JVM虚拟机栈之操作数栈

上图时JVM虚拟机栈的栈帧的内部结构,本篇主要讲解操作数栈
一、概念:
(1)操作数栈,主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。
(2)操作数栈就是JVM执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧也会随之被创建出来,这个方法的操作数栈是空的。(操作数栈的实现是一个数组,当数组被创建出来的时候,它的长度已经确定,只不过操作数栈不能用索引来获取数据,它是一个栈结构,只有出栈和入栈操作).
(3)每一个操作数栈都会拥有一个明确的栈帧深度用来存储数值,其所需的最大深度在编译期就定义好了,保存在方法的code属性中,为max_stack的值。
如图:

javap 命令反编译后,stack=2 是操作数栈的最大栈深度,locals=3 是局部变量的长度。
和局部变量表一样在编译期间就可以确定长度。
(4)栈中的任何一个元素都是可以任意的java数据类型。
32bit的类型占用一个栈单位深度。
64bit的类型占用两个栈单位深度。
(5)操作数栈并非采用范文索引的方式来进行数据访问的,而是只能通过标准的入栈(push)和出栈(pop)操作来完成一次数据的访问。
(6) 如果被调用的方法带有返回值的化,其返回值将会被压入当前栈帧的操作数栈中,并更新pc寄存器中下一条需要执行的字节码指令。
如图:

使用jclasslib 分析:
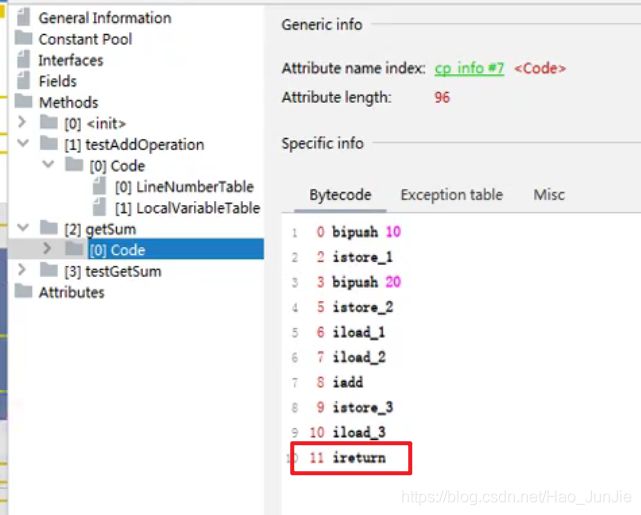
将int类型数据返回,getsum()栈帧出栈,

发下testGetSum当前栈帧,一上来就获取上一个栈帧的返回值,并保存在操作数栈中。
补充:我们所说的java虚拟机的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。
二、举例更加深入的了解操作数栈:
(1)编写代码:

都以int来保存,是以int保存到局部变量表中。并不是以int类型保存到操作数栈的入栈,还是以byte类型的操作数栈入栈。
(2)反编译后的字节码指令是:

(3)刚执行这个方法,虚拟机栈就会创建栈帧:

此时pc寄存器的值是0,局部变量表和操作数栈都是空的,但它们的长度已经确定。(操作数栈那个15可以忽略)
(4)然后执行引擎根据pc寄存器的值去执行操作指令:bipush
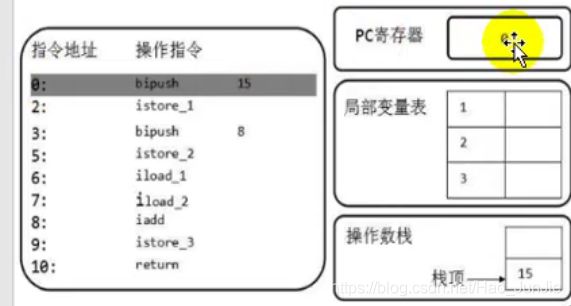
将15 存储到操作数栈中。
(5)执行引擎根据pc寄存器的值去执行操作指令istore_1

操作数栈的15 出栈,存入到局部变量表索引为1的slot中(因为索引为0的slot中存放的是this的引用)
(6)执行引擎根据pc寄存器的值去执行操作指令bipush

将8存放到操作数栈中。
(7)执行引擎根据pc寄存器的值去执行操作指令istore_2,将操作数栈中的8出栈,存放到局部变量表索引为2的slot中
(8)执行引擎根据pc寄存器的值去执行操作指令iload_1,
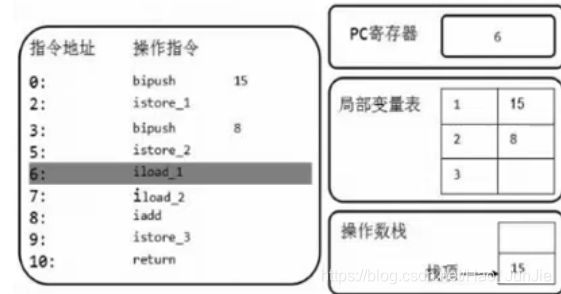
将局部变量表中索引为1的数值入栈到操作数栈中
(9)执行引擎根据pc寄存器的值去执行操作指令iload_2

将局部变量表中索引为2的数值入栈到操作数栈中。
(10)执行引擎根据pc寄存器的值去执行操作指令iadd,执行引擎执行指令,通过解释器解析成机器指令,调用cpu,将8和15依次出栈,将13入栈到操作数栈中。

(11)执行引擎根据pc寄存器的值去执行操作指令istore_3
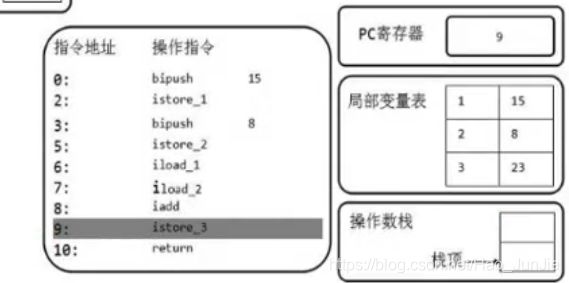
将操作数栈中的23出栈,存储到局部变量表所以为3的slot中。
(12)执行引擎根据pc寄存器的值去执行操作指令return,栈帧出栈。