了可见性函数,第二部分是加入了cos项,即n点乘l的截断。

cos weight
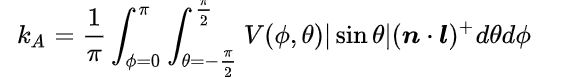

(11)局部环境映射(Localized Environment Maps)?
最先应用该方法的游戏是半条命2,在开发过程中,美术人员在场景中设置采样点,在预处理阶段,每个采样点都会根据它们的位置生成一个cube map。在计算specular light的时候,直接用反射方向查找最近的采样点的cube map。
(12)屏幕空间反射(screen-space reflections)?
给定着色点世界空间中的位置,视线方向和法线,可计算得出反射方向,沿该方向计算与depth buffer的交点。交点计算方法是沿着光线方向迭代前进,将世界空间坐标投影到屏幕空间坐标,查询对应深度缓冲中的值。如果该值小于光线上采样点的z值,那么意味着该点检测到相交。接着用对应坐标查找颜色缓冲,作为入射光的radiance。
由于该方法是在世界空间中进行追踪,这导致在屏幕空间中,较近的地方在世界空间中前进一步可能对应于屏幕空间中许多像素,在较远的地方在世界空间前进很多步可能还是对应屏幕空间中的一步。
将起始点和终止点投影到屏幕空间,在屏幕空间中对连线上的每个像素进行检测。
对每个像素都检测消耗过大,可以通过xy方向上的变化量计算出前进方向,沿前进方向步进。
最基础的SSR只追踪一条光线,只能提供完全镜面反射,无法模拟glossy表面。
仍然采用一根光线追踪,不过追踪到的反射结果单独存储在一个缓冲当中。对该缓冲进行不同程度的降采样和模糊,分别存储起来。
在计算光照的时候,根据BRDF lobe的宽度选择不同的缓冲。
虽然看起来还不错,但是直接对结果进行过滤则把表面的不连续性,表面朝向等因素都忽略了。
Stachowiak以一种更符合理论的方式进行计算。他使用BRDF重要性采样,在反射方向周围随机发射光线。由于性能限制,该方法在一个更低分辨率的缓冲中进行,并且每条光线仅采样一到四个点。由于采样点过少,生成的图像会充满噪声。在此基础上,该方法将相交信息共享与周围周围多个像素。比如p0点在d0方向交于i0点,可以假设我们从p1向d1发射的光线的交点仍然为i0,取出结果,然后将乘上该方向的贡献都总积分中。
和Hiz进行遮挡剔除的思路有点类似。首先将深度缓冲进行降采样,下一级每2x2个像素形成一个新像素,数值取四个中的最小值。
之后进行相交检测,先在高分辨率深度缓冲中检测,如果在给定步骤内没有检测到相交,则采用更低分辨率的深度缓冲进行采样,直到碰到相交,如第二行左边,之后采用精细的深度缓冲进行检测。第十二章图像空间处理
高斯双边滤波会丢失边缘的信息。GPU双边滤波则丢弃或降低那些与采样中心不相关的采样点,来保留边缘信息。可以通过深度,法线等信息来确定采样点是否相关。

(2)2D镜头光晕实现方法(lens of flare)?
在屏幕空间中创建一系列不同纹理的正方形来表示光晕,根据屏幕空间中光源与屏幕中心的连线确定朝向。光源离屏幕中心越远,则该正方形越小且越透明,反之则越大且越不透明。
(3)上述方法的改进?
Maughan通过使用GPU来计算屏幕上区域光源的遮挡来改变镜头光晕的亮度。
(4)镜头光晕条纹(steak)效果实现?
通过方向滤波实现,也就是在给定方向做模糊。
(5)巫师三中镜头光晕处理?
首先提取亮的部分,再以光源为中心进行径向模糊,重复多次。这些模糊操作都是在低分辨率的图像上进行的操作,和最开始介绍的一样,降低分辨率相当于提高滤波大小。
(6)光晕(Bloom)实现方法?
光晕可以让光源看起来更亮。它的实现方法是提取场景中较亮的部分,进行模糊,得到bloom的图像,最后和原始场景进行合成。
(7)Bloom实现过程中的一些要点?
1.提取较量部分可以用bright pass fliter,即亮的部分保留,暗的部分设为黑色,过渡部分采用混合或缩放。
2.bloom的图像可以低分辨率渲染,理由见前几节。
3.bloom的图像也可以通过多次降采样,再把降采样的图像合起来作为最终结果,该方法可以采样的消耗并提高模糊范围。
4.最终的结果值肯定会超过1,所以需要缩放会0到1区间。
(8)景深效果有几大类实现方法?
主要有三大类方法,第三类方法有两种方式。第一大类方法是根据累计缓冲实现,第二大类方法是区域分离方法实现,第三大类是基于模糊圈的算法,它有两种实现,第一个是基于模糊圈的区域分离算法,第二个是scatter as you gather方法?
(9)累计缓冲方法实现景深?
通过累积缓冲的方法,沿透镜改变相机的位置,同时固定焦点,这样物体就会根据离焦点的远近进行不同程度的模糊。虽然该方法可以达到ground-truth,但是需要对场景渲染多次,消耗巨大。
(10)区域分离方法?
将场景中分为三个部分,近景、远景和聚焦区域。通过改变远近裁剪面来分别渲染上述三个部分的结果。对非聚焦区域进行模糊,最后根据深度将三张图片合在一起。
(11)什么是模糊圈?
当相机聚焦点位于非聚焦区域时,景深效果可近似为一个像素影响到周围的像素,影响的范围则称为circle of confuse,模糊圈的大小由多个参数决定。
(12)基于模糊圈的区域分离算法?
和区域分离方法类似,不过考虑到了距离对模糊效果的影响和解决了分解问题。
第一步为对每个像素生成一个值代表模糊圈半径,它的计算需要多个相机参数。
第二步根据模糊圈半径分裂成两张新的图像,近景图像和剩余区域图像,加上原始图像总共三张图像。
第三步对分裂的两张图片进行模糊,对前景图像进行降采样和模糊,同时前景区域的每个像素还可附加一个alpha值,表示混合系数,该值也被模糊。对剩余区域图像同样进行模糊。
第四步将三张图片合在一起,近景区域直接和原始图像进行混合操作。剩余区域图像根据模糊圈大小和原始图像进行插值。
(13)如果不把前景分离出来有什么后果?
如果不将前景和其他区域分开的话,前景和其他区域交界处会有明显的边界,因为聚焦区域的模糊圈半径为0,所以该区域相当于没有进行模糊。
(14)scatter as you gather?
1,对一个较大区域采样,根据模糊圈找出那些可以影响到中心像素的采样点。
2,从这些采样点中找出z值最小的点,和与该点z值相近的点,将这些点的像素值加和平均,在计算时根据模糊圈估计影响程度,存在alpha值中,用于后续混合是产生覆盖效果。
3,将第二部的结果连同alpha存在前景结果图中。
4,除了第2步之外的点,进行相似的加和平均操作。
5,将两张图进行blend操作。
(15)boken效果?
由光源或高光造成的模糊圈要比周围其他物体更亮,这些明亮的光源对比度更高,因此更清楚地显示光圈形状。有时用术语bokeh描述这种亮的区域,虽然这是不准确的。
(16)运动模糊的实现方法?
和景深类似。第一种是累积缓冲,第二种是仅当相机移动或转动时采用的方法,第三种是scatter as you gather。
(17)累计缓冲方法?
在一帧时间内渲染场景多次并模糊。和景深一样,可以达到ground truth,不过消耗太大。
(18)仅当相机移动或转动时采用的方法?
仅当相机转动时,在给定方向模糊即可,该方法被称作line intergral convolution。如果沿view轴改变朝向,则进行circular模糊。
(19)朴素运动模糊方法?
Rosado的方法:使用前一帧相机的view矩阵计算速度。根据当前帧屏幕空间中的坐标即深度值反推回其世界坐标,再用前一帧的view矩阵计算其屏幕空间坐标。两个坐标相减即为速度向量,根据该结果进行模糊。
(20)scatter as you gather?
1:Pass1,计算velocity buffer,通过在顶点着色器中将前一帧和当前帧的model矩阵作用于顶点上,它们的差即为速度,然后将该速度向量变换到屏幕空间,piexl shader中对顶点速度插值得到每个像素的速度。

2.Pass2,屏幕后处理,缓冲大小为第一个Pass的1/64,每个像素存储Pass1的输出中每8x8像素速度的最大值。
3.Pass3,屏幕后处理,缓冲大小和Pass2相同,每个像素存储Pass2的输出中每3x3像素速度的最大值。
4.最后一个pass,采样Pass3结果,得到最大方向,沿该方向采样,通过Pass2中的结果判断采样像素是否会影响到中心像素,若影响到,则累积进去。若Pass3中的值小于一定程度,则不进行模糊采样。
(21)scatter as you gather要注意的部分?
第一个是,前景不动而其后面的物体动,对前景物体采样时,会将后面物体的颜色同样考虑进去。解决方法是通过深度来判断前景后景并作出相应处理。
第二个是ghosting现象,过对采样点进行randomly jittered处理。第十五章 非真实感渲染
主要有两个参数,描述物体表面漫反射程度的NdotL以及描述物体表面镜面反射程度的VdotR,用这两个参数来划分不同的色块。
(2)如何确定countour edge?
对于countour edge,它相邻的两个三角形朝向不同方向。检测方式是通过法线和视线的点积来确定countour edge,如果结果接近0,那么这个边很可能是countour edge。
(3)几何方法确定countour edge的缺点?
1.边缘宽度不确定。
2.对于一些物体比如立方体会失败,采用该方法绘制一个接近正对着摄像机的正方体,最终绘制时会发现左右两面全部被判定为边缘。
(4)如何确定轮廓边?
过程式几何方法
第一步进行背面裁剪,正常绘制前向面,第二部进行正向面裁剪,绘制后向面,不过后向面根据深度值向前移动一点。
(5)过程式几何方法的问题,怎么解决这种问题?
这个方法的边缘宽度不是均匀的的,同时,边缘宽度不仅取决于向前移动大小,还和前后面夹角有关。
有两种解决方法,第一种是拓展背向三角形,第二种是shell方法。
(6)拓展背向三角形方法?
这个方法在绘制背向面时将背向三角形的三条边在三角形平面内向外拓展一定距离来保证在屏幕空间中描边宽度相同。
存在的缺点是,对于特别细长三角形,角上的顶点移动的距离特别长。
改进方法是,将三角形的三条边向外平移,并把这些边连接起来,形成一个六边形。
(7)shell方法?
让背向面沿法线方向移动一定距离。
解决方法2:在这些会产生分离的边上再创建两个三角形,(总共四个顶点,但每两个的位置相同),当沿法线移动之后,它们就成为了有面积的三角形。
(8)通过后处理的方法进行边缘检测?
深度不连续可用于确定contour-edge,法线不连续可用于确定 contour和boundary edge等等
1:绘制场景,存储深度,法线,物体ID等信息到render targets中。
2:后处理pass,根据上面信息检测边缘。
1.sobel算子,拉普拉斯算子等
2.膨胀腐蚀算子,可以检测边缘或者使边缘更粗。
(9)如何找出所有的countour edge?
如果一个边相邻三角形朝向不同方向,那么这个边是contour edge。第十八章 管线优化
最慢的阶段决定整个管线的速度。如果瓶颈所在的阶段无法被优化,可以让其他阶段做更多的事情。
(2)管线优化基本步骤?
1.定位瓶颈
2.优化对应阶段
3.瓶颈可能会转移,重复1步
(3)定位瓶颈的两种基本操作?
方法1:减少测试阶段的工作量,如果整个管线性能提升,则该阶段为瓶颈
方法2:减少除测试阶段外其他阶段的工作量,如果pipeline未有性能提升,则测试阶段为瓶颈
(4)应用程序阶段如何定位瓶颈?
定位方法1.减少其他阶段的数据量来尽量使它们不工作,虽然在该种情况下CPU始终是瓶颈,但是可以知道在GPU阶段不运行时,application阶段有多大提升。对于某些系统,可以通过一个null driver(即接受调用但不执行任何操作)来进行检测。
定位方法2:对 CPU 进行Underclock。如果性能与 CPU 速率成正比,则application是CPU-Bound。
(5)几何处理阶段瓶颈产生原因和定位?
有两个原因,分别是顶点数量和顶点处理的操作量
1:vertex fetching
2:vertex processing
(6)像素处理阶段(piexl processing stage)定位瓶颈方法?
方法1:改变屏幕分辨率,如果低分辨率使得性能提升,该阶段很可能是瓶颈
方法2:分辨率可能会影响其他阶段,可以通过增加片元着色器的操作量来观察性能变化。
方法3:texture cache misses也可能是原因之一,将使用的纹理分辨率换成1X1大小,如果有提升,则可能是瓶颈。
(7)应用程序阶段瓶颈优化方法?
从两个大的方面优化,第一个方面是使代码运行更快,第二个方面是使内存访问次数更少且更快。
(8)减少状态切换的方法?
1:batching批处理,将要渲染的物体按shader,使用的texture等方面分组渲染来减少state change
2:重新组织物体的数据。比如减少纹理绑定的一个方法是将多个纹理放到一个大的纹理中。或者使用API中的bindless texture。
(9)减少draw call的方法?
1.将多个相同shader和state的物体合成一个mesh绘制。
2.实例渲染
(10)Piexl Processing阶段的一些优化方法?
1.LOD根据不同的距离使用不同的着色器,越远则使用的着色器越简陋。
2.early-z,在Piexl stage之前的阶段进行zTest,使得未通过的fragment不进行着色计算
(11)深度复杂性和重绘次数的概念?
可视化深度复杂度的方法是使用glBlendFunc(GL_ONE,GL_ONE),先让场景为黑色,之后场景绘制的物体的颜色为(1/255,1/255,1/255),这样如果一个piexl越白,那么这个像素绘制的次数越多。

上式背后所包含的逻辑是:第一个绘制的多边形是一次绘制:第 2 个多边形在第一个多边形之前绘制的概率是 1/2:第三个多边形在前两个多边形前绘制的概率是 1/3。
(12)减少重绘(overdraw)的方式?
1:从近向远绘制,远处的物体不会写入到color和zbuffer中。
2:z-prepass(不是early-z)方法
第一次只绘制几何到zbuffer中,第二次正常绘制。
3.在之前提到过可以通过shader和texture的不同将待绘制的物体分组,这里我们再加上距离。这样产生的难点是很难找到一种理想顺序满足三种要求。
可行的方法如上,用更低精度位数存储距离,使得我们更有可能分组绘制相同shader和texture的物体集合,第一位是透明位,在所有不透明物体后绘制,同时透明物体的距离应取到数或取相反数,从而可以从后到前绘制。
(13)实时渲染中的三种multiprocess的方法?
1.时域并行:multiprocess pipline
2.空域并行:parallel process
3.两者结合起来,task-based multiprocessing
(14)Multiprocess?
将整个application stage分成多个部分,每个部分单独执行。一种分离策略是分离成APP,CULL,DRAW三部分,每部分功能如下
1.APP collision detection,viewpoint updata等操作
2.CULL LOD,state sorting,生成要渲染的物体列表等操作
3.DRAW 去除CULL中的列表并调用绘制命令

图中下标指的是第几帧,下面两种方法相较于第一个每个阶段可用的时间更多,吞吐量更大,速度更快,但是延迟更大,也就是从玩家做出决定到视觉产生相应反馈的时间更长。

减少延迟的方法如上。让CULL和DRAW阶段有一定重叠,这也意味着,CULL阶段每生成一个render list就需要尽快送到DRAW,在这两个阶段之间用一个FIFObuffer管理。当该buffer满的时候,CULL拥塞,空的时候,DRAW饥饿。
Multiprocess pipline的缺点是延迟,Paralell Processing可解决这个问题,与Multiprocess pipline将整个application分成三个阶段不同,Paralell Processing将整个application的任务分成许多份,比如将选择LOD这个任务分成多份。
将前面两种方法结合起来,任何一个processor产生的task都可以放到work pool中,任何空闲的process也可以从work pool中取得一个task。
1:task应当有明确定义的输入和输出
2:task在执行的时候应当是独立的
3:task不能过大,使得某时只有一个processor在运行。19
1:将该物体存储在能完全包含整个物体且划分区域最小的层级,该方法的问题是,会导致许多三角形都处在较高的层级上,这样查询的时候效率很低。
2:将指向该物体的指针放在每个叶子节点中,问题是对物体进行修改时很麻烦,因为放在了多个地方。并且效率也较低。
3:宽松的八叉树算法loose octrees
(2)宽松的八叉树算法loose octrees?
该方法的主要思想是box的size可以更大,在上图左边,每个新的box是原来的1.5倍,它们的中心和之前一样。这样左图中的五角星可以被整个的划分到一个box中。
(3)有几种主要的裁剪技术?
视锥裁剪,遮挡裁剪,背面裁剪。
(4)有几个层次的裁剪?
三个层次,第一个层次是物体或实例,第二个层次是三角形集合,第三个层次是三角形。
(5)背面裁剪的三种主要算法?
第一种是基本的三角形层面的背面裁剪算法,第二种是三角形集合层面,第三种是静态场景三角形背面剔除。
(6)三角形层面的两种背面剔除算法?
1:在屏幕空间中计算三角形的有向面积,如果为负值,则为背面。计算方法就是软件光栅化中用到的叉乘。
2:在view Space里进行,方法是沿三角形表面任意一点(最简单的方式选择一个顶点)与视点做连线,然后与法线做叉积,若为负值则是背面。
(7)三角形集合层面背面剔除算法(cluster backface culling)?
步骤如下:
1.构建一个平截锥体,下图第二个,该平截锥体应包含三角形所有法线方向。
2.所有三角形顶点在平截锥体法线上的投影用来决定最大最小的阶段距离(下图第三个)。
3.根据视点位置是在front cone还是back cone来决定该三角形集合是否可见(下图第四个)。

(9)静态场景背面剔除算法?
计算一个正方体包围住n个三角形,每个面都被分成rxr个Pixel(虽然Piexl表述不是很准确),每个Piexl都包含n位编码表示n个三角形通过该Pixel是否可见。以左边第二个Piexl可见计算为例:沿正方形中心向Piexl做连线得到一个锥体,n个三角形中如果该三角形朝向的半空间与该锥体相交,则为正面,反之为背面。
给定一个立方体外部的视点,寻找其所在的Pixel形成的视锥体,查询该Piexl的编码,进行背面剔除。

(10)视锥裁剪优化?
每个检测出与视锥相交的三角形(即排除完全在视锥内和完全不在两种情况)都存储k位编码表示该三角形与视锥体的哪个面相交,后面更新的时候只需要检测这个面就可以了。
(11)Portal Culling的基本步骤?
1.去除不再视域内的cell
2.去除不连通的cell
3.去除入口不再视域内的cell
4.是否存在一条穿透线,通过从视点到当前cell的所有portal
(12)小三角形裁剪算法(detail and samll triangle culling)?
裁剪原因:相机运动时很小的三角形对结果影响很小或者没有影响,当相机停止时,detail culling通常被禁止。
(13)遮挡剔除的概念,它有几种基本实现方法?
处于视锥内的模型也未必是可见的,因为它有可能被其他模型完全挡住。如果我们能够用比较低的代价剔除掉那些被完全遮挡的模型,那么就不需要对它们再进行绘制,从而提高渲染性能。
(14)什么是遮挡查询?
occlusion query允许你在绘制命令执行之前,向GPU插入一条查询,并且在绘制结束之后的某个时刻,从GPU将查询结果回读到系统内存里。这条查询命令得到的是某次DrawCall中通过Depth Test的Sample数量,当这个Sample的数量大于0时,就表示当前模型是部分可见的,否则当前模型完全被遮挡。
(14)基于遮挡查询的遮挡剔除算法?
三个步骤
(1)用一个简单的depth only的pass绘制整个场景
(2)每次绘制前后插入occlusion query的命令,并根据passed sample count去标记某个物体是否被完全挡住
(3)执行正常的渲染流程,并剔除那些被标记为完全遮挡的模型
(15)基于遮挡查询的遮挡剔除算法的缺点及改进?
第一个缺点是,对于复杂的场景,即使只用简单的depth only pass也有很大的开销优化方法是用包围盒代替模型本身去做渲染,为了更加精确,也可以用多个紧贴的包围盒或者相对原模型更简单的Proxy Mesh去做occlusion query。此外,可以通过batch多个模型/包围盒去减少occlusion query阶段的draw call数量。
(16)层次z缓冲算法基本步骤Hierarachical Z-Buffer(HZB)?
(1)HZB将场景模型组织成八叉树,将zBuffer组织成金字塔。该算法在图像空间进行,八叉树使得被遮挡场景可以分层剔除,即该节点如果被遮挡,其子节点全部被遮挡。zbuffer金字塔允许允许分层进行z比较,即该层级被检测出遮挡,后面层级不用再检测了。
(2)最高层级的z金字塔为原始zbuffer,之后其他层级的z值为2x2窗口内的最大值,见下图。
(3)对八叉树以粗略的从前到后的顺序遍历,检测节点的包围盒使用上一节拓展的遮挡查询,首先测试最粗糙的z金字塔,该层级需要可以包围住包围盒的屏幕投影。之后用包围盒投影最小的z值和z-pyramid比较,若大的话,该包围盒即被遮挡了。

HZB有很多变种算法,但它们总体上可以分为三步:
1:先用一些较大的遮挡物体生成z-pyramid
2:将包围盒投影到屏幕空间,估计mip level并检测该物体是否被遮挡。
3:重复步骤2,直到达到最精细的层级或者中间检测出遮挡。
(17)HZB算法步骤2?
长的边(单位为像素)用来计算mip level
![]()
n是mip level的最大值,L为边长。max防止得到负的level,min防止超过最大层级。该步骤选择的层级中,投影的bounding volume至多覆盖2x2个深度像素,这是为了控制消耗,因为该方法本身就类似一种概率测试,所以没有理由对更多的值进行读取和测试,4个即可。
(18)HZB算法步骤3?
计算bounding volume的最小深度值。AABB,OBB,sphere等包围盒计算方式均不同。zmin至多和zbuffer中4个像素进行测试。
(19)LOD切换有几种方式?
有四种方式,第一种是离散几何LOD切换,第二种是混合LOD切换,第三种是基于边折叠的LOD切换,第四种是渐进式LOD切换。
(20)离散几何LOD切换方法?
即一个模型存储不同LOD的数据,该方法可能会带来明显的跳变现象,当然如果不同LOD的模型很相似的话,可以减缓该问题。
(21)混合LOD切换方法?
假设现在有两个LOD,当前是LOD1,想要过渡到LOD2.
Giegl的方法:
1:将不透明的LOD1写入到缓冲中(color和z)。
2:LOD2淡入,通过增加LOD2的透明度,使用over混合模式。
3:该过程中LOD1应允许深度测试而禁止深度写入,
解决:原始LOD的绘制结果通过back projection从前一帧中获取。
(22)基于边折叠的LOD切换方法?
比如基于二次度量的网格简化
1:该方法简化生成的一系列模型不一定都可行
2:单独渲染三角形比渲染整个网格代价大(draw call多)
3:如果同一个物体的不同简化版本存在于同一场景,那么每个物体都需指定其包含的三角形集合。
(23)渐进式LOD切换方法?
给出两个相邻细节层次的LOD, 顶点之间有一定对应关系。例如边折叠的过程中,折叠边关联的两个顶点合并成一个顶点。为了最小化视觉跳变,可以采用过度的方法,两个顶点可以平滑过渡到一个顶点。
(24)LOD层级确定的方法?
主要有两种方法,第一种是基于距离的层级确定(range-based),第二种是基于投影面积的层级确定(Projected Area Based)。
(25)基于距离的层级确定(range-based)?
按距离选择LOD,假如距离大于 r i r_i ri,选择LODi+1,小于则选择LODi。

(26)基于投影面积的层级确定(Projected Area Based)?
该方法是将物体的包围盒在屏幕空间中的大小选择LOD。

计算公式如上,p为屏幕空间中的半径,r为世界空间中的半径,d为摄像机lookat的方向,n为近平面,v为摄像机位置,c为球心位置。右式分母表示摄像机与球心连线的向量在d上的投影。把r移到左边,就可以把该公式看做三角形相似。20
23
22&25