详解【负载均衡】(负载均衡算法、一致性hash、负载均衡架构分析)
作者:duktig
博客:https://duktig.cn
优秀还努力。愿你付出甘之如饴,所得归于欢喜。
本文源码参看:https://github.com/duktig666/distributed-programme/tree/main/load-balance
1. 什么是负载均衡?
负载均衡建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。用于解决互联网架构中的高并发和高可用的问题。
负载均衡,英文名称为Load Balance,其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。
——百度百科
对于“均衡”的理解
所谓的“均衡”,不能狭义地理解为分配给所有实际服务器一样多的工作量,因为多台服务器的承载能力各不相同,这可能体现在硬件配置、网络带宽的差异,也可能因为某台服务器身兼多职,我们所说的“均衡”,也就是希望所有服务器都不要过载,并且能够最大程序地发挥作用。
2. 为什么要使用负载均衡?(由来)
在业务初期,我们一般会先使用单台服务器对外提供服务。随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板。当单服务器的性能无法满足业务需求时,就需要把多台服务器组成集群系统提高整体的处理性能。
所以我们要使用统一的流量入口来对外提供服务,本质上就是需要一个流量调度器,通过负载均衡算法,将用户大量的请求流量均衡地分发到集群中不同的服务器上。
3. 负载均衡类型
广义上的负载均衡器大概可以分为 3 类,包括:DNS 方式实现负载均衡、硬件负载均衡、软件负载均衡。
(1)DNS 实现负载均衡
DNS 实现负载均衡是最基础简单的方式。一个域名通过 DNS 解析到多个 IP,每个 IP 对应不同的服务器实例,这样就完成了流量的调度,虽然没有使用常规的负载均衡器,但实现了简单的负载均衡功能。

优点:实现简单,成本低,无需自己开发或维护负载均衡设备
缺点:
- 服务器故障切换延迟大,服务器升级不方便。DNS 与用户之间是层层的缓存,即便是在故障发生时及时通过 DNS 修改或摘除故障服务器,但中间经过运营商的 DNS 缓存,且缓存很有可能不遵循 TTL 规则,导致 DNS 生效时间变得非常缓慢,有时候一天后还会有些许的请求流量。
- 流量调度不均衡,粒度太粗。DNS 调度的均衡性,受地区运营商 LocalDNS 返回 IP 列表的策略有关系,有的运营商并不会轮询返回多个不同的 IP 地址。另外,某个运营商 LocalDNS 背后服务了多少用户,这也会构成流量调度不均的重要因素。
- 流量分配策略太简单,支持的算法太少。DNS 一般只支持轮询方式,流量分配策略比较简单,不支持权重、Hash 等调度算法。
- DNS 支持的 IP 列表有限制。DNS 使用 UDP 报文进行信息传递,每个 UDP 报文大小受链路的 MTU 限制,所以报文中存储的 IP 地址数量也是非常有限的,阿里 DNS 系统针对同一个域名支持配置 10 个不同的 IP 地址。
实际上生产环境中很少使用这种方式来实现负载均衡,毕竟缺点很明显。文中之所以描述 DNS 负载均衡方式,是为了能够更清楚地解释负载均衡的概念。
像 BAT 体量的公司一般会利用 DNS 来实现地理级别的全局负载均衡,实现就近访问,提高访问速度,这种方式一般是入口流量的基础负载均衡,下层会有更专业的负载均衡设备实现的负载架构。
(2)硬件负载均衡
硬件负载均衡是通过专门的硬件设备来实现负载均衡功能,是专用的负载均衡设备。目前业界典型的硬件负载均衡设备有两款:F5 和 A10。
这类设备性能强劲、功能强大,但价格非常昂贵,一般只有土豪公司才会使用此类设备,中小公司一般负担不起,业务量没那么大,用这些设备也是挺浪费的。
优点:
- 功能强大:全面支持各层级的负载均衡,支持全面的负载均衡算法。
- 性能强大:性能远超常见的软件负载均衡器。
- 稳定性高:商用硬件负载均衡,经过了良好的严格测试,经过大规模使用,稳定性高。
- 安全防护:还具备防火墙、防 DDoS 攻击等安全功能,以及支持 SNAT 功能。
缺点:
- 价格贵;
- 扩展性差,无法进行扩展和定制;
- 调试和维护比较麻烦,需要专业人员;
(3)软件负载均衡
软件负载均衡,可以在普通的服务器上运行负载均衡软件,实现负载均衡功能。目前常见的有 Nginx、HAproxy、LVS。其中的区别:
Nginx:七层负载均衡,支持 HTTP、E-mail 协议,同时也支持 4 层负载均衡;HAproxy:支持七层规则的,性能也很不错。OpenStack 默认使用的负载均衡软件就是 HAproxy;LVS:运行在内核态,性能是软件负载均衡中最高的,严格来说工作在三层,所以更通用一些,适用各种应用服务。
优点:
- 易操作:无论是部署还是维护都相对比较简单;
- 便宜:只需要服务器的成本,软件是免费的;
- 灵活:4 层和 7 层负载均衡可以根据业务特点进行选择,方便进行扩展和定制功能。
4. 常见的软件负载均衡器简介
(1)Nginx
Nginx是一款轻量级的Web服务器 / 反向代理服务器 及 电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好。
反向代理
正向代理:局域网中的电脑用户想要直接访问网络是不可行的,只能通过代理服务器来访问,这种代理服务就被称为正向代理。

由于防火墙的原因,我们并不能直接访问谷歌,那么我们可以借助VPN来实现,这就是一个简单的正向代理的例子。这里你能够发现,正向代理“代理”的是客户端,而且客户端是知道目标的,而目标是不知道客户端是通过VPN访问的。
反向代理:客户端无法感知代理,因为客户端访问网络不需要配置,只要把请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据,然后再返回到客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器IP地址。

当我们在外网访问百度的时候,其实会进行一个转发,代理到内网去,这就是所谓的反向代理,即反向代理“代理”的是服务器端,而且这一个过程对于客户端而言是透明的。
负载均衡
客户端发送多个请求到服务器,服务器处理请求,有一些可能要与数据库进行狡猾,服务器处理完毕之后,再将结果返回给客户端但是随着信息数量增长,访问量和数据量飞速增长,普通架构无法满足现在的需求
我们首先想到的是升级服务器配置,但是如果单纯从硬件提升性能已经逐渐不可取了,怎么解决这种需求呢?
我们可以增加服务器的数量,构建集群,将请求分发到各个服务器上,将原来请求集中到单个服务器的情况改为请求分发到多个服务器,也就是我们说的负载均衡
假设有15个请求发送到代理服务器,那么由代理服务器根据服务器数量,平均分配,每个服务器处理5个请求,这个过程就叫做负载均衡
动静分离
为了加快网站的解析速度,可以把动态页面和静态页面交给不同的服务器来解析,加快解析的速度,降低由单个服务器的压力。
Nginx访问静态资源,Tomcat访问动态资源。
优缺点
Nginx优点:
- 简单:安装和配置比较简单、测试也简单
- 稳定:单机一般能支撑几万次的并发量
- 轻量:能ping通就就能进行负载功能
- 易用:明确的错误码、超时提醒
- 强大:负载均衡、反向代理、WEB容器等功能
Nginx缺点:
- 仅能支持http、https和Email协议
- 对后端服务器的健康检查, 只支持通过端口来检测,不支持通过url来检测
(2)LVS
LVS,全称 Linux Virtual Server 是由国人章文嵩博士发起的一个开源的项目,在社区具有很大的热度,是一个基于四层、具有强大性能的反向代理服务器。
四层负载均衡基本上都会使用 LVS,据了解 BAT 等大厂都是 LVS 重度使用者,就是因为 LVS 非常出色的性能,能为公司节省巨大的成本。
它现在是标准内核的一部分,它具备可靠性、高性能、可扩展性和可操作性的特点,从而以低廉的成本实现最优的性能。
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡功能(平时我们说的 Linux 防火墙就是 netfilter)。
优缺点
LVS优点:
- 高效:工作在网络4层之上 仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的 ,对内存和cpu资源消耗比较低
- 易用:配置性比较低,简化操作成本
- 稳定:本身抗负载能力很强,自身有完整的双机热备方案
- 应用广:因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、tcp、数据库、在线聊天室等
LVS缺点:
- 不能做动静分离
- 大型网站LVS+Keepalived实施起来就比较复杂,配置成本高
关于LVS原理可参看:全网最详细的负载均衡原理图解
(3)HAProxy
HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。
Nginx 跟 Haproxy 其实他们两个的定位是有所不同的,Nginx的定位是一个server,Haproxy的定位是一个load balancer。
HAProxy 支持两种代理模式 TCP(四层)和HTTP(七层),也是支持虚拟主机的。
优缺点
HAProxy的优点能够补充Nginx的一些缺点, 比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态。
HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡。
**三大主流软件负载均衡器 **适用业务场景
- 网站建设初期,可以选用Nginx、HAProxy作为反向代理负载均衡(流量不大时,可以不选用负载均衡),因为其配置简单,性能也能满足一般业务场景。如果考虑到负载均衡器是有单点问题,可以采用Nginx+Keepalived/HAproxy+Keepalived避免负载均衡器自身的单点问题。
- 网站并发到达一定程度后,为了提高稳定性和转发效率,可以使用lvs,毕竟lvs比Nginx/HAProxy要更稳定,转发效率也更高。
三者详细对比参看:Nginx和HAProxy对比,各有什么优点与不足?
5. 负载均衡的架构演变过程
(1)单节点访问
项目前期没啥流量,所以只部署了一台 tomcat server,让客户端直接请求这台 server。

这样部署一开始也没啥问题,因为业务量不是很大,单机足以扛住。
问题:
后来业务踩中了风口,迅猛发展,于是单机的性能逐渐遇到了瓶颈,而且由于只部署了一台机器,这台机器挂掉了业务也就跌零了,这可不行。
(2)多节点访问
为了避免单机性能瓶颈与解决单点故障的隐患,可以多部署几台机器(假设为三台),这样可以让 client 随机打向其中的一台机器,这样就算其中一台机器挂了,另外的机器还存活,让 client 打向其它没有宕机的机器即可。

问题:
client 到底该打向这三台机器的哪一台呢?如果让 client 来选择肯定不合适,因为如果让 client 来选择具体的 server,那么它必须知道有哪几台 server,然后再用轮询等方式随机连接其中一台机器,但如果其中某台 server 宕机了,client 是无法提前感知到的,那么很可能 client 会连接到这台挂掉的 server 上,所以选择哪台机器来连接的工作最好放在 server 中,具体怎么做呢?
(3)负载均衡
在架构设计中有个经典的共识:没有什么是加一层解决不了的,如果有那就再加一层,所以我们在 server 端再加一层,将其命名为 LB(Load Balance,负载均衡),由 LB 统一接收 client 的请求,然后再由它来决定具体与哪一个 server 通信,一般业界普遍使用 Nginx 作为 LB。

采用这样的架构设计支撑了业务的快速增长。
问题:
所有的流量都能打到 server 上,这显然是有问题的,不太安全,那能不能在流量打到 server 前再做一层鉴权操作呢,鉴权通过了我们才让它打到 server 上,我们把这一层叫做网关(为了避免单点故障,网关也要以集群的形式存在)。
(4)网关+负载均衡

这样的话所有的流量在打到 server 前都要经过网关这一层,鉴权通过后才把流量转发到 server 中,否则就向 client 返回报错信息,除了鉴权外,网关还起到风控(防止羊毛党),协议转换(比如将 HTTP 转换成 Dubbo),流量控制等功能,以最大程度地保证转发给 server 的流量是安全的,可控的。
问题:
不管是动态请求,还是静态资源(如 js,css文件)请求都打到 tomcat 了,这样在流量大时会造成 tomcat 承受极大的压力,其实对于静态资源的处理 tomcat 不如 Nginx,tomcat 每次都要从磁盘加载文件比较影响性能,而 Nginx 有 proxy cache 等功能可以极大提升对静态资源的处理能力。
所谓的 proxy cache 是指 nginx 从静态资源服务器上获取资源后会缓存在本地的内存+磁盘中,下次请求如果命中缓存就从 Nginx 本机的 Cache 中直接返回了
(5)动静分离 + 直接访问
动静分离:如果是动态请求,则经过 gateway 打到 tomcat(tomcat 就可以专注于处理其擅长的动态请求);如果是静态请求,则打到静态资源服务器上(静态资源利用到了 Nginx 的 proxy cache 等功能)。
直接访问:并不是所有的动态请求都需要经过网关,像某些后台由于是内部员工使用的,所以它的鉴权与网关的 api 鉴权并不相同,所以单独部署 server ,直接让 Nginx 将的请求打到了这台 server 上,绕过网关。

(6)Nginx集群
1. 主从
为了避免单点故障 Nginx 也需要部署至少两台机器,于是我们的架构变成了下面这样,Nginx 部署两台,以主备的形式存在,备 Nginx 会通过 keepalived 机制(发送心跳包) 来及时感知到主 Nginx 的存活,发现宕机自己就顶上充当主 Nginx 的角色。

2. 考虑LVS
虽然这样可以解决单节点故障问题,但是如果有巨额流量,显然一台Nginx是不可行的。这样可以使用Nginx的集群(这个后边再说)。
目前的架构已经算是趋于完善和不错了。
但仍然还存在优化空间:
Nginx 是七层(即应用 层)负载均衡器 ,这意味着如果它要转发流量首先得和 client 建立一个 TCP 连接,并且转发的时候也要与转发到的上游 server 建立一个 TCP 连接,而我们知道建立 TCP 连接其实是需要耗费内存(TCP Socket,接收/发送缓存区等需要占用内存)的,客户端和上游服务器要发送数据都需要先发送暂存到到 Nginx 再经由另一端的 TCP 连接传给对方。

所以 Nginx 的负载能力受限于机器I/O,CPU内存等一系列配置,一旦连接很多(比如达到百万)的话,Nginx 抗负载能力就会急遽下降。
经过分析可知 Nginx 的负载能力较差主要是因为它是七层负载均衡器必须要在上下游分别建立两个 TCP 所致,那么是否能设计一个类似路由器那样的只负载转发包但不需要建立连接的负载均衡器呢?这样由于不需要建立连接,只负责转发包,不需要维护额外的 TCP 连接,它的负载能力必然大大提升,于是四层负载均衡器 LVS 就诞生了,简单对比下两者的区别

可以看到 LVS 只是单纯地转发包,不需要和上下游建立连接即可转发包,相比于 Nginx 它的抗负载能力强、性能高,能达到 F5 硬件的 60%;对内存和cpu资源消耗比较低。
那么四层负载均衡器是如何工作的呢?
负载均衡设备在接收到第一个来自客户端的SYN 请求时,即通过负载均衡算法选择一个最佳的服务器,并对报文中目标IP地址进行修改(改为后端服务器 IP ),直接转发给该服务器。TCP 的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改。

问题:
只有一台 LVS 的话在流量很大的情况下也是找不住的,怎么办,多加几台啊,使用 DNS 负载均衡在解析域名的时候随机打到其中一台。
3. LVS集群

LVS 可以采用部署多台的形式来避免单点故障,那 Nginx 也可以,而且 Nginx 在 1.9 之后也开始支持四层负载均衡了,所以貌似 LVS 不是很有必要?
4. Nginx集群(最终版)

(7)引入CDN
如果流量很大时,静态资源应该部署在 CDN 上, CDN 会自动选择离用户最近的节点返回给用户,所以我们最终的架构改进如下:

(8)最终架构图
通过部署多台 Nginx 的方式在流量不是那么大的时候确实是可行,但 LVS 是 Linux 的内核模块,工作在内核态,而 Nginx 工作在用户态,也相对比较重,所以在性能和稳定性上 Nginx 是不如 LVS 的,这就是为什么我们要采用 LVS + Nginx 的部署方式。
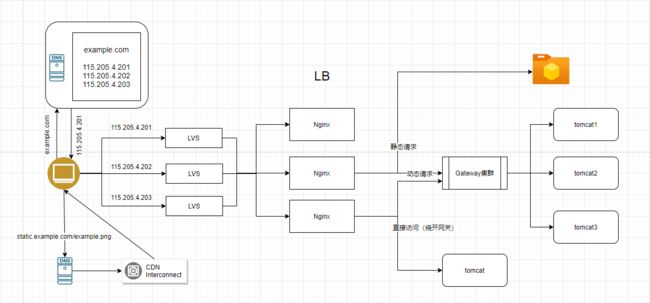
负载均衡架构,也可参看:架构 - 负载均衡 - 阿里云
6. 负载均衡算法
算法详解
1、轮询访问
按请求顺序轮流分配到后端服务器,即挨个数数,轮流分配。
优点:实现简单,绝对均衡
缺点:无法保证分配的合理性,即无法根据服务器的承受能力来分配任务。
2、随机访问
随机选择一台服务器来分配任务。请求增多(分散性)达到了均衡。基于概率统计的理论,吞吐量越大,随机算法的效果越接近于轮询算法的效果。
优点:没有状态,不需要维持上次的选择状态和均衡因子
缺点:请求达到一定程度,具备轮询访问的缺点
3、源地址哈希法(IP-Hash)
根据客户端IP地址,通过hash函数计算一个hashcode,用hashcode对服务器列表进行取模运算,从而得到客户端要访问的序号。
优点:保证了相同客户端IP地址将会被哈希到同一台后端服务器,直到后端服务器列表变更。根据此特性可以在服务消费者与服务提供者之间建立有状态的session会话。
缺点:除非集群中服务器的非常稳定,基本不会上下线,否则一旦有服务器上线、下线,那么可能路由不到相应的服务,如果是session则取不到session,如果是缓存则可能引发"雪崩"。
4、加权轮询
按照请求顺序和权重两个条件进行任务分配。给配置高、负载低的机器更加高的权重,而且有序。
5、加权随机
按照权重随机分配服务器。并非有序。与轮询加权相比,两者不同的是,轮询加权请求分配数比例相等,而随机加权是一个近似值。
6、最小连接法
根据后端服务器当前连接情况,动态选取当前连接数最少的一台服务器来处理请求。
缺点:当服务器性能差距较大时,无法达到预期效果,连接数小而自身性能差的服务器可能不及连接数大而性能好的服务器。
前面几种方法费尽心思来实现服务消费者请求次数分配的均衡,当然这么做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是实际情况是否真的如此?实际情况中,请求次数的均衡真的能代表负载的均衡吗?这是一个值得思考的问题。
上面的问题,再换一个角度来说就是:以后端服务器的视角来观察系统的负载,而非请求发起方来观察。最小连接数法便属于此类。
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能地提高后端服务器的利用效率,将负载合理地分流到每一台机器。由于最小连接数设计服务器连接数的汇总和感知,设计与实现较为繁琐,下文就不说它的实现了。
负载均衡算法实现
Java代码实现前的准备工作:
定义一个负载均衡策略的接口
public interface LoadBalance {
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
String route(Map<String, Integer> serverMap);
}
定义一个存放IP的Map
模拟服务器的实例,并配置相应的权重
public class IpMap {
/**
* 待路由的Ip列表,Key代表Ip,Value代表该Ip的权重
*/
public static Map<String, Integer> serverWeightMap = new HashMap<>();
static {
serverWeightMap.put("192.168.1.100", 1);
serverWeightMap.put("192.168.1.101", 1);
serverWeightMap.put("192.168.1.102", 2);
serverWeightMap.put("192.168.1.103", 2);
serverWeightMap.put("192.168.1.104", 3);
}
}
定义一个工具类,方便测试
public class LoadBalanceUtil {
private static String requestIp;
/**
* 统计路由结果
*
* @param routingMap 记录路由结果的Map
*/
public static void countRoutingMap(Map<String, Integer> routingMap) {
// 路由总体结果
for (Map.Entry<String, Integer> entry : routingMap.entrySet()) {
System.out.println("IP:" + entry.getKey() + ",次数:" + entry.getValue());
}
}
/**
* 模拟路由调用
*
* @param loadBalance 负载均衡策略
* @param requestCount 请求次数
* @return 负载均衡的记录
*/
public static Map<String, Integer> imitateRouting(LoadBalance loadBalance, int requestCount) {
Map<String, Integer> serverMap = new ConcurrentHashMap<>(IpMap.serverWeightMap.size());
for (int i = 0; i < requestCount; i++) {
String server = loadBalance.route(IpMap.serverWeightMap);
Integer count = serverMap.getOrDefault(server, 0);
serverMap.put(server, ++ count);
}
return serverMap;
}
/**
* 获取Ip地址
*
* @return IP地址
*/
public static String getIp() {
try {
InetAddress ip4 = Inet4Address.getLocalHost();
return ip4.getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
return null;
}
/**
* 获取请求的 Ip地址 (模拟)
*
* @return IP地址
*/
public static String getRequestIp() {
return requestIp;
}
/**
* 设置请求的IP 模拟
*
* @param requestIp 请求IP
*/
public static void setRequestIp(String requestIp) {
LoadBalanceUtil.requestIp = requestIp;
}
}
1、随机
public class RandomLoadBalance implements LoadBalance {
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
// 复制遍历用的集合,防止操作中集合有变更
List<String> serverList = new ArrayList<>(serverMap.size());
serverList.addAll(serverMap.keySet());
// 随机数随机访问
int randomInt = new Random().nextInt(serverList.size());
return serverList.get(randomInt);
}
}
测试:
/**
* 测试 随机
*/
@Test
public void testRandom() {
Map<String, Integer> routingMap = LoadBalanceUtil.imitateRouting(new RandomLoadBalance(), 20000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
}
结果:
IP:192.168.1.100,次数:3959
IP:192.168.1.101,次数:4015
IP:192.168.1.102,次数:4017
IP:192.168.1.103,次数:4009
IP:192.168.1.104,次数:4000
从结果上看,访问趋近均衡。
2、轮询
public class RoundRobinLoadBalance implements LoadBalance {
private static volatile Integer index = 0;
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
// 复制遍历用的集合,防止操作中集合有变更
List<String> serverList = new ArrayList<>(serverMap.size());
serverList.addAll(serverMap.keySet());
synchronized (RoundRobinLoadBalance.class) {
index++;
if (index == serverList.size()) {
index = 0;
}
return serverList.get(index);
}
}
}
测试:
/**
* 测试 轮询
*/
@Test
public void testRoundRobin() {
Map<String, Integer> routingMap = LoadBalanceUtil.imitateRouting(new RoundRobinLoadBalance(), 20000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
}
结果:
IP:192.168.1.100,次数:4000
IP:192.168.1.101,次数:4000
IP:192.168.1.102,次数:4000
IP:192.168.1.103,次数:4000
IP:192.168.1.104,次数:4000
从结果上看,访问绝对均衡。
3、加权随机
public class WeightRandomLoadBalance implements LoadBalance {
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
Map<String, Integer> tempMap = new HashMap<>(serverMap.size());
tempMap.putAll(serverMap);
List<String> serverList = new ArrayList<>();
for (String server : tempMap.keySet()) {
// 按照权重比例添加服务节点(权重高,节点数量多)
for (int i = 0; i < serverMap.get(server); i++) {
serverList.add(server);
}
}
int randomInt = new Random().nextInt(serverList.size());
return serverList.get(randomInt);
}
}
测试:
/**
* 测试 加权随机
*/
@Test
public void testWeightRandom() {
Map<String, Integer> routingMap = LoadBalanceUtil.imitateRouting(new WeightRandomLoadBalance(), 20000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
}
结果:
IP:192.168.1.100,次数:2184
IP:192.168.1.101,次数:2265
IP:192.168.1.102,次数:4345
IP:192.168.1.103,次数:4407
IP:192.168.1.104,次数:6799
从结果上看,相同权重的实例,访问趋近均衡。
4、加权轮询
public class WeightRoundRobinLoadBalance implements LoadBalance {
private static volatile Integer index = 0;
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
Map<String, Integer> tempMap = new HashMap<>(serverMap.size());
tempMap.putAll(serverMap);
List<String> serverList = new ArrayList<>();
for (String server : tempMap.keySet()) {
// 按照权重比例添加服务节点(权重高,节点数量多)
for (int i = 0; i < serverMap.get(server); i++) {
serverList.add(server);
}
}
synchronized (WeightRoundRobinLoadBalance.class) {
index++;
if (index == serverList.size()) {
index = 0;
}
return serverList.get(index);
}
}
}
测试:
/**
* 测试 加权轮询
*/
@Test
public void testWeightRoundRobin() {
Map<String, Integer> routingMap = LoadBalanceUtil.imitateRouting(new WeightRoundRobinLoadBalance(), 20000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
}
结果:
IP:192.168.1.100,次数:2222
IP:192.168.1.101,次数:2223
IP:192.168.1.102,次数:4445
IP:192.168.1.103,次数:4444
IP:192.168.1.104,次数:6666
从结果上看,相同权重的实例,访问绝对均衡。
5、源地址Hash
public class HashLoadBalance implements LoadBalance {
/** 用于源地址hash的参数(可以是IP/主机名/域名) */
private String requestHashParam;
public HashLoadBalance(String requestHashParam) {
this.requestHashParam = requestHashParam;
}
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
// 复制遍历用的集合,防止操作中集合有变更
List<String> serverList = new ArrayList<>(serverMap.size());
serverList.addAll(serverMap.keySet());
// 哈希计算请求的服务器
int index = requestHashParam.hashCode() % serverList.size();
return serverList.get(Math.abs(index));
}
}
测试:
/**
* 测试 源地址Hash
*/
@Test
public void testHash() {
// 提前设置请求的Ip
LoadBalanceUtil.setRequestIp("127.0.0.1");
Map<String, Integer> routingMap =
LoadBalanceUtil.imitateRouting(new HashLoadBalance(LoadBalanceUtil.getRequestIp()), 20000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
}
结果:
IP:192.168.1.102,次数:20000
因为是本机模拟访问,IP地址相同,所以所有请求访问到了同一台服务实例上。
测试几种负载均衡算法的执行时间
虽然算法是自己实现的,可能有很多的问题,但从10W的访问量上,也可以说明很多的问题。
/**
* 对比 几种负载均衡算法的时间
*/
@Test
public void testLoadBalanceTime() {
System.out.println("---测试10W访问量,各种负载均衡算法用时---");
LocalDateTime startTime = LocalDateTime.now();
LoadBalanceUtil.imitateRouting(new RoundRobinLoadBalance(), 100000);
LocalDateTime endTime = LocalDateTime.now();
long minutes = Duration.between(startTime, endTime).toMillis();
System.out.println("轮询负载均衡算法 用时:" + minutes + " ms");
startTime = LocalDateTime.now();
LoadBalanceUtil.imitateRouting(new RandomLoadBalance(), 100000);
endTime = LocalDateTime.now();
minutes = Duration.between(startTime, endTime).toMillis();
System.out.println("随机负载均衡算法 用时:" + minutes + " ms");
startTime = LocalDateTime.now();
LoadBalanceUtil.imitateRouting(new WeightRoundRobinLoadBalance(), 100000);
endTime = LocalDateTime.now();
minutes = Duration.between(startTime, endTime).toMillis();
System.out.println("加权轮询负载均衡算法 用时:" + minutes + " ms");
startTime = LocalDateTime.now();
LoadBalanceUtil.imitateRouting(new WeightRandomLoadBalance(), 100000);
endTime = LocalDateTime.now();
minutes = Duration.between(startTime, endTime).toMillis();
System.out.println("加权随机负载均衡算法 用时:" + minutes + " ms");
// 提前设置请求的Ip
LoadBalanceUtil.setRequestIp("127.0.0.1");
startTime = LocalDateTime.now();
LoadBalanceUtil.imitateRouting(new HashLoadBalance(LoadBalanceUtil.getRequestIp()), 100000);
endTime = LocalDateTime.now();
minutes = Duration.between(startTime, endTime).toMillis();
System.out.println("源地址Hash负载均衡算法 用时:" + minutes + " ms");
}
结果:
---测试10W访问量,各种负载均衡算法用时---
轮询负载均衡算法 用时:57 ms
随机负载均衡算法 用时:40 ms
加权轮询负载均衡算法 用时:97 ms
加权随机负载均衡算法 用时:74 ms
源地址Hash负载均衡算法 用时:14 ms
Nginx的负载均衡算法
1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
2、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
例如:
upstream myServer {
server 192.168.0.14 weight=10;
server 192.168.0.15 weight=10;
}
3、ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
例如:
upstream myServer {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}
4、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream myServer {
server server1;
server server2;
fair;
}
5、url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
例:在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method是使用的hash算法。
upstream myServer {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
每个设备的状态设置为:
tips:
upstream myServer{#定义负载均衡设备的Ip及设备状态
ip_hash;
server 127.0.0.1:9090 down;
server 127.0.0.1:8080 weight=2;
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup;
}
在需要使用负载均衡的server中增加
proxy_pass http://myServer/;
down:表示单前的server暂时不参与负载weight:默认为1.weight越大,负载的权重就越大。max_fails:允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误fail_timeout:max_fails次失败后,暂停的时间。backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻
负载均衡——一致性hash
普通Hash算法的问题
hash(object) % nodeTotal
- 一个缓存服务器宕机了,这样所有映射到这台服务器的对象都会失效,我们需要把属于该服务器中的缓存移除,这时候缓存服务器是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
- 由于QPS升高,我们需要添加多一台服务器,这时候服务器是 N+1 台,映射公式变成了 hash(object)%(N+1) 。
1 和 2 的改变都会出现所有服务器需要进行数据迁移。
一致性Hash
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
一致性Hash性质
平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
原理
(1)一致性hash的分部和范围
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
(2)服务器的ip或主机名进行hash
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
(3)访问节点如何计算
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
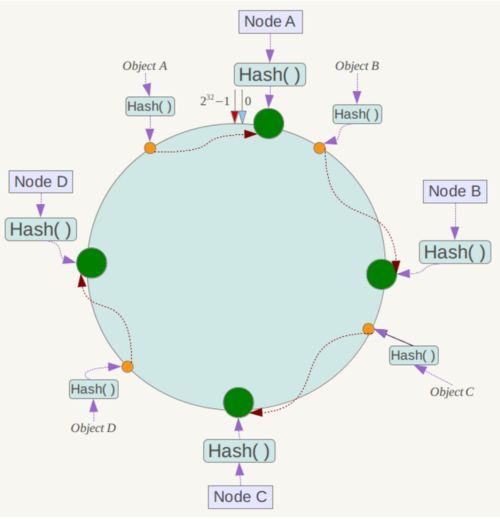
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。、
(4)宕机如何处理
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
(5)虚拟节点解决不均匀问题
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,

此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
一致性Hash代码实现
定义Hash的接口:
public interface HashFunction {
/**
* hash 函数
*
* @param key hash的key
* @return hashcode
*/
long hash(String key);
}
提供MD5实现hash函数的实现:
jdk提供默认提供的hashCode,并不能很好地保证平衡性。
public class Md5HashFunction implements HashFunction {
private MessageDigest md5 = null;
/**
* MD5 实现 hash函数
*
* @param key hash函数的key
* @return hashcode
*/
@Override
public long hash(String key) {
if (md5 == null) {
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException("no md5 algorithm found");
}
}
md5.reset();
md5.update(key.getBytes());
byte[] bKey = md5.digest();
//具体的哈希函数实现细节--每个字节 & 0xFF 再移位
long result = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16
| ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF));
return result & 0xffffffffL;
}
}
一致性Hash的负载均衡算法实现:
public class ConsistentHashLoadBalance implements LoadBalance {
/** Hash函数 */
private final HashFunction hashFunction;
/** 节点的复制因子, 虚拟节点个数 = 实际节点个数 * numberOfReplicas */
private final int numberOfReplicas;
/** 存储虚拟节点的hash值到真实节点的映射 */
private final SortedMap<Long, String> circle;
/** 用于源地址hash的参数(可以是IP/主机名/域名) */
private String requestHashParam;
public ConsistentHashLoadBalance(HashFunction hashFunction, int numberOfReplicas, String requestHashParam) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
this.requestHashParam = requestHashParam;
circle = new TreeMap<>();
}
/**
* 添加服务实例,并构建虚拟节点
*
* @param node 待添加的服务实例
*/
public void add(String node) {
for (int i = 0; i < numberOfReplicas; i++) {
/* 对于一个实际机器节点 node, 对应 numberOfReplicas 个虚拟节点
* 不同的虚拟节点(i不同)有不同的hash值,但都对应同一个实际机器node
* 虚拟node一般是均衡分布在环上的,数据存储在顺时针方向的虚拟node上
*/
circle.put(hashFunction.hash(node + i), node);
}
}
/**
* 移除节点
*
* @param node 待移除节点
*/
public void remove(String node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove(hashFunction.hash(node + i));
}
}
/**
* 获得一个最近的顺时针节点,根据给定的key 取Hash
* 然后再取得顺时针方向上最近的一个虚拟节点对应的实际节点
* 再从实际节点中取得 数据
*/
public String get(String key) {
if (circle.isEmpty()) {
return null;
}
// node 用String来表示,获得node在哈希环中的hashCode
long hash = hashFunction.hash(key);
//数据映射在两台虚拟机器所在环之间,就需要按顺时针方向寻找机器
if (! circle.containsKey(hash)) {
SortedMap<Long, String> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
/**
* 查询虚拟节点数量
*
* @return 虚拟节点数量
*/
public long getSize() {
return circle.size();
}
/**
* 路由
*
* @param serverMap 服务列表
* @return 选择到的一个服务
*/
@Override
public String route(Map<String, Integer> serverMap) {
Map<String, Integer> tempMap = new HashMap<>(serverMap.size());
tempMap.putAll(serverMap);
for (String server : tempMap.keySet()) {
// 依据实际节点 构建 虚拟节点
this.add(server);
}
return this.get(requestHashParam);
}
}
测试:
/**
* 测试 一致性hash 实现负载均衡
*/
@Test
public void testConsistentHashLoadBalance() {
System.out.println("---第一台机器测试---");
// 提前设置请求的Ip
LoadBalanceUtil.setRequestIp("192.122.2.1");
Map<String, Integer> routingMap =
LoadBalanceUtil.imitateRouting(new ConsistentHashLoadBalance(new Md5HashFunction(), 3,
LoadBalanceUtil.getRequestIp()), 5000);
// 统计路由结果
LoadBalanceUtil.countRoutingMap(routingMap);
System.out.println("---第二台机器测试---");
LoadBalanceUtil.setRequestIp("192.122.2.1");
routingMap = LoadBalanceUtil.imitateRouting(new ConsistentHashLoadBalance(new Md5HashFunction(), 3,
LoadBalanceUtil.getRequestIp()), 5000);
LoadBalanceUtil.countRoutingMap(routingMap);
System.out.println("---第三台机器测试---");
LoadBalanceUtil.setRequestIp("192.122.2.2");
routingMap = LoadBalanceUtil.imitateRouting(new ConsistentHashLoadBalance(new Md5HashFunction(), 3,
LoadBalanceUtil.getRequestIp()), 5000);
LoadBalanceUtil.countRoutingMap(routingMap);
System.out.println("---第四台机器测试---");
LoadBalanceUtil.setRequestIp("192.122.2.2");
routingMap = LoadBalanceUtil.imitateRouting(new ConsistentHashLoadBalance(new Md5HashFunction(), 3,
LoadBalanceUtil.getRequestIp()), 5000);
LoadBalanceUtil.countRoutingMap(routingMap);
System.out.println("---第五台机器测试---");
LoadBalanceUtil.setRequestIp("192.122.2.3");
routingMap = LoadBalanceUtil.imitateRouting(new ConsistentHashLoadBalance(new Md5HashFunction(), 3,
LoadBalanceUtil.getRequestIp()), 5000);
LoadBalanceUtil.countRoutingMap(routingMap);
}
模拟五个客户端请求,客户端①和②的IP相同,客户端③和④相同,客户端⑤不同。每个客户端分别请求4000次,共20000次。待查看所有请求到的服务实例情况。
结果:
---第一台机器测试---
IP:192.168.1.101,次数:4000
---第二台机器测试---
IP:192.168.1.101,次数:4000
---第三台机器测试---
IP:192.168.1.102,次数:4000
---第四台机器测试---
IP:192.168.1.102,次数:4000
---第五台机器测试---
IP:192.168.1.101,次数:4000
从结果上看,相同IP的客户端必然请求到相同的服务实例,不同IP的客户端也有可能请求到相同的实例。
其他
1. Tomcat 与 Nginx,Apache的区别是什么?
(1)定义
Apache HTTP服务器是一个模块化的服务器,可以运行在几乎所有广泛使用的计算机平台上。其属于应用服务器。Apache支持支持模块多,性能稳定,Apache本身是静态解析,适合静态HTML、图片等,但可以通过扩展脚本、模块等支持动态页面等。
(Apche可以支持PHPcgiperl,但是要使用Java的话,你需要Tomcat在Apache后台支撑,将Java请求由Apache转发给Tomcat处理。)
缺点:配置相对复杂,自身不支持动态页面。
Tomcat是应用(Java)服务器,它只是一个Servlet(JSP也翻译成Servlet)容器,可以认为是Apache的扩展,但是可以独立于Apache运行。
Nginx是俄罗斯人编写的十分轻量级的HTTP服务器,Nginx,它的发音为“engine X”,是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP 代理服务器。
(2)nginx相对于apache的优点
- 轻量级, 配置简洁,同样起web 服务,比apache占用更少的内存及资源 ,Nginx 静态处理性能比 Apache 高 3倍以上;
- 抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
- 高度模块化的设计,编写模块相对简单
- 提供负载均衡
- 社区活跃,各种高性能模块出品迅速
(3)apache 相对于nginx 的优点
- apache的 rewrite 比nginx 的强大;
- 支持动态页面;
- 支持的模块多,基本涵盖所有应用;
- 性能稳定,而nginx相对bug较多。
(4)三者对比:
Nginx优点:负载均衡、反向代理、处理静态文件优势。nginx处理静态请求的速度高于apache;
Apache优点:相对于Tomcat服务器来说处理静态文件是它的优势,速度快。Apache是静态解析,适合静态HTML、图片等。
Tomcat:动态解析容器,处理动态请求,是编译JSP\Servlet的容器,Nginx有动态分离机制,静态请求直接就可以通过Nginx处理,动态请求才转发请求到后台交由Tomcat进行处理。
(5)通常使用场景
虽然Tomcat也可以认为是HTTP服务器,但通常它仍然会和Nginx配合在一起使用:
- 动静态资源分离——运用Nginx的反向代理功能分发请求:所有动态资源的请求交给Tomcat,而静态资源的请求(例如图片、视频、CSS、JavaScript文件等)则直接由Nginx返回到浏览器,这样能大大减轻Tomcat的压力。
- 负载均衡,当业务压力增大时,可能一个Tomcat的实例不足以处理,那么这时可以启动多个Tomcat实例进行水平扩展,而Nginx的负载均衡功能可以把请求通过算法分发到各个不同的实例进行处理
Apache在处理动态有优势,Nginx并发性比较好,CPU内存占用低,如果rewrite频繁,那还是Apache较适合。
2.经典面试题:「请说出在淘宝网输入一个关键词到最终展示网页的整个流程,越详细越好」
这道面试题考验的非常全面,负载均衡是一个不错的角度。
参考:
- 什么是负载均衡原理? (负载架构演变)
- 架构 - 负载均衡 - 阿里云
- 关于负载均衡算法和Nginx的负载均衡算法参看:负载均衡的6种算法,Ngnix的5种算法!
- 关于负载均衡算法的实现参考:一篇有趣的负载均衡算法实现 (以上6中算法的Java实现)
- 几种简单的负载均衡算法及其Java代码实现
- 关于负载均衡的实现方式参看:全网最详细的负载均衡原理图解 (软硬件负载均衡的实现原理,LVS的原理)
- 就是要让你搞懂Nginx,这篇就够了! (Nginx基础概念)
- 8分钟带你深入浅出搞懂Nginx (很多Nginx的思考和面试题)
- Nginx为什么快到根本停不下来?
- tomcat 与 nginx,apache的区别是什么? (知乎,很多比较好的回答)
- tomcat与nginx,apache的区别是什么? (百度,很多比较好的分析)
- 聊聊一致性哈希 (使用木桶举例,更易理解)
- 把一致性哈希算法原理讲的最清楚的一篇 (原理讲的比较好)