Flink系列四:flink的状态管理
目录
- 状态的定义
- 状态的类型
- 状态的存储
-
-
- 内存型和文件型状态存储
- 基于RocksDB的StateBackend
-
- 状态的实例
状态的定义
状态在Flink中叫做State,用了保存中间计算结果或者缓存数据。
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
- sum求和
对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。 - 去重
数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。 - 模式检测
检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
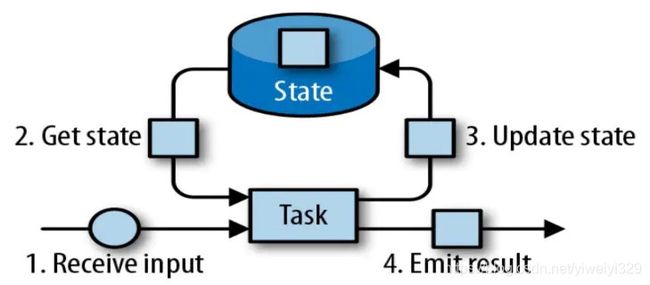
一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。
状态的类型
按照数据结构的不同,Flink中定义了多种State,应用与不同的场景,具体如下:
1、ValueState
即类型为T的单值状态。可以使用 update(T) 进行更新,并通过 value() 获取状态值。
2、ListState
存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
3、MapState
维护 Map 类型的状态。通过put(K,V)或者putAll(Map
4、ReducingState
通过用户传入的 reduceFunction ,使用 add(T) 增加元素时,会调用reduceFunction,最后合并到一个单一的状态值。
5、AggregatingState
聚合状态,和4不同的是,这里聚合的类型可以是不同的元素类型,使用 add(IN) 添加元素,并使用AggregateFunction函数计算聚合结果。
6、FoldingState
和ReducingState类似,不过它的状态值类型可以和add方法中传入的元素类型不同。已被标识为废弃,不建议使用。
State按照是否有key划分为KeyedState和OperateorState两种,如下:
| 按是否有key划分 | 支持的state |
|---|---|
| KeyState | ValueState ListState ReducingState AggregationState MapState FoldingState |
| OperatorState | ListState |
状态的存储
Flink中无论是那种类型的State,都需要被持久化到可靠存储中,才具备应用级到容错能力,State的存储在Flink中叫做StateBackend。StateBackend需要具备如下两种能力。
- 在计算过程中提供访问State的能力,开发者在编写业务逻辑中能够使用
StateBackend的接口读写数据。 - 能够将State持久化到外部存储,提供容错能力。
根据使用场景不同,flink内置了3种StateBackend,如下:
- 纯内存:MemoryStateBackend,适用于验证、测试,不推荐生产环境。
- 内存+文件:FsStateBackend,适用于长周期大规模的数据。
- RocksDB:RocksDBStateBackend,适用于长周期大规模的数据。
上面提到的是面向用户的,那么flink内部3种State的关系如下:

在运行时,MemoryStateBackend和FsStateBackend本地的State都保存在TaskMananger的内存中,所以其底层都依赖于HeapKeyedStateBackend。HeapKeyedStateBackend面向flink引擎内部,使用者无须感知。
内存型和文件型状态存储
内存型和文件型状态存储都依赖于内存保存运行时所需都state,区别在于状态保存的位置。
- 内存型StateBackend
内存型StateBackend在flink中叫作MemoryStateBackend,运行时所需要的State数据保存在TaskManager JVM堆上内存中,KV类型的State、窗口算子的State使用HashTable来保存数据、触发器等。执行检查点的时候,会把State的快照数据保存到JobManager进程的内存中。MemoryStateBackend可以使用异步的方式进行快照,也可以使用同步的方式。推荐使用异步的方式,以避免阻塞算子处理数据。
以下情况推荐使用内存存储:
1)本地开发或调用
2)只保存少量状态的作业。例如仅仅包含一次一条记录算子(例如:Map,FlatMap,Fliter,…)的作业。对于这样的作业,Kafka Consumer 仅仅需要非常少的状态。
内存存储有如下限制:
1)每一个状态大小默认5M。这个值可以在实例化MemoryStateBackend的时候增加。
2)不管配置的最大状态大小是多少,状态大小不能超过akka配置的桢(一次RPC传输的数据)大小(参数: akka.framesize,默认:10M)。
3)状态存储在JobManager的内存中,受限于JobManager的内存大小。 - 文件型StateBackend
FsStateBackend将状态数据保存在TaskManager的内存中。当checkpoint的时候,将状态数据写到配置的分布式文件系统或本地文件系统中。如使用HFDS的路径为:“hdfs://namenode:40010/flink/checkpoints”,使用本地文件系统的路径为:“file:///data/flink/checkpoints”。
FsStateBackend默认使用异步快照,以避免阻塞流处理。
以下情况,推荐使用FsStateBackend
1)具有大状态,长窗口,大的key/value状态的作业
2)所有HA模式下 - 内存型和文件型StateBackend存储结构
内存型和文件型StateBackend依赖于HeapKeydStateBackend,HeapKeyStateBackend使用StateTable存储数据。
StateTable体系如下:

NestedMapsStateTable使用两层嵌套的HashMap保存状态数据,支持同步快照。CopyOnWriteStateTable使用CopyOnWriteStateMap来保存状态数据,支持异步快照,可以避免在保存快照的过程中持续写入导致的状态不一致的问题。
基于RocksDB的StateBackend
RocksDBStateBackend跟内存型和文件型StateBackend不同,其使用嵌入式的本地数据库RocksDB将流计算数据状态存储在本地磁盘中,不会受限于TaskManager的内存大小,在执行检查点的时候,再将整个RocksDB中保存的State数据全量或者增量持久化到配置的文件系统中,在JobManager内存中会存储少量的检查点元数据。RockDB克服了State受内存限制的问题,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
但是RocksDBStateBackend相比基于内存的StateBackend,访问State的成本高很多,可能导致数据流的吞吐量剧烈下降,甚至可能降低为原来的1/10。
- 适用场景
1)最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
2)RocksDBStateBackend非常适合用于高可用方案。
3)RocksDBStateBackend是目前唯一支持增量检查点的后端。增量检查点非常适用于超大状态的场景。 - 注意点
1)总State大小受限于磁盘大小,不受内存限制。
2)RocksDBStateBackend也需要配置外部文件系统,集中保存State。
3)Rocks的JNI API基于byte数组,单key和单value的大小不能超过231 字节。
4)对于使用具有合并操作状态的应用程序,如ListState,随时间可能会累积到超过231 字节大小,这将会导致在接下来到查询中失败。
状态的实例
实例需求:当接收到的相同 key 的元素个数等于 3 个或者超过 3 个的时候,就计算这些元素的 value 的平均值。计算 keyed stream 中每 3 个元素的 value 的平均值。
首先main方法那模拟了一段数据,如下:
DataStream> dataSource = env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
实例调用flatMap获取状态值。因此,需要继承RichFlatMapFunction类且重写类中的open和flatMap方法。open()方法仅会执行一次,在open里面我们会进行状态的注册,而且把这个状态交由Flink去管理。flatMap中对数据进行处理。
1、ValueState
以下内容open函数中把状态注册好,flatMap再取出来用。
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class ValueStateDemo extends RichFlatMapFunction, Tuple2> {
ValueState> countAndSum;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor> descriptor = new ValueStateDescriptor<>("average", Types.TUPLE(Types.LONG, Types.LONG));
countAndSum = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Tuple2 value, Collector> out) throws Exception {
Tuple2 currentState = countAndSum.value();
if (currentState == null) {
currentState = Tuple2.of(0L, 0L);
}
currentState.f0 += 1;
currentState.f1 += value.f1;
countAndSum.update(currentState);
if (currentState.f0 >= 3) {
double avg = (double) currentState.f1 / currentState.f0;
out.collect(Tuple2.of(value.f0, avg));
countAndSum.clear();
}
}
}
public class StateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream> dataSource = env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
DataStream> dataStream = dataSource
.keyBy(0)
.flatMap(new ValueStateDemo()); // valueState
dataStream.print();
env.execute("my state");
}
}
2、ListState
以下内容open函数中把状态注册好,flatMap再取出来用。
import com.google.common.collect.Lists;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Collections;
public class ListStateDemo extends RichFlatMapFunction, Tuple2> {
ListState> elementByKey;
@Override
public void open(Configuration parameters) throws Exception {
ListStateDescriptor> descriptor = new ListStateDescriptor<>("average", Types.TUPLE(Types.LONG, Types.LONG));
elementByKey = getRuntimeContext().getListState(descriptor);
}
@Override
public void flatMap(Tuple2 value, Collector> out) throws Exception {
Iterable> currentState = elementByKey.get();
if (currentState == null) {
elementByKey.addAll(Collections.emptyList());
}
elementByKey.add(value);
ArrayList> allElement = Lists.newArrayList(elementByKey.get());
if (allElement.size() >= 3) {
long count = 0;
long sum = 0;
for (Tuple2 ele : allElement) {
count++;
sum += ele.f1;
}
double avg = (double) sum / count;
out.collect(new Tuple2<>(value.f0, avg));
elementByKey.clear();
}
}
}
public class StateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream> dataSource = env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
DataStream> dataStream = dataSource
.keyBy(0)
.flatMap(new ListStateDemo()); // ListStateDemo
dataStream.print();
env.execute("my state");
}
}
3、MapState
以下内容open函数中把状态注册好,flatMap再取出来用。
import com.google.common.collect.Lists;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.UUID;
public class MapStateDemo extends RichFlatMapFunction, Tuple2> {
MapState mapState;
@Override
public void open(Configuration parameters) throws Exception {
MapStateDescriptor descriptor = new MapStateDescriptor<>("average", String.class, Long.class);
mapState = getRuntimeContext().getMapState(descriptor);
}
@Override
public void flatMap(Tuple2 value, Collector> out) throws Exception {
mapState.put(UUID.randomUUID().toString(), value.f1);
ArrayList arrayList = Lists.newArrayList(mapState.values());
if (arrayList.size()>=3) {
long sum = 0;
long count = 0;
for(Long arr: arrayList) {
count +=1;
sum += arr;
}
double avg = (double) sum/count;
out.collect(Tuple2.of(value.f0, avg));
mapState.clear();
}
}
}
public class StateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream> dataSource = env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
DataStream> dataStream = dataSource
.keyBy(0)
.flatMap(new MapStateDemo()); // MapStateDemo
dataStream.print();
env.execute("my state");
}
}
4、ReducingState
ReducingState具有聚合效果,所以它能模拟出sum的累加并最后得出结果的效果。首先我们会有一个ReducingStateDescriptor descriptor来接收描述,需要实现一个ReduceFunction接口,之后还有一个数据类型Long.class。
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class ReducingStateDemo extends RichFlatMapFunction, Tuple2> {
ReducingState reducingState;
@Override
public void open(Configuration parameters) throws Exception {
ReducingStateDescriptor descriptor = new ReducingStateDescriptor<>("average",
new ReduceFunction() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
},
Long.class);
reducingState = getRuntimeContext().getReducingState(descriptor);
}
@Override
public void flatMap(Tuple2 value, Collector> out) throws Exception {
reducingState.add(value.f1);
out.collect(new Tuple2(value.f0, reducingState.get()));
}
}
public class StateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream> dataSource = env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L),
Tuple2.of(2L, 4L), Tuple2.of(2L, 2L), Tuple2.of(2L, 5L));
DataStream> dataStream = dataSource
.keyBy(0)
.flatMap(new ReducingStateDemo()); // ReducingStateDemo
dataStream.print();
env.execute("my state");
}
}
5、AggregatingState
不常用。
6、FoldingState
已被标识为废弃。