腾讯云函数使用方法及注意事项
本人博客
https://blog.thatcoder.cn
本文以建立一个python推送课表为例
-
写好python文件
-
打包依赖
-
配置云函数
-
大功告成
-
写好python文件
def get_class(name, passwd):登入并获得课表网站数据
def findall(soundCode):将数据处理成answer数列
def msg(answer):判断当天有无课并推送
def strToBase64(s):按网站要求加密账号密码
def planB():爬取网站失败时启动备选方案
# -*- codeing = utf-8 -*-
# @TIME : 2021/5/15 3:56
# @Auther : 幼稚鬼(Naive)
# @what are you to do? : 九江职业技术学院课表推送
import base64
import linecache
import os
import re
import requests
from bs4 import BeautifulSoup
import pytz
import datetime
import pandas as pd
from pandas import DataFrame
pytz.country_timezones('cn')
tz = pytz.timezone('Asia/Shanghai')
rq = str(datetime.datetime.now(tz).strftime('%Y-%m-%d'))
xq = str(datetime.datetime.now(tz).isoweekday())
xq = int(xq)
cn = "" # 星期几
if xq == 7:
cn = "星期日"
elif xq == 1:
cn = "星期一"
elif xq == 2:
cn = "星期二"
elif xq == 3:
cn = "星期三"
elif xq == 4:
cn = "星期四"
elif xq == 5:
cn = "星期五"
elif xq == 6:
cn = "星期六"
def strToBase64(s):
strEncode = base64.b64encode(s.encode('utf8'))
return str(strEncode, encoding='utf8')
def get_class(name, passwd):
encoded = strToBase64(name) + '%%%' + strToBase64(passwd) # 自己在线转换base4 name+%%%+passwd
param = { # 提交的表单
'userAccount': name,
'userPassword': passwd,
'encoded': encoded # base64加密后的字符串
}
head = { # 请求头
"rq": rq,
"Cookie": "application/x-www-form-urlencoded; charset=UTF-8",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",
"Referer": "https://www.baidu.com/",
"accept-encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "max-age=0",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
session = requests.session() # 使用session保持在线
jsess = session.post(url="http://jiaowu.jvtc.jx.cn/jsxsd/xk/LoginToXk", params=param, headers=head) # 发送请求
if jsess.status_code == 200: # 验证是否链接成功
print("链接成功!")
else:
print("链接失败!")
calls("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切")
wx("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切")
planB()
param2 = { # 获得课表jsp页面的表单
"Referer": "http://jiaowu.jvtc.jx.cn/jsxsd/framework/xsMain_new.jsp?t1=1", # 来自主页面的跳转
"rq": rq
}
r = session.post("http://jiaowu.jvtc.jx.cn/jsxsd/framework/main_index_loadkb.jsp", params=param2) # 提交课表时间请求,返回本周课表
soundCode = r.text
# all=session.post('http://jiaowu.jvtc.jx.cn/jsxsd/xskb/xskb_list.do') #全课表,真心分析不动
findall(soundCode)
def findall(soundCode):
demand = BeautifulSoup(soundCode, 'lxml')
if len(demand.select('title')) != 0:
if str(demand.title.string) == '登录': # str(demand.title.string)验证是否还在登入页面,因为强智系统还是出问题 若还在则结束推送
print("链接成功,当依然在登入页面!")
calls("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切切")
wx("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切切")
planB()
else:
print("len(demand.select('title')) != 0 的未知错误,请处理!")
calls("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切切切")
wx("\n有内鬼,停止交易!\n\n服务器都炸了你还在这里吟诗作对,切切切")
planB()
else:
print("进入主页成功,等待加载 * * * * * * ")
week = re.findall('上课时间:第(.*?)周 星期', str(soundCode))[0]
fo = open("log.txt", "w+") # log.txt 第一行记载本周周数与最后更新时间
fo.write(week + "\n" + rq)
fo.close()
axq = ['星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日']
answer = [['星期一', []], ['星期二', []], ['星期三', []], ['星期四', []], ['星期五', []], ['星期六', []], ['星期日', []]]
list = demand.select('p') # 本周有的课都在标签里
answerindex = 0
for i in axq:
for li in list:
string1 = str(li)
stringclass = ''
if string1.find(i) != -1: # 查看p.string是否包含今天的星期数cn
namestart = re.findall("\[(.*?)\]节<", string1) # 匹配第几节
j = str(namestart[0])
if j == '01-02':
j = "第一大节"
elif j == '03-04':
j = "第二大节"
elif j == '05-06':
j = "第三大节"
elif j == '07-08':
j = "第四大节"
elif j == '09-10':
j = "第五大节"
elif j == '11-12':
j = "第六大节"
stringclass += j
namestart = re.findall("课程名称:(.*?)<br/>", string1) # 匹配课程名称
stringclass += "\n" + namestart[0]
namestart = re.findall("上课地点:(.*?)\">", string1) # 匹配上课地点
stringclass += "\n" + namestart[0]
if stringclass != '':
answer[answerindex][1].append(stringclass) # 把一节课的数据存入answer
answerindex += 1
# print(answer)
msg(answer)
answer[6][1].append(None)
answer[6][1].append(None)
answer[6][1].append(None)
answer[6][1].append(None)
answer[6][1].append(None)
answer[6][1].append(None)
toexcl(answer, week)
def msg(answer): # 遍历answer进行QQ推送
if len(answer[int(xq) - 1][1]) == 0: # 无课判断
print("休息日 无课\n\n业精于勤,荒于嬉;行成于思,毁于随——韩愈")
calls("\n休息日 无课\n\n业精于勤,荒于嬉;行成于思,毁于随——韩愈")
wx("\n休息日 无课\n\n业精于勤,荒于嬉;行成于思,毁于随——韩愈")
else:
lifeline = ""
for i in answer[int(xq) - 1][1]:
lifeline += '\n' + str(i) + '\n'
print(lifeline)
wx(lifeline)
calls(lifeline)
# 到这开始存csv
def calls(strs): # qq推送
pass
# print("qq:",strs)
qqone = 'qmsg酱的sky'
requests.get(qqone)
print("QQ推送成功")
def wx(strs): # 微信企业推送
# print("wx:", strs)
urlwxqy = "server酱的链接"
parmwxqy = {
'title': rq + ' ' + cn,
'desp': strs,
'openid': 'YouZhiGui'
}
requests.post(url=urlwxqy, params=parmwxqy)
print("企业微信推送成功")
def planB():
print("开始执行方案B")
week = linecache.getline(r'log.txt', 1)
if len(week) == 3:
week = week[0:2]
elif len(week) == 2:
week = week[0:1]
lastdate = linecache.getline(r'log.txt', 2)[0:10]
path = r'第{}周课表.csv'.format(week)
if os.path.exists(path):
pass
else:
path = r'第{}周课表.csv'.format(int(week) - 1)
if os.path.exists(path):
pass
else:
strs = "\n无历史课表\n\n生而为人,我很抱歉\n"
print(strs)
calls(strs)
wx(strs)
exit(0)
pdarry = pd.read_csv(r'第{}周课表.csv'.format(week))
list1 = pdarry[str(xq)].values
strs = '\n执行方案B\n数据来源:{}\n\n'.format(lastdate)
for i in list1:
if str(i) == '芜湖':
i = ''
strs += str(i)
if strs == '\n执行方案B\n数据来源:{}\n\n'.format(lastdate):
strs += "休息日 无课\n\n业精于勤,荒于嬉;行成于思,毁于随——韩愈\n"
strs += "\n历史课表,仅供参考!!!"
print(strs)
calls(strs)
wx(strs)
print("执行方案B成功")
def toexcl(anwser, week): # 存csv
print("开始执行存csv")
data = [anwser[0][1], anwser[1][1], anwser[2][1], anwser[3][1], anwser[4][1], anwser[5][1], anwser[6][1]]
pdarrays = DataFrame(data, index=[1, 2, 3, 4, 5, 6, 7], columns=['第一大节', '第二大节', '第三大节', '第四大节', '第五大节', '第六大节'],
dtype=str)
pdarrays2 = pdarrays.fillna('芜湖') # 查找空数据
pdarrays3 = pdarrays2.T # 行列数据转置
pdarrays3.to_csv(r'第{}周课表.csv'.format(week))
print("存入csv成功")
def go(arg1,arg2):
get_class('账号','密码')
-
打包依赖
强烈建议在linux下执行
写好代码后在pycharm终端或cmd命令符到项目地址开始打包依赖,因为在腾讯云函数的依赖较少,需要自行上传
因为我使用到 beautifulsoup4 库 ,所以代码1行下载beautifulsoup4库到项目文件夹的text下,并自己把py文件放入text下
pip3 install lxml beautifulsoup4 -t text/
cd text
pip freeze > requirements.txt
pip install -r requirements.txt
zip text.zip * -r
强烈建议在linux环境下执行2步操作,因为window下容易编码不一致导致云函数极易报错
运行完结果如下
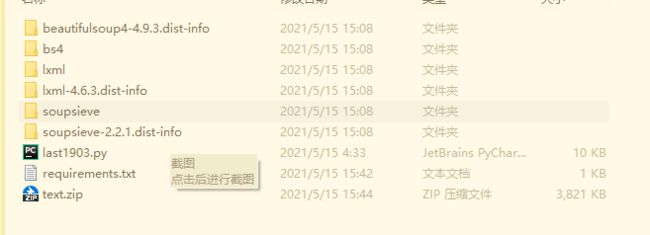
-
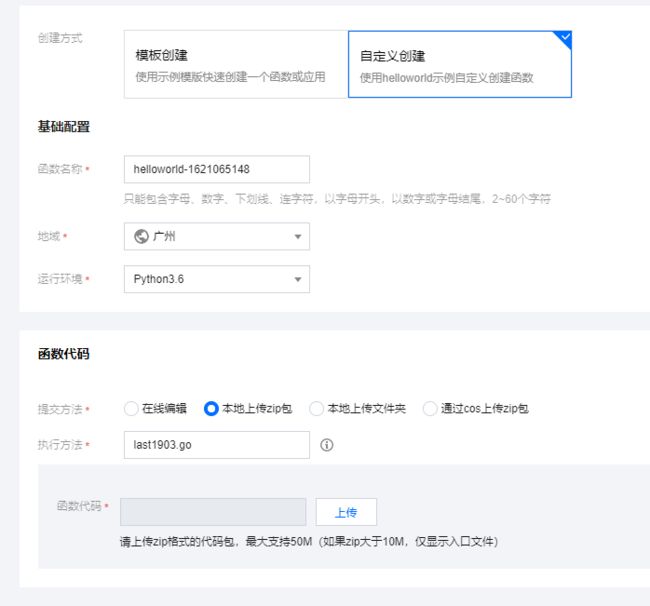
配置云函数信息
登入云函数 函数服务-新建

创建方式 : 自定义创建
函数代码:
提交方法 : 本地上传zip包 (就是传2步打包好的text.zip)
执行方法 : py文件名.主方法入口 (主方法入口必须有两个形式参数,即使用不上,具体参考我py代码 222 行的 def go(arg1,arg2): 方法,所以我这里执行方法是 last1903.go )
触发器配置 :
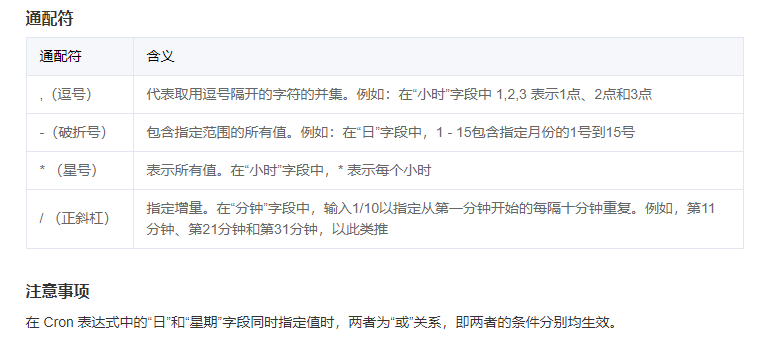
触发周期 : 自定义
Cron表达式 : 参考相关文档 --->云函数 定时触发器 - 开发指南 - 文档中心 - 腾讯云 (tencent.com)

触发器表达式参考 :

-
大功告成
点击 部署 并自己 测试 一下
特别鸣谢参考
略略略—— 腾讯云scf云函数,python依赖安装与上传的正确姿势 - 略略略—— - 博客园 (cnblogs.com)
Sharp 实战腾讯云云函数最简单部署包含第三方依赖的Python项目 - SharpG.的博客 (Sharpgan.Com)