机器学习——K-Means聚类
目录
1.1 过程和原理
1.1.1 过程
1.1.2 原理
1.1.3 算法流程
1.2 算法优化
1.2.1 K个聚类中心初始值的选择
1.2.2 Mini Batch K-Means
1.3 优点和缺点
1.3.1 优点
1.3.2 缺点
1.4 算法实现及应用实例
1.4.0 生成样本数据
1.4.1 K-Means
1.4.2 Mini Batch K-Means
1.1 过程和原理
1.1.1 过程
K-Means 算法是一种无监督的聚类算法,其核心思想是:对于给定的样本集,按照样本点之间的距离大小,将样本集划分为K个簇,并让簇内的点尽量紧凑,簇间的点尽量分开
算法流程图如下:

K-Means算法流程
如图,以 ![]() 为例:我们需要将图(a) 中的样本点划分为两类,则K-means聚类过程如下:
为例:我们需要将图(a) 中的样本点划分为两类,则K-means聚类过程如下:
第 1 步:从M个数据对象中任意选择2个对象作为初始聚类中心,如图(b) 所示
第 2 步:计算每个对象到这两个聚类中心的距离,把各样本划分到与它们最近的中心所代表的类别去,如图(c) 所示,并计算当前状态下的损失值
第 3 步:计算各类别所包含点的均值点,将其作为新的类别中心,如图(d) 所示
第 4 步:重复第 2 步和第 3 步,直到连续两次的损失值相差为某一设定值为止
初始聚类中心的选择是随机的,经过反复迭代第 2 步和第 3 步后,最终聚类中心会趋于稳定,如图(f) 所示;聚类中心稳定后,所有样本点的划分也会趋于稳定,从而达到比较理想的聚类效果
1.1.2 原理
K-means聚类的四个关键点:
 聚类簇数 K 值的选择:这是一个较为困难的问题,也很重要,会直接影响聚类结果,处理时主要依靠人工试探或者超参数搜索的形式来确定
聚类簇数 K 值的选择:这是一个较为困难的问题,也很重要,会直接影响聚类结果,处理时主要依靠人工试探或者超参数搜索的形式来确定
K 个聚类中心点的初始值选择:这个关键点会直接影响更新迭代次数,传统 K-Means 算法是随机在样本点中选择 K 个点作为聚类中心点的初始值
距离度量方式:样本点之间的距离度量使用较多的是欧氏距离,假设样本点的特征维度是  ,则两个 维向量
,则两个 维向量 ![]() 和
和 ![]() 之间的欧式距离为
之间的欧式距离为
![]()
损失函数的选择:聚类问题的损失函数是各个簇中样本向量到对应簇均值向量的均方误差,假设样本点 ![]() 需要被聚类成
需要被聚类成 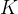 个簇
个簇 ![]() ,则各个簇内样本点的均值向量为
,则各个簇内样本点的均值向量为
![]()
其中,![]() 为簇
为簇  中包含的样本数目,所有簇的总均方误差为
中包含的样本数目,所有簇的总均方误差为
![]()
我们的目标就是最小化这个均方误差
1.1.3 算法流程
输入:待聚类样本集 ![]() ,聚类簇数 ,最大迭代次数
,聚类簇数 ,最大迭代次数 
输出:聚类好的簇 ![]()
步骤如下:
第 1 步:从数据集  中随机选择 个聚类中心,设对应向量为
中随机选择 个聚类中心,设对应向量为 ![]()
第 2 步:计算各个样本点到 个聚类中心的距离 ![]() ,将各个样本点归入离其最近的簇中
,将各个样本点归入离其最近的簇中
第 3 步:计算第 2 步得到 个簇的中心向量 ![]() ,将其作为新的聚类中心
,将其作为新的聚类中心
第 4 步:重复第 2 步和第 3 步,直到满足最大迭代次数 或所有簇的中心向量不再发生变化,输出聚类好的簇 ![]()
1.2 算法优化
1.2.1 K个聚类中心初始值的选择
K-means 算法中 个聚类中心的初始值选择会直接影响需要迭代的次数,传统的 K-means 算法是先随即从  个样本点中选择 个点作为聚类中心的初始值,但这样有较大的偶然性
个样本点中选择 个点作为聚类中心的初始值,但这样有较大的偶然性
改进方法为 k-means++,步骤如下:
第 1 步:先随机从 个样本点中选择一个样本点作为聚类中心,设其为 ![]() 然后计算各个样本点到该聚类中心的距离
然后计算各个样本点到该聚类中心的距离![]() ;选择距离最远的一个样本点,将其作为第二个聚类中心
;选择距离最远的一个样本点,将其作为第二个聚类中心 ![]()
第 2 步:计算各个样本点到已有的聚类中心的距离,并将各样本点归入离其最近的一个聚类中心
第 3 步:把到自身聚类中心最远的那个样本点作为新加入的聚类中心
第 4 步:重复第 2 步和第 3 步,直到获得 个聚类中心,然后利用这 个聚类中心作为初始聚类中心,重新开始 K-Means 算法流程
1.2.2 Mini Batch K-Means
在处理大数据样本时,传统 K-Means 非常耗时,所以提出改进版——Mini Batch K-Means算法
Mini Batch K-Means 就是在做 K-Means算法前先对大样本数据进行一个随机采样(一般是无放回的),对采样得到的样本再用 K-Means 算法进行聚类
为了提高聚类的准确性,一般进行多次 Mini Batch 后在进行多次 K-Means 聚类,最后选择最优的聚类簇
1.3 优点和缺点
1.3.1 优点
(1)原理简单,容易实现,收敛速度快,可解释性较强
(2)需要调节的参数较少(主要是聚类簇数 ),且聚类效果较好
1.3.2 缺点
(1)聚类簇数 值的选择不好把握,一般只能通过暴力搜索法来确定
(2)只适合簇型数据,对其他类型的数据聚类效果一般
(3)当数据类别严重不平衡时,聚类效果不佳
(4)当数据量较大时,计算量也增大,采用 Mini Batch K-Means的方式虽然可以缓解,但可能会牺牲准度
1.4 算法实现及应用实例
1.4.0 生成样本数据
import matplotlib.pyplot as plt
#生成数据
import numpy as np
from sklearn.datasets._samples_generator import make_blobs
X, y = make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],random_state=6)
print(X) #样本点
print(y) #簇标签
#画图
plt.scatter(X[:,0], X[:, 1], c = y)
plt.text(.99, .06, 'k = 4', transform=plt.gca().transAxes, horizontalalignment='right')
plt.show(输出:

1.4.1 K-Means
from sklearn.cluster import KMeans
k_means = KMeans(n_clusters=8,
max_iter=300,
init='k-means++',
n_init=10,
algorithm='auto',
random_state=None)
参数
n_clusters:即K值,默认为8,需要手动调试
max_iter:最大迭代次数,默认为300
init:选择初始化聚类中心的方式,可选择 k-means++ 或 random,默认k-means++
n_init:指定选择不同的初始化聚类中心运行算法的次数,默认是10,初始化会影响聚类结果,所以一般选择几组初始聚类中心进行尝试,最后选择最好的结果作为最终聚类结果
algorithm:选择距离度量算法,有 auto、full 和 elkan三种选择。默认auto,自动选择;full表示传统 K-Means算法,使用二范数度量距离;elkan 表示使用 elkan K-Means算法,当数据比较稠密时,选择该算法可以减少计算量
random_state:用于产生初始化聚类中心的随机化种子
属性
cluster_centers_:输出各个聚类中心向量
labels_:输出各个簇的标签
方法
fit(X):训练聚类模型
fit_predict(X):在 X 上执行数据集,返回样本 X 的簇标记
predict(X):预测样本集 X 中每个样本最接近的簇
程序如下:
from sklearn.metrics import adjusted_rand_score #外部指标ARI
from sklearn.metrics import adjusted_mutual_info_score #外部指标NMI
from sklearn.metrics import davies_bouldin_score #内部指标DB指数
#K-Means聚类
from sklearn.cluster import KMeans
for index, k in enumerate((1,2,3,4)):
plt.subplot(2,2,index+1) #图像布局2*2
k_means = KMeans(n_clusters=k,random_state=6) #建立模型
y_pred = k_means.fit_predict(X) #在X上执行数据集,返回样本X的簇标记
#print(y_pred)
print("K = ",k)
print("兰德指数:", adjusted_rand_score(y, y_pred))
print("标准化互信息:",adjusted_mutual_info_score(y, y_pred))
if k != 1:print("DB指数:", davies_bouldin_score(X,y_pred))
plt.scatter(X[:,0], X[:, 1], c = y_pred)
plt.text(.99, .06, 'k=%d'%k, transform=plt.gca().transAxes, horizontalalignment='right')
plt.show()结果输出:





兰德指数和标准化互信息是聚类模型评估的外部指标,越接近1,则聚类结果与真实情况越吻合
DB指数是聚类模型评估的内部指标,其值越小越好
模型评估详情:https://blog.csdn.net/T940842933/article/details/131667393?spm=1001.2014.3001.5502
1.4.2 Mini Batch K-Means
from sklearn.cluster import MiniBatchKMeans
mb_k_means = MiniBatchKMeans(n_clusters=8,
max_iter=100,
init='k-means++',
n_init=3,
init_size=None,
random_state=None,
batch_size=100,
reassignment_ratio=0.01,
max_no_improvement=10)参数
n_clusters:即K值,默认为8,需要手动调试
max_iter:最大迭代次数,默认为100
init:选择初始化聚类中心的方式,可选择 k-means++ 或 random,默认k-means++
n_init:指定选择不同的初始化聚类中心运行算法的次数,默认是3,与K-Means不同,K-Means类里的n_init是用同样的训练集数据来 " 跑 " 不同的初始化聚类中心,而Mini Batch K-Means类里的n_init每次用不同的采样数据集来 “ 跑 ” 不同的初始化聚类中心
init_size:用来做聚类中心初始值候选的样本个数,默认是batch_size的3倍
random_state:用于产生初始化聚类中心的随机化种子
batch_size:采用得到的各个小批量样本中包含的样本数目,默认为100
reassignment_ratio:某个聚类中心被重新赋值的次数占所有聚类中心被重新赋值的次数的比例,默认为0.01
max_no_improvement:当连续多少个Mini Batch没有改善聚类效果时,就停止算法,用于控制算法运行时间,默认为10
属性
cluster_centers_:输出各个聚类中心向量
labels_:输出各个簇的标签
方法
fit(X):训练聚类模型
fit_predict(X):在 X 上执行数据集,返回样本 X 的簇标记
predict(X):预测样本集 X 中每个样本最接近的簇
partial_fit(X):在单个Mini Batch上更新 K-Means
程序如下:
#Mini Batch K-Means聚类
from sklearn.cluster import MiniBatchKMeans
for index, k in enumerate((1,2,3,4)):
plt.subplot(2,2,index+1) #图像布局2*2
mb_k_means = MiniBatchKMeans(n_clusters=k,random_state=6) #建立模型
y_pred = mb_k_means.fit_predict(X) #在X上执行数据集,返回样本X的簇标记
#print(y_pred)
print("K = ",k)
print("聚类中心向量:", mb_k_means.cluster_centers_)
print("簇标签:", mb_k_means.labels_[:10])
print("更新K-Means:",mb_k_means.partial_fit(X))
print("兰德指数:", adjusted_rand_score(y, y_pred))
print("标准化互信息:",adjusted_mutual_info_score(y, y_pred))
if k != 1:print("DB指数:", davies_bouldin_score(X,y_pred))
plt.scatter(X[:,0], X[:, 1], c = y_pred)
plt.text(.99, .06, 'k=%d'%k, transform=plt.gca().transAxes, horizontalalignment='right')
plt.show()结果输出:





由于样本数量只有1000,聚类簇数最大只有4,所以还无法体现 Mini Batch K-Means 算法的优势,感兴趣的朋友可以更改生成样本数据函数的参数,再对两个算法进行对比
完整代码:
import matplotlib.pyplot as plt
#生成数据
import numpy as np
from sklearn.datasets._samples_generator import make_blobs
X, y = make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],random_state=6)
print(X) #样本点
print(y) #簇标签
plt.scatter(X[:,0], X[:, 1], c = y)
plt.text(.99, .06, 'k = 4', transform=plt.gca().transAxes, horizontalalignment='right')
plt.show()
from sklearn.metrics import adjusted_rand_score #外部指标ARI
from sklearn.metrics import adjusted_mutual_info_score #外部指标NMI
from sklearn.metrics import davies_bouldin_score #内部指标DB指数
#K-Means聚类
from sklearn.cluster import KMeans
for index, k in enumerate((1,2,3,4)):
plt.subplot(2,2,index+1) #图像布局2*2
k_means = KMeans(n_clusters=k,random_state=6) #建立模型
y_pred = k_means.fit_predict(X) #在X上执行数据集,返回样本X的簇标记
#print(y_pred)
print("K = ",k)
print("聚类中心向量:", k_means.cluster_centers_)
print("簇标签:", k_means.labels_[:10])
print("兰德指数:", adjusted_rand_score(y, y_pred))
print("标准化互信息:",adjusted_mutual_info_score(y, y_pred))
if k != 1:print("DB指数:", davies_bouldin_score(X,y_pred))
plt.scatter(X[:,0], X[:, 1], c = y_pred)
plt.text(.99, .06, 'k=%d'%k, transform=plt.gca().transAxes, horizontalalignment='right')
plt.show()
#Mini Batch K-Means聚类
from sklearn.cluster import MiniBatchKMeans
for index, k in enumerate((1,2,3,4)):
plt.subplot(2,2,index+1) #图像布局2*2
mb_k_means = MiniBatchKMeans(n_clusters=k,random_state=6) #建立模型
y_pred = mb_k_means.fit_predict(X) #在X上执行数据集,返回样本X的簇标记
#print(y_pred)
print("K = ",k)
print("聚类中心向量:", mb_k_means.cluster_centers_)
print("簇标签:", mb_k_means.labels_[:10])
print("更新K-Means:",mb_k_means.partial_fit(X))
print("兰德指数:", adjusted_rand_score(y, y_pred))
print("标准化互信息:",adjusted_mutual_info_score(y, y_pred))
if k != 1:print("DB指数:", davies_bouldin_score(X,y_pred))
plt.scatter(X[:,0], X[:, 1], c = y_pred)
plt.text(.99, .06, 'k=%d'%k, transform=plt.gca().transAxes, horizontalalignment='right')
plt.show()