数据预处理(超详细)
import pandas as pd
import numpy as np
【例5-1】使用read_csv函数读取CSV文件。
df1 = pd.read_csv("sunspots.csv")
#读取CSV文件到DataFrame中
print(df1.sample(5))
df2 = pd.read_table("sunspots.csv",sep = ",")
#使用read_table,并指定分隔符
print("------------------")
print(df2.sample(5))
df3 = pd.read_csv("sunspots.csv",names = ["a","b"])
#文件不包含表头行,允许自动分配默认列名,也可以指定列名
print("------------------")
print(df3.sample(5))
year counts 1 1701 11.0 262 1962 37.5 35 1735 34.0 66 1766 11.4 72 1772 66.5 ------------------ year counts 216 1916 57.1 43 1743 16.0 196 1896 41.8 7 1707 20.0 212 1912 3.6 ------------------ a b 269 1968 105.9 60 1759 54 33 1732 11 0 year counts 75 1774 30.6
【例5-2】读取excel文件。
xlsx = "data_test.xlsx"
df1 = pd.read_excel(xlsx,"Sheet1")
print(df1)
#也可以直接利用:
df2 = pd.read_excel("data_test.xlsx","Sheet1")
print("-------------------------------")
print(df2)
00101 长裤 黑色 89 0 1123 上衣 红色 129 1 1010 鞋子 蓝色 150 2 100 内衣 灰色 100 ------------------------------- 00101 长裤 黑色 89 0 1123 上衣 红色 129 1 1010 鞋子 蓝色 150 2 100 内衣 灰色 100
【例5-3】merge的默认合并数据。
price = pd.DataFrame({'fruit':['apple','grape','orange','orange'],
'price':[8,7,9,11]})
amount = pd.DataFrame({'fruit':['apple','grape','orange'],'amout':[5,11,8]})
display(price,amount,pd.merge(price,amount))
| fruit | price | |
|---|---|---|
| 0 | apple | 8 |
| 1 | grape | 7 |
| 2 | orange | 9 |
| 3 | orange | 11 |
| fruit | amout | |
|---|---|---|
| 0 | apple | 5 |
| 1 | grape | 11 |
| 2 | orange | 8 |
| fruit | price | amout | |
|---|---|---|---|
| 0 | apple | 8 | 5 |
| 1 | grape | 7 | 11 |
| 2 | orange | 9 | 8 |
| 3 | orange | 11 | 8 |
【例5-4】指定合并时的列名。
display(pd.merge(price,amount,left_on = 'fruit',right_on = 'fruit'))
| fruit | price | amout | |
|---|---|---|---|
| 0 | apple | 8 | 5 |
| 1 | grape | 7 | 11 |
| 2 | orange | 9 | 8 |
| 3 | orange | 11 | 8 |
【例5-5】左连接。
display(pd.merge(price,amount,how = 'left'))
| fruit | price | amout | |
|---|---|---|---|
| 0 | apple | 8 | 5 |
| 1 | grape | 7 | 11 |
| 2 | orange | 9 | 8 |
| 3 | orange | 11 | 8 |
【例5-6】右连接。
display(pd.merge(price,amount,how = 'right'))
| fruit | price | amout | |
|---|---|---|---|
| 0 | apple | 8 | 5 |
| 1 | grape | 7 | 11 |
| 2 | orange | 9 | 8 |
| 3 | orange | 11 | 8 |
【例5-7】merge通过多个键合并。
left = pd.DataFrame({'key1':['one','one','two'],'key2':['a','b','a'],'value1':range(3)})
right = pd.DataFrame({'key1':['one','one','two','two'],'key2':['a','a','a','b'],'value2':range(4)})
display(left,right,pd.merge(left,right,on = ['key1','key2'],how = 'left'))
| key1 | key2 | value1 | |
|---|---|---|---|
| 0 | one | a | 0 |
| 1 | one | b | 1 |
| 2 | two | a | 2 |
| key1 | key2 | value2 | |
|---|---|---|---|
| 0 | one | a | 0 |
| 1 | one | a | 1 |
| 2 | two | a | 2 |
| 3 | two | b | 3 |
| key1 | key2 | value1 | value2 | |
|---|---|---|---|---|
| 0 | one | a | 0 | 0.0 |
| 1 | one | a | 0 | 1.0 |
| 2 | one | b | 1 | NaN |
| 3 | two | a | 2 | 2.0 |
【例5-8】merge函数中参数suffixes的应用。
print(pd.merge(left,right,on = 'key1'))
print(pd.merge(left,right,on = 'key1',suffixes = ('_left','_right')))
key1 key2_x value1 key2_y value2 0 one a 0 a 0 1 one a 0 a 1 2 one b 1 a 0 3 one b 1 a 1 4 two a 2 a 2 5 two a 2 b 3 key1 key2_left value1 key2_right value2 0 one a 0 a 0 1 one a 0 a 1 2 one b 1 a 0 3 one b 1 a 1 4 two a 2 a 2 5 two a 2 b 3
【例5-9】两个Series的数据连接。
s1 = pd.Series([0,1],index = ['a','b'])
s2 = pd.Series([2,3,4],index = ['a','d','e'])
s3 = pd.Series([5,6],index = ['f','g'])
print(pd.concat([s1,s2,s3])) #Series行合并
a 0 b 1 a 2 d 3 e 4 f 5 g 6 dtype: int64
【例5-10】两个DataFrame的数据连接。
data1 = pd.DataFrame(np.arange(6).reshape(2,3),columns = list('abc'))
data2 = pd.DataFrame(np.arange(20,26).reshape(2,3),columns = list('ayz'))
data = pd.concat([data1,data2],axis = 0,sort=False)
display(data1,data2,data)
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| a | y | z | |
|---|---|---|---|
| 0 | 20 | 21 | 22 |
| 1 | 23 | 24 | 25 |
| a | b | c | y | z | |
|---|---|---|---|---|---|
| 0 | 0 | 1.0 | 2.0 | NaN | NaN |
| 1 | 3 | 4.0 | 5.0 | NaN | NaN |
| 0 | 20 | NaN | NaN | 21.0 | 22.0 |
| 1 | 23 | NaN | NaN | 24.0 | 25.0 |
【例5-11】指定索引顺序。
s1 = pd.Series([0,1],index = ['a','b'])
s2 = pd.Series([2,3,4],index = ['a','d','e'])
s3 = pd.Series([5,6],index = ['f','g'])
s4 = pd.concat([s1*5,s3],sort=False)
s5 = pd.concat([s1,s4],axis = 1,sort=False)
s6 = pd.concat([s1,s4],axis = 1,join = 'inner',sort=False)
s7 = pd.concat([s1,s4],axis = 1,join = 'inner',join_axes = [['b','a']],sort=False)
display(s4,s5,s6,s7)
a 0
b 5
f 5
g 6
dtype: int64
| 0 | 1 | |
|---|---|---|
| a | 0.0 | 0 |
| b | 1.0 | 5 |
| f | NaN | 5 |
| g | NaN | 6 |
| 0 | 1 | |
|---|---|---|
| a | 0 | 0 |
| b | 1 | 5 |
| 0 | 1 | |
|---|---|---|
| b | 1 | 5 |
| a | 0 | 0 |
【例5-12】使用combine_first合并。
s6.combine_first(s5)
| 0 | 1 | |
|---|---|---|
| a | 0.0 | 0.0 |
| b | 1.0 | 5.0 |
| f | NaN | 5.0 |
| g | NaN | 6.0 |
【例5-13】利用isnull检测缺失值。
import numpy as np
import pandas as pd
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
print(string_data)
string_data.isnull()
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object0 False
1 False
2 True
3 False
dtype: bool
【例5-14】None值也会被当做NA处理。
string_data = pd.Series(['aardvark', 'artichoke',None, 'avocado'])
string_data.isnull()
0 False 1 False 2 True 3 False dtype: bool
【例5-15】利用isnull().sum()统计缺失值。
df = pd.DataFrame(np.arange(12).reshape(3,4),columns = ['A','B','C','D'])
df.iloc[2,:] = np.nan
df[3] = np.nan
print(df)
df.isnull().sum()
A B C D 3 0 0.0 1.0 2.0 3.0 NaN 1 4.0 5.0 6.0 7.0 NaN 2 NaN NaN NaN NaN NaN A 1 B 1 C 1 D 1 3 3 dtype: int64
【例5-16】用info方法查看DataFrame的缺失值。
df.info()
RangeIndex: 3 entries, 0 to 2 Data columns (total 5 columns): A 2 non-null float64 B 2 non-null float64 C 2 non-null float64 D 2 non-null float64 3 0 non-null float64 dtypes: float64(5) memory usage: 248.0 bytes
【例5-17】Series的dropna用法。
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
print(data)
print(data.dropna())
0 1.0 1 NaN 2 3.5 3 NaN 4 7.0 dtype: float64 0 1.0 2 3.5 4 7.0 dtype: float64
【例5-18】布尔型索引选择过滤非缺失值。
not_null = data.notnull()
print(not_null)
print(data[not_null])
0 True
1 False
2 True
3 False
4 True
dtype: bool
0 1.0
2 3.5
4 7.0
dtype: float64
【例5-19】DataFrame对象的dropna默认参数使用。
from numpy import nan as NA
data = pd.DataFrame([[1., 5.5, 3.], [1., NA, NA],[NA, NA, NA],
[NA, 5.5, 3.]])
print(data)
cleaned = data.dropna()
print('删除缺失值后的:\n',cleaned)
0 1 2 0 1.0 5.5 3.0 1 1.0 NaN NaN 2 NaN NaN NaN 3 NaN 5.5 3.0 删除缺失值后的: 0 1 2 0 1.0 5.5 3.0
【例5-20】传入参数all。
data = pd.DataFrame([[1., 5.5, 3.], [1., NA, NA],[NA, NA, NA],
[NA, 5.5, 3.]])
print(data)
data.dropna(how='all')
0 1 2 0 1.0 5.5 3.0 1 1.0 NaN NaN 2 NaN NaN NaN 3 NaN 5.5 3.0
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | 5.5 | 3.0 |
| 1 | 1.0 | NaN | NaN |
| 3 | NaN | 5.5 | 3.0 |
【例5-21】dropna中的axis参数应用。
df = pd.DataFrame([[1., 5.5, NA], [1., NA, NA],[NA, NA, NA], [NA, 5.5, NA]])
print(df)
df.dropna(axis = 1, how = 'all')
0 1 2 0 1.0 5.5 NaN 1 1.0 NaN NaN 2 NaN NaN NaN 3 NaN 5.5 NaN
| 0 | 1 | |
|---|---|---|
| 0 | 1.0 | 5.5 |
| 1 | 1.0 | NaN |
| 2 | NaN | NaN |
| 3 | NaN | 5.5 |
【例5-22】dropna中的thresh参数应用。
df = pd.DataFrame(np.random.randn(7, 3))
df.iloc[:4, 1] = NA
df.iloc[:2, 2] = NA
print(df)
df.dropna(thresh=2)
0 1 2 0 -0.506363 NaN NaN 1 0.109888 NaN NaN 2 -1.102190 NaN 0.399151 3 0.757800 NaN 1.170835 4 0.350187 -0.315094 -2.319175 5 0.056101 0.256769 0.438723 6 -0.128135 -0.141123 -0.945234
| 0 | 1 | 2 | |
|---|---|---|---|
| 2 | -1.102190 | NaN | 0.399151 |
| 3 | 0.757800 | NaN | 1.170835 |
| 4 | 0.350187 | -0.315094 | -2.319175 |
| 5 | 0.056101 | 0.256769 | 0.438723 |
| 6 | -0.128135 | -0.141123 | -0.945234 |
【例5-23】通过字典形式填充缺失值。
df = pd.DataFrame(np.random.randn(5,3))
df.loc[:3,1] = NA
df.loc[:2,2] = NA
print(df)
df.fillna({1:0.88,2:0.66})
0 1 2 0 -0.889385 NaN NaN 1 0.672471 NaN NaN 2 1.515747 NaN NaN 3 0.000104 NaN 0.212531 4 -1.993694 1.385779 -0.870010
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -0.889385 | 0.880000 | 0.660000 |
| 1 | 0.672471 | 0.880000 | 0.660000 |
| 2 | 1.515747 | 0.880000 | 0.660000 |
| 3 | 0.000104 | 0.880000 | 0.212531 |
| 4 | -1.993694 | 1.385779 | -0.870010 |
【例5-24】fillna中method的应用。
df = pd.DataFrame(np.random.randn(6, 3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
print(df)
df.fillna(method = 'ffill')
0 1 2 0 0.756464 0.443256 -0.658759 1 0.919615 0.492780 0.993361 2 1.362813 NaN -0.515228 3 -1.114843 NaN -0.622650 4 0.496363 NaN NaN 5 0.647327 NaN NaN
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0.756464 | 0.443256 | -0.658759 |
| 1 | 0.919615 | 0.492780 | 0.993361 |
| 2 | 1.362813 | 0.492780 | -0.515228 |
| 3 | -1.114843 | 0.492780 | -0.622650 |
| 4 | 0.496363 | 0.492780 | -0.622650 |
| 5 | 0.647327 | 0.492780 | -0.622650 |
【例5-25】用Series的均值填充。
series= pd.Series([1., NA, 3.5, NA, 7])
series.fillna(data.mean())
0 1.0 1 5.5 2 3.5 3 NaN 4 7.0 dtype: float64
【例5-26】DataFrame中用均值填充。
df = pd.DataFrame(np.random.randn(4, 3))
df.iloc[2:, 1] = NA
df.iloc[3:, 2] = NA
print(df)
df[1] = df[1].fillna(df[1].mean())
print(df)
0 1 2 0 0.209804 -0.308095 1.773856 1 -1.021306 2.082047 -0.396020 2 0.835592 NaN -1.363282 3 -1.253210 NaN NaN 0 1 2 0 0.209804 -0.308095 1.773856 1 -1.021306 2.082047 -0.396020 2 0.835592 0.886976 -1.363282 3 -1.253210 0.886976 NaN
【例5-27】判断DataFrame中的重复数据。
data = pd.DataFrame({ 'k1':['one','two'] * 3 + ['two'],'k2':[1, 1, 2, 3, 1, 4, 4] ,'k3':[1,1,5,2,1, 4, 4] })
print(data)
data.duplicated()
k1 k2 k3 0 one 1 1 1 two 1 1 2 one 2 5 3 two 3 2 4 one 1 1 5 two 4 4 6 two 4 4 0 False 1 False 2 False 3 False 4 True 5 False 6 True dtype: bool
【例5-28】每行各个字段都相同时去重。
data.drop_duplicates()
| k1 | k2 | k3 | |
|---|---|---|---|
| 0 | one | 1 | 1 |
| 1 | two | 1 | 1 |
| 2 | one | 2 | 5 |
| 3 | two | 3 | 2 |
| 5 | two | 4 | 4 |
【例5-29】指定部分列重复时去重。
data.drop_duplicates(['k2','k3'])
| k1 | k2 | k3 | |
|---|---|---|---|
| 0 | one | 1 | 1 |
| 2 | one | 2 | 5 |
| 3 | two | 3 | 2 |
| 5 | two | 4 | 4 |
【例5-30】去重时保留最后出现的记录。
data.drop_duplicates(['k2','k3'],keep = 'last')
| k1 | k2 | k3 | |
|---|---|---|---|
| 2 | one | 2 | 5 |
| 3 | two | 3 | 2 |
| 4 | one | 1 | 1 |
| 6 | two | 4 | 4 |
【例5-31】利用散点图检测异常值。
import matplotlib.pyplot as plot
wdf = pd.DataFrame(np.arange(20),columns = ['W'])
wdf['Y'] = wdf['W']*1.5+2
wdf.iloc[3,1] = 128
wdf.iloc[18,1] = 150
wdf.plot(kind = 'scatter',x = 'W',y = 'Y')
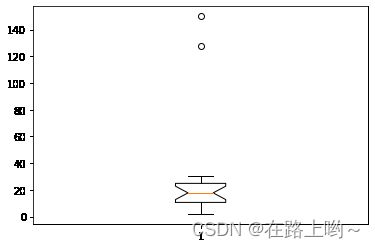
【例5-32】利用箱线图分析异常值。
import matplotlib.pyplot as plt
plt.boxplot(wdf['Y'].values,notch = True)
{'whiskers': [, ], 'caps': [ , ], 'boxes': [ ], 'medians': [ ], 'fliers': [ ], 'means': []}
【例5-33】利用3σ法则检测异常值。
def outRange(S):
blidx = (S.mean()-3*S.std()>S)|(S.mean()+3*S.std()<S)
idx = np.arange(S.shape[0])[blidx]
outRange = S.iloc[idx]
return outRange
outier = outRange(wdf['Y'])
outier
18 150.0 Name: Y, dtype: float64
【例5-34】replace替换数据值。
data = {'姓名':['李红','小明','马芳','国志'],'性别':['0','1','0','1'],
'籍贯':['北京','甘肃','','上海']}
df = pd.DataFrame(data)
df = df.replace('','不详')
print(df)
姓名 性别 籍贯
0 李红 0 北京
1 小明 1 甘肃
2 马芳 0 不详
3 国志 1 上海
【例5-35】replace传入列表实现多值替换。
df = df.replace(['不详','甘肃'],['兰州','兰州'])
print(df)
姓名 性别 籍贯 0 李红 0 北京 1 小明 1 兰州 2 马芳 0 兰州 3 国志 1 上海
【例5-36】 replace传入字典实现多值替换
df = df.replace({'1':'男','0':'女'})
print(df)
姓名 性别 籍贯 0 李红 女 北京 1 小明 男 兰州 2 马芳 女 兰州 3 国志 男 上海
【例5-37】map方法映射数据。
data = {'姓名':['李红','小明','马芳','国志'],'性别':['0','1','0','1'],
'籍贯':['北京','兰州','兰州','上海']}
df = pd.DataFrame(data)
df['成绩'] = [58,86,91,78]
print(df)
def grade(x):
if x>=90:
return '优'
elif 70<=x<90:
return '良'
elif 60<=x<70:
return '中'
else:
return '差'
df['等级'] = df['成绩'].map(grade)
print("-----------------------------------")
print(df)
姓名 性别 籍贯 成绩 0 李红 0 北京 58 1 小明 1 兰州 86 2 马芳 0 兰州 91 3 国志 1 上海 78 ----------------------------------- 姓名 性别 籍贯 成绩 等级 0 李红 0 北京 58 差 1 小明 1 兰州 86 良 2 马芳 0 兰州 91 优 3 国志 1 上海 78 良
【例5-38】数据的离差标准化。
def MinMaxScale(data):
data = (data-data.min())/(data.max()-data.min())
return data
x = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
print('原始数据为:\n',x)
x_scaled = MinMaxScale(x)
print('标准化后矩阵为:\n',x_scaled,end = '\n')
原始数据为: [[ 1. -1. 2.] [ 2. 0. 0.] [ 0. 1. -1.]] 标准化后矩阵为: [[0.66666667 0. 1. ] [1. 0.33333333 0.33333333] [0.33333333 0.66666667 0. ]]
【例5-39】数据的标准差标准化。
def StandardScale(data):
data = (data-data.mean())/data.std()
return data
x = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
print('原始数据为:\n',x)
x_scaled = StandardScale(x)
print('标准化后矩阵为:\n',x_scaled,end = '\n')
原始数据为: [[ 1. -1. 2.] [ 2. 0. 0.] [ 0. 1. -1.]] 标准化后矩阵为: [[ 0.52128604 -1.35534369 1.4596009 ] [ 1.4596009 -0.41702883 -0.41702883] [-0.41702883 0.52128604 -1.35534369]]
【例5-40】数据的哑变量处理。
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize','class label']
print(df)
pd.get_dummies(df)
color size prize class label 0 green M 10.1 class1 1 red L 13.5 class2 2 blue XL 15.3 class1
| prize | color_blue | color_green | color_red | size_L | size_M | size_XL | class label_class1 | class label_class2 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 10.1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 13.5 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 2 | 15.3 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
【例5-41】cut方法应用。
np.random.seed(666)
score_list = np.random.randint(25, 100, size = 10)
print('原始数据:\n',score_list)
bins = [0, 59, 70, 80, 100]
score_cut = pd.cut(score_list, bins)
print(pd.value_counts(score_cut))
# 统计每个区间人数
原始数据: [27 70 55 87 95 98 55 61 86 76] (80, 100] 4 (0, 59] 3 (59, 70] 2 (70, 80] 1 dtype: int64
例5-42 泰坦尼克数据集中的年龄字段进行分组转换为分类特征
如(<=12,儿童)、(<=18,青少年)、(<=60,成人)、(>60,老人)
import seaborn as sns
import sys
# 导入泰坦尼克数据集
df = sns.load_dataset('titanic')
display(df.head())
df['ageGroup']=pd.cut(
df['age'],
bins=[0, 13, 19, 61, sys.maxsize],
labels=['儿童', '青少年', '成人', '老人']
)
# sys.maxsize是指可以存储的最大值
display(df.head())
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | ageGroup | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False | 成人 |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False | 成人 |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True | 成人 |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False | 成人 |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True | 成人 |
【例5-43】等频法离散化连续型数据。
def SameRateCut(data,k):
k = 2
w = data.quantile(np.arange(0,1+1.0/k,1.0/k))
data = pd.cut(data,w)
return data
result = SameRateCut(pd.Series(score_list),3)
result.value_counts()
(73.0, 98.0] 5 (27.0, 73.0] 4 dtype: int64