爬虫(二):requests模块 ---get和post方法,cookie和session,代理
一、requests模块的使用步骤
# 1、导包
import requests
# 2、确定基础url
base_url = 'https://www.baidu.com/'
# 3、发送请求,获取响应
response = requests.get(base_url)
# 4、处理响应内容
二、requests中的get方法
requests.get(
url = '请求url',
headers = {
}, # 请求头
params = {
}, # 请求参数,get方法中的请求参数拼接在url中
timeout = 超时时长,
)
requests模块的get方法,返回一个response对象
1、response对象
服务器响应包含:状态行(协议,状态码)、响应头、空行、响应正文。
(1)响应正文
字符串格式:response.text
bytes类型:response.content
(2)状态码
response.status_code
(3)响应头
response.headers --字典
# 获取响应头中的cookie
response.headers['cookie']
(4)响应正文的编码
response.encoding
# response.text获取到的字符串类型的响应正文,其实是通过下面的步骤获取的
response.encoding = response.content.decode()
(5)乱码问题的解决办法
产生的原因:编码和解码的编码格式不一致造成的。
str.encode() # 将字符串解码成bytes类型
bytes.decode() # 将bytes类型编码成字符串
第一种方法:
response.content.decode('页面正确的编码格式')
第二种方法:找到正确的编码,设置到 response.encoding 中
response.encoding = '正确的编码'
response.text ---> 正确的页面内容
2、get 方法举例
案例一:爬取百度首页
https://www.baidu.com/
# 1、导包
import requests
# 2、确定基础url
base_url = 'https://www.baidu.com/'
# 封装请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
# 3、发送请求,获取响应
response = requests.get(base_url,headers=headers)
# 解决乱码问题的第一种方法
# response.encoding = 'utf-8'
# 4、处理响应
with open('baidu.html','w',encoding='utf-8') as fp:
# fp.write(response.text)
# 解决乱码问题的第二种方法
fp.write(response.content.decode('utf-8'))
案例二:爬取新浪新闻
输入 国产航母 ,分析检查返回的页面,如下图所示:
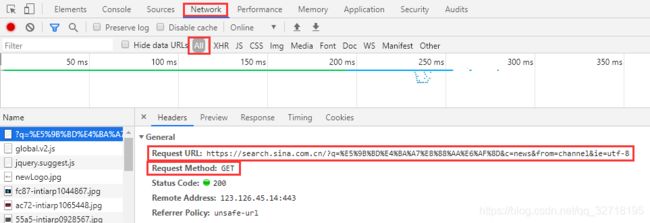
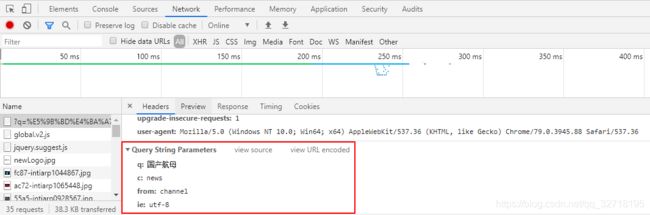
图 2-1 返回的页面
请求的是:https://search.sina.com.cn/?q=%E5%9B%BD%E4%BA%A7%E8%88%AA%E6%AF%8D&c=news&from=channel&ie=utf-8
请求方法是:get请求。
请求参数:有四个,其中一个参数是中文,请求的时候需要编码。
爬取代码示例:
# get请求,携带请求参数
# 1、导包
import requests
# 2、确定基础url
# 带请求参数的基础url,就是?以前包括问号
base_url = 'https://search.sina.com.cn/?'
# 封装请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
# 请求参数
kw = '国产航母'
params = {
'q': kw,
'c': 'news',
'from': 'channel',
'ie': 'utf-8'
}
# 3、发送请求,获取响应
response = requests.get(base_url,headers=headers,params=params)
# 4、处理响应
# 右击-->检查 查看页面源代码
#
with open('sina_new.html','w',encoding='gbk') as fp:
fp.write(response.content.decode('gbk'))
案例三:爬取百度贴吧
百度贴吧,搜索 python,利用get方法做分页
第一页:https://tieba.baidu.com/f?kw=%E7%8E%8B%E8%80%85&ie=utf-8&pn=0
第二页:https://tieba.baidu.com/f?kw=%E7%8E%8B%E8%80%85&ie=utf-8&pn=50
第三页:https://tieba.baidu.com/f?kw=%E7%8E%8B%E8%80%85&ie=utf-8&pn=100
寻找每个页面url中不同的地方,就是url最后的pn值不同
爬取代码示例: