MySQL之索引
索引是什么
索引是一个排序的列表,列表当中存储着索引的值和包含这个值的数据所在行的物理地址。
索引的作用
1.利用索引,数据库可以快速定位,大大加快查询速度
2.表的数据很大,查询需要多个表,这个时候使用索引也可以提高查询速度
3.加快表与表之间的连接
4.分组和排序的时候,可以大大减少分组排序时间
5.可以提高数据库恢复数据时的速度
索引的创建原则
如果有索引,数据库会先进行索引查询,然后定位数据,索引使用不当,反而会增加数据库的负担
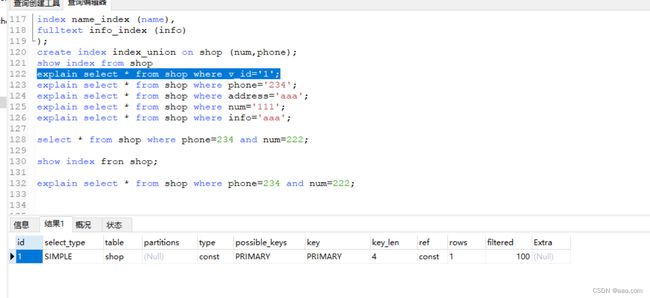
主键,外键 必须有索引 创建好了主键,外键自动就是索引,不需要额外声明
一个表查过了300行的记录,必须要有索引,否则数据库会遍历表的所有数据。(数据库是一行一行查询数据)
互相之间有关联的表,在这个关联字段上应该设置索引
唯一性太差的字段,不适合创建索引
更新太频繁的字段,不适合做索引(比如年龄)
经常被where条件匹配的字段,尤其是表数据比较多的,应该创建索引
在经常进行group by (分组) order by (排序语句) 的字段要建立索引。
索引的列的字段越小越好,长文本字段,不适合建立索引。
此外:当一个表写入多、读取很少的时候,不需要建立索引。唯一性太差的字段、更新太频繁地字段、大字段,不适合做索引。
数据库索引的分类
常用类型:
B-树(B-tree)
查看表的索引:
show index from test;
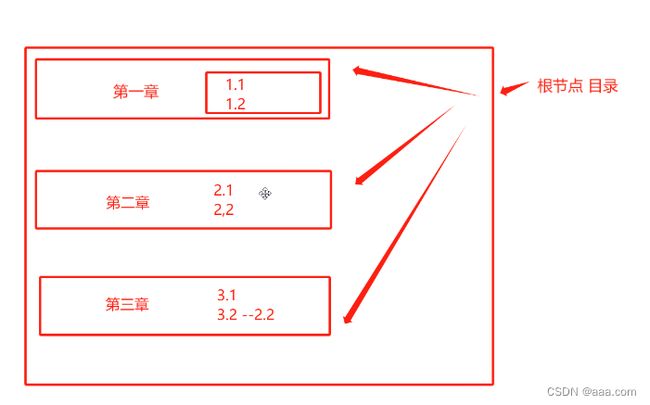
树形结构的索引,也是大部分数据库的默认索引类型。
根节点:树最顶端的分支节点
分支节点:指向多起里其他的分支节点,也可以是叶子节点
叶子节点:直接指向表里的数据行
哈希索引:散列索引 把任意长度的输入,通过散列算法变换成固定长度的输出。散列值-----分别对应数据里的列和行
mosql的默认索引引擎:INNODB 默认的引擎类型就是Btree。
MEMORY 引擎可以支持HASH索引,也是他的默认索引。
先算散列值,然后再对应,速度比较慢,比btree慢。
hash的索引匹配: =in () <= >
索引的副作用
索引也需要占用额外的磁盘空间,innodb表数据文件本身也是索引,myisam:索引和数据文件是分离的。更新一个包含索引的表,要比更新一个没有索引表花费的时间更多。更新值,也就是更新索引。
创建表需要考虑的因素
1.关联程度 3张表,选好关联字段。
2.每个字段的长度,也要考虑
3.设计合理的索引列
4.表数据,要控制在合理范围之内。可以在牺牲一定性能的条件下,满足需求。5秒以上就要考虑优化了。10秒以上一般是出问题了(数据雪崩)
普通索引的创建
CREATE INDEX 索引名 ON 表名 (列名(长度));
#长度可以加也可以不加,添加长度时,则该索引会取每行字段的前几位(即字段的长度)作为索引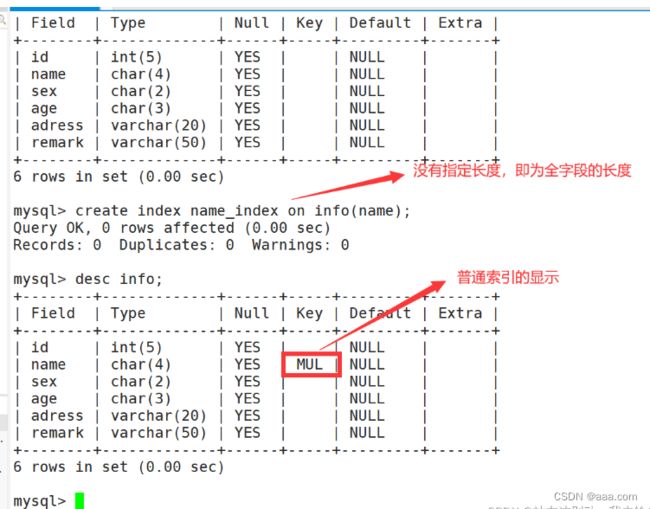
修改方式添加索引
alter table member add index card_id_index (card_id);
show index from member;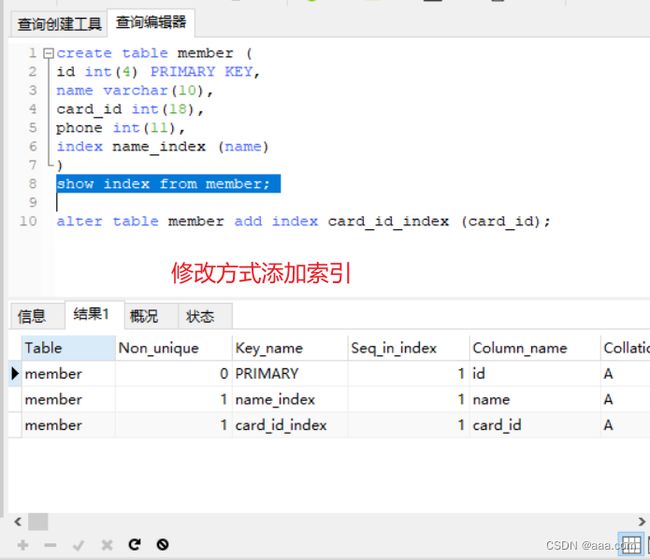
唯一索引
unique 与普通索引类似,唯一索引的每个值都是唯一,唯一索引允许空值。添加唯一键才会创建唯一索引。最好是不要为空。unique not null
CREATE UNIQUE index phone_index on member(phone);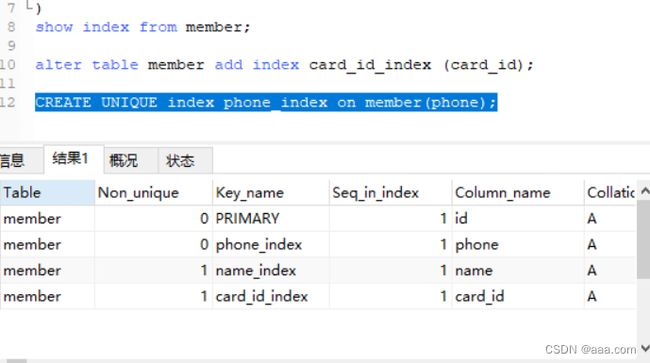
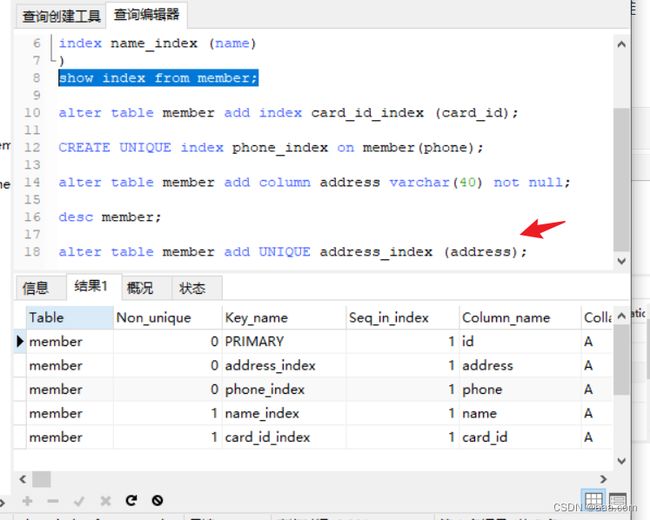
修改表结构的方式增加唯一键
ALTER TABLE 表名 ADD UNIQUE 索引名(字段名);全文索引
text
适合在进行模糊查询时使用,可以在一篇文章中检索文本信息。
全文索引
create table test2 (
id int(4) PRIMARY KEY,
name varchar(10),
card_id int(18) not null,
phone int(11) not null,
notes text,
UNIQUE card_id_index (card_id),
UNIQUE phone_index (phone)
);
create fulltext index notes_index on test2 (notes);
show index from test2;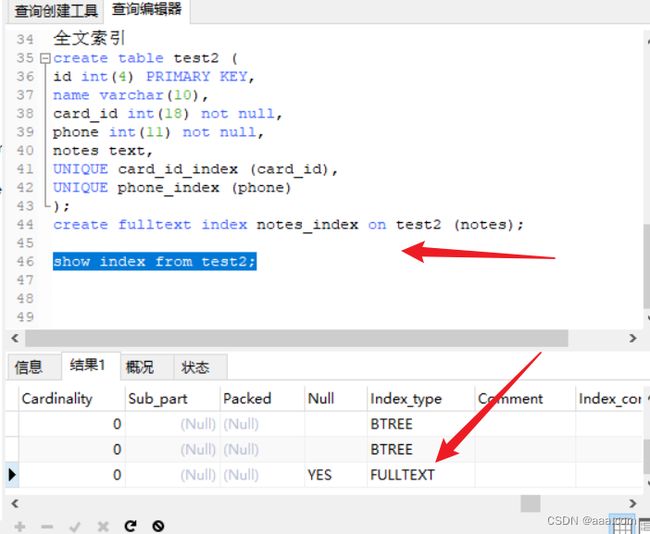
联合索引
联合索引
create table test3 (
id int(4) PRIMARY KEY,
name varchar(10),
card_id int(18) not null,
phone int(11) not null,
notes text,
UNIQUE card_id_index (card_id),
UNIQUE phone_index (phone),
fulltext notes_index (notes)
);
create index index_union on test3 (card_id,phone);
show INDEX from test3;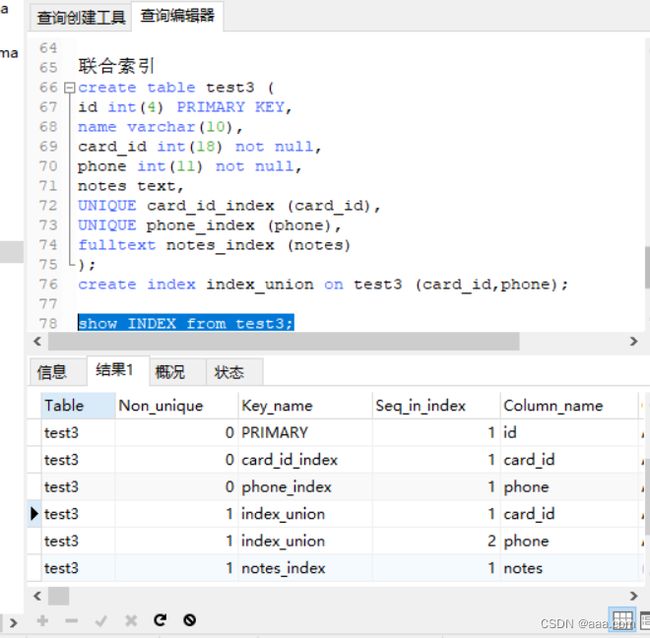
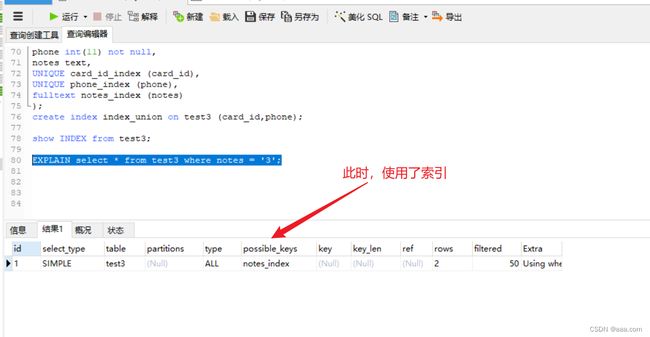
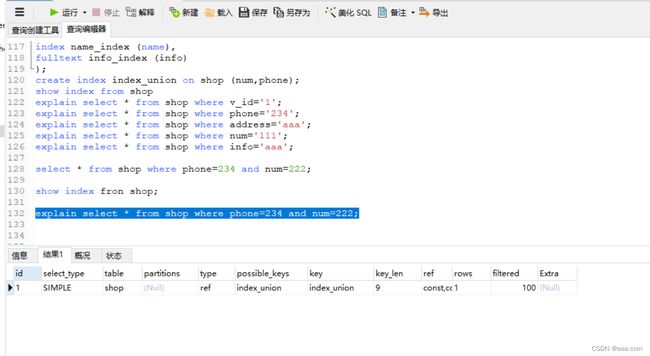
如果是联合索引,查询时必须按照创建时的顺序进行查询
explain select * from test4 where card_id=1 and id=1; mysql机制 会默认找最短的索引列,最优索引选择。
联合索引,从左到右开始,不能跳过索引,否则索引会失效。
范围查询,有可能右侧的索引会失效
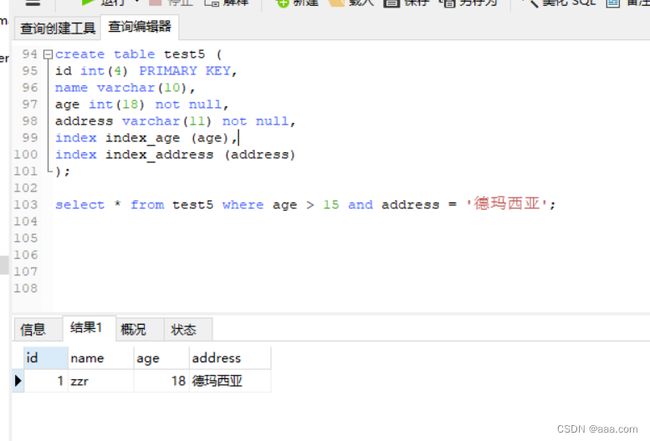
create table test5 (
id int(4) PRIMARY KEY,
name varchar(10),
age int(18) not null,
address varchar(11) not null,
index index_age (age),
index index_address (address)
);
select * from test5 where age > 15 and address = '123';
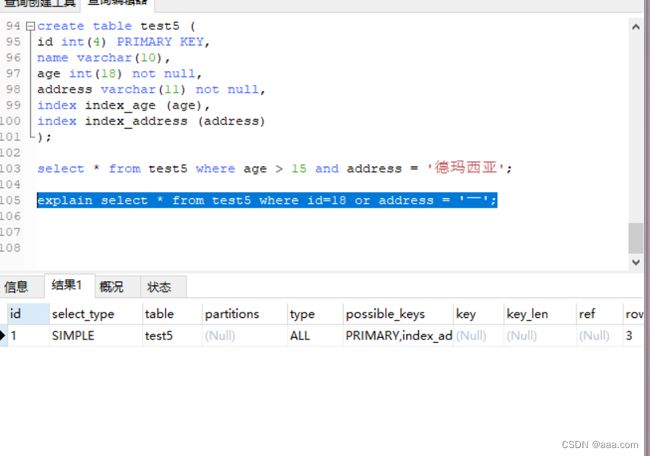
使用or语句 索引一定失效,使用or作为条件,mysql无法同时使用多个索引。
is null
is not null 使用这两个,索引有时会失效
where is null 数据的绝大多数都是空值,索引会失效
where is not null 数据多数为 不空,索引失效
现在一张表的查询速度是7.62s;该如何解决
首先查缓存,看请求是不是直接到了后端数据库。
再看索引,请求的列值不是默认的索引,添加一下即可
explain查看
练习

1.先创建表,vip_member
2.根据你的选择,来给这张表创建索引
3.每个列都要创建索引,然后执行查看索引的使用情况。
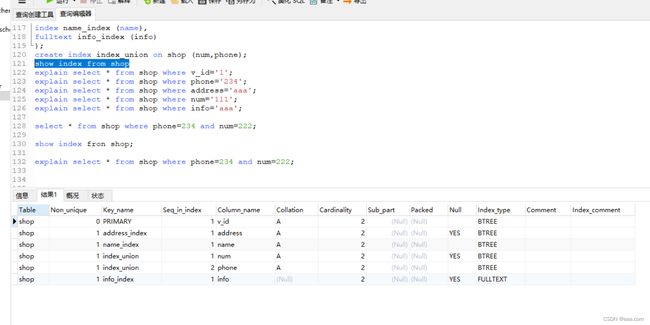
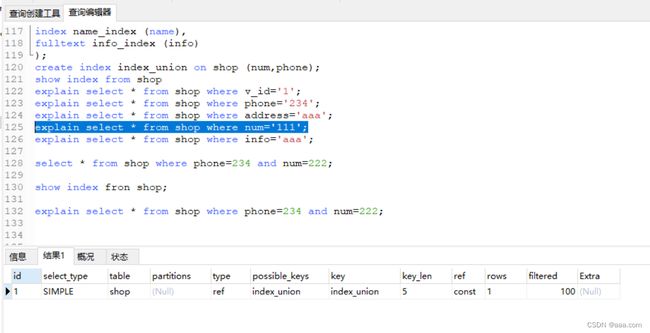
create table shop (
v_id int(4) PRIMARY KEY,
name varchar(10) not null,
num int(18),
phone int(11) not null,
address varchar(50),
info text,
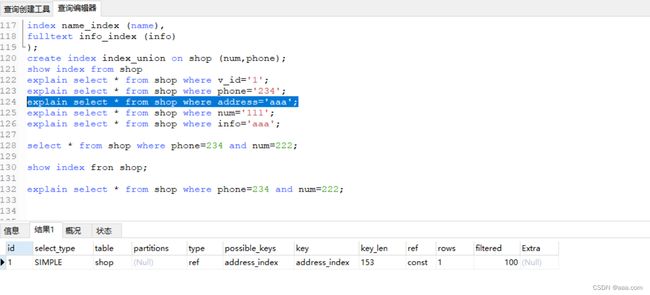
index address_index (address),
index name_index (name),
fulltext info_index (info)
);
create index index_union on shop (num,phone);