liunx文本三剑客(grep,awk,sed),正则表达式
正则表达式
基础正则
| 符号 | 含义 |
|---|---|
| ^ | 以…开头 |
| $ | 以…结尾 |
| [] | 表示或者,[abc] 表示a或者b或者c ,和去除特殊字符含义 |
| * | 表示前一个字符出现0次或者多次 |
| . | 表示任意一个字符 |
| ^$ | 表示空行 |
| .* | 表示任意字符 |
| [^] | 表示取反 |
^ :以...开头
grep -n ”^p“ scan_oN.txt

* : 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
grep -n "t*“ scan_oN.txt

$ :以....为结尾
grep -n "p$" scan_oN.txt

. : 匹配任意单个字符,不能匹配空行
grep -n ".0" scan_oN.txt

^$ :匹配空行
grep -n "^$" scan_oN.txt

.* :匹配任意字符
grep -n ".*" scan_oN.txt

-v :显示不被pattern 匹配到的行,相当于[^] 反向匹配
grep -nv "^$" scan_oN.txt
不显示空行

\ :转义字符
grep -n "\.$" scan_oN.txt
查询以 . 结尾的

[] :中括号,表示匹配中括号内的任意一个字符[abc] a或b或c
注意[]还有转义字符的作用,在中括号中的特殊字符都会被转义
grep -n "[abc]" scan_oN.txt

[^] :取反的效果
grep -n "[\^abc]" scan_oN.txt
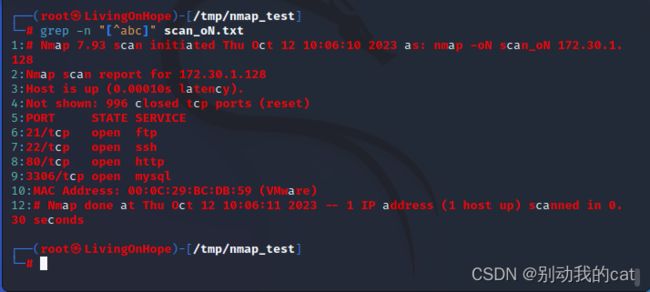
[0-9]:匹配所有包含数字的行
grep -n "[0-9]" scan_oN.txt

[a-z] :匹配所有包含小写字母的行
grep -n "[a-z]" scan_oN.txt

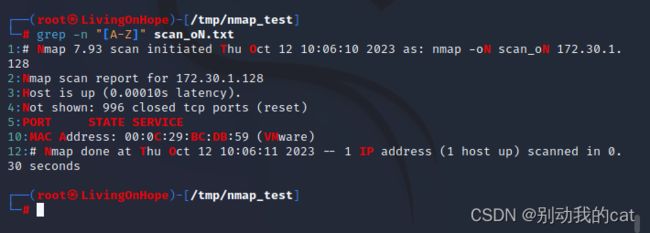
[A-Z] :匹配所有包含大写字母的行
grep -n "[A-Z]" scan_oN.txt
[a-Z0-9] 或 [a-zA-Z0-9] :匹配所有大小字母和所有数字
-i :不区分大小写
grep -n "[a-Z0-9]" scan_oN.txt
grep -n "[a-zA-Z0-9]" scan_oN.txt
grep -ni "[a-z0-9]" scan_oN.txt


[.] :中括号转义,匹配所有带点的行
grep -n "[.]" scan_oN.txt

扩展正则
| 符号 | 含义 |
|---|---|
| + | 前一个字符连续出现1次或者1次以上 |
| | | 或者 |
| () | 一个整体,sed反向引用 |
| {} | o{n,m}前一个字母o,至少连续出现n次,最多连续出现m次 |
| ? | 前一个字母连续出现0次或者1次 |
| :竖杠,表示或者的意思
egrep "ftp|ssh" scan_oN.txt

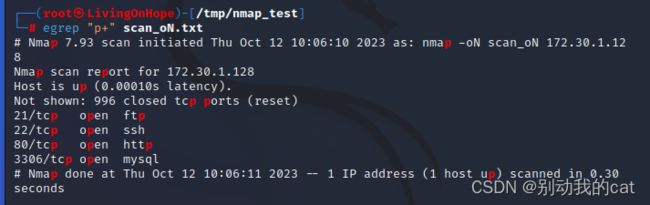
+ :表示匹配前字符1次字符或者前字符多次字符
egrep "p+" scan_oN.txt
[0-9]+ :匹配连续的数字
egrep "[0-9]+" scan_oN.txt

[a-Z]+ :匹配所有连续的字母
egrep "[a-Z]+" scan_oN.txt

-o :显示匹配结果过程
egrep -o "[a-Z]+" scan_oN.txt

() :被小括号括起来的表示为一个整体,在sed命令中是向后引用
egrep “i(n|t)” scan_oN.txt

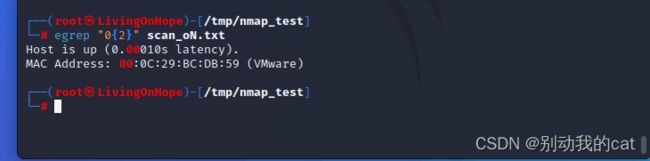
{} :o{n,m} o:表示o至少连续出现n次,m表示o最多连续出现m次
egrep "0{2,3}" scan_oN.txt

{} :o{n} o:表示o刚好连续出现了n次
egrep "0{2}" scan_oN.txt
{} :o{,m}:表示o最多连续出现了m次
egrep "0{,3}" scan_oN.txt

{} :o{n,}:表示o连续出现的次数小于等于n
egrep "0{2,}" scan_oN.txt

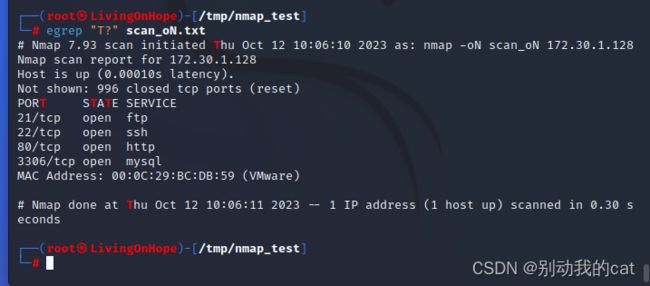
? :前一个字符至少连续出现0次或者1次
egrep "T?" scan_oN.txt
liunx文本三剑客
grep的基本使用
| 参数 | 含义 |
|---|---|
| -E | == egrep 当使用扩展正则时使用 |
| -A | -An 显示符合条件行及其后n行 |
| -B | -Bn显示符合条件行及其前n行 |
| -C | -Cn显示符合条件行及其前后n行 |
| -c | -c 统计符合条件的行数 |
| -w | 精准匹配 |
| -o | 显示匹配过程 |
| -v | 排除符合条件的行 |
| -i | 不区分大小写 |
| -n | 显示行号 |
-E :== egrep 当使用扩展正则时使用
grep -E "0{2}" scan_oN.txt

-A :-An 显示符合条件行及其后n行
grep -A5 "Nmap" scan_oN.txt

-B :-Bn 显示符合条件及其前n行
grep -B5 "Nmap" scan_oN.txt

-C :-Cn 显示符合条件及其前后n行
grep -C5 "Nmap" scan_oN.txt

-c :统计符合条件的行数
grep -c "Nmap" scan_oN.txt

-i :不区分大小
grep -i "nmap" scan_oN.txt

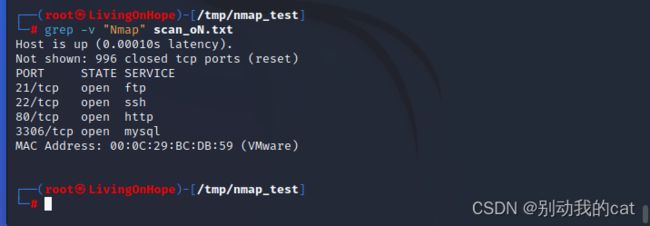
-v :排除
grep -v "Namp" scan_oN.txt
-o :显示匹配过程
grep -o "Nmap" scan_oN.txt

-w :精准匹配
grep -w "mysql" scan_oN.txt

-n :显示行号
grep -n "mysql" scan_oN.txt

sed
查找p
| 参数 | 说明 |
|---|---|
| np | n表示查找并输出显示的行数 |
| /0/p | 表示查找并输出显示符合0的行 |
| /0/,/9/p | 表示查找并输出显示符合0的行 |
| /[0-9]/p | 支持正则表达式 |
| -r | 支持扩展正则表达式 |
| -n | 只输出符合条件的行 |
sed -n '3p' scan_oN.txt
查询指定行

sed -n '/21/p' scan_oN.txt
查询包含指定内容的行

sed -n /21/,/80/p scan_oN.txt
范围过滤

sed -n '$p' scan_oN.txt
最后一行

删除d
sed '1d' scan_oN.txt
删除指定行

sed '2,4p' scan_oN.txt
删除指定范围的

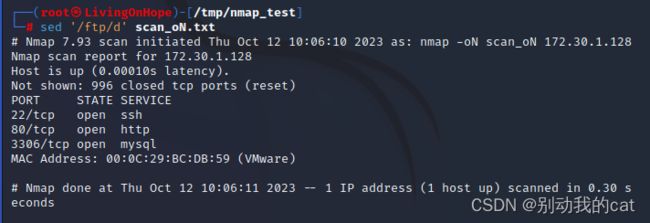
sed '/ftp/d' scan_oN.txt
删除指定内容的行
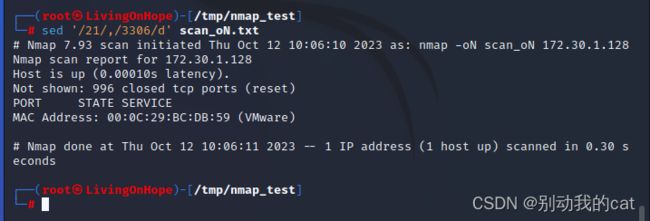
sed '/21/,/3306/d' scan_oN.txt
删除指定范围的行
增加cai
sed '2a xiao hei zi' scan_oN.txt
a在指定行后追加

sed '2i xiaoheizi' scan_oN.txt
i在指定行前插入内容

sed '2c xxxxxx' scan_oN.txt
c替换指定行内容

替换s
sed 's#MAC#YYY#g' scan_oN.txt
s 替换
g 全局替换
sed 默认替换第一个字符所有要加g
替换调指定内容

sed -nr '6s#^.*/(.*cp).*#\1#gp'
()后向引用

ip a s eth0 | sed -n '3p' | sed -nr 's#.*t (.*)/.*#\1#gp'
ip a s eth0 | sed -nr '3s#.*t (.*)/.*#\1#gp'
去ip地址案例

awk
| 命令 | 参数 |
|---|---|
| NR | NR行,NR==3 表示第三行 |
| NF | 每行有多少列,$NF 表示最后一列 |
| FS | -F分隔符,-F : 表示用:做分割符 |
| OFS | OFS输出字段分隔符,-vOFS=:表示用:做分割符输出 |
ls -l | awk NR==2{print $6}
取第二行的第6列,默认分割符为空格,连续的空格,和制表位(TAB)

ls -l | awk -F: 'NR==2{print $2}'
-F指定分割符为:

ls -l | awk -F - 'NR==2{print $NF}'
取最后一列的

ls -l | awk -F- -vOFS=: 'NR==2{print $1,$2,$3}'
指定输出分割符为:

ls -l | awk -F- "//"