Dubbo——负载均衡算法解析
Dubbo——负载均衡算法解析
1. 解析目的
- 当工作中需要设计像RPC、网关等中间件时,提供思路;
- 在平时项目中用到Dubbo的同学更加了解Dubbo的负载均衡机制。
2. 开始源码解析(基于Dubbo 2.7.8版本)
-
LoadBalance:负载均衡接口@SPI(RandomLoadBalance.NAME) public interface LoadBalance { /** * select one invoker in list. * * @param invokers invokers. * @param url refer url * @param invocation invocation. * @return selected invoker. */ @Adaptive("loadbalance") <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException; }该接口使用了Dubbo的SPI机制,默认实现是加权随机算法,所以Dubbo的缺省负载均衡策略是加权随机。
-
AbstractLoadBalance: 负载均衡抽象类,所有的负载均衡算法都继承了这个类。首先看实现接口的
select方法@Override public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) { if (CollectionUtils.isEmpty(invokers)) { return null; } if (invokers.size() == 1) { return invokers.get(0); } return doSelect(invokers, url, invocation); } protected abstract <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation);这里用到了模板模式,抽离了算法的前置条件,判断服务提供者是否为空或只有一个服务提供者,然后调用抽象方法
doSelect也就是每个负载均衡算法重写的方法。这个抽象类还抽离了计算权重的方法,因为Dubbo的负载均衡算法很强调权重的概念
/** * 获取服务提供者权重 * @param invoker * @param invocation * @return */ int getWeight(Invoker<?> invoker, Invocation invocation) { int weight; URL url = invoker.getUrl(); // 默认权重100 // org.apache.dubbo.registry.RegistryService的权重从registry.weight获取 if (REGISTRY_SERVICE_REFERENCE_PATH.equals(url.getServiceInterface())) { weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT); } else { weight = url.getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT); if (weight > 0) { // 服务提供者启动时间 long timestamp = invoker.getUrl().getParameter(TIMESTAMP_KEY, 0L); if (timestamp > 0L) { // 服务提供者运行时间 long uptime = System.currentTimeMillis() - timestamp; if (uptime < 0) { return 1; } // 需要预热的时间,默认10分钟 int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP); // 服务提供者的运行时间小于预热时间,则重新计算权重 if (uptime > 0 && uptime < warmup) { weight = calculateWarmupWeight((int)uptime, warmup, weight); } } } } return Math.max(weight, 0); } /** * 考虑预热情况下的权重计算 * @param uptime * @param warmup * @param weight * @return */ static int calculateWarmupWeight(int uptime, int warmup, int weight) { // 运行时间/(规定预热时间/权重),即运行时间*(规定预热时间/权重) // 当运行时间到达规定预热时间时,ww>=weight int ww = (int) ( uptime / ((float) warmup / weight)); // 小于1时,表示还没到规定预热时间 // 达到预热时间后返回权重 return ww < 1 ? 1 : (Math.min(ww, weight)); }AbstractLoadBalance这个类的作用:- 抽取了算法的前置条件,用到了模板模式
- 计算权重的方法
3. 加权随机算法(RandomLoadBalance)
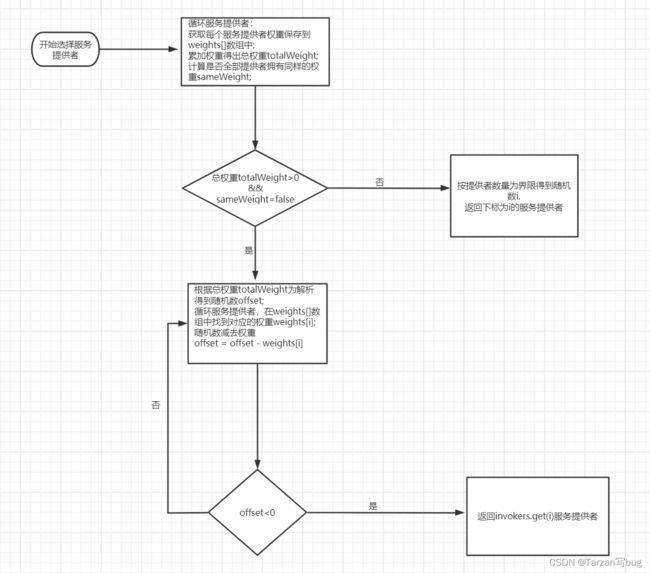
算法背景:这是在随机算法的基础上加上了权重的概念,比如有服务提供者[A, B, C],对应的权重为[1, 2, 3],可以将服务提供者的权重看成是左闭右开的区间,A的区间在[0,1),B的区间在[1,3),C的区间在[3,6),则总权重1+2+3=6。以总权重为界限生成随机数,看随机数落在哪个区间则返回对应的服务提供者。
RandomLoadBalance.java源码分析:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 服务提供者数量
int length = invokers.size();
// 每个提供者有相同的权重
boolean sameWeight = true;
// 保存每个提供者的权重
int[] weights = new int[length];
// 第一个提供者权重
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
// 总权重
int totalWeight = firstWeight;
// 循环服务提供者
for (int i = 1; i < length; i++) {
// 获取权重
int weight = getWeight(invokers.get(i), invocation);
// 保存到weights中
weights[i] = weight;
// 累加计算总权重
totalWeight += weight;
// 提供者的权重不等于第1个提供者权重时,sameWeight=false
// 这里的目的是只要有一个服务提供者的权重不等于第一个提供者的权重,说明提供者们的权重不都是一样
// 不都是一样则需要进行加权负载均衡,否则随机一个
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
// 总权重大于0且服务提供者之间没有相同权重
if (totalWeight > 0 && !sameWeight) {
// 总权重范围内获取随机数
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// 循环服务提供者,随机数-对应服务提供者权重,当小于0时表示落在对应的服务提供者里面,则返回对应的服务提供者
for (int i = 0; i < length; i++) {
offset -= weights[i];
if (offset < 0) {
return invokers.get(i);
}
}
}
// 如果所有服务提供者有相同权重或总权重等于0时,随机返回一个服务提供者
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
加权随机算法流程图:
4. 加权轮询算法(RoundRobinLoadBalance)
算法背景:在轮询的基础上加上权重计算,轮询是指将请求轮流分配给每个服务提供者,但现实情况不是每台服务器的性能都相近的,所以需要给性能更优越的服务器接收更多的请求。比如有服务提供者[A, B, C],对应的权重是[1, 2, 3],当发送6次请求时,A收到1次,B收到2次,C收到3次。而在经过多次算法优化后,目前这个版本使用的是参考于Nginx的平滑加权轮询。
平滑加权轮询:服务提供者[A, B, C],权重为[5, 1, 1],7次请求期望的结果是比较均匀地落在每个服务提供者上,比如[A, A, B, A, C, A, A]。所以算法是这样设计的,每个服务器对应两个权重,分别为weight和currentWeight,其中weight是固定的,currentWeight会动态调整,初始值为0。当有新请求进来时,遍历服务提供者,让它的currentWeight加上自身权重。遍历完成后,找到最大的currentWeight,并将其减去权重总和,然后返回相应的服务提供者。
Dubbo官方中的举例说明:
服务提供者[A, B, C]对应的权重[5, 1, 1]
| 请求编号 | currentWeight数组 | 选择结果 | 减去权重总和后的currentWeight数组 |
|---|---|---|---|
| 1 | [5, 1, 1] | A | [-2, 1, 1] |
| 2 | [3, 2, 2] | A | [-4, 2, 2] |
| 3 | [1, 3, 3] | B | [1, -4, 3] |
| 4 | [6, -3, 4] | A | [-1, -3, 4] |
| 5 | [4, -2, 5] | C | [4, -2, -2] |
| 6 | [9, -1, -1] | A | [2, -1, -1] |
| 7 | [7, 0, 0] | A | [0, 0, 0] |
RoundRobinLoadBalance.java源码分析:
/**
* 保存权重、currentWeight计算
*/
protected static class WeightedRoundRobin {
// 权重
private int weight;
// currentWeight
private AtomicLong current = new AtomicLong(0);
// 更新时间
private long lastUpdate;
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
// 设置权重时,currentWeight初始化为0
current.set(0);
}
public long increaseCurrent() {
// 返回currentWeight+weight
return current.addAndGet(weight);
}
public void sel(int total) {
// currentWeight-=总权重
current.addAndGet(-1 * total);
}
public long getLastUpdate() {
return lastUpdate;
}
public void setLastUpdate(long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
// 嵌套 Map 结构,存储的数据结构示例如下:
// {
// "UserService.query": {
// "url1": WeightedRoundRobin@123,
// "url2": WeightedRoundRobin@456,
// },
// "UserService.update": {
// "url1": WeightedRoundRobin@123,
// "url2": WeightedRoundRobin@456,
// }
// }
// 最外层为服务类名 + 方法名,第二层为 url 到 WeightedRoundRobin 的映射关系。
// 这里我们可以将 url 看成是服务提供者的 id
private ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<String, ConcurrentMap<String, WeightedRoundRobin>>();
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 比如com.demo.xxx.sayHello
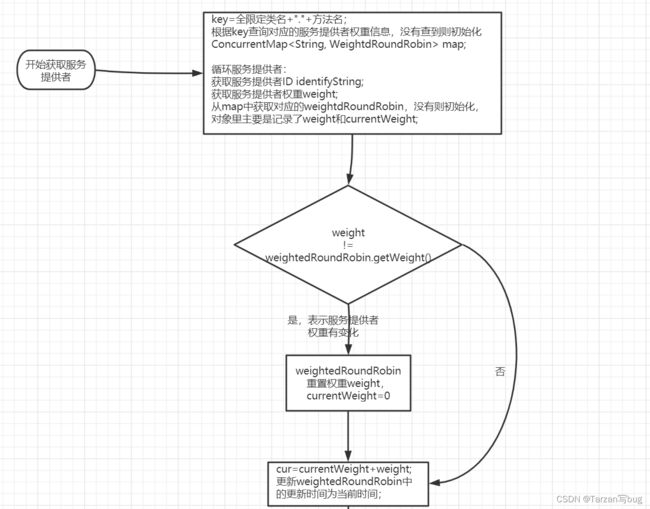
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
// 如果不存在key则实例化
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.computeIfAbsent(key, k -> new ConcurrentHashMap<>());
// 总权重
int totalWeight = 0;
// 最大权重
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
// 最大currentWeight服务提供者,也是最后返回的服务提供者
Invoker<T> selectedInvoker = null;
// 最大currentWeight服务提供者对应的WeightdRoundRobin对象
WeightedRoundRobin selectedWRR = null;
// 循环服务提供者
for (Invoker<T> invoker : invokers) {
// 可以看成是服务提供者ID
String identifyString = invoker.getUrl().toIdentityString();
// 获取服务提供者权重
int weight = getWeight(invoker, invocation);
// map中如果不存在服务提供者ID则初始化WeightedRoundRobin
WeightedRoundRobin weightedRoundRobin = map.computeIfAbsent(identifyString, k -> {
WeightedRoundRobin wrr = new WeightedRoundRobin();
// 设置权重,并将currentWeight置为0
wrr.setWeight(weight);
return wrr;
});
// 当服务提供者权重有更新时,则重置为最新的权重,currentWeight置为0
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// currentWeight+=weight
long cur = weightedRoundRobin.increaseCurrent();
// 重置更新时间
weightedRoundRobin.setLastUpdate(now);
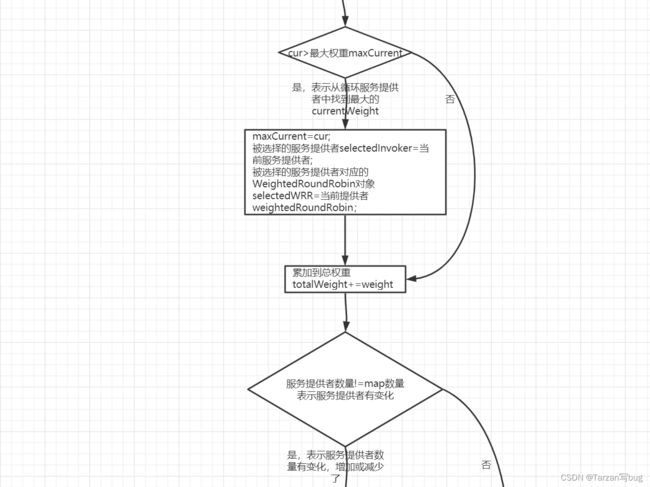
// currentWeight大于最大的权重时
if (cur > maxCurrent) {
// 最大权重重置为当前的currentWeight
maxCurrent = cur;
// 被选择的服务提供者重置为当前的服务提供者
selectedInvoker = invoker;
// 被选择的权重对象重置为当前的权重对象
selectedWRR = weightedRoundRobin;
}
// 累加到总权重
totalWeight += weight;
}
// 当服务提供者数量不等于map中的数量时,表示服务提供者有变化,前面已经说了map中的key可以理解为服务提供者ID
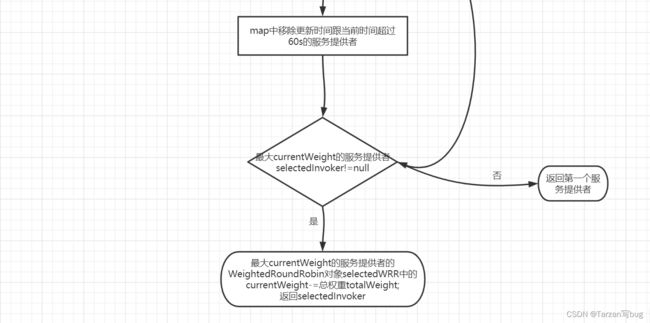
// 移除长时间没有更新的节点,默认60s
if (invokers.size() != map.size()) {
map.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD);
}
if (selectedInvoker != null) {
// currentWeight-=总权重
selectedWRR.sel(totalWeight);
// 返回最大current的服务提供者
return selectedInvoker;
}
// should not happen here
return invokers.get(0);
}
加权轮询算法流程图:
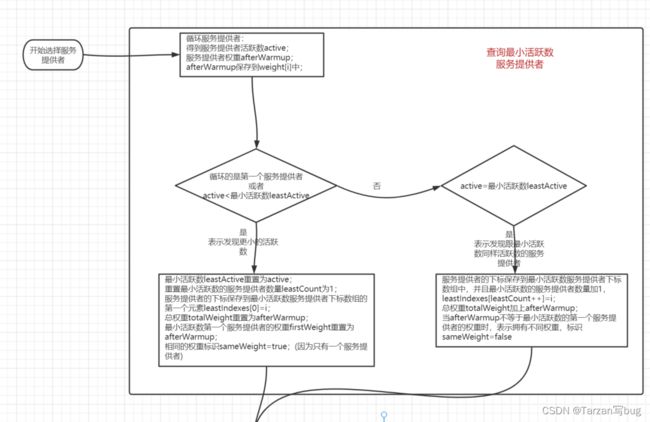
5. 加权最小活跃数算法(LeaseActiveLoadBalance)
算法背景:用活跃数表示服务提供者正在处理的请求,服务提供者初始活跃数为0,当请求到服务提供者时,活跃数加1,处理完请求后活跃数减1。活跃数越少表示服务提供者性能越高,所以在负载均衡的时候优先调用活跃数少的服务提供者。当两个服务提供者拥有同样的活跃数时,会调用权重更大的服务提供者。
LeastActiveLoadBalance.java源码分析:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 服务提供者数量
int length = invokers.size();
// 预设的最小活跃数
int leastActive = -1;
// 拥有最小活跃数的服务提供者数量
int leastCount = 0;
// 存储最小活跃数的服务提供者在invokers中的下标
int[] leastIndexes = new int[length];
// 每个服务提供者的权重
int[] weights = new int[length];
// 最小活跃数的服务提供者们的总权重(经过预热降权)
int totalWeight = 0;
// 第一个最小活跃数服务提供者权重
int firstWeight = 0;
// 最小活跃数的服务提供者的权重是否相同
boolean sameWeight = true;
// 循环服务提供者
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// 得到服务提供者的活跃数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// 降权后的权重
int afterWarmup = getWeight(invoker, invocation);
// 将权重保存到weight[]中
weights[i] = afterWarmup;
// 如果是第一个服务提供者,或者这个服务提供者的活跃数小于最小活跃数
if (leastActive == -1 || active < leastActive) {
// 重置最小活跃数为这个服务提供者的活跃数
leastActive = active;
// 重置最小活跃数的服务提供者为1
leastCount = 1;
// 将这个最小活跃数的服务提供者下标保存在leastIndexes的第一个元素
leastIndexes[0] = i;
// 重置最小活跃数的服务提供者总权重
totalWeight = afterWarmup;
// 记录最小活跃提供者的权重
firstWeight = afterWarmup;
// 只有一个服务提供者,则有相同权重
sameWeight = true;
// 当这个服务提供者的活跃数等于最小活跃数,表示有多个服务提供者拥有最小活跃数
} else if (active == leastActive) {
// 将下标记录到leastIndexes[]中,并且leastCount加1
leastIndexes[leastCount++] = i;
// 累加到总权重中
totalWeight += afterWarmup;
// 当权重不等于第一个最小活跃数服务提供者权重时,
// 表示最小活跃数服务提供者们拥有不同的权重
if (sameWeight && afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
// 从最小活跃数提供者中选择
// 如果服务提供者只有一个,则从leastIndexes[0]中得到下标返回对应的服务提供者
if (leastCount == 1) {
return invokers.get(leastIndexes[0]);
}
// 拥有不同权重,且总权重大于0
if (!sameWeight && totalWeight > 0) {
// 以总权重为界限得到随机数
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
// 循环最小活跃数的服务提供者
for (int i = 0; i < leastCount; i++) {
// 获取服务提供者下标
int leastIndex = leastIndexes[i];
// 随机数-对应服务提供者的权重,如果小于0,返回对应下标的服务提供者
offsetWeight -= weights[leastIndex];
if (offsetWeight < 0) {
return invokers.get(leastIndex);
}
}
}
// 如果最小活跃数的服务提供者拥有相同的权重,或总权重为0,则以服务提供者的数据为界限得到随机数
// 根据随机数到leastIndexes中获取服务提供者的下标,返回对应下标的服务提供者
return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
}
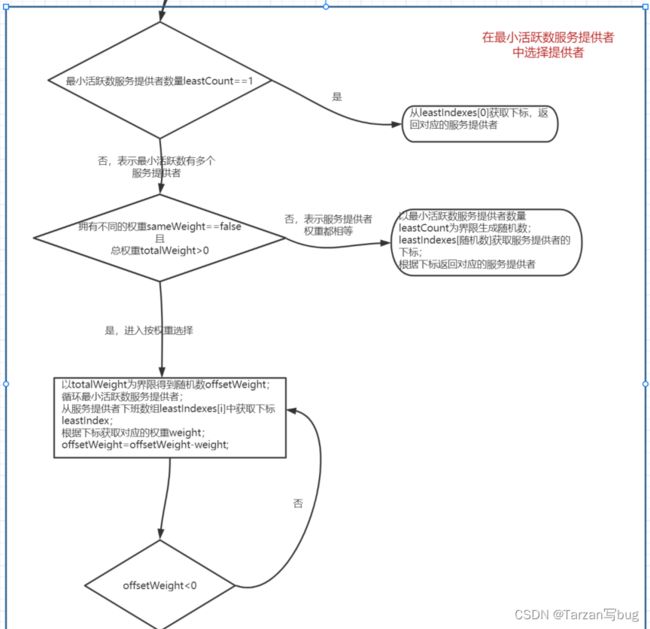
逻辑可以分了两部分,第一部分是获取最小活跃数服务提供者,因为有可能最小活跃数的提供者有多个,所以这里用数组保存最小活跃数的服务提供者下标和权重。第二部分是根据过滤的服务提供者进行选择,如果有多个服务提供者则根据权重选择,权重选择这里跟加权随机算法类似。
加权最小活跃数算法流程图:

6. 一致性Hash算法(ConsistentHashLoadBalance)
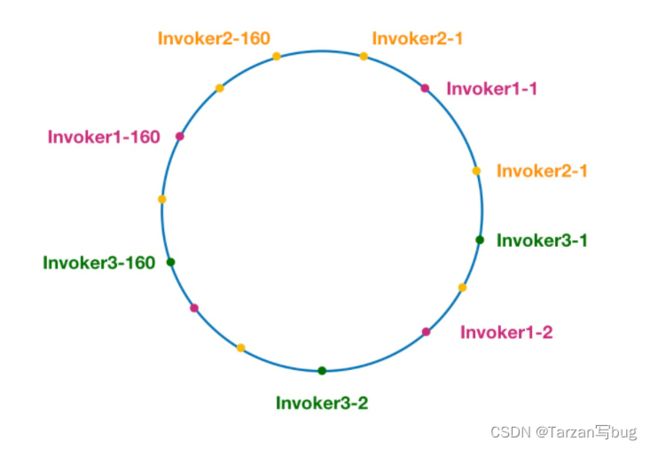
算法背景:根据服务提供者的ip或其他信息生成hash值,并放置在[0, 2^32-1]的圆环上,当请求过来时,根据请求中的信息生成一个hash值,在圆环中找到第一个大于或等于这个hash的节点,由此决定返回哪个服务提供者。而为了节点在圆环中分布均匀,引入虚拟节点,从而防止数据倾斜。
引用Dubbo官网中的图:
数据倾斜

虚拟节点: Invoker1-1、Invoker1-2、…Invoker1-160都是同一个服务提供者
ConsistentHashLoadBalance.java源码分析:
@SuppressWarnings("unchecked")
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// key = 全限定类名 + "." + 方法名,比如com.xxx.DemoService.sayHello
String methodName = RpcUtils.getMethodName(invocation);
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// 获取List的hashCode
int invokersHashCode = invokers.hashCode();
// 根据key查询是否有对应的ConsistentHashSelector
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
// 没查到
// 或者查到的hashCode跟当前服务提供者集合的hashCode不一样,表示服务提供者有变化
if (selector == null || selector.identityHashCode != invokersHashCode) {
// selectors存入key和新建ConsistentHashSelector实例
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, invokersHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
// 调用ConsistentHashSelector.select()获取服务提供者
return selector.select(invocation);
}
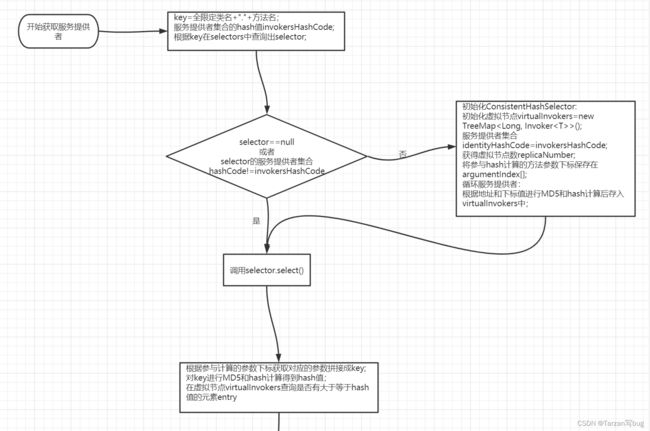
在doSelect()中做一下前置的检查和初始化,真正获取服务提供者的是ConsistentHashSelector.select(),接下来看看ConsistentHashSelector的初始化
// 虚拟节点存储
private final TreeMap<Long, Invoker<T>> virtualInvokers;
// 虚拟节点数
private final int replicaNumber;
// 服务提供者集合hashCode
private final int identityHashCode;
// 方法参数下标
private final int[] argumentIndex;
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 获取虚拟节点数,默认是160
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
// 获取参与计算hash的参数的下标值,默认取第一个参数
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
argumentIndex = new int[index.length];
// 循环参与hash计算的参数
for (int i = 0; i < index.length; i++) {
// 保存参数下标
argumentIndex[i] = Integer.parseInt(index[i]);
}
// 循环服务提供者
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
// 循环虚拟节点数除以4,为什么除以4,是为了配合后端hash算法
for (int i = 0; i < replicaNumber / 4; i++) {
// 地址+i进行md5计算
byte[] digest = md5(address + i);
// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数
for (int h = 0; h < 4; h++) {
// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算
// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算
// h = 2, h = 3 时过程同上
long m = hash(digest, h);
// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,
// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构
virtualInvokers.put(m, invoker);
}
}
}
}
初始化需要加入计算hash值的方法参数下标,计算出虚拟节点;
接着看选择服务提供者的过程select()
/**
* 选择服务提供者
* @param invocation
* @return
*/
public Invoker<T> select(Invocation invocation) {
// 参与hash的参数,拼接在一起
String key = toKey(invocation.getArguments());
// 对key进行md5
byte[] digest = md5(key);
// 计算hash值,在virtualInvokers中查询是否有对应的key,并返回对应的服务提供者
return selectForKey(hash(digest, 0));
}
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
// 循环参与计算的参数下标
for (int i : argumentIndex) {
// 在范围内将参数拼接
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
/**
* 根据hash查询virtualInvokers
* @param hash
* @return
*/
private Invoker<T> selectForKey(long hash) {
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
// 没有对应hash的服务提供者则返回第一个
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
逻辑:根据需要加入计算的参数拼接成key,对key进行md5后进行hash计算得到hash值,在虚拟节点中查找是否有这个hash值,有的话返回对应的服务提供者。
一致性Hash算法流程图:
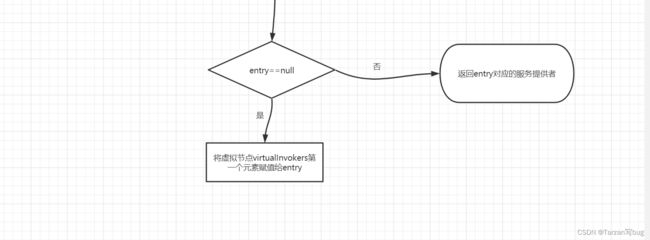
7. 加权最短响应时间算法(ShortestResponseLoadBalance)
算法背景:类似于最小活跃数算法,成功的响应时间越短,表示服务提供者处理请求越快,优先选择响应时间短的。
ShortestResponseLoadBalance.java源码分析:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 服务提供者数量
int length = invokers.size();
// 设定的最短响应时间
long shortestResponse = Long.MAX_VALUE;
// 拥有最短响应时间的服务提供者数量
int shortestCount = 0;
// 拥有最短响应时间的服务提供者下标
int[] shortestIndexes = new int[length];
// 每个服务提供者的权重
int[] weights = new int[length];
// 拥有最短响应时间的服务提供者总权重
int totalWeight = 0;
// 拥有最短响应时间的第一个服务提供者权重
int firstWeight = 0;
// 拥有最短响应时间的服务提供者是否有相同权重
boolean sameWeight = true;
// 循环服务提供者
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
RpcStatus rpcStatus = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
// 响应时间=活跃连接数*响应成功的平均执行时间
long succeededAverageElapsed = rpcStatus.getSucceededAverageElapsed();
int active = rpcStatus.getActive();
long estimateResponse = succeededAverageElapsed * active;
// 降权后的权重
int afterWarmup = getWeight(invoker, invocation);
// 将权重保存到weight[]
weights[i] = afterWarmup;
// 当前服务提供者响应时间<最短响应时间
if (estimateResponse < shortestResponse) {
// 重置最短响应时间为当前服务提供者响应时间
shortestResponse = estimateResponse;
// 最短响应时间服务提供者数量重置为1
shortestCount = 1;
// 服务提供者下标保存在shortestIndexes[]
shortestIndexes[0] = i;
// 总权重重置为当前服务提供者权重
totalWeight = afterWarmup;
// 第一个服务提供者权重重置为当前服务提供者权重
firstWeight = afterWarmup;
// 服务提供者同样权重表示为true,因为此时只有一个最短响应时间服务提供者
sameWeight = true;
// 当前服务提供者的响应时间等于最小响应时间,则表示最小响应时间有多个服务提供者
} else if (estimateResponse == shortestResponse) {
// 保存下标到shortestIndexes[],最小响应时间服务提供者数量加1
shortestIndexes[shortestCount++] = i;
// 当前服务提供者权重累加到总权重
totalWeight += afterWarmup;
// 当前服务提供者权重不等于第一个服务提供者权重时,置sameWeight为false,表示服务提供者拥有不同权重
if (sameWeight && i > 0
&& afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
// 当最小响应时间的服务提供者数量只有一个时
if (shortestCount == 1) {
// 获取下标返回对应的服务提供者
return invokers.get(shortestIndexes[0]);
}
// 服务提供者权重不同且总权重大于0,则需要根据权重选择服务提供者
if (!sameWeight && totalWeight > 0) {
// 根据总权重为界限生成随机数
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
// 循环最短响应时间服务提供者
for (int i = 0; i < shortestCount; i++) {
// 获取对应的服务提供者下标
int shortestIndex = shortestIndexes[i];
// 随机数-对应的服务提供者权重<0,则返回对应的服务提供者
offsetWeight -= weights[shortestIndex];
if (offsetWeight < 0) {
return invokers.get(shortestIndex);
}
}
}
// 服务提供者权重相同或总权重等于0,则以最短响应时间服务提供者数量为界限生成随机数
// 根据随机数找到对应服务提供者下标,返回对应的服务提供者
return invokers.get(shortestIndexes[ThreadLocalRandom.current().nextInt(shortestCount)]);
}
源码逻辑跟最小活跃数算法简直一模一样,只是将活跃数换成了响应时间。
8. 各负载均衡算法应用场景
| 算法 | 场景 |
|---|---|
| 加权随机算法 | 算法高效,服务提供者机器性能比较接近的场景 |
| 加权轮询算法 | 服务提供者机器硬件条件不同的场景 |
| 加权最小活跃数算法 | 当服务提供者机器硬件条件相同,但在运行时处理速度不同的场景 |
| 一致性Hash算法 | 相同参数的请求总是发到同一个服务提供者,查询比较多的场景,因为查询的适合参数一般不变 |
| 加权最短响应时间算法 | 跟加权最小活跃数算法类似 |
9. 总结
在阅读时首先要对算法背景进行理解,再去看源码效率会更快。关键在于对算法的理解,实现方法可以多种,比如Nginx和Ribbon中的负载均衡算法。
参考链接:
https://dubbo.apache.org/zh/docsv2.7/dev/source/loadbalance/
谢谢阅读,就分享到这,未完待续…
欢迎同频共振的那一部分人
作者公众号:Tarzan写bug