正则表达式 re模块
1、re模块
re模块中常用的是match函数,用于对字符串进行正则匹配
用法:match(pattern, string)
参数说明:pattern表示正则表达式,string表示待匹配字符串
注意:match函数从头开始匹配,要么第一个就符合要求,要么不符合,匹配成功则返回match对象,否则返回None
import re
str = "python java python c++"
rs = re.match("python",str)
print(rs)
![]()
获取匹配的字符串,调用group方法
import re
str = "python java python c++"
rs = re.match("python",str)
print(rs.group())
![]()
2、单字符匹配
| 符号 | 描述 |
|---|---|
| . | 匹配除“\n”之外的任意单个字符 |
| \d | 匹配0到9之间的一个数字,等价于[0~9] |
| \D | 匹配一个非数字字符,等价于[^0~9] |
| \s | 匹配任意空白字符,如空格、制表符、换行等 |
| \S | 匹配任意非空白字符 |
| \w | 匹配单词字符,包括字母、数字、下划线 |
| \W | 匹配非单词字符 |
| [] | 匹配[]中列举的字符 |
例:
import re
rs = re.match(".","1") #匹配一个包含数字的字符串
print(rs.group())
rs = re.match(".","a") #匹配一个包含单字符的字符串
print(rs.group())
rs = re.match(".","abc") #匹配一个包含多字符的字符串
print(rs.group())

3、数量表示
| 符号 | 描述 |
|---|---|
| * | 匹配一个字符出现0次或者多次 |
| + | 匹配一个字符至少出现一次,等价于{1,} |
| ? | 匹配一个字符至多出现一次,也就是出现0次或1次,等价于{0,1} |
| {m} | 匹配一个字符出现m次 |
| {m,} | 匹配一个字符至少出现m次 |
| {m,n} | 匹配一个字符出现m到n次 |
例;检查用户信息是否完整
import re
#存储用户信息列表,每条用户信息包含三个字段:姓名,手机号,年龄
user_infos = ["Tom,13812345678,20","David,,30","Lilei,18851888888,25"]
for user in user_infos:
# 使用正则检查用户信息是否完整
rs = re.match("\w+,[0-9]{11},\d+",user)
if rs != None:
# 匹配成功打印用户信息
print("用户信息:{}".format(rs.group()))
else:
print("用户信息不完整!")

4、边界表示
| 符号 | 描述 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
例:验证手机号
# 结束边界在手机号验证中的应用
import re
def reg_phone(phone):
#合法的手机号规则:由11位数字组成,第1位是1,第2位是3、5、7、8其中一个数字,第3到第11位是0-9的数字
rs = re.match("1[3578]\d{9}$", phone)
if rs == None:
return False
else:
print(rs.group())
return True
#测试1:正确的手机号
print("----------测试1结果----------")
print(reg_phone("13612345678"))
#测试2:错误的手机号
print("----------测试2结果----------")
print(reg_phone("14612345678")) #第2位没有出现3、5、7、8其中一个
#测试3:正确的手机号+字符
print("----------测试3结果----------")
print(reg_phone("13612345678abc"))

5、转义字符
1.要匹配“.”,需要使用“.”
2.打印原生字符串,在前面加一个字母“r”
#匹配字符串中的斜杠“\”
import re
str = "\python"
#使用非原生字符串定义正则表达式匹配规则
rs = re.match("\\\\\w+",str)
print(rs)
#使用原生字符串定义正则表达式匹配规则
rs = re.match(r"\\\w+",str)
print(rs)

6、匹配分组
| 符号 | 描述 |
|---|---|
| | | 连接多个表达式,表达式之间是或的关系,匹配“|” 连接的任何一个表达式 |
| () | 将括号中字符作为一个分组 |
| \NUM | 结合()使用,引用 分组NUM对应的匹配规则 |
| (?p< name>) | 给分组起别名 |
| (?p=name) | 根据组名使用分组中的正则表达式 |
7、内置函数
(1).compile函数
使用re模块内置的compile函数编译正则表达式,返回一个正则表达式对象,在匹配时可以多次复用一个正则表达式对象进行匹配
import re
# 复用正则表达式对象匹配邮箱地址
pattern = re.compile("\w{4,10}@163\.com$") #返回正则表达式对象
rs = re.match(pattern,"[email protected]")
print(rs)
rs = re.match(pattern,"[email protected]")
print(rs)
rs = re.match(pattern,"[email protected]")
print(rs)

(2).search函数
re模块内置的search函数的功能是从左到右在字符串的任意位置搜索第一个被正则表达式匹配的字符串
- search()和match()的区别:
- match()方法是从字符串的开头进行匹配,如果开始就不符合正则的要求,则匹配失败,返回None
- search()方法从字符串的开始位置一直搜索到字符串的最后,如果在整个字符中都没有匹配到,则失败,返回None
import re
#从字符串中查找是否包含“python”
rs = re.search("python","hi python,i am going to study python")
print(rs)

(3).findall函数
re模块内置的findall函数的功能是在字符串中查找正则表达式匹配成功的所有子字符串,返回匹配成功的结果列表
import re
# 从用户信息中查找出所有手机号
infos = "Tom:13800000001,David:13800000002"
list = re.findall(r"1[3578]\d{9}",infos)
print(list)

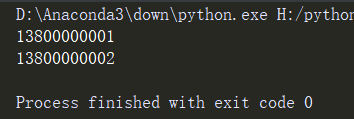
(4).finditer函数
re模块内置的finditer函数的功能是在字符串中查找正则表达式匹配成功的所有子字符串,返回结果是一个可迭代对象Iterator,Iterator中的每个元素都是正则表达式匹配的一个子字符串
import re
#从用户信息中查找出所有手机号
infos = "Tom:13800000001,David:13800000002"
iter_obj = re.finditer(r"1[3578]\d{9}",infos)
for iter in iter_obj:
print(iter.group())
(5).sub函数
re模块内置的sub函数的功能是将正则表达式匹配的子字符串使用新的字符串替换掉,返回结果是替换之后的新字符串,原字符串值不变
- 参数:
- pattern: 正则表达式的规则,匹配需要被替换的字符串
- repl: 替换后的字符串
- string:被替换的原字符串
import re
#将字符串中的所有空格替换成逗号
stu = "Tom 13800000001 Male"
stu_new = re.sub("\s",",",stu)
print("stu={}".format(stu))
print("stu_new={}".format(stu_new))

8、贪婪与非贪婪模式
- 贪婪模式:默认采用贪婪模式,尽可能多地匹配字符
- 非贪婪模式:尽可能少地匹配字符
- 启用非贪婪模式的方法:在表示数量的符号,如“*”、”?“、"+"等的后边添加一个问号
import re
#贪婪与非贪婪模式对比
#贪婪模式
print("--------贪婪模式--------")
rs = re.findall("python\d*", "python2018") #任意多个数字
print(rs)
rs = re.findall("python\d+", "python2018") #至少出现一次数字
print(rs)
rs = re.findall("python\d{2,}", "python2018") #至少出现2次数字
print(rs)
re.findall("python\d{1,4}","python2018") #出现1到4次数字
print(rs)
#非贪婪模式
print("--------非贪婪模式--------")
rs = re.findall("python\d*?", "python2018")
print(rs)
rs = re.findall("python\d+?", "python2018")
print(rs)
rs = re.findall("python\d{2,}?", "python2018")
print(rs)
re.findall("python\d{1,4}?","python2018")
print(rs)

9、补充
- 正则模式 re.I 不区分大小写
- ’\w+(\d{4})‘ # ()代表子组,括号中的表达式首先作为整个正则的一部分,另外会把符合小括号中的内容单独提取处理。groups函数输出
看书学习
《Python3快速入门与实战》