【论文笔记】U-BERT: Pre-training User Representations for Improved Recommendation
原文作者:Zhaopeng Qiu, Xian Wu, Jingyue Gao, Wei Fan
原文标题:U-BERT: Pre-training User Representations for Improved Recommendation
原文来源:AAAI 2021
原文链接:https://www.aaai.org/AAAI21Papers/AAAI-2116.QiuZ.pdf
U-BERT: Pre-training User Representations for Improved Recommendation
对于推荐系统来说,学习到精确的用户representation是非常重要的。早期的研究方法从user-item评分矩阵中得到用户representation。但是这种办法存在问题,评分矩阵通常十分稀疏,而且评分也比较粗粒度。有些方法使用了review增强用户的表征,但是由于某些领域的review非常少,也无法获得准确的用户表征。本文提出的U-BERT方法很好的解决了这个问题。
问题定义
U = { u k } k = 1 k = M 和 I = { i j } j = 1 j = N \mathcal{U =}\left\{ u_{k} \right\}_{k = 1}^{k = M}和\mathcal{I =}\left\{ i_{j} \right\}_{j = 1}^{j = N} U={uk}k=1k=M和I={ij}j=1j=N分别表示领域D中的用户集和item集,领域D中的评论集为 T f \mathcal{T}_{f} Tf( U \mathcal{U} U写给 I \mathcal{I} I),每条评论包含user ID u u u,item ID i i i,文本 s s s,评分 r r r。用户在其他领域的评论集为 T p \mathcal{T}_{p} Tp,评论的格式与上述相同(item集不同)。
模型架构
模型分为两个部分:pre-training和fine-tuning。预训练阶段,通过两个自监督任务从不同领域的评论中预训练U-BERT模型和用户表征。微调阶段,使用预训练好的模型U-BERT编码用户特征,帮助item编码器得到领域D的评论中的item表征。通过监督评分预测任务,得到领域D最终的推荐模型。
预训练阶段
预训练阶段的模型架构如图2所示。有三个模块组成:输入层、评论编码器、用户编码器。
输入层

输入评论文本、用户ID和相应的领域ID。输入的每一条评论,添加[CLS]和[SEP]到起始和末尾位置。然后将评论中的每一个单词通过矩阵 E W ∈ R ∣ V ∣ × d \mathbf{E}_{W} \in \mathbb{R}^{\mathcal{|V| \times}d} EW∈R∣V∣×d转化为对应的嵌入向量, ∣ V ∣ \mathcal{|V|} ∣V∣是单词表的大小, d d d是嵌入向量的维度。然后每个嵌入向量加上相应的segment embedding和position embedding。最终一条评论的representation为 S ∈ R L s × d \mathbf{S} \in \mathbb{R}^{L_{s} \times d} S∈RLs×d, L s L_{s} Ls是评论s的长度。
用户ID也转化为d维的向量 u \mathbf{u} u,通过嵌入矩阵 E U ∈ R ∣ U ∣ × d \mathbf{E}_{U} \in \mathbb{R}^{\mathcal{|U| \times}d} EU∈R∣U∣×d。为了解决两个阶段中领域不一致的问题,作者引入了domain ID来建模特定domain的信息。同样通过一个矩阵 E O \mathbf{E}_{O} EO将domain ID转化为向量 o ∈ R d \mathbf{o} \in \mathbb{R}^{d} o∈Rd。
review encoder
使用多层Transformer。 S l = { e t l } t = 1 t = L s \mathbf{S}^{l} = \left\{ \mathbf{e}_{t}^{l} \right\}_{t = 1}^{t = L_{s}} Sl={etl}t=1t=Ls表示第 l + 1 l + 1 l+1个Transformer层的输入,也就是第 l l l的输出。 S 0 \mathbf{S}^{0} S0就是review encoder的输入,也就是上文提到的 S \mathbf{S} S**。**不同的Transformer层之间的参数是不同的。每个Transformer层包括两个子层,Multi-Head Self-Attention和Position-wise Feed-Forward。
Multi-Head Self-Attention层中,使用上下文语义增强评论中每个单词的representation。使用三个矩阵 Q ∈ R L Q × d 、 K ∈ R L K × d 、 V ∈ R L V × d \mathbf{Q} \in \mathbb{R}^{L_{Q} \times d}\mathbf{、}\mathbf{K} \in \mathbb{R}^{L_{K} \times d}\text{、}\mathbf{V} \in \mathbb{R}^{L_{V} \times d} Q∈RLQ×d、K∈RLK×d、V∈RLV×d,而且 L K = L V L_{K} = L_{V} LK=LV。
Attn ( Q , K , V ) = Softmax ( QK ⊤ / d ) V \text{Attn}(\mathbf{Q},\mathbf{K},\mathbf{V}) = \text{Softmax}\left( \mathbf{\text{QK}}^{\top}/\sqrt{d} \right)\mathbf{V} Attn(Q,K,V)=Softmax(QK⊤/d)V
每个attention head都使用上式计算,即:
head i = Attn ( S l W i Q , S l W i K , S l W i V ) \text{head}_{i} = \text{Attn}\left( \mathbf{S}^{l}\mathbf{W}_{i}^{Q},\mathbf{S}^{l}\mathbf{W}_{i}^{K},\mathbf{S}^{l}\mathbf{W}_{i}^{V} \right) headi=Attn(SlWiQ,SlWiK,SlWiV)
head i ∈ R L s × d / h \text{head}_{i} \in \mathbb{R}^{L_{s} \times d/h} headi∈RLs×d/h然后将多个head拼接起来:
MH ( S l ) = [ head 1 ; … ; head h ] W O \text{MH}\left( \mathbf{S}^{l} \right) = \left\lbrack \text{head}_{1};\ldots;\text{head}_{h} \right\rbrack\mathbf{W}^{O} MH(Sl)=[head1;…;headh]WO
其中 W i Q , W i K , W i V ∈ R d × d / h , W O ∈ R d × d \mathbf{W}_{i}^{Q},\mathbf{W}_{i}^{K},\mathbf{W}_{i}^{V} \in \mathbb{R}^{d \times d/h}\text{,}\mathbf{W}^{O} \in \mathbb{R}^{d \times d} WiQ,WiK,WiV∈Rd×d/h,WO∈Rd×d都是学习得到的参数。h是head的个数。(这里的拼接操作应该axis=1: R L s × ( d / h × h ) × R d × d \mathbb{R}^{L_{s} \times (d/h \times h)} \times \mathbb{R}^{d \times d} RLs×(d/h×h)×Rd×d)
然后进行残差连接和层标准化:
H l = LN ( S l + MH ( S l ) ) \mathbf{H}^{l} = \text{LN}\left( \mathbf{S}^{l} + \text{MH}\left( \mathbf{S}^{l} \right) \right) Hl=LN(Sl+MH(Sl))
Position-wise Feed-Forward子层中,对于输入 H ∈ R L H × d \mathbf{H} \in \mathbb{R}^{L_{H} \times d} H∈RLH×d有:
FFN ( H ) = G E L U ( HW 1 F + b 1 F ) W 2 F + b 2 F \text{FFN}(\mathbf{H}) = GELU\left( \mathbf{\text{HW}}_{1}^{F} + \mathbf{b}_{1}^{F} \right)\mathbf{W}_{2}^{F} + \mathbf{b}_{2}^{F} FFN(H)=GELU(HW1F+b1F)W2F+b2F
其中 W 1 F ∈ R d × 4 d , W 2 F ∈ R 4 d × d , b 1 F ∈ R 4 d and b 2 F ∈ R d \mathbf{W}_{1}^{F} \in \mathbb{R}^{d \times 4d},\mathbf{W}_{2}^{F} \in \mathbb{R}^{4d \times d},\mathbf{b}_{1}^{F} \in \mathbb{R}^{4d}\text{\ and\ }\mathbf{b}_{2}^{F} \in \mathbb{R}^{d} W1F∈Rd×4d,W2F∈R4d×d,b1F∈R4d and b2F∈Rd都是可训练的参数。
同样进行残差连接和层标准化:
S l + 1 = Trm ( S l ) = LN ( H l + FFN ( H l ) ) \mathbf{S}^{l + 1} = \text{Trm}\left( \mathbf{S}^{l} \right) = \text{LN}\left( \mathbf{H}^{l} + \text{FFN}\left( \mathbf{H}^{l} \right) \right) Sl+1=Trm(Sl)=LN(Hl+FFN(Hl))
最终,一条评论经过L层的Transformer,表征为 S L \mathbf{S}^{L} SL。
user encoder
该模块将用户的评论语义聚合到用户的表征中,使其包含用户对item的意见。由三个子层构成:embedding fusion layer、word-level aggregation layer、fusion layer。
embedding fusion layer将domain embedding和用户embedding融合, u ~ = LN ( u + o ) \widetilde{\mathbf{u}} = \text{LN}(\mathbf{u} + \mathbf{o}) u =LN(u+o)。这使得预训练得到的用户表征能直接应用到领域D的推荐任务中。
word-level aggregation layer利用注意力机制,得到评论中哪些单词更能表达用户意见,因为不同的单词表达意见的信息量不同。
s u = Attn ( u ~ W u , S L , S L ) \mathbf{s}^{u} = \text{Attn}\left( \widetilde{\mathbf{u}}\mathbf{W}^{u},\mathbf{S}^{L},\mathbf{S}^{L} \right) su=Attn(u Wu,SL,SL)
W u ∈ R d × d \mathbf{W}^{u} \in \mathbb{R}^{d \times d} Wu∈Rd×d是可训练的参数。
fusion layer将 s u \mathbf{s}^{u} su和 u ~ \widetilde{\mathbf{u}} u 结合起来,得到增强的用户表征 u ^ \widehat{\mathbf{u}} u :
H u = LN ( u ~ W u + s u ) \mathbf{H}^{u} = \text{LN}\left( \widetilde{\mathbf{u}}\mathbf{W}^{u} + \mathbf{s}^{u} \right) Hu=LN(u Wu+su)
u ^ = Fuse ( u ~ , s u ) = LN ( H u + FFN ( H u ) ) \widehat{\mathbf{u}} = \text{Fuse}\left( \widetilde{\mathbf{u}},\mathbf{s}^{u} \right) = \text{LN}\left( \mathbf{H}^{u} + \text{FFN}\left( \mathbf{H}^{u} \right) \right) u =Fuse(u ,su)=LN(Hu+FFN(Hu))
这里同样使用了残差连接和层标准化。
pre-training阶段使用两个任务进行训练,1)Masked Opinion Token Prediction;2)Opinion Rating Prediction。
第一个任务类似于BERT中的MLM任务,首先随机mask一些单词,然后使用双向上下文信息进行预测。在U-BERT中为了适配推荐任务,进行了一些修改:预测masked words时,增加用户representation来学习用户固定的评论偏好;mask单词不是随机选择,而是选择同一用户在不同domain的评论中类似的单词,而且暗含着用户个人的评论偏好(which are shared across different domain reviews written by the same user and imply the personal review preference)。
具体来说,先从一个opinion word库中定位评论中所有的opinion words。然后随机选择50%的opinion words进行masking。Mask的策略类似于BERT。假定某个单词 w t w_{t} wt masked,使用 S t L \mathbf{S}_{t}^{L} StL(评论 s s s中的单词 w t w_{t} wt的representation)和 u \mathbf{u} u进行预测。
Pr ( w t ) = Softmax ( h t W 3 P + b 2 P ) h t = LN ( GELU ( S t L W 1 P + u W 2 P + b 1 P ) ) \begin{matrix} \Pr\left( w_{t} \right)& = \text{Softmax}\left( \mathbf{h}_{t}\mathbf{W}_{3}^{P} + \mathbf{b}_{2}^{P} \right) \\ \mathbf{h}_{t}& = \text{LN}\left( \text{GELU}\left( \mathbf{S}_{t}^{L}\mathbf{W}_{1}^{P} + \mathbf{u}\mathbf{W}_{2}^{P} + \mathbf{b}_{1}^{P} \right) \right) \\ \end{matrix} Pr(wt)ht=Softmax(htW3P+b2P)=LN(GELU(StLW1P+uW2P+b1P))
其中 W 1 P , W 2 P ∈ R d × d , W 3 P ∈ R d × ∣ V ∣ , b 1 P ∈ R d \mathbf{W}_{1}^{P},\mathbf{W}_{2}^{P} \in \mathbb{R}^{d \times d},\mathbf{W}_{3}^{P} \in \mathbb{R}^{d \times |\mathcal{V|}},\mathbf{b}_{1}^{P} \in \mathbb{R}^{d} W1P,W2P∈Rd×d,W3P∈Rd×∣V∣,b1P∈Rd, b 2 P ∈ R ∣ V ∣ \mathbf{b}_{2}^{P} \in \mathbb{R}^{\mathcal{|V|}} b2P∈R∣V∣都是可训练参数。
第二个任务是Opinion Rating Prediction。用户评论item时有两种表达意见的方式:①粗粒度的综合性评分;②细粒度的评,而且评论中有不同的opinion token。二者都能表达用户的偏好,但是仍然有不同。首先,尽管使用了同样的opinion words,但是不同的用户给出的评分是不一样的。其次,同样的评分可能有不同的opinion words的组合。这种差距来自于用户个人的评价偏好。因此,我们可以从该用户在其他领域的评价中学习用户的评价偏好,然后应用到领域D中。
u ^ \widehat{\mathbf{u}} u 中融合了用户的偏好信息和opinion信息,文中用它预测整体的评分 r ′ r^{'} r′:
r ′ = u ^ W R + b R r^{'} = \widehat{\mathbf{u}}\mathbf{W}^{R} + b^{R} r′=u WR+bR
其中, W R ∈ R d × 1 且 b R ∈ R \mathbf{W}^{R} \in \mathbb{R}^{d \times 1}\text{且}b^{R} \in \mathbb{R} WR∈Rd×1且bR∈R是可训练的参数。
预训练阶段的损失函数为:
L ( Θ ) = ∑ k = 1 ∣ T p ∣ − ∑ t ∈ s k M log ( Pr ( w t ) ) ∣ s k M ∣ + β ( r k ′ − r k ) 2 \mathcal{L(}\Theta) = \sum_{k = 1}^{\left| \mathcal{T}_{p} \right|}\frac{- \sum_{t \in s_{k}^{M}}^{}\log\left( \Pr\left( w_{t} \right) \right)}{\left| s_{k}^{M} \right|} + \beta\left( r_{k}^{'} - r_{k} \right)^{2} L(Θ)=k=1∑∣Tp∣∣∣skM∣∣−∑t∈skMlog(Pr(wt))+β(rk′−rk)2
其中, T p \mathcal{T}_{p} Tp是预训练的语料库; s k M s_{k}^{M} skM是第k条评论的maskedwo rd集。损失函数分为两部分,最大化第一部分,最小化第二部分。分别对应两个任务,第一部分解释为:每条评论中所有masked word概率求和取平均。第二部分是用户某条评论的预测评分和真实评分的平方误差。 β \beta β是平衡两个误差的权重。
微调阶段

图三中展示了fine-tuning阶段的模型架构。这一阶段的输入和pre-training阶段的输入有细小的变动。
输入层
输入有五个部分:domain ID,user ID,用户评论,item ID,item评论。使用矩阵 E I ∈ R ∣ I ∣ × d \mathbf{E}_{I} \in \mathbb{R}^{\mathcal{|I| \times}d} EI∈R∣I∣×d将item
ID转化为d维的嵌入向量 i \mathbf{i} i**,**user ID,domain ID和评论都与pre-training中的处理一致。最终得到的是user embedding u \mathbf{u} u,domain embedding o \mathbf{o} o,user review representation S u = { S k u } k = 1 k = C u \mathbf{S}^{u} = \left\{ \mathbf{S}_{k}^{u} \right\}_{k = 1}^{k = C_{u}} Su={Sku}k=1k=Cu,item review representation S i = { S k i } k = 1 k = C i \mathbf{S}^{i} = \left\{ \mathbf{S}_{k}^{i} \right\}_{k = 1}^{k = C_{i}} Si={Ski}k=1k=Ci。
review encoder
Transformer难以处理很长的序列,作者使用U-BERT中的review encoder一个一个的编码user/item的评论。对于用户的第k条评论,其编码为:
S ^ k u = Trm L ( Trm L − 1 ( … ( Trm 1 ( S k u ) ) ) ) {\widehat{\mathbf{S}}}_{k}^{u} = \text{Trm}^{L}\left( \text{Trm}^{L - 1}\left( \ldots\left( \text{Trm}^{1}\left( \mathbf{S}_{k}^{u} \right) \right) \right) \right) S ku=TrmL(TrmL−1(…(Trm1(Sku))))

user&item encoder
将用户所有的评论的representation按行拼接: S ^ u = [ S ^ 0 u ∣ S ^ 1 u ∣ … ∣ S ^ C u u ] {\widehat{\mathbf{S}}}^{u} = \left\lbrack {\widehat{\mathbf{S}}}_{0}^{u}\left| {\widehat{\mathbf{S}}}_{1}^{u} \right|\ldots \mid {\widehat{\mathbf{S}}}_{C_{u}}^{u} \right\rbrack S u=[S 0u∣∣∣S 1u∣∣∣…∣S Cuu](将一个矩阵拼接成一个长矩阵)。然后将usere mbedding和domain embedding融合, u ~ = LN ( u + o ) \widetilde{\mathbf{u}} = \text{LN}(\mathbf{u} + \mathbf{o}) u =LN(u+o)。然后再用所有评论的representation与其融合,得到multi-review-aware user representation:
u ^ = Fus e ( u ~ , s ^ u ) \widehat{\mathbf{u}} = \text{Fus}e\left( \widetilde{\mathbf{u}},{\widehat{\mathbf{s}}}^{u} \right) u =Fuse(u ,s u)
s ^ u = Attn ( u ~ W u , S ^ u , S ^ u ) {\widehat{\mathbf{s}}}^{u} = \text{Attn}\left( \widetilde{\mathbf{u}}\mathbf{W}^{u},{\widehat{\mathbf{S}}}^{u},{\widehat{\mathbf{S}}}^{u} \right) s u=Attn(u Wu,S u,S u)
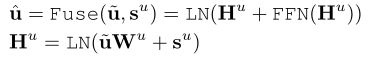
类似地,item的representation i ^ \ \widehat{\mathbf{i}} i 使用同样的方式获得。
review co-matching layer
同一领域的item通常有共同关系的方面。比如一般手机考虑的方面包括"价格","电池寿命"等。不同的用户关注不同的方面;而且针对这些方面表达opinion和偏好。评论的整体评分通常是各个方面opinion的综合。通过用户的评论就可以知道用户关注的方面和相应的评价。同时,通过了解其他用户对item i的评论,可以了解item各方面的详细描述以及这些用户的一般评论。因此可以通过衡量用户评论的语义相似度,估计用户u对物品i各个方面的关心程度。相似度信息可以进一步帮助从细粒度的角度预测评分。文中从两个方向获得相似度信息。
Mutual Attention子层:
D u = Attn ( S ^ u , S ^ i , S ^ i ) ; D i = Attn ( S ^ i , S ^ u , S ^ u ) \mathbf{D}^{u} = \text{Attn}\left( {\widehat{\mathbf{S}}}^{u},{\widehat{\mathbf{S}}}^{i},{\widehat{\mathbf{S}}}^{i} \right);\mathbf{D}^{i} = \text{Attn}\left( {\widehat{\mathbf{S}}}^{i},{\widehat{\mathbf{S}}}^{u},{\widehat{\mathbf{S}}}^{u} \right) Du=Attn(S u,S i,S i);Di=Attn(S i,S u,S u)
使用注意力机制分别对齐user和item的评论到各自的语义空间中。原因是作者希望在细粒度上比较二者的review表征。
Matching子层获得原来的表征和注意力之后的表征语义相似度:
M u & = Tanh ( [ S ^ u − D u ; S ^ u ∘ D u ] W M + b M ) M i & = Tanh ( [ S ^ i − D i ; S ^ i ∘ D i ] W M + b M ) \begin{matrix} \mathbf{M}^{u}\& = \text{Tanh}\left( \left\lbrack {\widehat{\mathbf{S}}}^{u} - \mathbf{D}^{u};{\widehat{\mathbf{S}}}^{u} \circ \mathbf{D}^{u} \right\rbrack\mathbf{W}^{M} + \mathbf{b}^{M} \right) \\ \mathbf{M}^{i}\& = \text{Tanh}\left( \left\lbrack {\widehat{\mathbf{S}}}^{i} - \mathbf{D}^{i};{\widehat{\mathbf{S}}}^{i} \circ \mathbf{D}^{i} \right\rbrack\mathbf{W}^{M} + \mathbf{b}^{M} \right) \\ \end{matrix} Mu&=Tanh([S u−Du;S u∘Du]WM+bM)Mi&=Tanh([S i−Di;S i∘Di]WM+bM)
其中 W M ∈ R 2 d × d , b M ∈ R d \mathbf{W}^{M} \in \mathbb{R}^{2d \times d}\text{,}\mathbf{b}^{M} \in \mathbb{R}^{d} WM∈R2d×d,bM∈Rd, − - −和 ∘ \circ ∘表示矩阵中逐元素相加和相乘操作。
最后使用逐行最大池化来融合所有位置的匹配信息(矩阵每行求最大值),以获得用户评论和item评论的综合表征:
t u = MaxPooling ( M u ) t i = MaxPooling ( M i ) \begin{matrix} &\mathbf{t}^{u} = \text{MaxPooling}\left( \mathbf{M}^{u} \right) \\ &\mathbf{t}^{i} = \text{MaxPooling}\left( \mathbf{M}^{i} \right) \\ \end{matrix} tu=MaxPooling(Mu)ti=MaxPooling(Mi)
5)预测层
r ′ = [ u ^ ; t u ; i ^ ; t i ] W f + b f r^{'} = \left\lbrack \widehat{\mathbf{u}};\mathbf{t}^{u};\widehat{\mathbf{i}};\mathbf{t}^{i} \right\rbrack\mathbf{W}^{f} + b^{f} r′=[u ;tu;i ;ti]Wf+bf
其中 W f ∈ R 4 d × 1 and b f ∈ R \mathbf{W}^{f} \in \mathbb{R}^{4d \times 1}\text{\ and\ }b^{f} \in \mathbb{R} Wf∈R4d×1 and bf∈R。
损失函数为:
L ( Θ f ) = 1 ∣ T f ∣ ∑ k = 1 ∣ T f ∣ ( r k ′ − r k ) 2 \mathcal{L}\left( \Theta_{f} \right) = \frac{1}{\left| \mathcal{T}_{f} \right|}\sum_{k = 1}^{\left| \mathcal{T}_{f} \right|}\left( r_{k}^{'} - r_{k} \right)^{2} L(Θf)=∣Tf∣1k=1∑∣Tf∣(rk′−rk)2
3.3.5实验
-
数据集:Amazon product review datasets、Yelp challenge dataset。
-
Baseline:PMF、SVD++、HFT、Deep-CoNN、NARRE、RMG、DAML、AHN、 U − B E R T P − U - BERT_{P -} U−BERTP−(使用bert权重初始化,没有U-BERT pre-training)
各模型的实验结果如表2所示。U-BERT模型在六个不同的领域数据集上优于所有的基线。

即使没有预训练,U-BERT在5个数据集上的性能仍比DAML、AHN和NARRE有所提高,这表明它可以有效的捕获评论感知的用户特征。

表三中为没有预训练任务的实验结果,可以观察到移除任何预训练任务会导致性能下降。
3.3.6总结
本文提出的U-BERT模型,基于BERT对推荐任务进行适配,文章解决了某些领域数据缺失的问题。利用用户评论这一关键信息,提取评论中代表用户偏好的信息,从而增强用户的表征;然后使用两个预训练任务,opinion token预测和opinion评分预测得到一个训练好的模型和所有的参数。Fine-tuning阶段基于预训练的模型,加入item encoder和review co-matching层对某个领域的数据进行微调。
整个模型较为复杂,尤其是co-matching层不太理解。(A CoMatching Model for Multi-choice Reading Comprehension. Neural Natural Language Inference Models Enhanced with External Knowledge阅读这两篇文章可能好理解一点。)
模型中比较重要的思想是跨域推荐的问题,即对于数据较少的领域,利用同一用户的特点,在数据丰富的领域中抽取其偏好和特征,适配到数据较少的领域中。