使用远程服务器进行EDVR代码复现全过程(应该是全网最详细了)
本人是即将入学的研0小白,导师布置的暑假任务是理解EDVR论文和代码,并动手复现。
我本科是通信工程专业,考研上岸电子信息,导师研究方向是计算机视觉。但我不是计算机专业本科出身,对Python一无所知,只学过一点c++,本科也没做过这方面的科研项目,没使用过实验室的服务器。因此这个任务对我来说困难重重,举步维艰,我在网上查找了EDVR复现的详细教程,找了几篇讲的都很简略,对我这种什么都不懂的小白来说很不友好,于是经过将近两个月的艰难摸索并成功复现代码后,我决定将整个过程记录下来,写一篇更详细的博客。即是对我学习过程的总结,也希望能帮助到后来的朋友。
一、阅读paper
paper下载地址:
[1905.02716] EDVR: Video Restoration with Enhanced Deformable Convolutional Networks (arxiv.org)
EDVR:基于增强型可变性卷积网络的视频恢复
EDVR是一个可以用于视频超分辨率、去模糊、去噪声、去块等多种视频恢复任务的通用框架。
于2019年由王鑫涛等人提出,用来参加NTIRE19挑战赛(New Trends in Image Restoration and Enhancement workshop),并在视频恢复和增强挑战赛的全部四个赛道上取得最好成绩,并且远超第二名,获得冠军。
视频恢复和增强挑战赛的四个赛道:
视频超分辨率,输入是干净图像、
视频超分辨率,输入是模糊图像;
视频去模糊,输入是干净图像、
视频去模糊,输入是带有压缩伪影的图像;
NTIRE19视频恢复和增强挑战赛发布了一个新的基准:REDS(REalistic and Diverse Scenes dataset),即现实多样化场景数据集,与先前的数据集相比,REDS中的视频包含更大、更复杂的动作,这使得REDS更加真实,更具挑战性。
为了应对这项挑战,EDVR主要提出了两个新的模块:PCD alignment Module and TSA fusion Module,PCD对齐模块和TSA融合模块是EDVR框架的核心。
PDC对齐模块:Pyramid,Cascading and Deformable convolutions module ,金字塔型,级联可变形卷积对齐模块
TSA融合模块:Temporal and Spatial Attention module,时间和空间注意力融合模块
EDVR通用框架:

对于视频超分辨率任务(上):将2N+1个连续低分辨率帧I[t-N:t+N]作为输入,生成一个高分辨率的输出。
输入首先通过PCD对齐模块,将相邻帧与参考帧在特征层面对齐;然后通过TSA融合模块,融合不同帧中间的图像信息;融合后的特征再经过一个重建模块,重建模块由一系列残差块组成,可以被单图像超分中任何一个更高级的模块取代;然后将其上采样,增大空间大小(分辨率);最后,将经过上述过程预测的图像残差与低分辨率输入直接上采样的图片相叠加,得到最终的高分辨率输出。
对于视频去模糊任务(下):输入是高分辨率帧,但带有严重模糊,生成一个高分辨率无模糊的输出。
输入首先通过步长卷积层下采样,将大部分的计算转入到低分辨率空间,这大大减小了计算量。经过下采样的输入首先通过一个预去模糊模块(PreDeblur Module),对带有严重模糊的输入进行预处理,来提高对齐的准确性;之后的过程与视频超分辨率的过程相同;最后将上采样后的预测的图像残差直接作为输出,不与输入相加。
PCD对齐模块: TSA融合模块:

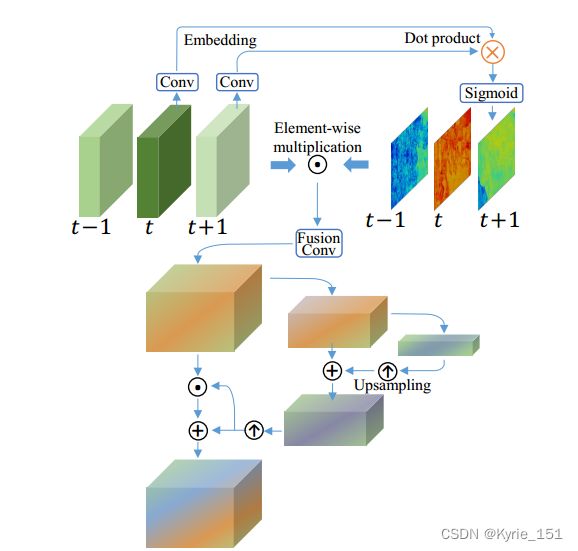
PCD对齐模块:首先提取输入视频的每一帧的特征,得到L1级的特征;再对L1级特征步长卷积,进行两倍下采样,得到L2级特征,以此类推得到L3级特征;将金字塔每一级的每一帧的特征级联后,与上一级(L+1级)的偏移(ΔP^l+1)_t+i 经过两倍上采样的结果进行卷积(f函数),得到本级的偏移(ΔP^l)_t+i, 如公式(3);将金字塔每一级的相邻帧的特征(F^l)_t+i与本级的偏移(ΔP^l)_t+i进行可变性卷积,然后再与上一级(L+1级)的对齐特征(F^a(l+1))_t+i进行卷积(g函数),得到本级的对齐特征(F^a(l))_t+i,如公式(4)。 L3级是金字塔最高级,没有更高一级的偏移和对齐特征,因此L3级的对齐特征和偏移由式(1)和式(2)得到。
三级金字塔结构后再级联一个可变形对齐模块,来进一步细化粗略对齐的特征。金字塔结构首先在较低尺度粗略估计来对齐特征,然后将偏移和对齐的特征传播到较高尺度来进行精确的运动补偿。PCD对齐模块以这种由粗到细的方式处理大的复杂的动作,提高了对齐的逐像素准确性。
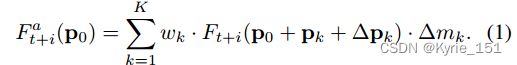
![]()
![]()
![]()
TSA融合模块:首先对参考帧和相邻帧的对齐特征进行简单的卷积,计算出两个嵌入。然后将这两个嵌入点乘,再经过一个sigmoid激活函数,得到帧相似距离,也即时间注意力,如公式(5);然后将得到的时间注意力图与原始的对齐特征图逐像素相乘,得到经过注意力调制后的特征,如公式(6);再通过一个额外的融合卷积层,聚合这些经过注意力调制后的特征,然后卷积,得到融合了时间注意力的特征,如公式(7);再从时间融合特征中计算空间注意力掩码,采用池化和两倍上采样来使空间大小减小和增大,实现金字塔结构,进而增加注意力接受范围;最后将计算的空间注意力掩码与时间融合的特征进行逐元素相乘相加,调制融合了时间注意力的特征,最终得到融合了时间注意力和空间注意力的特征。
不同的相邻帧由于闭塞、模糊区域和视察问题,含有的信息量不同;且先前的PCD对齐模块中的未对齐情况会对后续的重建新能产生不良影响。因此,帧间的时间联系和帧内的空间联系对融合至关重要。TSA融合模块计算了相邻帧与参考帧之间的相似性,即时间联系,将其调制到对齐的特征中,随后又计算空间注意力,并将权重分配到每个通道中的每个位置。通过这两步操作,可以更好的利用每一帧的视觉信息和跨通道的空间信息,有效解决了上述问题。
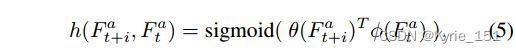
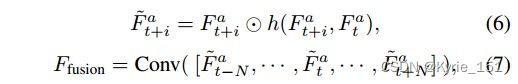
两阶段策略:虽然带有PCD对齐模块和TSA融合模块的单一EDVR结构可以实现最先进的性能,但是当输入的图片质量很差,比如存在严重模糊和扭曲时,动作补偿和细节聚合将会受到影响,导致较差的重建性能。为了解决这一问题,可以采用两阶段策略:在单一的EDVR网络后再级联一个相似的但是更浅的 EDVR网络,用来去除第一阶段网络中处理不了的严重模糊。这一策略可以进一步提高EDVR的性能。
二、复现code
code下载地址:https://github.com/xinntao/EDVR
网页中有提示,EDVR已经被并入了BasicSR。因此要注意的是,从这里下载的代码并不完整,比如basicsr目录下就缺少__init__.py和version.py文件。起初我并没有注意到这个问题,因此直接用这个代码去训练,结果报出一堆错。比如其他的文件不能导入basicsr模块下的文件,在网上找了很久,发现是路径问题,需要在basicsr文件夹下新建一个__init__.py文件表明basicsr是一个软件包,并在该文件中添加两行语句,将basicsr的路径添加的系统路径下,参考博客。解决了这个问题后,又报出找不到verson.py文件,在确认代码无误后,我才意识到我下载的代码并不完整。于是我又仔细阅读了code里的readme文件,发现原来完整的代码在BasicSR里,必须先克隆BasicSR的代码,后续的代码才能正常运行。
1.在VScode中使用ssh扩展连接远程服务器,并建立存放项目的目录
首先要得到一个服务器的账号和密码,我是找导师要的,服务器是一个2080ti显卡,ubuntu系统。然后的步骤就很简单,具体参考这篇博客,讲的非常详细。也可以使用pycharm软件,但pycharm的社区版没有远程连接服务器的功能,需要下载pycharm专业版。但专业版是付费的,可以去官网用.edu结尾的教育邮箱申请免费,或者用学信网的学籍证明来申请,方法参考这篇博客。
我的项目存放在EDVR-master目录下,与代码EDVR-master同名

2.安装虚拟环境
参考readme_cn文件:

需要一个python版本大于等于3.7的conda环境,并且需要安装版本大于等于1.3的Pytorch,以及英伟达的显卡和cuda。
我使用的服务器中已经有了一个名为Pytorch1.7的conda环境,顾名思义,这个虚拟环境中安装有1.7版本的torch,而且可以看到python版本为3.7.3,符合要求。因此我不需要再创建新的虚拟环境,只需要source activate torch1.7直接使用即可。python虚拟环境的创建方法可以参考这篇知乎文章
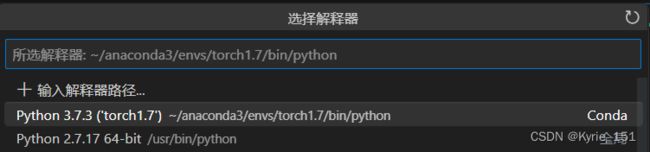
![]()
3.克隆BasicSR代码
参考readme_cn文件:
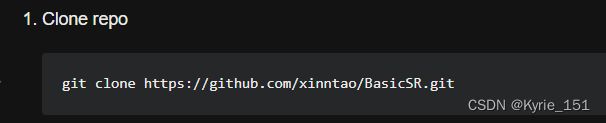
在VScode终端中运行代码:git clone https://github.com/xinntao/BasicSR.git
![]()
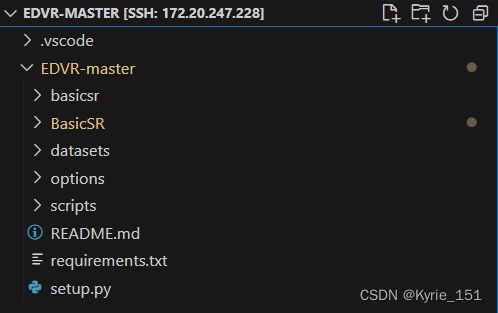
即从github上将代码克隆到项目目录里,如下图。这时目录里除BasicSR外其他的文件夹(如basicsr、options等)就可以删除了,因为BasicSR里有更完整的版本。
4.安装项目依赖的python库
参考readme_cn文件:
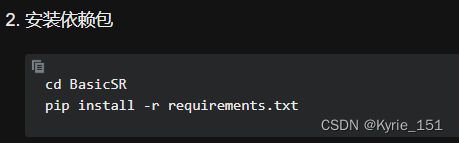
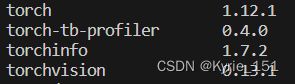
requirement.txt文件中有本项目运行需要的python库,可以先查看本次使用的虚拟环境中已经安装了那些库(pip list),然后将其注释掉,再运行命令pip install -r requirements.txt,安装剩余的库。
5.安装BasicSR
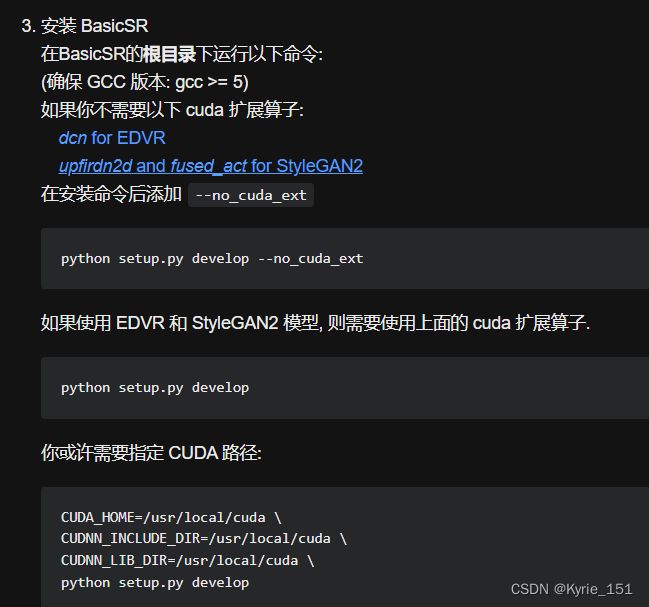
按照readme_cn文件说明,运行setup.py文件即可。
6.下载数据集
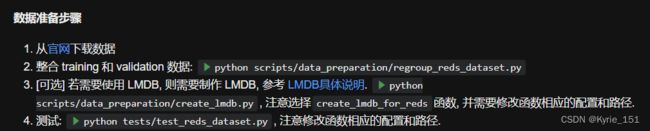
参考DatasetPreparation_CN文件,因为我只用了REDS数据集训练和测试,所以参考REDS的数据准备步骤:
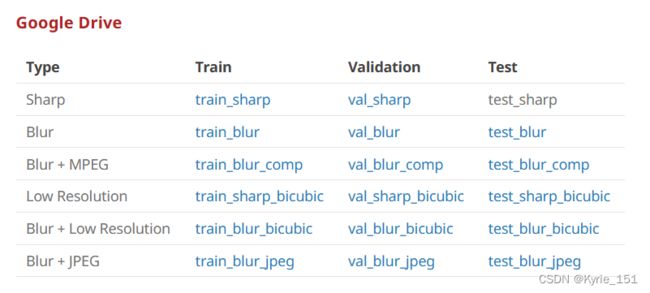
官网提供三种下载方法,我是从 google drive上下载的,需要。REDS数据集分很多类,训练要用到train_sharp、val_sharp、train_sharp_bicubic、val_sharp_bicubic,点击链接即可下载,需要六七个小时才能完成。其他数据集可以在训练完测试时再下载。google drive每一次下载都有时长限制,下载一段时间后会自动中断,而且刷新下载地址后数据会丢失,要重新下载。因此对于个别较大的数据集,如train_sharp有32G,需要分几次才能下载完,就不能直接下载,可以用IDM下载器下载,IDM接管下载任务后,下载中断可以续传。IDM使用方法和免费注册方法,可以参考这两篇文章:
Google Drive(谷歌网盘)下载超大文件方法 - 知乎 (zhihu.com)
http://t.csdn.cn/nm7PI
由于google drive需要,而服务器没有挂代理,因此不能直接将数据集下载到服务器上。只能先下载到本机上,然后用sftp传到服务器上(datasets文件夹),这个过程会花费很长时间,与下载数据集的时间差不多。sftp传文件方法参考这篇文章http://t.csdn.cn/If5wc
数据集下载好后,需要整合训练和测试数据,创建lmdb(这一步可以省略,因为我运行文件时报了一堆错,不知道怎么改,就放弃这一步了,不过不影响后续训练和测试),以及测试,按照说明文档操作就行,但要注意在文件中修改数据集路径,否则会报错:找不到数据集。
7.训练
参考TrainTest_CN.md文件:
预训练模型下载到experiments文件夹
先修改训练的配置文件,将GPU数量改成1,查看数据集路径,如果不正确就需要修改。
num_gpu: 1 # official: 8 GPUs dataroot_gt: datasets/REDS/train_sharp/
dataroot_lq: datasets/REDS/train_sharp_bicubic/X4EDVR有5个训练的配置文件,我选的是train_EDVR_M_x4_SR_REDS_woTSA.yml,该配置不需要预训练模型。
L和M的区别在于num_feat和num_reconstruct_block不同
然后运行单GPU训练命令:

去掉反双斜线,改为空格,将-opt后的路径改为train_EDVR_M_x4_SR_REDS_woTSA.yml的路径
![]()
运行命令后,等待训练完成即可。
因为需要的训练时间很长,训练是分两次完成的。(出于对我新笔记本的爱惜,没有让它在晚上一直开机)
查看训练日志:
![]()
第一次训练是从8月18号早上9:25训练到了8月19号凌晨00:11,用了14小时46分钟,迭代了275000次。
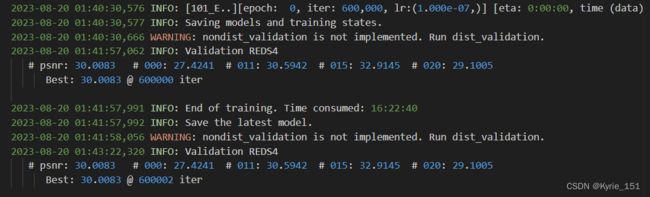
第二次训练从8月19号早上9:19开始,到8月20号凌晨1:40结束,用了16小时22分钟,至此训练完成,一共迭代600000次。
第一次训练中断后,想要在第一次训练基础上继续训练,只需修改配置文件。将resume_state的值设置为上一次训练完时保存的最后一个模型的路径(275000.state)即可。

训练每迭代5000次保存一次模型,并在验证集上进行一次验证,峰值信噪比psnr第一次验证时(迭代5000次)为27.9809,最终达到了30.0083。
8.测试
同样,先修改配置文件,将GPU数量设为1,再确认数据集路径,不正确就要修改。
num_gpu: 1 # official: 8 GPUs dataroot_gt: datasets/REDS/train_sharp/
dataroot_lq: datasets/REDS/train_sharp_bicubic/X4EDVR有7个测试的配置文件,我第一次测试选的是 test_EDVR_M_x4_SR_REDS.yml。这个配置是用REDS数据集测试超分辨率,用到的数据集是train_sharp和train_sharp_bicubic,不用重新下载。
运行单GPU测试命令,修改opt 的选项为test_EDVR_M_x4_SR_REDS.yml的路径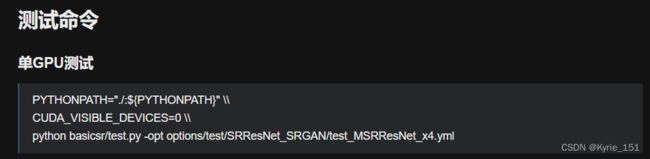
![]()
测试的可视化结果和日志保存在results文件夹里

生成的每一帧图片都可查看:
可以将结果下载下来,然后用pr生成视频,更直观的观看。pr将逐帧图片导出为视频的教程:2分钟教你PR把序列帧图片转成视频_哔哩哔哩_bilibili
除了SR-Clean Track外,其他三个赛道的测试要下载另外三个新的数据集,作为EDVR的输入。
分别是
train_blur : 高分辨率,带有模糊
train_blur_comp: 高分辨率,带有模糊,带有压缩伪影
train_blur_bicubic: 低分辨率,带有模糊
train_blur_bicubic是低分辨率,所以数据集很小,只有2.1G,下载上传很快;而train_blur和train_blur_comp都是高分辨率,数据集很大,分别是26G和21G,下载和上传很费时间,所以我只下载了train_blur。因此我只做了三个赛道的测试,SR-Clean、SR-Blur、Deblur-Clean。
EDVR原文中的结果图:

我的测试结果:
1.SR-Clean: 使用的数据集,GT: train_sharp LQ: train_sharp_bicubic
使用的配置文件:test_EDVR_M_x4_SR_REDS.yml
REDS4 000/0073


EDVR GT 超分效果与原文中的EDVR(S1)基本一致
![]() psnr:30.5274
psnr:30.5274
2.SR-Blur: 使用的数据集,GT: train_sharp LQ: train_blur_bicubic
使用的配置文件:test_EDVR_L_x4_SRblur_REDS.yml
REDS4 011/0024


EDVR GT 超分并去模糊效果与原文中的EDVR(S1)基本一致
![]()
psnr : 28.8819
3.Deblur-Clean: 使用的数据集,GT: train_sharp LQ: train_blur
使用的配置文件:test_EDVR_L_deblur_REDS.yml
REDS4 015/0043


EDVR GT 去模糊效果与原文中EDVR(S1)基本一致
![]()
psnr达到34.8018
4.Deblur-comp: 还未测试
到此,EDVR复现工作基本结束。
暑假这两个月,阅读了无数CSDN博客和知乎的文章,CSDN收藏夹里攒了一百多篇博客,多是关于python的函数教程,知乎收藏夹也攒了六十多篇。但感觉python还是只懂了九牛一毛,对深度学习和CV的理解也并不系统全面。复现代码时出错最痛苦,一个错误要一两天才能解决,很耗时间。而且往往是,网上查了很多原因,读了很多行代码,最后发现代码是正确的,错误原因是一开始运行命令时把文件路径输错,或者python文件中数据集路径没有修改对。路漫漫其修远兮,吾将上下而求索......
第二篇博客,2023/8/29