保姆级 Kubernetes 1.24 高可用集群部署中文指南
公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

作者:liugp
出处:https://www.cnblogs.com/liugp/p/16357445.html
一、前言
二、基础环境部署
1)前期准备(所有节点)
2)安装容器 docker(所有节点)
3)配置 k8s yum 源(所有节点)
4)将 sandbox_image 镜像源设置为阿里云 google_containers 镜像源(所有节点)
5)配置 containerd cgroup 驱动程序 systemd(所有节点)
6)开始安装 kubeadm,kubelet 和 kubectl(master 节点)
7)使用 kubeadm 初始化集群(master 节点)
8)安装 Pod 网络插件(CNI:Container Network Interface)(master)
9)node 节点加入 k8s 集群
10)配置 IPVS
11)集群高可用配置
12)部署 Nginx+Keepalived 高可用负载均衡器
三、k8s 管理平台 dashboard 环境部署
1)dashboard 部署
2)创建登录用户
3)配置 hosts 登录 dashboard web
四、k8s 镜像仓库 harbor 环境部署
1)安装 helm
2)配置 hosts
3)创建 stl 证书
4)安装 ingress
5)安装 nfs
6)创建 nfs provisioner 和持久化存储 SC
7)部署 Harbor(Https 方式)
一、前言
官网:https://kubernetes.io/
官方文档:https://kubernetes.io/zh-cn/docs/home/
二、基础环境部署
1)前期准备(所有节点)
1、修改主机名和配置 hosts
先部署 1master 和 2node 节点,后面再加一个 master 节点
# 在192.168.0.113执行
hostnamectl set-hostname k8s-master-168-0-113
# 在192.168.0.114执行
hostnamectl set-hostname k8s-node1-168-0-114
# 在192.168.0.115执行
hostnamectl set-hostname k8s-node2-168-0-115配置 hosts
cat >> /etc/hosts<2、配置 ssh 互信
# 直接一直回车就行
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master-168-0-113
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node1-168-0-114
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node2-168-0-1153、时间同步
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources4、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld5、关闭 swap
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab6、禁用 SELinux
# 临时关闭
setenforce 0
# 永久禁用
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config7、允许 iptables 检查桥接流量(可选,所有节点)
若要显式加载此模块,请运行 sudo modprobe br_netfilter,通过运行 lsmod | grep br_netfilter 来验证 br_netfilter 模块是否已加载,
sudo modprobe br_netfilter
lsmod | grep br_netfilter为了让 Linux 节点的 iptables 能够正确查看桥接流量,请确认 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
cat <2)安装容器 docker(所有节点)
提示:v1.24 之前的 Kubernetes 版本包括与 Docker Engine 的直接集成,使用名为 dockershim 的组件。这种特殊的直接整合不再是 Kubernetes 的一部分 (这次删除被作为 v1.20 发行版本的一部分宣布)。你可以阅读检查 Dockershim 弃用是否会影响你 以了解此删除可能会如何影响你。要了解如何使用 dockershim 进行迁移,请参阅从 dockershim 迁移。
# 配置yum源
cd /etc/yum.repos.d ; mkdir bak; mv CentOS-Linux-* bak/
# centos7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# centos8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动
systemctl start docker
# 开机自启
systemctl enable docker
# 查看版本号
docker --version
# 查看版本具体信息
docker version
# Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat >/etc/docker/daemon.json<【温馨提示】dockerd 实际真实调用的还是 containerd 的 api 接口,containerd 是 dockerd 和 runC 之间的一个中间交流组件。所以启动 docker 服务的时候,也会启动 containerd 服务的。
3)配置 k8s yum 源(所有节点)
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF4)将 sandbox_image 镜像源设置为阿里云 google_containers 镜像源(所有节点)
# 导出默认配置,config.toml这个文件默认是不存在的
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
5)配置 containerd cgroup 驱动程序 systemd(所有节点)
kubernets 自v 1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是 containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd6)开始安装 kubeadm,kubelet 和 kubectl(master 节点)
# 不指定版本就是最新版本,当前最新版就是1.24.1
yum install -y kubelet-1.24.1 kubeadm-1.24.1 kubectl-1.24.1 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
查看日志,发现有报错,报错如下:
kubelet.service: Main process exited, code=exited, status=1/FAILURE kubelet.service: Failed with result 'exit-code'.

【解释】重新安装(或第一次安装)k8s,未经过 kubeadm init 或者 kubeadm join 后,kubelet 会不断重启,这个是正常现象……,执行 init 或 join 后问题会自动解决,对此官网有如下描述,也就是此时不用理会 kubelet.service。
查看版本
kubectl version
yum info kubeadm
7)使用 kubeadm 初始化集群(master 节点)
最好提前把镜像下载好,这样安装快
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.24.1
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.24.1
docker pull registry.aliyuncs.com/google_containers/pause:3.7
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.3-0
docker pull registry.aliyuncs.com/google_containers/coredns:v1.8.6集群初始化
kubeadm init \
--apiserver-advertise-address=192.168.0.113 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.24.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。这里的ip为master节点ip,记得更换。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
# --control-plane-endpoint cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:192.168.0.113 cluster-endpoint。 这将允许你将 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。 稍后你可以修改 cluster-endpoint 以指向高可用性方案中的负载均衡器的地址。【温馨提示】kubeadm 不支持将没有
--control-plane-endpoint参数的单个控制平面集群转换为高可用性集群。
重置再初始化
kubeadm reset
rm -fr ~/.kube/ /etc/kubernetes/* var/lib/etcd/*
kubeadm init \
--apiserver-advertise-address=192.168.0.113 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.24.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。这里的ip为master节点ip,记得更换。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
# --control-plane-endpoint cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:192.168.0.113 cluster-endpoint。 这将允许你将 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。 稍后你可以修改 cluster-endpoint 以指向高可用性方案中的负载均衡器的地址。配置环境变量
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 临时生效(退出当前窗口重连环境变量失效)
export KUBECONFIG=/etc/kubernetes/admin.conf
# 永久生效(推荐)
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile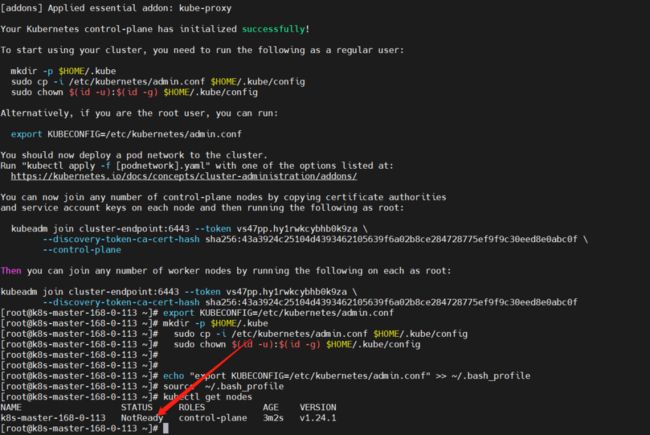
发现节点还是有问题,查看日志 /var/log/messages
"Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"

接下来就是安装 Pod 网络插件
8)安装 Pod 网络插件(CNI:Container Network Interface)(master)
你必须部署一个基于 Pod 网络插件的 容器网络接口 (CNI),以便你的 Pod 可以相互通信。
# 最好提前下载镜像(所有节点)
docker pull quay.io/coreos/flannel:v0.14.0
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml如果上面安装失败,则下载我百度里的,离线安装
链接:https://pan.baidu.com/s/1HB9xuO3bssAW7v5HzpXkeQ
提取码:8888
再查看 node 节点,就已经正常了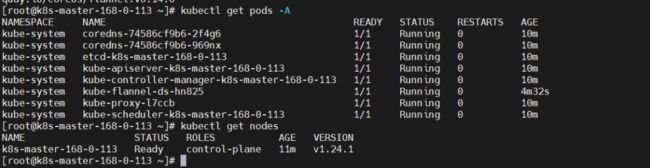
9)node 节点加入 k8s 集群
先安装 kubelet
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
systemctl status kubelet如果没有令牌,可以通过在控制平面节点上运行以下命令来获取令牌:
kubeadm token list默认情况下,令牌会在24小时后过期。如果要在当前令牌过期后将节点加入集群, 则可以通过在控制平面节点上运行以下命令来创建新令牌:
kubeadm token create
# 再查看
kubeadm token list如果你没有 –discovery-token-ca-cert-hash 的值,则可以通过在控制平面节点上执行以下命令链来获取它:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'如果执行 kubeadm init 时没有记录下加入集群的命令,可以通过以下命令重新创建(推荐)一般不用上面的分别获取 token 和 ca-cert-hash 方式,执行以下命令一气呵成:
kubeadm token create --print-join-command这里需要等待一段时间,再查看节点节点状态,因为需要安装 kube-proxy 和 flannel。
kubectl get pods -A
kubectl get nodes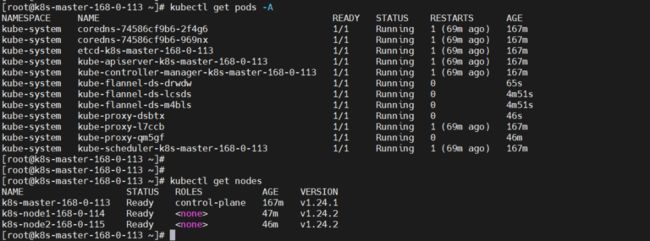
10)配置 IPVS
【问题】集群内无法 ping 通 ClusterIP(或 ServiceName)
1、加载 ip_vs 相关内核模块
modprobe -- ip_vs
modprobe -- ip_vs_sh
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr所有节点验证开启了 ipvs:
lsmod |grep ip_vs2、安装 ipvsadm 工具
yum install ipset ipvsadm -y3、编辑 kube-proxy 配置文件,mode 修改成 ipvs
kubectl edit configmap -n kube-system kube-proxy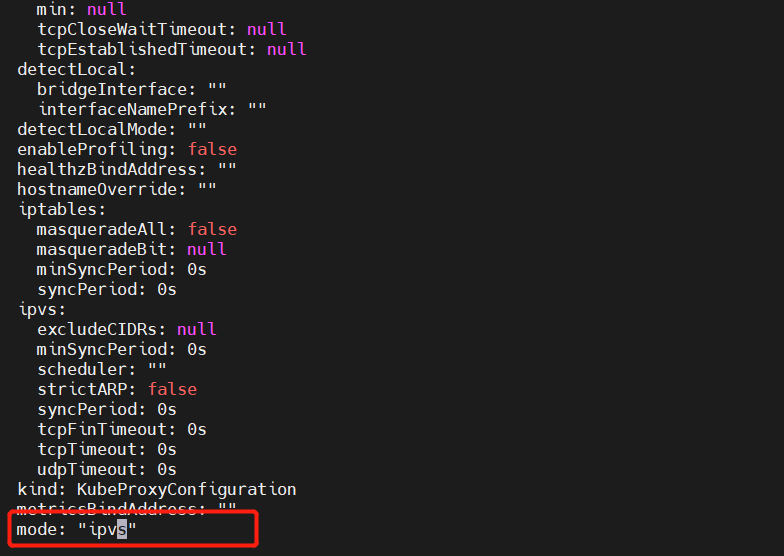
4、重启 kube-proxy
# 先查看
kubectl get pod -n kube-system | grep kube-proxy
# 再delete让它自拉起
kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
# 再查看
kubectl get pod -n kube-system | grep kube-proxy
5、查看 ipvs 转发规则
ipvsadm -Ln
11)集群高可用配置
配置高可用(HA)Kubernetes 集群实现的两种方案:
使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存(本章使用),架构图如下:

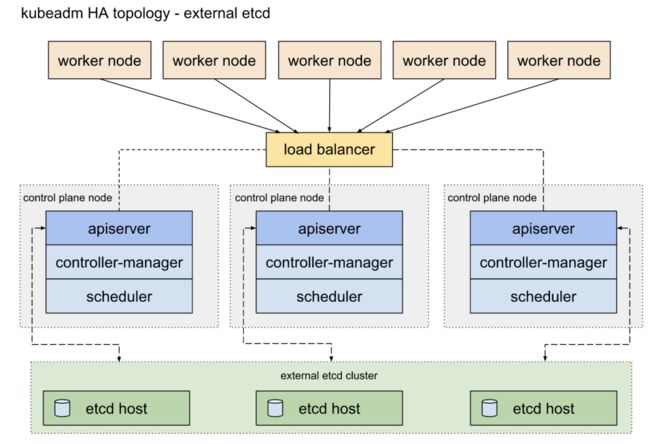
使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行,架构图如下:
这里新增一台机器作为另外一个 master 节点:192.168.0.116 配置跟上面 master 节点一样。只是不需要最后一步初始化了。
1、修改主机名和配置 hosts
所有节点都统一如下配置:
# 在192.168.0.113执行
hostnamectl set-hostname k8s-master-168-0-113
# 在192.168.0.114执行
hostnamectl set-hostname k8s-node1-168-0-114
# 在192.168.0.115执行
hostnamectl set-hostname k8s-node2-168-0-115
# 在192.168.0.116执行
hostnamectl set-hostname k8s-master2-168-0-116配置 hosts
cat >> /etc/hosts<2、配置 ssh 互信
# 直接一直回车就行
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master-168-0-113
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node1-168-0-114
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-node2-168-0-115
ssh-copy-id -i ~/.ssh/id_rsa.pub root@k8s-master2-168-0-1163、时间同步
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources7、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld4、关闭 swap
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab5、禁用 SELinux
# 临时关闭
setenforce 0
# 永久禁用
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config6、允许 iptables 检查桥接流量(可选,所有节点)
若要显式加载此模块,请运行 sudo modprobe br_netfilter,通过运行 lsmod | grep br_netfilter 来验证 br_netfilter 模块是否已加载,
sudo modprobe br_netfilter
lsmod | grep br_netfilter为了让 Linux 节点的 iptables 能够正确查看桥接流量,请确认 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
cat <7、安装容器 docker(所有节点)
提示:v1.24 之前的 Kubernetes 版本包括与 Docker Engine 的直接集成,使用名为 dockershim 的组件。这种特殊的直接整合不再是 Kubernetes 的一部分 (这次删除被作为 v1.20 发行版本的一部分宣布)。你可以阅读检查 Dockershim 弃用是否会影响你 以了解此删除可能会如何影响你。要了解如何使用 dockershim 进行迁移,请参阅从 dockershim 迁移。
# 配置yum源
cd /etc/yum.repos.d ; mkdir bak; mv CentOS-Linux-* bak/
# centos7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# centos8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动
systemctl start docker
# 开机自启
systemctl enable docker
# 查看版本号
docker --version
# 查看版本具体信息
docker version
# Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat >/etc/docker/daemon.json<【温馨提示】dockerd 实际真实调用的还是 containerd 的 api 接口,containerd 是 dockerd 和 runC 之间的一个中间交流组件。所以启动 docker 服务的时候,也会启动 containerd 服务的。
8、配置 k8s yum 源(所有节点)
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF9、将 sandbox_image 镜像源设置为阿里云 google_containers 镜像源(所有节点)
# 导出默认配置,config.toml这个文件默认是不存在的
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
10、配置 containerd cgroup 驱动程序 systemd
kubernets 自v 1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是 containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd11、开始安装 kubeadm,kubelet 和 kubectl(master 节点)
# 不指定版本就是最新版本,当前最新版就是1.24.1
yum install -y kubelet-1.24.1 kubeadm-1.24.1 kubectl-1.24.1 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
# 查看版本
kubectl version
yum info kubeadm12、加入 k8s 集群
# 证如果过期了,可以使用下面命令生成新证书上传,这里会打印出certificate key,后面会用到
kubeadm init phase upload-certs --upload-certs
# 你还可以在 【init】期间指定自定义的 --certificate-key,以后可以由 join 使用。 要生成这样的密钥,可以使用以下命令(这里不执行,就用上面那个自命令就可以了):
kubeadm certs certificate-key
kubeadm token create --print-join-command
kubeadm join cluster-endpoint:6443 --token wswrfw.fc81au4yvy6ovmhh --discovery-token-ca-cert-hash sha256:43a3924c25104d4393462105639f6a02b8ce284728775ef9f9c30eed8e0abc0f --control-plane --certificate-key 8d2709697403b74e35d05a420bd2c19fd8c11914eb45f2ff22937b245bed5b68
# --control-plane 标志通知 kubeadm join 创建一个新的控制平面。加入master必须加这个标记
# --certificate-key ... 将导致从集群中的 kubeadm-certs Secret 下载控制平面证书并使用给定的密钥进行解密。这里的值就是上面这个命令(kubeadm init phase upload-certs --upload-certs)打印出的key。
根据提示执行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config查看
kubectl get nodes
kubectl get pods -A -owide
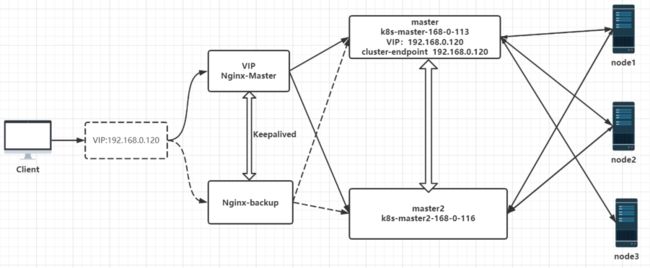
虽然现在已经有两个 master 了,但是对外还是只能有一个入口的,所以还得要一个负载均衡器,如果一个 master 挂了,会自动切到另外一个 master 节点。
12)部署 Nginx+Keepalived 高可用负载均衡器
1、安装 Nginx 和 Keepalived
# 在两个master节点上执行
yum install nginx keepalived -y2、Nginx 配置
在两个 master 节点配置
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
# Master APISERVER IP:PORT
server 192.168.0.113:6443;
# Master2 APISERVER IP:PORT
server 192.168.0.116:6443;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF【温馨提示】如果只保证高可用,不配置 k8s-apiserver 负载均衡的话,可以不装 nginx,但是最好还是配置一下 k8s-apiserver 负载均衡。
3、Keepalived 配置(master)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.0.120/24
}
track_script {
check_nginx
}
}
EOFvrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移)virtual_ipaddress:虚拟 IP(VIP)
检查 nginx 状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh4、Keepalived 配置(backup)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.120/24
}
track_script {
check_nginx
}
}
EOF检查 nginx 状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh5、启动并设置开机启动
systemctl daemon-reload
systemctl restart nginx && systemctl enable nginx && systemctl status nginx
systemctl restart keepalived && systemctl enable keepalived && systemctl status keepalived查看 VIP
ip a
6、修改 hosts(所有节点)
将 cluster-endpoint 之前执行的 ip 修改执行现在的 VIP
192.168.0.113 k8s-master-168-0-113
192.168.0.114 k8s-node1-168-0-114
192.168.0.115 k8s-node2-168-0-115
192.168.0.116 k8s-master2-168-0-116
192.168.0.120 cluster-endpoint7、测试验证
查看版本(负载均衡测试验证)
curl -k https://cluster-endpoint:16443/version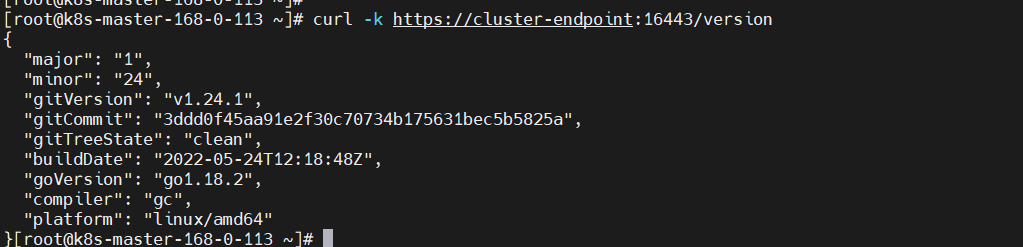
高可用测试验证,将 k8s-master-168-0-113 节点关机
shutdown -h now
curl -k https://cluster-endpoint:16443/version
kubectl get nodes -A
kubectl get pods -A【温馨提示】堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
三、k8s 管理平台 dashboard 环境部署
1)dashboard 部署
GitHub 地址:https://github.com/kubernetes/dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.0/aio/deploy/recommended.yaml
kubectl get pods -n kubernetes-dashboard但是这个只能内部访问,所以要外部访问,要么部署 ingress,要么就是设置 service NodePort 类型。这里选择 service 暴露端口。
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.0/aio/deploy/recommended.yaml修改后的内容如下:
# Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31443
selector:
k8s-app: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kubernetes-dashboard
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-csrf
namespace: kubernetes-dashboard
type: Opaque
data:
csrf: ""
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
rules:
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs", "kubernetes-dashboard-csrf"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster", "dashboard-metrics-scraper"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:", "dashboard-metrics-scraper", "http:dashboard-metrics-scraper"]
verbs: ["get"]
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.6.0
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
nodeSelector:
"kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
ports:
- port: 8000
targetPort: 8000
selector:
k8s-app: dashboard-metrics-scraper
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: dashboard-metrics-scraper
template:
metadata:
labels:
k8s-app: dashboard-metrics-scraper
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
containers:
- name: dashboard-metrics-scraper
image: kubernetesui/metrics-scraper:v1.0.8
ports:
- containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 8000
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- mountPath: /tmp
name: tmp-volume
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
serviceAccountName: kubernetes-dashboard
nodeSelector:
"kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
volumes:
- name: tmp-volume
emptyDir: {}
重新部署
kubectl delete -f recommended.yaml
kubectl apply -f recommended.yaml
kubectl get svc,pods -n kubernetes-dashboard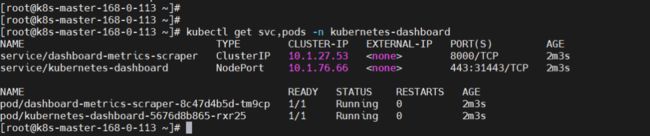
2)创建登录用户
cat >ServiceAccount.yaml<创建并获取登录 token
kubectl -n kubernetes-dashboard create token admin-user3)配置 hosts 登录 dashboard web
192.168.0.120 cluster-endpoint登录:https://cluster-endpoint:31443
输入上面创建的 token 登录
四、k8s 镜像仓库 harbor 环境部署
GitHub 地址:https://github.com/helm/helm/releases
这使用 helm 安装,所以得先安装 helm
1)安装 helm
mkdir -p /opt/k8s/helm && cd /opt/k8s/helm
wget https://get.helm.sh/helm-v3.9.0-rc.1-linux-amd64.tar.gz
tar -xf helm-v3.9.0-rc.1-linux-amd64.tar.gz
ln -s /opt/k8s/helm/linux-amd64/helm /usr/bin/helm
helm version
helm help2)配置 hosts
192.168.0.120 myharbor.com3)创建 stl 证书
mkdir /opt/k8s/helm/stl && cd /opt/k8s/helm/stl
# 生成 CA 证书私钥
openssl genrsa -out ca.key 4096
# 生成 CA 证书
openssl req -x509 -new -nodes -sha512 -days 3650 \
-subj "/C=CN/ST=Guangdong/L=Shenzhen/O=harbor/OU=harbor/CN=myharbor.com" \
-key ca.key \
-out ca.crt
# 创建域名证书,生成私钥
openssl genrsa -out myharbor.com.key 4096
# 生成证书签名请求 CSR
openssl req -sha512 -new \
-subj "/C=CN/ST=Guangdong/L=Shenzhen/O=harbor/OU=harbor/CN=myharbor.com" \
-key myharbor.com.key \
-out myharbor.com.csr
# 生成 x509 v3 扩展
cat > v3.ext <<-EOF
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[alt_names]
DNS.1=myharbor.com
DNS.2=*.myharbor.com
DNS.3=hostname
EOF
#创建 Harbor 访问证书
openssl x509 -req -sha512 -days 3650 \
-extfile v3.ext \
-CA ca.crt -CAkey ca.key -CAcreateserial \
-in myharbor.com.csr \
-out myharbor.com.crt4)安装 ingress
ingress 官方网站:https://kubernetes.github.io/ingress-nginx/
ingress 仓库地址:https://github.com/kubernetes/ingress-nginx
部署文档:https://kubernetes.github.io/ingress-nginx/deploy/
1、通过 helm 部署
helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace2、通过 YAML 文件安装(本章使用这个方式安装 ingress)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.2.0/deploy/static/provider/cloud/deploy.yaml如果下载镜像失败,可以用以下方式修改镜像地址再安装
# 可以先把镜像下载,再安装
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.2.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.1.1
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.2.0/deploy/static/provider/cloud/deploy.yaml
# 修改镜像地址
sed -i '[email protected]/ingress-nginx/controller:v1.2.0\(.*\)@registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.2.0@' deploy.yaml
sed -i '[email protected]/ingress-nginx/kube-webhook-certgen:v1.1.1\(.*\)[email protected]/google_containers/kube-webhook-certgen:v1.1.1@' deploy.yaml
###还需要修改两地方
#1、kind: 类型修改成DaemonSet,replicas: 注销掉,因为DaemonSet模式会每个节点运行一个pod
#2、在添加一条:hostnetwork:true
#3、把LoadBalancer修改成NodePort
#4、在--validating-webhook-key下面添加- --watch-ingress-without-class=true
#5、设置master节点可调度
kubectl taint nodes k8s-master-168-0-113 node-role.kubernetes.io/control-plane:NoSchedule-
kubectl taint nodes k8s-master2-168-0-116 node-role.kubernetes.io/control-plane:NoSchedule-
kubectl apply -f deploy.yaml
5)安装 nfs
1、所有节点安装 nfs
yum -y install nfs-utils rpcbind2、在 master 节点创建共享目录并授权
mkdir /opt/nfsdata
# 授权共享目录
chmod 666 /opt/nfsdata3、配置 exports 文件
cat > /etc/exports<exportfs 命令
常用选项
-a 全部挂载或者全部卸载
-r 重新挂载
-u 卸载某一个目录
-v 显示共享目录 以下操作在服务端上
4、启动 rpc 和 nfs(客户端只需要启动 rpc 服务)(注意顺序)
systemctl start rpcbind
systemctl start nfs-server
systemctl enable rpcbind
systemctl enable nfs-server查看
showmount -e
# VIP
showmount -e 192.168.0.120-e 显示 NFS 服务器的共享列表
-a 显示本机挂载的文件资源的情况 NFS 资源的情况
-v 显示版本号
5、客户端
# 安装
yum -y install nfs-utils rpcbind
# 启动rpc服务
systemctl start rpcbind
systemctl enable rpcbind
# 创建挂载目录
mkdir /mnt/nfsdata
# 挂载
echo "192.168.0.120:/opt/nfsdata /mnt/nfsdata nfs defaults 0 1">> /etc/fstab
mount -a6、rsync 数据同步
【1】rsync 安装
# 两端都得安装
yum -y install rsync【2】配置
在/etc/rsyncd.conf 中添加
cat >/etc/rsyncd.conf<配置 rsyncd_users.db
cat >/etc/rsyncd_users.db<【3】rsyncd.conf 常用参数详解
rsyncd.conf 参数
| rsyncd.conf 参数 | 参数说明 |
|---|---|
| uid=root | rsync 使用的用户。 |
| gid=root | rsync 使用的用户组(用户所在的组) |
| use chroot=no | 如果为 true,daemon 会在客户端传输文件前“chroot to the path”。这是一种安全配置,因为我们大多数都在内网,所以不配也没关系 |
| max connections=200 | 设置最大连接数,默认 0,意思无限制,负值为关闭这个模块 |
| timeout=400 | 默认为 0,表示 no timeout,建议 300-600(5-10 分钟) |
| pid file | rsync daemon 启动后将其进程 pid 写入此文件。如果这个文件存在,rsync 不会覆盖该文件,而是会终止 |
| lock file | 指定 lock 文件用来支持“max connections”参数,使得总连接数不会超过限制 |
| log file | 不设或者设置错误,rsync 会使用 rsyslog 输出相关日志信息 |
| ignore errors | 忽略 I/O 错误 |
| read only=false | 指定客户端是否可以上传文件,默认对所有模块为 true |
| list=false | 是否允许客户端可以查看可用模块列表,默认为可以 |
| hosts allow | 指定可以联系的客户端主机名或和 ip 地址或地址段,默认情况没有此参数,即都可以连接 |
| hosts deny | 指定不可以联系的客户端主机名或 ip 地址或地址段,默认情况没有此参数,即都可以连接 |
| auth users | 指定以空格或逗号分隔的用户可以使用哪些模块,用户不需要在本地系统中存在。默认为所有用户无密码访问 |
| secrets file | 指定用户名和密码存放的文件,格式;用户名;密码,密码不超过 8 位 |
| [backup] | 这里就是模块名称,需用中括号扩起来,起名称没有特殊要求,但最好是有意义的名称,便于以后维护 |
| path | 这个模块中,daemon 使用的文件系统或目录,目录的权限要注意和配置文件中的权限一致,否则会遇到读写的问题 |
【4】rsync 常用命令参数详解
rsync --help
rsync [选项] 原始位置 目标位置
常用选项 说明
-r 递归模式,包含目录及子目录中的所有文件
-l 对于符号链接文件仍然复制为符号链接文件
-v 显示同步过程的详细信息
-z 在传输文件时进行压缩goD
-p 保留文件的权限标记
-a 归档模式,递归并保留对象属性,等同于-rlpt
-t 保留文件的时间标记
-g 保留文件的属组标记(仅超级用户使用)
-o 保留文件的属主标记(仅超级用户使用)
-H 保留硬链接文件
-A 保留ACL属性信息
-D 保留设备文件及其他特殊文件
--delete 删除目标位置有而原始位置没有的文件
--checksum 根据对象的校验和来决定是否跳过文件【5】启动服务(数据源机器)
#rsync监听端口:873
#rsync运行模式:C/S
rsync --daemon --config=/etc/rsyncd.conf
netstat -tnlp|grep :873【6】执行命令同步数据
# 在目的机器上执行
# rsync -avz 用户名@源主机地址/源目录 目的目录
rsync -avz [email protected]:/opt/nfsdata/* /opt/nfsdata/【7】crontab 定时同步
# 配置crontab, 每五分钟同步一次,这种方式不好
*/5 * * * * rsync -avz [email protected]:/opt/nfsdata/* /opt/nfsdata/【温馨提示】crontab 定时同步数据不太好,可以使用
rsync+inotify做数据实时同步,这里篇幅有点长了,先不讲,如果后面有时间会出一篇单独文章来讲。
6)创建 nfs provisioner 和持久化存储 SC
【温馨提示】这里跟我之前的文章有点不同,之前的方式也不适用新版本。
GitHub 地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
helm 部署 nfs-subdir-external-provisioner
1、添加 helm 仓库
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/2、helm 安装 nfs provisioner
【温馨提示】默认镜像是无法访问的,这里使用 dockerhub 搜索到的镜像
willdockerhub/nfs-subdir-external-provisioner:v4.0.2,还有就是 StorageClass 不分命名空间,所有在所有命名空间下都可以使用。
helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
--namespace=nfs-provisioner \
--create-namespace \
--set image.repository=willdockerhub/nfs-subdir-external-provisioner \
--set image.tag=v4.0.2 \
--set replicaCount=2 \
--set storageClass.name=nfs-client \
--set storageClass.defaultClass=true \
--set nfs.server=192.168.0.120 \
--set nfs.path=/opt/nfsdata【温馨提示】上面 nfs.server 设置为 VIP,可实现高可用。
3、查看
kubectl get pods,deploy,sc -n nfs-provisioner
7)部署 Harbor(Https 方式)
1、创建 Namespace
kubectl create ns harbor2、创建证书秘钥
kubectl create secret tls myharbor.com --key myharbor.com.key --cert myharbor.com.crt -n harbor
kubectl get secret myharbor.com -n harbor3、添加 Chart 库
helm repo add harbor https://helm.goharbor.io4、通过 helm 安装 harbor
helm install myharbor --namespace harbor harbor/harbor \
--set expose.ingress.hosts.core=myharbor.com \
--set expose.ingress.hosts.notary=notary.myharbor.com \
--set-string expose.ingress.annotations.'nginx\.org/client-max-body-size'="1024m" \
--set expose.tls.secretName=myharbor.com \
--set persistence.persistentVolumeClaim.registry.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.jobservice.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.database.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.redis.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.trivy.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.chartmuseum.storageClass=nfs-client \
--set persistence.enabled=true \
--set externalURL=https://myharbor.com \
--set harborAdminPassword=Harbor12345这里稍等一段时间在查看资源状态
kubectl get ingress,svc,pods,pvc -n harbor
5、ingress 没有 ADDRESS 问题解决
【分析】,发现"error: endpoints “default-http-backend” not found"
cat << EOF > default-http-backend.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: default-http-backend
labels:
app: default-http-backend
namespace: harbor
spec:
replicas: 1
selector:
matchLabels:
app: default-http-backend
template:
metadata:
labels:
app: default-http-backend
spec:
terminationGracePeriodSeconds: 60
containers:
- name: default-http-backend
# Any image is permissible as long as:
# 1. It serves a 404 page at /
# 2. It serves 200 on a /healthz endpoint
image: registry.cn-hangzhou.aliyuncs.com/google_containers/defaultbackend:1.4
# image: gcr.io/google_containers/defaultbackend:1.4
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
ports:
- containerPort: 8080
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: default-http-backend
namespace: harbor
labels:
app: default-http-backend
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: default-http-backend
EOF
kubectl apply -f default-http-backend.yaml6、卸载重新部署
# 卸载
helm uninstall myharbor -n harbor
kubectl get pvc -n harbor| awk 'NR!=1{print $1}' | xargs kubectl delete pvc -n harbor
# 部署
helm install myharbor --namespace harbor harbor/harbor \
--set expose.ingress.hosts.core=myharbor.com \
--set expose.ingress.hosts.notary=notary.myharbor.com \
--set-string expose.ingress.annotations.'nginx\.org/client-max-body-size'="1024m" \
--set expose.tls.secretName=myharbor.com \
--set persistence.persistentVolumeClaim.registry.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.jobservice.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.database.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.redis.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.trivy.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.chartmuseum.storageClass=nfs-client \
--set persistence.enabled=true \
--set externalURL=https://myharbor.com \
--set harborAdminPassword=Harbor12345
5、访问 harbor
https://myharbor.com
账号/密码:admin/Harbor12345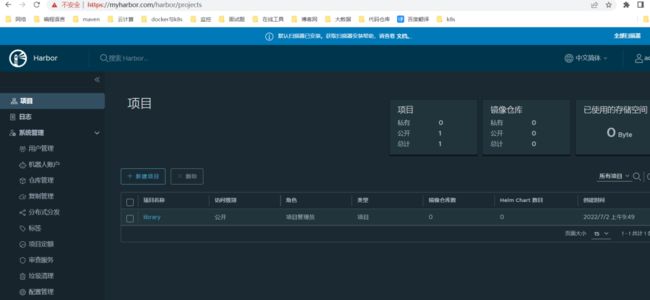
6、harbor 常见操作
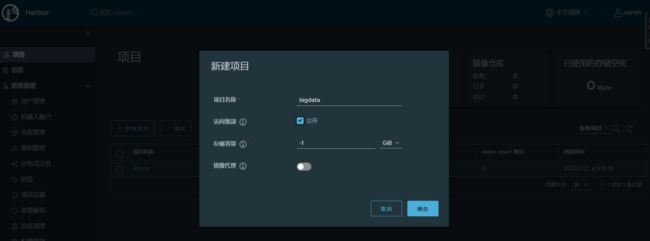
【1】创建项目 bigdata
【2】配置私有仓库
在文件/etc/docker/daemon.json添加如下内容:
"insecure-registries":["https://myharbor.com"]重启 docker
systemctl restart docker【3】服务器上登录 harbor
docker login https://myharbor.com
#账号/密码:admin/Harbor12345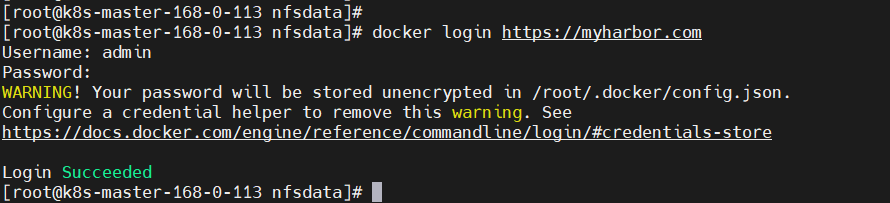
【4】打标签并把镜像上传到 harbor
docker tag rancher/pause:3.6 myharbor.com/bigdata/pause:3.6
docker push myharbor.com/bigdata/pause:3.67、修改 containerd 配置
以前使用 docker-engine 的时候,只需要修改/etc/docker/daemon.json 就行,但是新版的 k8s 已经使用 containerd 了,所以这里需要做相关配置,要不然 containerd 会失败。证书(ca.crt)可以在页面上下载: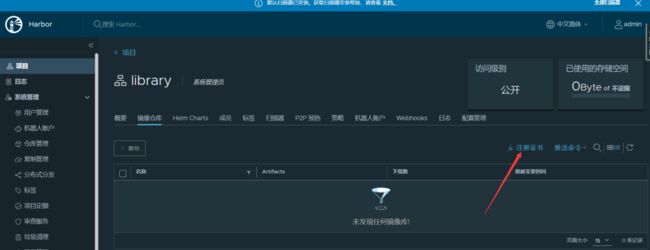
创建域名目录
mkdir /etc/containerd/myharbor.com
cp ca.crt /etc/containerd/myharbor.com/配置文件:/etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.auths]
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."myharbor.com".tls]
ca_file = "/etc/containerd/myharbor.com/ca.crt"
[plugins."io.containerd.grpc.v1.cri".registry.configs."myharbor.com".auth]
username = "admin"
password = "Harbor12345"
[plugins."io.containerd.grpc.v1.cri".registry.headers]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."myharbor.com"]
endpoint = ["https://myharbor.com"]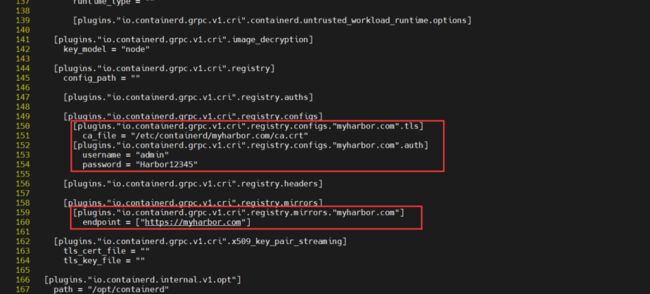
重启 containerd
#重新加载配置
systemctl daemon-reload
#重启containerd
systemctl restart containerd简单使用
# 把docker换成crictl 就行,命令都差不多
crictl pull myharbor.com/bigdata/mysql:5.7.38执行 crictl 报如下错误的解决办法
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
ERRO[0000] unable to determine image API version: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory"这个报错是 docker 的报错,这里没使用,所以这个错误不影响使用,但是还是解决好点,解决方法如下:
cat < /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF 再次拉取镜像
crictl pull myharbor.com/bigdata/mysql:5.7.38
Kubernetes(k8s)最新版最完整版基础环境部署+master 高可用实现详细步骤就到这里了,有疑问的小伙伴欢迎给我留言哦~
本文转载自:「进击的云原生」,原文:https://url.hi-linux.com/92c2s,版权归原作者所有。欢迎投稿,投稿邮箱: [email protected]。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。
![]()
你可能还喜欢
点击下方图片即可阅读

下一代微服务框架 Dapr 中文入门指南
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!