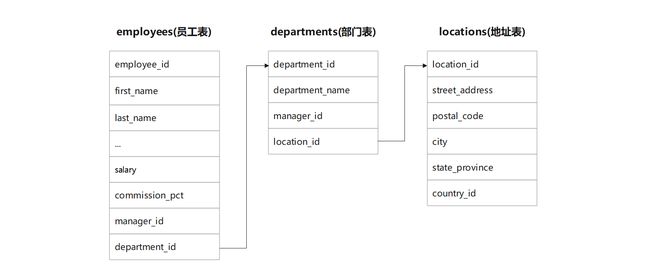
1. 多表查询
多表查询(也叫关联查询, 联结查询): 可以用于检索涉及到多个表的数据.
使用关联查询, 可以将两张或多张表中的数据通过某种关系联系在一起, 从而生成需要的结果集.
前提条件: 这些一起查询的表之间它们之间一定是有关联关系.
mysql> DESC employees;
+
| Field | Type | Null | Key | Default | Extra |
+
| employee_id | int | NO | PRI | 0 | |
| first_name | varchar(20) | YES | | NULL | |
| last_name | varchar(25) | NO | | NULL | |
| email | varchar(25) | NO | UNI | NULL | |
| phone_number | varchar(20) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | | NULL | |
| commission_pct | double(2,2) | YES | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| department_id | int | YES | MUL | NULL | |
+
11 rows in set (0.01 sec)
mysql> DESC departments;
+
| Field | Type | Null | Key | Default | Extra |
+
| department_id | int | NO | PRI | 0 | |
| department_name | varchar(30) | NO | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| location_id | int | YES | MUL | NULL | |
+
4 rows in set (0.00 sec)
mysql> DESC locationS;
+
| Field | Type | Null | Key | Default | Extra |
+
| location_id | int | NO | PRI | 0 | |
| street_address | varchar(40) | YES | | NULL | |
| postal_code | varchar(12) | YES | | NULL | |
| city | varchar(30) | NO | | NULL | |
| state_province | varchar(25) | YES | | NULL | |
| country_id | char(2) | YES | MUL | NULL | |
+
6 rows in set (0.00 sec)
员工表通过"部门id"关联部门表, 部门表通过"地址id"关联地址表.
1.1 分步骤查询
现在查询名字为'Jack'的工作的城市, 多表查询可以通过一张表一张表进行分步查询(不过, 这种方式可能比较麻烦, 效率也不高).
mysql> SELECT first_name, department_id FROM employees WHERE first_name = 'Jack';
+
| first_name | department_id |
+
| Jack | 80 |
+
1 row in set (0.03 sec)
mysql> SELECT department_id, location_id FROM departments WHERE department_id = 80;
+
| department_id | location_id |
+
| 80 | 2500 |
+
1 row in set (0.01 sec)
mysql> SELECT location_id, city FROM locations WHERE location_id = 2500;
+
| location_id | city |
+
| 2500 | Oxford |
+
1 row in set (0.01 sec)
当使用分步骤查询多张表时, 每次查询只能获取一张表的数据, 然后再通过条件去查询下一张表, 以此类推.
这样的处理方式, 需要进行多次数据库查询操作, 增加了数据库的负担, 降低了查询效率.
此外, 分步骤查询还可能导致数据的冗余传输, 即每次查询都需要将上一次查询的结果集传递给下一次查询, 增加了数据传输的开销.
1.2 交叉连接
1.2.1 隐式交叉连接
隐式的交叉连接(implicit cross join): 是指在查询语句中直接使用逗号连接多个表的查询方式.
这种查询语句将返回所有表的笛卡尔积(有人也称它为笛卡尔积连接),
即将左侧表中的每一行与右侧表中的每一行进行组合, 生成所有可能的组合结果.
例如, 假设有两个表A和B, 它们分别包含两列数据, 如下所示:
表 A:
列1 | 列2
-----|-----
1 | a
2 | b
表 B:
列1 | 列2
-----|-----
x | 10
y | 20
使用逗号进行隐式的交叉连接查询:
SELECT 列1, 列2
FROM A, B;
将返回下列笛卡尔积形式的结果集:
列1 | 列2
-----|-----
1 | a
1 | 10
1 | 20
2 | b
2 | 10
2 | 20
隐式的交叉连接会产生非常大的结果集, 并且往往不是我们需要的结果.
SELECT first_name, department_name FROM employees, departments;
mysql> SELECT first_name, department_name FROM employees, departments;
+
| first_name | department_name |
+
| Steven | Payroll |
| ... | ... |
| William | Administration |
+
2889 rows in set (0.03 sec)
1.2.2 避免笛卡尔积错误
笛卡尔积的错误会在下面条件下产生:
* 1. 省略多个表的连接条件(或关联条件).
* 2. 连接条件(或关联条件)无效.
* 3. 所有表中的所有行互相连接
为了避免笛卡尔积, 可以在WHERE加入有效的连接条件.
当多个表中具有相同列名时, 需要使用表名前缀来区分不同表中的列名.
在使用带有表名前缀的列名时, 查询语句如下:
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;
使用了WHERE子句来指定连接条件, 即table1.column1 = table2.column2.
这个连接条件指定了如何将table1和table2中的数据组合在一起.
注意: 使用隐式连接时, 如果不使用表名前缀指定列名, 则可能会出现名字冲突, 并且sql检查器可能无法确定需要连接哪些列m 从而产生错误.
因此, 使用表名前缀来指定列名是一种很好的习惯.
mysql> SELECT first_name, department_name FROM employees, departments
-> WHERE employees.department_id = departments.department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| ... | ... |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set (0.01 sec)
mysql> SELECT first_name, department_id FROM employees WHERE department_id <=> NULL;
+
| first_name | department_id |
+
| Kimberely | NULL |
+
1 row in set (0.01 sec)
mysql> SELECT employees.first_name, departments.department_name FROM employees, departments
-> WHERE employees.department_id = departments.department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| ... | ... |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set (0.00 sec)
1.2.3 表别名
可以使用AS语句(或者使用空格作为别名分隔符)设置别名, 使用表别名可以让查询语句更易读, 易理解.
表别名可以给每个表指定一个简短的名称, 这样在查询语句中引用这些表时, 可以使用简短的别名代替完整的表名, 使查询语句更简洁明了.
这样的查询语句更容易阅读, 也更容易理解其含义.
注意事项:
* 1. 一旦为表设置了别名, 就应该使用这个别名来引用这个表, 而不能再使用原名, 否则会报错.
* 2. 当表名或列名中包含空格, 特殊字符或与MySQL关键字冲突时, 可以通过使用反引号(`)包裹,
这样可以确保MySQL正确解析这些标识符(不能使用单双引号).
mysql> SELECT `e mp`.first_name, dept.department_name FROM employees AS `e mp`, departments AS `dept`
-> WHERE `e mp`.department_id = dept.department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| ... | ... |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set (0.00 sec)
如果有n个表实现多表的查询, 则需要至少n-1个连接条件.
mysql> SELECT locs.city FROM employees AS `emp`, departments AS `dept`, locations AS `locs`
WHERE emp.department_id = dept.department_id AND dept.location_id = locs.location_id AND emp.first_name = 'Jack';
+
| city |
+
| Oxford |
+
1 row in set (0.00 sec)
1.2.4 交叉连接完整格式
交叉连接完整格式: 表与表之间使用关键字CROSS JOIN连接:
SELECT 列1, 列2
FROM A CROSS JOIN B;
WHERE A.column1 = B.column2;
mysql> SELECT locs.city FROM employees AS `emp` CROSS JOIN departments AS `dept` CROSS JOIN locations AS `locs`
-> WHERE emp.department_id = dept.department_id AND dept.location_id = locs.location_id AND emp.first_name = 'Jack';
+
| city |
+
| Oxford |
+
1 row in set (0.02 sec)
2. 多表查询分类
2.1 等值连接与非等值连接
等值连接和非等值连接是关系型数据库查询中的两种主要连接方式, 它们的主要区别在于连接条件的不同.
* 1. 等值连接(Equi-Join): 在等值连接中, 连接条件是两个表中的列值相等.
也就是说, 等值连接会根据连接条件从一个表中选取每一行数据, 然后与另一个表中满足相同条件的行进行连接.
例如, 如果有两个表A和B, 其中一个连接条件为"A.id = B.id", 那么这个连接就是一个等值连接,
它会将A表中id字段的值与B表中id字段的值相等的行连接起来.
* 2. 非等值连接(Non-Equi-Join): 在非等值连接中, 连接条件可以是两个表中的列值不等或者使用其他比较运算符(如<, >, <=, >=等).
非等值连接会根据连接条件从一个表中选取每一行数据, 然后与另一个表中满足条件的行进行连接.
例如, 如果有两个表A和B, 其中一个连接条件为"A.salary > B.salary", 那么这个连接就是一个非等值连接,
它会将A表中salary字段的值大于B表中salary字段的值的行连接起来.
* 等值连接要求连接条件中的列值相等, 而非等值连接则可以使用其他比较运算符进行连接.
mysql> SELECT emp.first_name, dept.department_name FROM employees AS `emp`, departments AS `dept`
-> WHERE emp.department_id = dept.department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| Shelli | Purchasing |
| Sigal | Purchasing |
| ... | ... |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set (0.04 sec)

mysql> select * from job_grades;
+
| grade_level | lowest_sal | highest_sal |
+
| A | 1000 | 2999 |
| B | 3000 | 5999 |
| C | 6000 | 9999 |
| D | 10000 | 14999 |
| E | 15000 | 24999 |
| F | 25000 | 40000 |
+
6 rows in set (0.01 sec)
mysql> SELECT emp.first_name, emp.salary, jg.grade_level FROM employees AS `emp`, job_grades AS `jg`
WHERE emp.salary BETWEEN jg.lowest_sal AND jg.highest_sal;
+
| first_name | salary | grade_level |
+
| Steven | 24000.00 | E |
| Neena | 17000.00 | E |
| Lex | 17000.00 | E |
| Alexander | 9000.00 | C |
| ... | ... | . |
| Jennifer | 4400.00 | B |
| Michael | 13000.00 | D |
| Pat | 6000.00 | C |
| Susan | 6500.00 | C |
| Hermann | 10000.00 | D |
| Shelley | 12000.00 | D |
| William | 8300.00 | C |
+
107 rows in set (0.00 sec)

2.2 自连接与非自连接
自连接和非自连接都是关系型数据库中的连接操作, 但它们连接的表的数量和类型有所不同.
* 1. 自连接: 是指一张表与其自身进行连接, 通过将同一张表复制为两份并对它们进行连接操作, 可以找出表内的相关数据并进行比较.
自连接通常用于查找存在于同一表中的相关数据, 例如员工与员工的上下级关系, 物品与物品的相似度等.
* 2. 非自连接则是指连接不同的表, 通过将不同表的列进行匹配, 可以从多个表中获取相关联的数据并进行更复杂的查询操作.
非自连接可以用于执行各种联接操作, 包括内连接, 外连接, 交叉连接等.
总之, 自连接和非自连接都是关系型数据库中的连接操作, 但它们的操作对象和目的有所不同.
mysql> SELECT worker.first_name AS "员工名字", manager.first_name AS "管理者名字"
-> FROM employees AS `worker`, employees AS `manager`
-> WHERE worker.manager_id = manager.employee_id;
+
| 员工名字 | 管理者名字 |
+
| Neena | Steven |
| Lex | Steven |
| Alexander | Lex |
| Bruce | Alexander |
| David | Alexander |
| Valli | Alexander |
| ... | ... |
| Jennifer | Neena |
| Michael | Steven |
| Pat | Michael |
| Susan | Neena |
| Hermann | Neena |
| Shelley | Neena |
| William | Shelley |
+
106 rows in set (0.00 sec)
2.3 SQL99 多表查询语法
SQL99(也称为SQL:1999)引入了标准的多表查询语法, 以提供更强大和灵活的多表查询功能.
以下是SQL99多表查询的一般语法结构:
SELECT 列名1, 列名2, ...
FROM 表名1
JOIN 表名2 ON 连接条件
[JOIN 表名3 ON 连接条件]
...
WHERE 条件;
这里是每个部分的解释:
- SELECT: 指定要从查询结果中返回的列.
- FROM: 指定要查询的表, 可以指定一个或多个表.
- JOIN: 用于将表连接起来, 可以使用多个JOIN语句实现多个表的连接.
- ON: 指定连接条件, 用于确定如何连接表.
- WHERE: 可选项, 用于指定额外的过滤条件.
* 关键字 JOIN, INNER JOIN, CROSS JOIN的含义是一样的, 都表示内连接.
mysql> SELECT locs.city
FROM employees AS `emp` JOIN departments AS `dept` ON emp.department_id = dept.department_id
JOIN locations AS `locs` ON dept.location_id = locs.location_id
WHERE emp.first_name = 'Jack';
+
| city |
+
| Oxford |
+
1 row in set (0.00 sec)
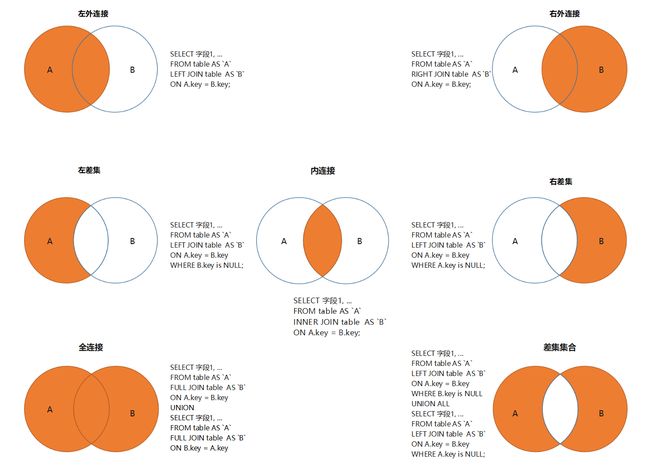
2.4 内连接与外连接
内连接和外连接是数据库中两种主要的连接类型, 它们在多表查询中起着重要的作用.
* 1. 内连接(Inner Join): 也被称为自然连接, 它是最常见的连接类型.
它基于两个或多个表之间的相等关系, 返回满足连接条件的匹配行.
内连接只返回符合连接条件的行, 其他不满足条件的行将被排除.
* 2. 外连接则包括左外连接, 右外连接和全外连接.
1. LEFT JOIN(左连接): 左连接将返回左表中的所有行, 以及符合连接条件的右表中的匹配行.
如果右表中没有与左表匹配的行, 则返回NULL值.
左连接常用于需要包含左表中的全部数据, 并根据连接条件关联右表的查询需求.
2. RIGHT JOIN(右连接): 右连接与左连接相反, 它将返回右表中的所有行, 以及符合连接条件的左表中的匹配行.
如果左表中没有与右表匹配的行, 则返回NULL值.
右连接在需要包含右表中的全部数据, 并根据连接条件关联左表的查询需求时使用.
3. FULL JOIN(全连接): 全连接返回两个表中所有行的组合, 不管是否满足连接条件.
如果没有匹配的行, 则返回NULL值.
全连接常用于需要包含两个表中全部数据的查询.
总的来说, 内连接只返回两个表中相关联的数据, 而外连接则返回更全面的数据结果, 包括了没有匹配的行.
在MySQL中, "左表"和"右表"是相对于SQL中使用多表查询时指定的表的位置.
当使用JOIN操作将两个或多个表连接时, 左表是在JOIN操作中使用的第一个表, 而右表是在JOIN操作中使用的第二个表(或后续表).
这个术语通常用于描述不同类型的JOIN操作, 如LEFT JOIN和RIGHT JOIN.
LEFT JOIN将左表作为主表, 并在结果中包含左表的所有记录, 而右表中匹配的记录将按照JOIN条件进行连接.
相反, RIGHT JOIN将右表作为主表, 并在结果中包含右表的所有记录, 同时将左表中匹配的记录进行连接.
总之, 左表和右表是相对于多表查询中使用的表的位置, 用于描述JOIN操作中的表连接顺序和结果.
SELECT 字段列表 FROM A表 LEFT OUTER JOIN B表 ON 关联条件 WHERE 等其他子句;
SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| ... | ... | .. | ... |
| Kimberely | 178 | NULL | NULL |
| ... | ... | .. | ... |
| Hermann | 204 | 70 | Public Relations |
| Shelley | 205 | 110 | Accounting |
| William | 206 | 110 | Accounting |
+
107 rows in set (0.00 sec)
SELECT 字段列表 FROM A表 RIGHT OUTER JOIN B表 ON 关联条件 WHERE 等其他子句;
SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
mysql> select * from departments;
+
| department_id | department_name | manager_id | location_id |
+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| 30 | Purchasing | 114 | 1700 |
| 40 | Human Resources | 203 | 2400 |
| 50 | Shipping | 121 | 1500 |
| 60 | IT | 103 | 1400 |
| 70 | Public Relations | 204 | 2700 |
| 80 | Sales | 145 | 2500 |
| 90 | Executive | 100 | 1700 |
| 100 | Finance | 108 | 1700 |
| 110 | Accounting | 205 | 1700 |
| 120 | Treasury | NULL | 1700 |
| 130 | Corporate Tax | NULL | 1700 |
| 140 | Control And Credit | NULL | 1700 |
| 150 | Shareholder Services | NULL | 1700 |
| 160 | Benefits | NULL | 1700 |
| 170 | Manufacturing | NULL | 1700 |
| 180 | Construction | NULL | 1700 |
| 190 | Contracting | NULL | 1700 |
| 200 | Operations | NULL | 1700 |
| 210 | IT Support | NULL | 1700 |
| 220 | NOC | NULL | 1700 |
| 230 | IT Helpdesk | NULL | 1700 |
| 240 | Government Sales | NULL | 1700 |
| 250 | Retail Sales | NULL | 1700 |
| 260 | Recruiting | NULL | 1700 |
| 270 | Payroll | NULL | 1700 |
+
27 rows in set (0.00 sec)
mysql> SELECT DISTINCT department_id FROM employees;
+
| department_id |
+
| NULL |
| 10 |
| 20 |
| 30 |
| 40 |
| 50 |
| 60 |
| 70 |
| 80 |
| 90 |
| 100 |
| 110 |
+
12 rows in set (0.00 sec)
部门表中有27个部门的信息,
员工表中右一个人没有部门, 其他的106人分别在11个部门下工作, 那么部门表中还有16个部门没有员工.
使用右连接后应该有: 106 + 16 = 122 条数据.
106: 是满足"emp.department_id = dept.department_id"的数据.
16: 是没有满足"emp.department_id = dept.department_id"的数据.
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Jennifer | 200 | 10 | Administration |
| ... | ... | .. | ... |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
122 rows in set (0.02 sec)
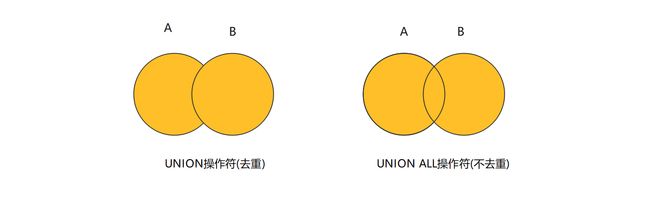
2.5 UNION合并语句
UNION关键字: 用于将两个或更多SELECT语句的结果集合并成一个结果集, 它用于在SQL查询中合并多个查询的结果.
当使用UNION时, 每个SELECT语句必须具有相同的列数和相似的数据类型, 因为UNION会将它们的结果合并到一个结果集中.
UNION会自动去重, 即如果两个查询结果中有相同的行, UNION只会保留其中一个.
除了UNION外, 还有UNION ALL, 它与UNION类似, 但不会去重, 即会保留所有查询结果中的行, 包括重复的行.
SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;
UNION [ALL]
SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
使用全连接后应该有: 1 + 106 + 16 = 123 条数据.
106: 是满足"emp.department_id = dept.department_id"的数据.
17 : 是没有满足"emp.department_id = dept.department_id"的数据(左边有1条不满足, 右边有16条不满足).
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
UNION
SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| ... | ... | .. | ... |
| Jack | 177 | 80 | Sales |
| Kimberely | 178 | NULL | NULL |
| ... | ... | .. | ... |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
123 rows in set (0.01 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
UNION ALL
SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| ... | ... | .. | ... |
| NULL | NULL | 270 | Payroll |
+
229 rows in set (0.00 sec)
mysql> SELECT department_id, first_name, email FROM employees
WHERE department_id > 90 OR email LIKE '%a%';
+
| department_id | first_name | email |
+
| 90 | Neena | NKOCHHAR |
| 90 | Lex | LDEHAAN |
| 60 | Alexander | AHUNOLD |
| .. | ... | ... |
| 40 | Susan | SMAVRIS |
| 70 | Hermann | HBAER |
| 110 | Shelley | SHIGGINS |
| 110 | William | WGIETZ |
+
67 rows in set (0.00 sec)
mysql> SELECT department_id, first_name, email FROM employees WHERE department_id > 90
UNION
SELECT department_id, first_name, email FROM employees WHERE email LIKE '%a%';
+
| department_id | first_name | email |
+
| 90 | Neena | NKOCHHAR |
| 90 | Lex | LDEHAAN |
| 60 | Alexander | AHUNOLD |
| .. | ... | ... |
| 40 | Susan | SMAVRIS |
| 70 | Hermann | HBAER |
| 110 | Shelley | SHIGGINS |
| 110 | William | WGIETZ |
+
67 rows in set (0.00 sec)
2.6 USING连接
自然连接 NATURAL JOIN
同名字段连接 USING JOIN
2.7 连接方式总结
mysql> SELECT employee_id, first_name, department_name
FROM employees AS `EMP`
JOIN departments AS `dept`
ON emp.`department_id` = dept.`department_id`;
+
| employee_id | first_name | department_name |
+
| 200 | Jennifer | Administration |
| 201 | Michael | Marketing |
| ... | ... | ... |
| 113 | Luis | Finance |
| 205 | Shelley | Accounting |
| 206 | William | Accounting |
+
106 rows in set (0.00 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| ... | ... | .. | ... |
| Kimberely | 178 | NULL | NULL |
| ... | ... | .. | ... |
| Hermann | 204 | 70 | Public Relations |
| Shelley | 205 | 110 | Accounting |
| William | 206 | 110 | Accounting |
+
107 rows in set (0.00 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Jennifer | 200 | 10 | Administration |
| ... | ... | .. | ... |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
122 rows in set (0.02 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
WHERE dept.department_id is null;
+
| first_name | employee_id | department_id | department_name |
+
| Kimberely | 178 | NULL | NULL |
+
1 row in set (0.00 sec)
SELECT A.*
FROM table_A A
LEFT JOIN table_B B ON A.key_column = B.key_column
WHERE B.key_column IS NULL;
SQL查询中, 使用LEFT JOIN来连接table_A和table_B.
这意味着, 获取到 table_A 的所有记录, 并与table_B中匹配的记录进行连接.
如果table_B中没有与table_A中的记录匹配的记录, 那么table_B中的所有列都将为NULL.
因此, 当我们使用WHERE B.key_column IS NULL, 我们实际上是在查找那些在table_B中没有与table_A中的记录匹配的记录.
换句话说, 这些记录存在于table_A中, 但不存在于table_B中, 即 A - (A ∩ B).
现在有一个员工的id为null, 那么A.key_column IS NULL得到的结果没有问题(但这并不代表这个方式是正确的).
如果员工的id不是null, 而是其他不存在与B表中的id, 那么那么A.key_column IS NULL得到的结果就是一个空集.
B.key_column IS NULL能保证结果一定是对的, 而A.key_column IS NULL无法保证!
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
WHERE emp.department_id IS NULL;
+
| first_name | employee_id | department_id | department_name |
+
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
16 rows in set (0.00 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
UNION
SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| ... | ... | .. | ... |
| Jack | 177 | 80 | Sales |
| Kimberely | 178 | NULL | NULL |
| ... | ... | .. | ... |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
123 rows in set (0.01 sec)
mysql> SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` LEFT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
WHERE dept.department_id IS NULL
UNION ALL
SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS `emp` RIGHT JOIN departments AS `dept`
ON emp.department_id = dept.department_id
WHERE emp.department_id IS NULL;
+
| first_name | employee_id | department_id | department_name |
+
| Kimberely | 178 | NULL | NULL |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
17 rows in set (0.00 sec)