HDFS高级-架构原理
文章目录
-
-
- 1 HDFS架构剖析
-
- 1.1 集群角色介绍
- 1.2 HDFS重要特性
- 2 HDFS Web Interfaces
-
- 2.1 模块功能解读
-
- Overview
- datanodes
- Datanode Volume Failures
- Snapshot
- Satartup progress
- Utilities
-
- Browse the file system
- Logs、Log Level
- Configruation
- 3 HDFS读写流程
-
- 3.1 HDFS写数据流程(上传文件)
- 3.2 HDFS读数据流程(下载文件)
- 4 NameNode元数据管理
-
- 4.1 元数据概述
- 4.2 元数据管理相关目录文件
- 4.3 SecondaryNameNode
-
- 4.3.1 SNN Checkpoint
- 4.4 NameNode元数据恢复
- 5 HDFS小文件解决方案
-
- 5.1 Hadoop Archive文件归档
- 5.2 Sequence File序列化文件
-
1 HDFS架构剖析
整体概述:
- HDFS是Hadoop Distribute File System 的简称,意为:Hadoop分布式文件系统。
- HDFS是Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。
- HDFS解决的问题就是大数据如何存储,它是横跨在多台计算机上的文件存储系统并且具有高度的容错能力。
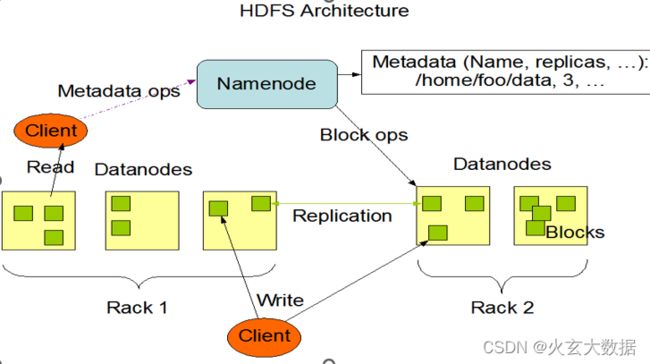
架构图:
- HDFS集群遵循主从架构(master/slave)。通常包括一个主节点和多个从节点。
- 在内部,文件分块存储,每个块根据复制因子存储在不同的从节点计算机上形成备份。
- 主节点存储和管理文件系统namespace,即有关文件块的信息,例如块位置,权限等;从节点存储文件的数据块。
- 主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。
1.1 集群角色介绍
主角色:namenode
-
NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
-
NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
-
基于此,NameNode成为了访问HDFS的唯一入口。
-
NameNode内部通过内存和磁盘文件两种方式管理元数据。
-
其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log(Journal)编辑日志。
-
在Hadoop2之前,NameNode是单点故障。Hadoop 2中引入的高可用性。Hadoop群集体系结构允许在群集中以热备配置运行两个或多个NameNode。
职责:
- NameNode是HDFS的核心,集群的主角色,被称为Master。
- NameNode仅存储管理HDFS的元数据:文件系统namespace操作维护目录树,文件和块的位置信息。
- NameNode不存储实际数据或数据集。数据本身实际存储在DataNodes中。
- NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
- NameNode并不持久化存储每个文件中各个块所在的DataNode的位置信息,这些信息会在系统启动时从DataNode汇报中重建。
- NameNode对于HDFS至关重要,当NameNode关闭时,HDFS / Hadoop集群无法访问。
- NameNode是Hadoop集群中的单点故障。
- NameNode所在机器通常会配置有大量内存(RAM)。
从角色:datanode
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
- DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。
职责:
- DataNode负责将实际数据存储在HDFS中。是集群的从角色,被称为Slave。
- DataNode启动时,它将自己发布到NameNode并汇报自己负责持有的块列表。
- 根据NameNode的指令,执行块的创建、复制、删除操作。
- DataNode会定期(dfs.heartbeat.interval配置项配置,默认是3秒)向NameNode发送心跳,如果NameNode长时间没有接受到DataNode发送的心跳, NameNode就会认为该DataNode失效。
- DataNode会定期向NameNode进行自己持有的数据块信息汇报,汇报时间间隔取参数dfs.blockreport.intervalMsec,参数未配置的话默认为6小时.
- DataNode所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode中。
主角色辅助角色:secondarynamenode
- 除了DataNode和NameNode之外,还有另一个守护进程,它称为secondaryNameNode。充当NameNode的辅助节点,但不能替代NameNode。
- 当NameNode启动时,NameNode合并Fsimage和edits log文件以还原当前文件系统名称空间。如果edits log过大不利于加载,Secondary NameNode就辅助NameNode从NameNode下载Fsimage文件和edits log文件进行合并。
注意:要是namenode挂了,secondary namenode是不能够当作namenode进行使用的,因为secondary namenode中没有元数据更新机制。
1.2 HDFS重要特性
主从架构
- HDFS采用master/slave架构。一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
- Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
分块存储机制
- HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。默认大小是128M(134217728)。
副本机制
- 文件的所有block都会有副本。每个文件的block大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
- 默认dfs.replication的值是3,也就是会额外再复制2份,连同本身总共3份副本。
namespace
- HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
- Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
- HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
- 文件自身属性信息:文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
- 文件块位置映射信息:记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
数据块管理
- 文件的各个block的具体存储管理由DataNode节点承担。每一个block都可以在多个DataNode上存储。
2 HDFS Web Interfaces
概述:
- 除了命令行界面之外,Hadoop还为HDFS提供了Web用户界面。用户可以通过Web界面操作文件系统并且获取和HDFS相关的状态属性信息。
- HDFS Web地址是http://nn_host:port/,默认端口号9870。
2.1 模块功能解读
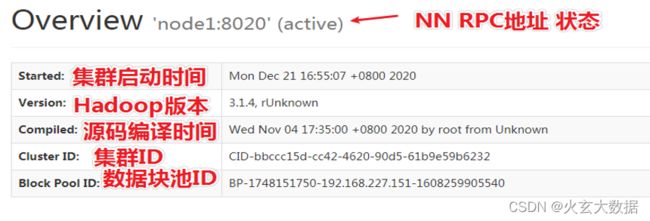
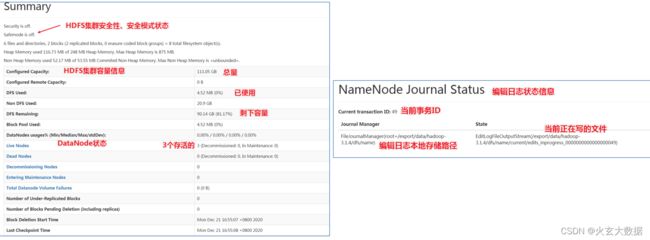
Overview
- Overview是HDFS web默认的主页面。展示了HDFS一些最核心的信息,概括性的信息。
- 具体包括Summary、NameNodeJournal Status、NameNode Storage、DFS Storage Types。

datanodes
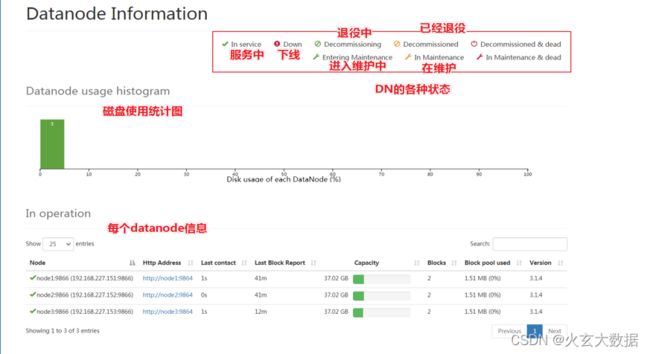
- Datanodes模块主要记录了HDFS集群中各个DataNode的相关状态信息。
Datanode Volume Failures
- 此模块记录了DataNode卷故障信息。
Snapshot
- Snapshot模块记录HDFS文件系统的快照相关信息,包括哪些文件夹创建了快照和总共有哪些快照。
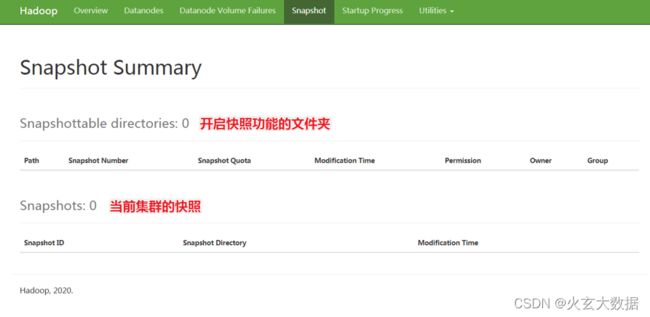
Satartup progress
- Startup Progress模块记录了HDFS集群启动的过程信息,执行步骤和每一步所做的事和用时。
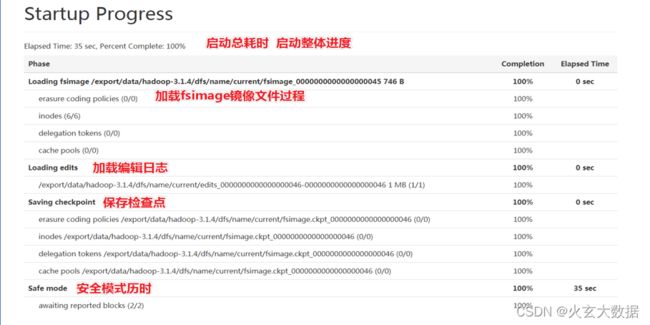
Utilities
- Utilities模块算是用户使用最多的模块了,里面包括了文件浏览、日志查看、配置信息查看等核心功能。
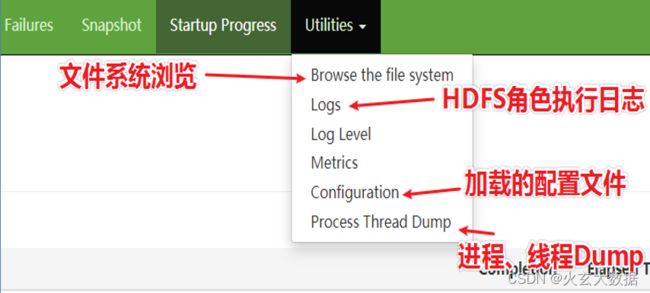
Browse the file system
- 该模块可以说是我们在开发使用HDFS过程中使用最多的模块了,提供了一种Web页面浏览操作文件系统的能力,在某些场合下,比使用命令操作更加直观方便。

Logs、Log Level
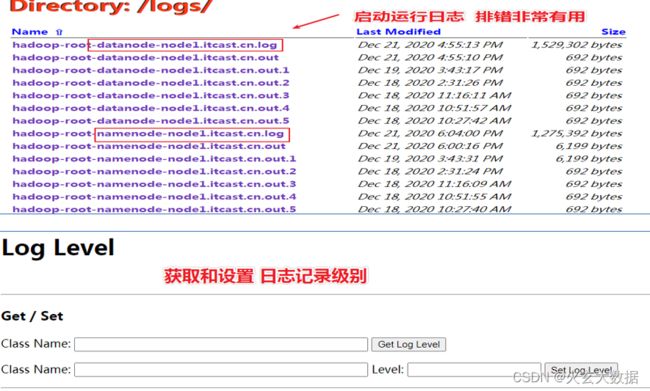
Configruation
- 该模块可以列出当前集群成功加载的所谓配置文件属性,可以从这里来进行判断用户所设置的参数属性是否成功加载生效,如果此处没有,需要检查配置文件或者重启集群加载。
3 HDFS读写流程
3.1 HDFS写数据流程(上传文件)
核心概念:
- Pipeline管道
- Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
- 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
- 因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
- 在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
- ACK应答响应
- ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
- 在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
- 默认3副本存储策略
- 默认副本存储策略是由BlockPlacementPolicyDefault指定。
- 第一块副本:优先客户端本地,否则随机
- 第二块副本:不同于第一块副本的不同机架。
- 第三块副本:第二块副本相同机架不同机器。
完整流程图:

- HDFS客户端创建对象实例DistributedFileSystem, 该对象中封装了与HDFS文件系统操作的相关方法。
- 调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。
- 客户端通过FSDataOutputStream输出流开始写入数据。
- 客户端写入数据时,将数据分成一个个数据包(packet 默认64k), 内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
- 传输的反方向上,会通过ACK机制校验数据包传输是否成功;
- 客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
- DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。最小复制是由参数dfs.namenode.replication.min指定,默认是1.
3.2 HDFS读数据流程(下载文件)
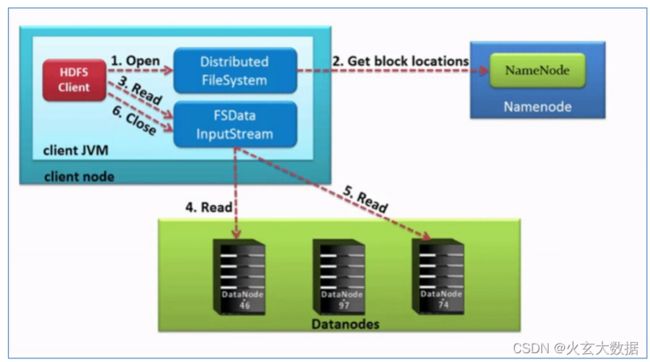
- HDFS客户端创建对象实例DistributedFileSystem, 调用该对象的**open()**方法来打开希望读取的文件。
- DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取)信息。对于每个块,namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的,与客户端的网络拓扑距离近的排序靠前。
- DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
- 客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件中第一个块的最近的DataNode。数据从DataNode流回客户端,结果客户端可以在流上重复调用read()。
- 当该块结束时,FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。
- 一旦客户端完成读取,就对FSDataInputStream调用close()方法。
4 NameNode元数据管理
4.1 元数据概述
在HDFS中,元数据主要指的是文件相关的元数据,由NameNode管理维护。从广义的角度来说,因为NameNode还需要管理众多DataNode节点,因此DataNode的位置和健康状态信息也属于元数据。
在HDFS中,文件相关元数据具有两种类型:
-
文件自身属性信息:文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
-
文件块位置映射信息:记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
按存储形式分为内存元数据和元数据文件两种,分别存在内存和磁盘上:
-
内存元数据
- 为了保证用户操作元数据交互高效,延迟低,NameNode把所有的元数据都存储在内存中,我们叫做内存元数据。内存中的元数据是最完整的,包括文件自身属性信息、文件块位置映射信息。
- 但是内存的致命问题是,断点数据丢失,数据不会持久化。因此NameNode又辅佐了元数据文件来保证元数据的安全完整。
-
元数据文件
-
元数据文件有两种:fsimage内存镜像文件、Edits log编辑日志。
- fsimage 内存镜像文件
-
是内存元数据的一个持久化的检查点。但是fsimage中仅包含Hadoop文件系统中文件自身属性相关的元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是由datanode启动加入集群的时候,向namenode进行数据块的汇报得到的,并且后续间断指定时间进行数据块报告。
-
持久化的动作是数据从内存到磁盘的IO过程。会对namenode正常服务造成一定的影响,不能频繁的进行持久化。
-
Edits log编辑日志
为了避免两次持久化之间数据丢失的问题,又设计了Edits log编辑日志文件。文件中记录的是HDFS所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中。
namenode加载元数据文件顺序
- fsimage和edits文件都是经过序列化的,在NameNode启动的时候,它会先将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
- 当客户端对HDFS中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存元数据中。因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢。
- HDFS这种设计实现着手于:一是内存中数据更新、查询快,极大缩短了操作响应时间;二是内存中元数据丢失风险颇高(断电等),因此辅佐元数据镜像文件(fsimage)+编辑日志文件(edits)的备份机制进行确保元数据的安全。
- NameNode维护整个文件系统元数据。因此,元数据的准确管理,影响着HDFS提供文件存储服务的能力。
4.2 元数据管理相关目录文件
问:在HDFS首次启动之前需要进行format操作,这里的format是在格式化什么?
答:format之前,HDFS在物理上还不存在。其次此处的format并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。其中就会创建元数据本地存储目录和一些初始化的元数据相关文件。
元数据本地存储目录:
-
namenode元数据存储目录由参数:dfs.namenode.name.dir指定。
-
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下创建文件。
-
dfs.namenode.name.dir是在hdfs-site.xml文件中配置的
元数据相关文件:
VERSION
- namespaceID/clusterID/blockpoolID
这些都是HDFS集群的唯一标识符。标识符被用来防止DataNodes意外注册到另一个集群中的namenode上。这些标识在联邦(federation)部署中特别重要。联邦模式下,会有多个NameNode独立工作。每个的NameNode提供唯一的命名空间(namespaceID),并管理一组唯一的文件块池(blockpoolID)。clusterID将整个集群结合在一起作为单个逻辑单元,在集群中的所有节点上都是一样的。
- storageType
说明这个文件存储的是什么进程的数据结构信息。如果是DataNode节点,storageType=DATA_NODE。
- cTime
NameNode存储系统创建时间,首次格式化文件系统这个属性是0,当文件系统升级之后,该值会更新到升级之后的时间戳;
- layoutVersion
HDFS元数据格式的版本。HDFS升级时会进行更新。
seen_txid
- 包含上一次checkpoint时的最后一个事务ID,这不是NameNode接受的最后一个事务ID。
- seen_txid内容不会在每个事务性操作上都更新,只会在checkpoint时更新。
- NameNode启动时会检查seen_txid文件,以验证它至少可以加载该数目的事务。如果无法验证加载事务,NameNode将中止启动。
fsimage
- 元数据镜像文件。每个fsimage文件还有一个对应的.md5文件,其中包含MD5校验和,HDFS使用该文件来防止磁盘损坏文件异常。
edits log
- 已完成且不可修改的编辑日志。这些文件中的每个文件都包含文件名定义的范围内的所有编辑日志事务。在HA高可用性部署中,主备namenode之间可以通过edits log进行数据同步。
fsimage文件内容查看:
-
fsimage文件是Hadoop文件系统元数据的一个永久性的检查点,包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;对于文件来说,包含的信息有修改时间、访问时间、块大小和组成一个文件块信息等;而对于目录来说,包含的信息主要有修改时间、访问控制权限等信息。
-
oiv是offline image viewer的缩写,可将hdfs fsimage文件的内容转储为人类可读的格式。
-
常用命令:hdfs oiv -i fsimage_0000000000000000050 -p XML -o fsimage.xml
edits log文件内容查看
-
edits log文件存放的是Hadoop文件系统的所有更新操作记录日志。
-
文件系统客户端执行的所有写操作首先会被记录到edits文件中。
-
oev是offline edits viewer(离线edits查看器)的缩写,该工具不需要hadoop集群处于运行状态。
-
命令:hdfs oev -iedits_0000000000000000011-0000000000000000025 -o edits.xml
4.3 SecondaryNameNode
根据以上方式管理存储元数据,会出现以下问题:
1.edits logs因操作记录多会变的很大,
2.fsimage因间隔时间长将会变得很旧;
3.namenode重启会花费很长时间,因为有很多改动要从edits log合并到fsimage文件上;
4.如果频繁进行fsimage持久化,又会影响NN正常服务,毕竟IO操作是一种内存到磁盘的耗精力操作.
SNN职责概述:
- 因此为了克服上述问题,需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。
- SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
- 因此常把secondarynamenode称之为主角色的辅助角色,辅助NameNode做一些事。
4.3.1 SNN Checkpoint
概述:
- Checkpoint核心是把fsimage与edits log合并以生成新的fsimage的过程。
- 结果:fsimage版本不断更新不会太旧、edits log文件不会太大。
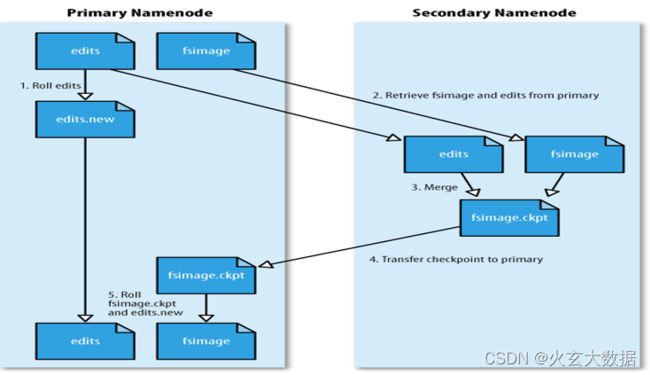
流程:
1、当触发checkpoint操作条件时,SNN发送请求给NN滚动edits log。然后NN会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
2、SNN会将旧的edits log文件和上次fsimage复制到自己本地(使用HTTP GET方式)。
3、SNN首先将fsimage载入到内存,然后一条一条地执行edits文件中的操作,使得内存中的fsimage不断更新,这个过程就是edits和fsimage文件合并。合并结束,SNN将内存中的数据dump生成一个新的fsimage文件。
4、SNN将新生成的Fsimage new文件复制到NN节点。至此刚好是一个轮回,等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
checkpoint触发机制:
- core-site.xml
dfs.namenode.checkpoint.period=3600 //两次连续的checkpoint之间的时间间隔。默认1小时
dfs.namenode.checkpoint.txns=1000000 //最大没有执行checkpoint事务的数量,满足将强制执行紧急checkpoint,即使尚未达到检查点周期。默认100万事务数量。
4.4 NameNode元数据恢复
方式1:NameNode存储多目录
- namenode元数据存储目录由参数:dfs.namenode.name.dir指定。
- dfs.namenode.name.dir属性可以配置多个目录,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
方式2:从SecondaryNameNode恢复
- SecondaryNameNode在checkpoint的时候会将fsimage和edits log下载到自己的本机上本地存储目录下。并且在checkpoint之后也不会进行删除。
- 如果NameNode中的fsimage真的出问题了,还是可以用SecondaryNamenode中的fsimage替换一下NameNode上的fsimage,虽然已经不是最新的fsimage,但是我们可以将损失减小到最少!
5 HDFS小文件解决方案
HDFS并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode占用内存,如果存在大量的小文件,它们会吃掉NameNode节点的大量内存。
5.1 Hadoop Archive文件归档
概述:Hadoop Archives可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
创建:
Usage: hadoop archive -archiveName name -p *
-archiveName 指要创建的存档的名称。扩展名应该是*.har。
-p 指定文件档案文件src的相对路径。
比如:-p /foo/bar a/b/c e/f/g,这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
案例:存档一个目录/smallfile下的所有文件:
hadoop archive -archiveName test.har -p /smallfile /outputdir
这样就会在/outputdir目录下创建一个名为test.har的存档文件。
注意:Archive归档是通过MapReduce程序完成的,需要启动YARN集群。
查看:
hadoop fs -ls /outputdir/test.har
har文件包括:多个索引文件,多个part文件,以及一个标识成功与否的文件。part文件是多个原文件的集合, 通过index文件可以去找到原文件。
在查看har文件的时候,如果没有指定访问协议,默认使用的就是hdfs://,此时所能看到的就是归档之后的样子。
此外,Archive还提供了自己的har uri访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
HadoopArchives的URI是:har://scheme-hostname:port/archivepath/fileinarchive
scheme-hostname格式为hdfs-域名:端口。
提取:
按顺序解压存档(串行):
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
要并行解压存档,请使用DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///outputdir/test.har/* /smallfile2
使用注意事项:
- Hadoop archive是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。archive的扩展名是*.har;
- 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令;
- 创建archive文件要消耗和原文件一样多的硬盘空间;
- archive文件不支持压缩,尽管archive文件看起来像已经被压缩过;
- archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日;
- 当创建archive时,源文件不会被更改或删除;
5.2 Sequence File序列化文件
概述:
- Sequence File是Hadoop提供的一种二进制文件存储格式。
- 一条数据称之为record(记录),底层直接以
优点:
- 二级制格式存储,比文本文件更紧凑。
- 支持不同级别压缩(基于Record或Block压缩)。
- 文件可以拆分和并行处理,适用于MapReduce程序。
局限性:
- 二进制格式文件不方便查看。
- 特定于hadoop,只有Java API可用于与之进行交互。尚未提供多语言支持。
格式:
- 根据压缩类型,有3种不同的Sequence File格式:未压缩格式、record压缩格式、block压缩格式。
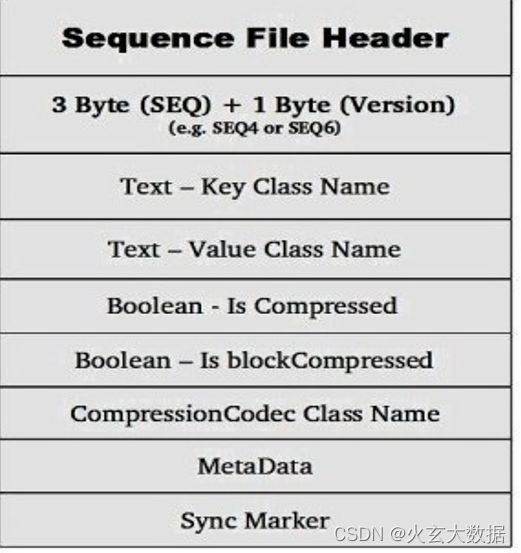
- Sequence File由一个header和一个或多个record组成。以上三种格式均使用相同的header结构,如下所示:
前3个字节为SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如SEQ4或SEQ6)。Header中其他也包括key、value class名字、 压缩细节、metadata、Sync marker。Sync Marker同步标记,用于可以读取任意位置的数据。
未压缩格式:
- 未压缩的Sequence File文件由header、record、sync三个部分组成。其中record包含了4个部分:record length(记录长度)、key length(键长)、key、value。
- 每隔几个record(100字节左右)就有一个同步标记。
基于record压缩格式
- 基于record压缩的Sequence File文件由header、record、sync三个部分组成。其中record包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
- 每隔几个record(100字节左右)就有一个同步标记。
基于block压缩格式
- 基于block压缩的Sequence File文件由header、block、sync三个部分组成。
- block指的是record block,可以理解为多个record记录组成的块。注意,这个block和HDFS中分块存储的block(128M)是不同的概念。Block中包括:record条数、压缩的key长度、压缩的keys、压缩的value长度、压缩的values。每隔一个block就有一个同步标记。
- block压缩比record压缩提供更好的压缩率。使用Sequence File时,通常首选块压缩。
记。
基于record压缩格式
- 基于record压缩的Sequence File文件由header、record、sync三个部分组成。其中record包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
- 每隔几个record(100字节左右)就有一个同步标记。
基于block压缩格式
- 基于block压缩的Sequence File文件由header、block、sync三个部分组成。
- block指的是record block,可以理解为多个record记录组成的块。注意,这个block和HDFS中分块存储的block(128M)是不同的概念。Block中包括:record条数、压缩的key长度、压缩的keys、压缩的value长度、压缩的values。每隔一个block就有一个同步标记。
- block压缩比record压缩提供更好的压缩率。使用Sequence File时,通常首选块压缩。