Python基础(11)-- numpy.argpartition函数
1.前言
在深挖自己研究领域的代码过程中,发现np.argpartition函数出现在核心代码部分,并且出现的频率很高,对于我理解这段代码也有很大的帮助,决定彻底搞懂,话不多说,Let’s go!
2.函数解析
在最新版本的numpy 1.8中,是这样描述argpartition函数的。

大致意思是:沿着给定的维度(axis参数所决定)使用特定的算法(kind参数所决定)对输入a执行分区。函数的返回值是一个与输入a有着相同shape的索引,这个索引是根据分区的顺序和给定的维度进行分区得到的。
嗯……,不说是晦涩难懂吧,反正是不怎么好理解。没关系,让我们先看一下函数的各个参数具体代表什么含义,可能会帮助我们理解这个函数。
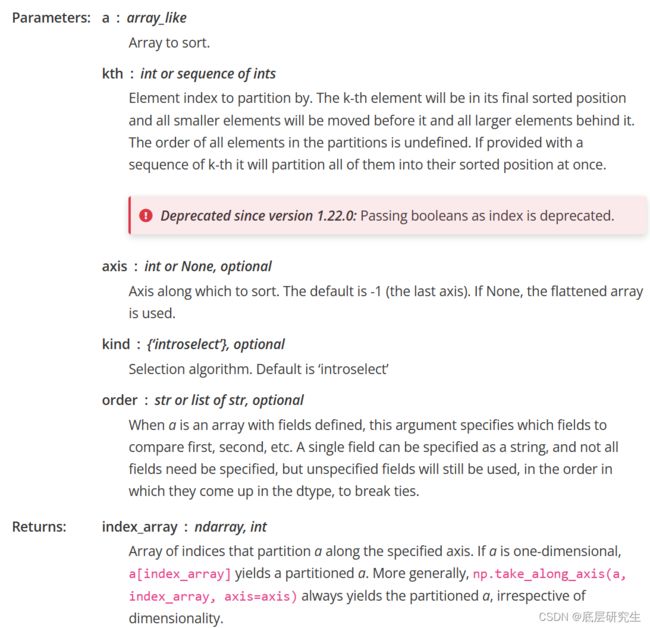
Input:a[array_like],很简单,代表我要对哪个array进行分区
kth:[int or int sequence]。比如kth=1,说明我要找最小的一个数,那么函数的返回值是最小的元素的索引;比如kth=3,那么函数的返回值是最小的3个元素的索引;kth=-2,说明函数的返回值是最大的2个元素的索引。
axis:维度,代表我要根据哪个维度进行分区,默认为-1,代表array的最后一个维度
kind:这是一个可选参数,默认为introselect,可以不用管,因为选项只有一个
order:是一个可选参数,用到的情况很少,这里不做解释
哦?看到这里,是不是对argpartition函数有一点感觉了,大致意思跟快速排序有点相似,但是argpartition函数返回的是索引,先选择好一个基准(kth决定),然后根据指定的维度(axis决定)对输入进行分区操作,所有小的数(序列a)放在前面,所有大的数(序列b)放在后面,然后返回新数组的索引。值得注意的是,序列a和序列b内部的顺序,我们是不予关注的,我们关注的是如何快速的找到最大或最小的几个数。
下面,我们通过多个案例理解argpartition函数的魔力。
3.案例分析
3.1 案例1-找出最小的三个元素
import numpy as np
x = np.array([5,6,1,2,4,-2,3])
print('Input array:',x)
y_index = np.argpartition(x, kth=3) # 找出最小的三个元素,返回与输入相同size的array
print('Output:',x[y_index][:3]) # 取出最小的三个元素的值

3.2 案例2-找出倒数第2、倒数第3和倒数第4小的元素
import numpy as np
x = np.array([5,6,1,2,4,-2,3])
print('Input array:',x)
y_index = np.argpartition(x, kth=(1,4)) # 找出最小的三个元素,返回与输入相同size的array
print('Output:',x[y_index][1:4]) # 取出最小的三个元素的值

3.3 案例3-多维数据
import numpy as np
x = np.array([[5,6,1],[1,2,3]])
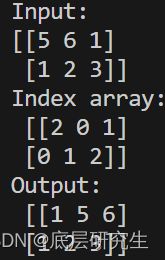
print('Input:\n{}'.format(x))
y_index_0 = np.argpartition(x, kth=1, axis=0)
print('Index array:\n',y_index_0)
y = np.take_along_axis(x, y_index_0, axis=0)
print('Output:\n', y)

3.4 案例4-多维数据
import numpy as np
x = np.array([[5,6,1],[1,2,3]])
print('Input:\n{}'.format(x))
y_index_1 = np.argpartition(x, kth=1, axis=1)
print('Index array:\n',y_index_1)
y = np.take_along_axis(x, y_index_1, axis=1)
print('Output:\n', y)
3.5 案例5-实际应用
以下摘自参考资料[3],该博主的解析十分浅显易懂,相信聪明的你们结合这2篇博客,定能将np.partition函数搞懂!


import numpy as np
import pandas as pd
from tqdm import tqdm
# generate sample data
n_features = 13426
n_disease = 425
features = [f"feature_{i}" for i in range(n_features)]
disease = [f"disease_{i}" for i in range(n_disease)]
weights = np.random.random((n_disease, n_features))
#function
def getdata(top_k: int) -> pd.DataFrame:
index = np.argpartition(weights, -top_k, axis=1)[:, -top_k:]
def slice_data(i):
temp_data = pd.DataFrame({
'features': np.array(features)[index[i, :]]})
temp_data['disease'] = disease[i]
temp_data['weights'] = weights[i, index[i, :]]
return temp_data
res = pd.concat([slice_data(i) for i in tqdm(range(weights.shape[0]))]).reset_index(drop=True)
return res
final_data = getdata(top_k=3) # 这里只是找top3的,要是想找top10的,修改数值就行了
final_data.shape
final_data.head(4)

参考资料
[1]https://numpy.org/doc/stable/reference/generated/numpy.argpartition.html
[2]https://www.geeksforgeeks.org/numpy-argpartition-in-python/
[3]https://zhuanlan.zhihu.com/p/546886845