黄仁勋:英伟达豪赌GPU终获回报,但我更看好高性能计算

黄仁勋日前在全球超算领域年度盛会SC18发表演讲,展望高性能及通用计算的未来。除了深度学习突飞猛进,Nvidia的GPU在超算、云平台等高性能计算领域发挥着举足轻重的作用。黄仁勋表示,Nvidia最好的产品还没有到来,未来计算的重任就交给GPU来抗。
11月11日~16日,2018年全球超算领域年度盛会、全球超级计算大会(SC18)在美国得克萨斯州达拉斯召开。昨天,Nvidia CEO黄仁勋发表了主旨演讲,简单说,就是未来计算的大旗放心交给英伟达来抗。
老黄在演讲中使用了数据图表、产品图片、甚至是超新星的精美画面,描述了加速器和人工智能驱动的计算转换,包括多精度处理器、新兴软件工具、垂直堆栈和容器等,当然还有Nvidia的产品,这些都将推动未来高性能计算的发展。

其实他在演讲中说的大多数挑战和解决方案大家都不陌生,不过我们可以理解他表现出的热情。因为GPU(或者更具体地说,是Nvidia 的GPU和CUDA),一直是HPC用以应对摩尔定律崩溃的关键手段。
最近,基于加速器的异构架构的不断兴起,这在世界超级计算机Top 500榜单上表现得很明显。在最新的榜单上,有127台超级计算机系统中使用了Nvidia的产品,包括目前世界上运算速度最快的两台超级计算机Summit和Sierra。
同样,Nvidia对混合精度功能的支持,对于提升机器学习和深度学习性能至关重要,这在Nvidia在Volta100和T4 GPU上部署的Tensor Core技术中可见一斑。
无论是敏锐的远见也好,聪明的机会主义也罢,Nvidia对GPU的豪赌都取得了丰厚的回报。现在的GPU对传统的建模和仿真任务,以及新兴的数据驱动的AI任务的支持越来越广泛。
关于HPC和GPU如何协同工作还有很多事情需要解决,至少近期,基于加速器的异构系统可以作为两者共同的动力。黄仁勋将Nvidia作为先行者,进行了不拘一格的技术讨论,并宣布了一系列内容,包括HPC性能基准、产品对市场推动力、新合作伙伴的努力以及对开源的模式赞誉等。
世界超级计算机Top 500榜单中,Nvidia进步明显。现在,榜单中使用Nvidia GPU的系统数量同比增长了48%,是五年前的三倍。两台全球顶级超级计算机Summit(橡树岭国家实验室)和Sierra(劳伦斯利弗莫尔国家实验室)一共使用了超过40000个Nvidia V100 Tensor Core GPU。Top500榜单中的近一半计算力(702/1417 petaflops)来自加速系统。在10年前,榜单中根本没有出现加速系统。
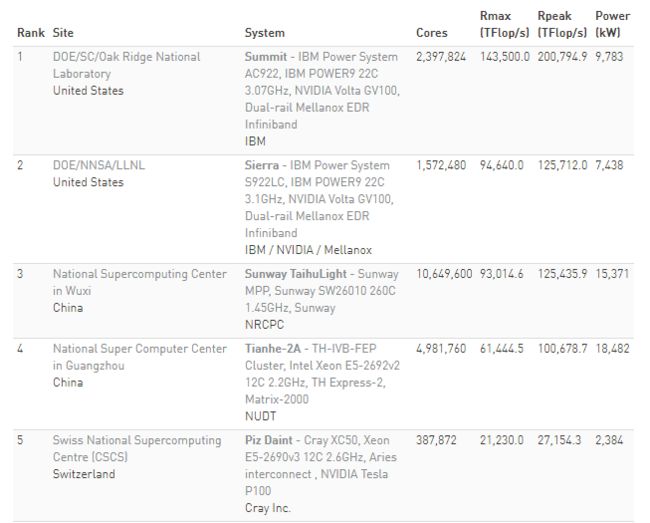
截至今年11月的最新超算Top 500榜单(前5名),中美各占两席
DGX-2为顶级实验室提供算力。黄仁勋表示,美国第一批Nvidia DGX-2 AI超级计算机已经运抵美国领先的一些研究实验室——布鲁克海文国家实验室、橡树岭国家实验室和桑迪亚国家实验室。DGX-2利用NVSwitch技术实现16个Nvidia TeslaV100 Tensor Core GPU的互联,提供了超过2 petaflop的算力。
在谷歌云上可以使用T4。据Nvidia发布的消息,新的T4 GPU推出后仅两个月,用即在57个独立的服务器设计中得到了应用,现在已经可以在云中使用,谷歌云平台首先可用于谷歌云平台的GPU。“我们有从未见过这么快就被数据中心采用的处理器,“Nvidia的加速计算副总裁兼总经理Ian Buck说。

容器业务扩展迅速。 Nvidia的NGC容器注册表现在提供41个框架和应用程序(去年为18个),用于深度学习,HPC及其可视化。最近增加的内容包括CHROMA,Matlab,MILC,ParaView,RAPIDS和VMD。
Nvidia发布了新的多节点HPC和可视化容器,允许超级计算用户在大规模集群上运行工作负载。此外,NGC容器现在可以在Singularity本地使用,Singularity是一种在超级计算中广泛采用的容器技术。
其他值得一提的亮点。 Nvidia GPU也为欧洲和日本最快的超级计算机提供加速服务。今天发布的Green 500排行榜测试了世界上最快系统的能效,榜单显示,前25个“最环保”的系统中,有22个系统使用Nvidia的GPU。
“对于Nvidia来说,这是超级计算领域的突破性的一年。”黄仁勋在发布会上表示,事实确实如此。
黄仁勋花了相当多的时间讨论Nvidia对其GPU生态系统的支持,他指出,CUDA版本的向后兼容性以及对一系列开源工具和框架的支持,对于Nvidia开发标准化垂直堆栈的努力至关重要。他说,这些堆栈将消灭大部分“苦差事”,并实现更广泛的各种AI功能。
同样值得一提的是T4在市场上的出色表现。 使用T4的服务器公司包括戴尔EMC,IBM,联想和超微。T4的功耗仅70瓦,可以灵活地适应标准服务器或任何面向开源计算项目的超大规模服务器设计。

服务器设计的适用范围从单个T4 GPU一直到单个节点中的20个GPU。 T4的多精度功能可提供四种不同精度级别的工作负载,FP32提供8.1 TFLOPS,FP16提供65TFLOPS,INT8提供130 TFLOPS,INT4提供260 TFLOPS。
在演讲的最后,黄仁勋激动地表示,英伟达最好的产品还没有到来。让我们拭目以待。
作为最早在云服务平台上应用Nvidia T4 GPU的企业,谷歌一直与Nvidia有着良好的合作关系。近日,谷歌的研究人员在 Medium上发布了一篇官方博文,题为《用XLA将GPU性能推向极限》(Pushing the limits of GPU performance with XLA)。
XLA 是 TensorFlow 图模型的编译器(complier),用于优化 TensorFlow 计算。虽然这篇博文中并未提到谷歌最新采用的英伟达T4 虚拟机,但很明显可以看出,谷歌在针对GPU做TensorFlow模型优化,未来也将如此。
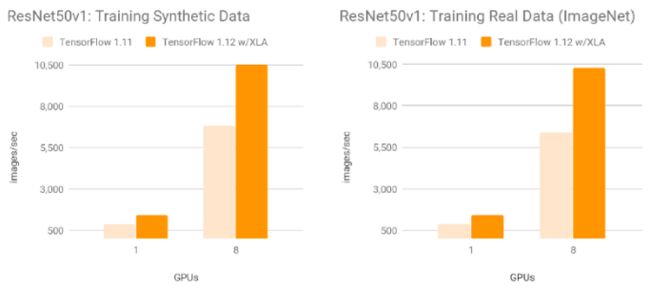
使用了XLA的TF1.12在英伟达Tesla V100GPU上训练ResNet-50,速度相比没有使用 XLA的TF1.11有了显著提升:合成数据为每秒10526幅图,真实数据为每秒10,267幅图。谷歌研究人员表示,他们观察到各种内部模型的加速最小的有1.13倍,最高的有3.04倍。
参考链接:
https://www.hpcwire.com/2018/11/14/nvidias-jensen-delivers-vision-for-the-new-hpc/
https://medium.com/tensorflow/pushing-the-limits-of-gpu-performance-with-xla-53559db8e473?linkId=59644343
来源:新智元
∞∞∞∞∞

公众号回复“IT派”,
邀你加入IT派 { 技术青年圈}