Hive Locking(锁机制)
Hive锁机制诞生原因
Hive的锁机制是为了让Hive支持并发读写而设计的。
来自于官网的前言
并发支持是数据库中必须的,并且它们的用例很好理解。至少,我们希望尽可能支持并发读取器和写入器。添加一种机制来发现当前已获取的锁会很有用。不需要立即添加 API 来显式获取任何锁,因此所有锁都将被隐式获取。
官网入口:https://cwiki.apache.org/confluence/display/Hive/Locking
Hive中定义的两种锁
Shared (S):共享锁/“S”锁,读取表时会获取“S”锁,可以同时获取多个“S”锁。
Exclusive (X):排他锁/“X”锁,增、删、改操作会获取X锁,X锁会阻塞所有其他锁。
来自于官网的兼容性矩阵图
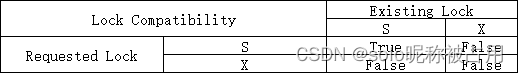
获取锁模式的原因
对于非分区表:读取表时(select操作),会获取 “S”锁,而对于所有其他操作(alter、insert等操作),都会获取 “X”锁。
对于分区表:执行读取时会获取表和相关分区上的“S”锁。对于所有其他操作,在分区上采用“X”锁。但是,如果更改仅适用于较新的分区,则在表上获取“S”锁,而如果更改适用于所有分区,则在表上获取“X”锁。因此,可以读取和写入较旧的分区,而将较新的分区转换为 RCFile。每当一个分区被锁定在任何模式时,它的所有父分区都被锁定在“S”模式。
分区表获取的锁如下表所示:
| Hive Command | Locks Acquired |
|---|---|
| select … T1 partition P1 | S on T1, T1.P1 |
| insert into T2(partition P2) select … T1 partition P1 | S on T2, T1, T1.P1 and X on T2.P2 |
| insert into T2(partition P.Q) select … T1 partition P1 | S on T2, T2.P, T1, T1.P1 and X on T2.P.Q |
| alter table T1 rename T2 | X on T1 |
| alter table T1 add cols | X on T1 |
| alter table T1 replace cols | X on T1 |
| alter table T1 change cols | X on T1 |
| alter table T1 concatenate | X on T1 |
| alter table T1 add partition P1 | S on T1, X on T1.P1 |
| alter table T1 drop partition P1 | S on T1, X on T1.P1 |
| alter table T1 touch partition P1 | S on T1, X on T1.P1 |
| alter table T1 set serdeproperties | S on T1 |
| alter table T1 set serializer | S on T1 |
| alter table T1 set file format | S on T1 |
| alter table T1 set tblproperties | X on T1 |
| alter table T1 partition P1 concatenate | X on T1.P1 |
| drop table T1 | X on T1 |
死锁
“S”锁和“X”锁同时出现,会发生死锁的情况(查询和写入/更改不可同时发生)。
避免死锁
为了避免死锁,所有要锁定的对象都按字典顺序排序,并获得所需的模式锁。在某些情况下,对象列表可能是未知的——例如,在动态分区的情况下,正在修改的分区列表在编译时是未知的——因此,该列表是保守地生成的。由于可能不知道分区的数量,因此应该在表上使用“X”锁。
查看表锁命令
SHOW LOCKS <TABLE_NAME>;
SHOW LOCKS <TABLE_NAME> EXTENDED;
SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>);
SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>) EXTENDED;
关闭锁机制
set hive.support.concurrency=false; --关闭并发
案例分享
由于我们的调度平台是购买的第三方基于DophinScheduler二开的平台,当时有一个脚本A依赖脚本B,脚本A在刷历史数据的时候,在调度平台上手工停止,但并未停止成功(平台的Bug),导致脚本A一直在集群中运行,由于脚本A依赖脚本B,在运行时一直查脚本B的表,而脚本B后来作了修改,提交时一直卡着不动,过了很久后报错,查日志报错如下:
FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
原因分析
脚本A中一直在查脚本B中要insert的表,select表时,该表会进入“S”锁模式,insert/alter等操作会在“S”锁释放后才执行。在锁冲突时,可以通过设置重试等待锁释放,参数如下:
set hive.lock.numretries --重试次数
set hive.lock.sleep.between.retries --重试时sleep的时间
由于脚本A中一直在查脚本B的insert的表,导致脚本B在insert该表时,不断重试等待表锁被释放,当重试次数超过设定参数后,就会报上面提示的错误。
总结
当脚本运行一直卡着不动,很久时间后报错日志如下:
FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
则是因为表锁冲突,导致insert/alter等操作失败。
解决办法
1.可以通过关闭并发,从而关闭锁机制;
2.调整重试次数和sleep时间;
set hive.support.concurrency=false;--关闭并发
set hive.lock.numretries=100; --重试次数
set hive.lock.sleep.between.retries=60s; --重试时sleep的时间