apply、applymap、transform、agg在dataframe中的用法
文章目录
-
-
- apply()
- map()
- applymap()
- transform()
- agg()
-
apply()
dataframe的apply方法的官方文档
其用法为pandas.DataFrame.apply(self, func, axis=0, raw=False, result_type=None)
agg可以做的,好像apply都可以做,所以apply比agg更加灵活,更一般化,但是调用Python内置函数和pandas函数时,运行速度比agg慢。
不同的是apply还能向用户自定义函数中传递参数,而且支持在同一个dataframe的不同series间进行运算,当应用的不是聚合函数时,就是对每个元素的逐一操作。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity='all'
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randint(90,100,size=(3,3)),columns=list('edg'))
df
#计算各列数据总和并作为新列添加到末尾
df['Col_sum'] = df.apply(lambda x: x.sum(), axis=1)
#计算各行数据总和并作为新行添加到末尾
df.loc['Row_sum'] = df.apply(lambda x: x.sum())
df

map()
map()是python自带的方法,可以在DataFrame中对具体的某一列使用.map()后缀的方式调用,对整个DataFrame使用会报错,不能使用聚合函数。常用的是数据类型转换,比如int转换为float类型,也可以用map()+lambda编写函数。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity='all'
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randint(90,100,size=(3,3)),columns=list('edg'))
df
df['e'].map(float)
df['d'].map(lambda x:x+3)
输出结果:

applymap()
applymap先应用apply再对每个Series使用map,可实现逐个元素操作。
apply 让函数作用于列或者行,applymap可以作用于每一个元素,map主要作用于series上的元素。applymap()是pandas里DataFrame的方法,它对DataFrame中的所有元素应用操作,不能使用聚合函数。
##jupyter中打印所有结果的解决办法
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity='all'
import pandas as pd
import numpy as np
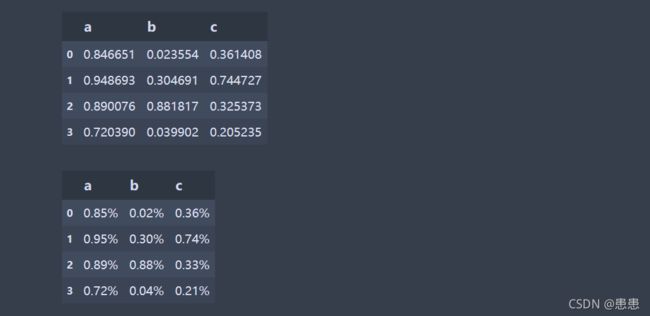
df = pd.DataFrame(np.random.rand(4, 3), columns = list('abc'))
df
#注意使用applymap()可以格式化字符串,使用apply()会报错,可采用函数的方法达到相同的目的。
func = lambda x: f'{x:.2f}%'
df.applymap(func)
输出如下:
transform()
transform方法可以被groupby、resampler、dataframe、series等对象调用。
groupby的transform方法的官方文档
其用法为pandas.DataFrame.transform(self, func, axis=0, *args, **kwargs)
其特点是,按元素进行操作,所以输入dataframe与输出dataframe的大小完全相同。
本方法同样支持对不同的轴调用不同的函数,以及通过字符串形式调用内置函数。
transform可以实现的操作,apply都可以,但是反之不成立。同agg一样,与内建函数一起使用时,比apply速度快。
在groupby对象中执行函数时,会同时使用元素的信息和所在组的信息。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity='all'
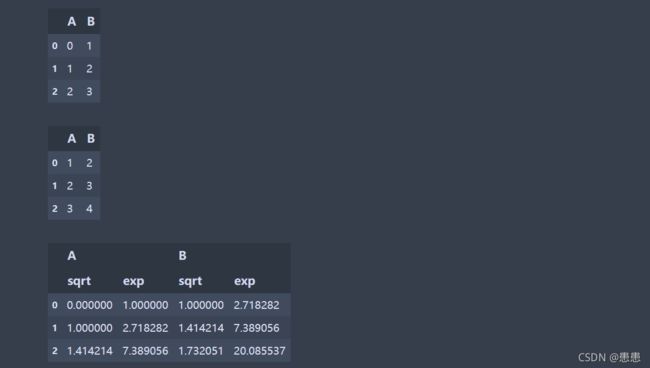
df = pd.DataFrame({'A': range(3), 'B': range(1, 4)})
df
df.transform(lambda x: x + 1)
#transform使用多个自定义函数
df = pd.DataFrame({'A': range(3), 'B': range(1, 4)})
trans=df.transform([np.sqrt, np.exp])
trans
输出结果:
总结:transform方法与apply很像,但是对使用的函数有一定限制:
它可以产生一个和输入组形状相同的对象,但是它不能修改输入
agg()
agg()属于DataFrame、Series对象的方法,可与聚合函数一起使用,例如sum、avg、count等
#对dataframe指定列进行指定的聚合运算
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']})
#输出:
A B
max NaN 8.0
min 1.0 2.0
sum 12.0 NaN