一文理解什么是贝叶斯优化的随机森林
贝叶斯优化
简介
贝叶斯优化是一种启发式的全局优化方法,用于优化那些评估代价高昂且可能带有噪音的黑盒函数。其核心思想是:在每一步,都利用已知的函数评估来构建一个概率模型,预测黑盒函数在未知点上的值,并据此选择下一个最有可能优化目标的点。
深入理解
-
概率模型:贝叶斯优化的核心是一个概率模型,通常是高斯过程(Gaussian Process, GP)。高斯过程为每个输入点提供了一个预测值和一个不确定性(通常是标准偏差)。
-
获取函数:概率模型用于构建一个“获取函数”(例如,预期改进或上界置信度),该函数在每一步都决定下一个查询点。其目的是在探索(尝试未知或不确定的区域)和利用(选择当前认为最好的点)之间取得平衡。
-
更新和迭代:当新的点被评估后,它的结果会用来更新概率模型,然后再次选择下一个点。这个过程重复进行,直到满足停止条件。
举个例子就明白了嘿!
想象你在一个未知的山脉中寻找最高峰,但你不能看到全貌,只能在地图上选择一个点去检查其高度。每次你选择一个点,你都获得了关于这座山的更多信息。贝叶斯优化就是帮助你做出这些决策的方法。
1. 高斯过程:你的高德地图
高斯过程(GP)就像一个指南,它基于你到目前为止探测的点,为你提供对整个山脉的一个“最佳猜测”。具体来说,它对每一个你还没有探测过的点都给出了一个预测的高度,并估计了这个预测有多确定(或说有多大的不确定性)。这里的“不确定性”就是那些你还没有探测过的地方,GP不确定那里的具体高度。
2. 获取函数:你的探索策略
现在,你有了一个基于已知数据的山的模型,但你应该去哪里探测下一个点呢?你想找到最高的峰,但同时你也想去那些不确定性很高的地方,因为那里可能隐藏着更高的峰。这就是“获取函数”的角色。它告诉你基于目前的知识和不确定性,下一个探测点最有可能在哪里。它在两个策略之间找到平衡:探索你不太确定的地方,或是利用你已经知道的高点。
3. 更新和迭代:成为山脉专家
每当你探测一个新点,你都会获得更多关于这座山的信息。所以,你会更新你的“山地指南”(GP模型),使其包括这个新的信息。然后,你再次使用“获取函数”来决定下一个探测点。这个过程会一直重复,直到你觉得自己已经找到了最高峰,或是已经探测了足够多的点。
优势与局限性
贝叶斯优化的主要优势是它在每一步都充分利用了所有已知的信息,这使其在很多应用中,特别是那些函数评估非常昂贵的情境中,都表现得相当高效。
然而,贝叶斯优化也有其局限性。它主要适用于低到中等维度的优化问题。对于高维问题,可能需要更复杂的方法或其他类型的模型来提供有效的指导。
随机森林简介
随机森林是一种集成学习方法,通过结合多个决策树来提高预测准确性和控制过拟合。随机性来源于两个方面:对数据的随机子样本选择和在每个决策点处的特征子集的随机选择。
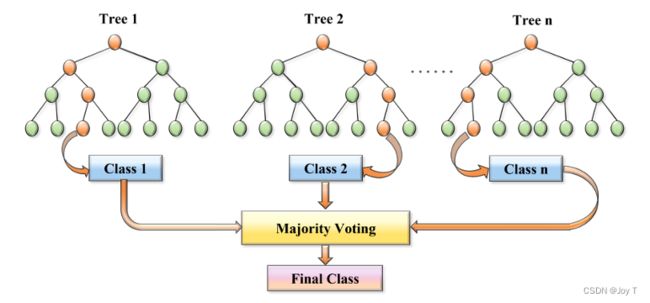
例子
1. 单个决策树:你的个人向导
想象决策树就像山区的一位向导。当你问这位向导“我应该去哪里找到最高的峰?”他会问你一系列问题,如:“你现在是在北坡还是南坡?”、“你当前的海拔是多少?”等。根据你的答案,他会引导你沿着某条路径前进,直到他认为你找到了一个不错的高峰。但这只是他的个人意见,其他向导可能会给你不同的建议。
2. 随机森林:集合多个向导的智慧
现在,想象你聘请了数百名这样的向导,并请他们所有人都给出自己的建议。每个向导都基于自己的经验和部分随机选择的信息来为你提供建议。这就是随机森林的核心思想:它是由多个决策树(即向导)组成的,每个树都基于数据的一个随机子集进行训练。
当你要预测或分类一个新点时,你就会询问这些向导他们的建议,然后做出一个基于他们大多数建议的决策。这样,你不再依赖一个单一的向导,而是依赖整个“森林”的智慧。
3. 为何使用随机森林:健壮性和准确性
你可能会问,为什么要同时请多位向导,而不是依赖单一的最经验丰富的那位?原因在于多样性。单一的向导可能会有自己的偏见或过于依赖某些特定信息,而随机森林通过融合多个决策树的意见,可以降低这种风险。因此,随机森林通常比单个决策树更加健壮,误差更小,并且对异常值不敏感。
介绍
1. 基本构成:决策树的集合
随机森林是一种集成学习方法,由多个决策树组成。每棵树都是独立地基于数据的随机子集进行训练的。
2. 数据的随机选择:Bootstrap抽样
每棵决策树在训练时都使用一种称为Bootstrap抽样的技术,从原始数据集中随机选取样本(有放回地选择),从而形成新的训练集,这个训练集就是数据的随机子集,这是随机森林“随机”的起源之一。这意味着每棵树可能会使用到某些样本多次,而完全忽略其他样本。
3. 特征的随机选择
除了对数据进行随机抽样外,随机森林在每次分裂节点时还会随机选择一部分特征。这样确保了每棵树在结构和决策上的多样性。让我们详细说明一下:
首先,让我们理解一下决策树的分裂。
在决策树和随机森林的背景中,“分裂”是一个过程,通过这个过程,数据会被根据某个特定的标准(如某个特征的值)划分为两个或更多的子集。
想象一下,你有一篮子水果,里面既有苹果又有香蕉。你的目标是将苹果和香蕉分开。一种简单的方法是根据“水果类型”进行“分裂”:所有的苹果放在一个篮子里,所有的香蕉放在另一个篮子里。
在决策树中,我们也做同样的事情,但不是与水果,而是与数据。我们查看数据的特征(例如年龄、性别、收入等)并选择一个特征来“分裂”数据,以使结果更“纯”。纯度意味着尽可能减少每个子集中类别的混合。例如,假设我们有以下数据,并想知道谁会在雨中打伞:
名字 是否带伞 Alice 是 Bob 否 Carol 是 如果我们知道每个人都是因为他们不想淋湿而带伞的,我们可以使用“不想淋湿”这一特征进行“分裂”:那些不想淋湿的人会带伞,而其他人则不会。在这里,“分裂”是一个决策点,它告诉我们如何将数据分为两部分:带伞的人和不带伞的人。当我们在决策树中进行“分裂”时,我们试图找到最佳的方式(即哪个特征)来区分数据,使每个子集尽可能地纯净。
在决策树中,每次节点分裂的目的是找到一个特征,使得其分裂可以最大程度地增加信息增益(或者其他定义的纯度增益)。对于常规的决策树,这一步会考虑数据集中的所有特征,并选择其中的最佳特征进行分裂。但是,在随机森林的构建中,为了增加多样性,每次分裂时并不会考虑所有的特征。而是随机选取一部分特征,并在这部分特征中选择最佳的特征来进行分裂。
随机选择特征:当一个节点需要分裂时,算法会从所有的特征中随机选取一个特征子集。这个子集的大小通常是所有特征数的平方根,但这个数值也可以作为参数进行调整。
最佳特征分裂:然后,算法会在这个随机选取的特征子集中寻找最佳的分裂特征,与常规的决策树相同,选择的标准通常是信息增益或基尼不纯度。
增加多样性:由于每次分裂都是基于一个随机的特征子集,这确保了每棵树的结构和决策都是多样化的。这种随机性是随机森林减少过拟合和增加泛化性能的关键要素。
这个特性与Bootstrap抽样一起,确保了随机森林中每棵树的独立性和多样性,这也是随机森林为什么能够在很多应用中取得很好性能的原因之一。
4. 预测:多数投票
当进行分类任务时,随机森林的预测是基于所有决策树的投票结果来决定的。每棵树都会单独做出预测,而随机森林则选择票数最多的类别作为最终预测结果。对于回归任务,预测值是所有决策树预测值的平均。
5. 优点:减少过拟合和增加健壮性
由于每棵树都是在数据和特征的随机子集上训练的,所以随机森林往往能够减少模型的过拟合。多样性不仅增加了模型的健壮性,还提高了其准确性。
6. 参数与调整
随机森林的关键参数包括森林中的决策树数量、在每次分裂时考虑的特征数量等。通过适当地调整这些参数,可以进一步优化模型的性能。而这个调整参数的过程,就可以使用贝叶斯优化。
贝叶斯优化与随机森林结合
随机森林算法有多个超参数,如树的数量、最大深度、最小叶子节点样本数等。手动选择或网格搜索可能不是最有效的方式。贝叶斯优化为解决这个问题提供了一个高效的方法。
1. 高斯过程 & 概率模型:
贝叶斯优化使用概率模型,通常为高斯过程(Gaussian Process, GP),来预测超参数的性能。高斯过程为每组超参数提供预测的性能值以及这个预测的不确定性(通常为标准偏差)。
2. 获取函数:
使用高斯过程的预测,贝叶斯优化定义“获取函数”,如预期改进 (Expected Improvement) 或上界置信度 (Upper Confidence Bound)。获取函数的目标是在尝试未知的超参数(探索)和选择当前认为性能最好的超参数(利用)之间找到平衡。
3. 优化循环:
- 使用当前的概率模型,通过获取函数选择下一组要评估的超参数。
- 使用随机森林的这组超参数在验证集上进行训练并评估其性能。
- 将新的超参数和性能值加入到已知数据中。
- 使用所有已知的数据更新高斯过程模型。
- 重复此过程直到满足停止条件,例如预定的迭代次数或性能的提高小于某个阈值。
4. 结果:
贝叶斯优化最终将推荐一组超参数,它认为这组超参数能够为随机森林提供最佳的性能。