【强化学习】15 —— TRPO(Trust Region Policy Optimization)
文章目录
- 前言
- TRPO特点
- 策略梯度的优化目标
- 使用重要性采样
- 忽略状态分布的差异
- 约束策略的变化
- 近似求解
- 线性搜索
- 算法伪代码
- 广义优势估计
- 代码实践
-
- 离散动作空间
- 连续动作空间
- 参考
前言
之前介绍的基于策略的方法包括策略梯度算法和 Actor-Critic 算法。这些方法虽然简单、直观,但在实际应用过程中会遇到训练不稳定的情况。回顾一下基于策略的方法:参数化智能体的策略,并设计衡量策略好坏的目标函数,通过梯度上升的方法来最大化这个目标函数,使得策略最优。这种算法有一个明显的缺点:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果;同时由于采集到的数据的分布会随策略的更新而变化,步长太长,更新的策略可能变差,导致采集到的数据变差,进而陷入恶性循环之中。本文将要介绍的信任区域策略优化(trust region policy optimization,TRPO)算法,在理论上能够保证策略学习的性能单调性,并在实际应用中取得了比策略梯度算法更好的效果。
TRPO特点
- 是一种on-policy的算法
- 可以用于连续或离散的动作空间
- Open AI Spinning Up 中的TRPO可以达到并行运行的效果
- TRPO以一种on-policy的方式训练了一个随机策略。这意味着它通过根据其随机策略的最新版本进行动作采样来进行探索。动作选择中的随机量取决于初始条件和训练过程。在训练过程中,策略通常会逐渐变得不那么随机,因为更新规则鼓励它利用已经发现的奖励。这可能导致策略陷入局部最优。
策略梯度的优化目标
假设当前策略为 π θ \pi_\theta πθ,其参数为 θ \theta θ。对于策略梯度的优化目标,我们可以将其写成累计的折扣回报 J ( θ ) = E τ ∼ p θ ( τ ) [ ∑ t γ t r ( s t , a t ) ] J(\theta)=\mathbb{E}_{\tau\sim p_\theta(\tau)}[\sum_t\gamma^tr(s_t,a_t)] J(θ)=Eτ∼pθ(τ)[∑tγtr(st,at)],基于轨迹 τ \tau τ,我们可以采样到累计的折扣回报。同时,因为 V π θ ( s ) V^{\pi_\theta}(s) Vπθ(s)相应的期望可以写成累计折扣回报的形式, V π θ ( s ) = E a ∼ π θ ( s ) [ Q π θ ( s , a ) ] = E a ∼ π θ ( s ) [ E τ ∼ p θ ( τ ) [ ∑ s k = s , a k = a ∑ t = k ∞ γ t − k r ( s t , a t ) ] ] V^{\pi_\theta}(s)=\mathbb{E}_{a\sim\pi_\theta(s)}[Q^{\pi_\theta}(s,a)]=\mathbb{E}_{a\sim\pi_\theta(s)}[\mathbb{E}_{\tau\sim p_\theta(\tau)}[\sum_{s_k=s,a_k=a}\sum_{t=k}^{\infty}\gamma^{t-k}r(s_t,a_t)]] Vπθ(s)=Ea∼πθ(s)[Qπθ(s,a)]=Ea∼πθ(s)[Eτ∼pθ(τ)[∑sk=s,ak=a∑t=k∞γt−kr(st,at)]],所以我们可以得到第二种优化目标(基于起始点的形式): J ( θ ) = E s 0 ∼ p θ ( s 0 ) [ V π θ ( s 0 ) ] J(\theta)=\mathbb{E}_{s_0\sim p_{\theta}(s_0)}[V^{\pi_\theta}(s_0)] J(θ)=Es0∼pθ(s0)[Vπθ(s0)]。两者是等效的。
在策略优化中,我们考虑如何借助当前的 θ \theta θ找到一个更优的参数 θ ′ \theta' θ′,使得 J ( θ ′ ) ≥ J ( θ ) J(\theta')\ge J(\theta) J(θ′)≥J(θ)。由于初始状态 s 0 s_0 s0的分布和策略无关(与起始的环境相关),因此上述策略下的优化目标 J ( θ ) J(\theta) J(θ)可以写成在新策略 π θ ′ \pi_{\theta'} πθ′的期望形式: J ( θ ) = E s 0 [ V π θ ( s 0 ) ] = E π θ ′ [ ∑ t = 0 ∞ γ t V π θ ( s t ) − ∑ t = 1 ∞ γ t V π θ ( s t ) ] = − E π θ ′ [ ∑ t = 0 ∞ γ t ( γ V π θ ( s t + 1 ) − V π θ ( s t ) ) ] \begin{aligned} J(\theta)& =\mathbb{E}_{s_0}[V^{\pi_\theta}(s_0)] \\ &=\mathbb{E}_{\pi_{\theta^{\prime}}}\left[\sum_{t=0}^\infty\gamma^tV^{\pi_\theta}(s_t)-\sum_{t=1}^\infty\gamma^tV^{\pi_\theta}(s_t)\right] \\ &=-\mathbb{E}_{\pi_{\theta'}}\left[\sum_{t=0}^{\infty}\gamma^{t}\left(\gamma V^{\pi_{\theta}}(s_{t+1})-V^{\pi_{\theta}}(s_{t})\right)\right] \end{aligned} J(θ)=Es0[Vπθ(s0)]=Eπθ′[t=0∑∞γtVπθ(st)−t=1∑∞γtVπθ(st)]=−Eπθ′[t=0∑∞γt(γVπθ(st+1)−Vπθ(st))]
基于以上等式,我们可以推导新旧策略的目标函数之间的差距: J ( θ ′ ) − J ( θ ) = E s 0 [ V π θ ′ ( s 0 ) ] − E s 0 [ V π θ ( s 0 ) ] = E π θ ′ [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] + E π θ ′ [ ∑ t = 0 ∞ γ t ( γ V π θ ( s t + 1 ) − V π θ ( s t ) ) ] = E π θ ′ [ ∑ t = 0 ∞ γ t [ r ( s t , a t ) + γ V π θ ( s t + 1 ) − V π θ ( s t ) ] ] \begin{aligned} J(\theta')-J(\theta)& =\mathbb{E}_{s_0}\left[V^{\pi_{\theta'}}(s_0)\right]-\mathbb{E}_{s_0}\left[V^{\pi_\theta}(s_0)\right] \\ &=\mathbb{E}_{\pi_{\theta^{\prime}}}\left[\sum_{t=0}^\infty\gamma^tr(s_t,a_t)\right]+\mathbb{E}_{\pi_{\theta^{\prime}}}\left[\sum_{t=0}^\infty\gamma^t\left(\gamma V^{\pi_\theta}(s_{t+1})-V^{\pi_\theta}(s_t)\right)\right] \\ &=\mathbb{E}_{\pi_{\theta'}}\left[\sum_{t=0}^{\infty}\textcolor{red}{\gamma^{t}\left[r(s_{t},a_{t})+\gamma V^{\pi_{\theta}}(s_{t+1})-V^{\pi_{\theta}}(s_{t})\right]}\right] \end{aligned} J(θ′)−J(θ)=Es0[Vπθ′(s0)]−Es0[Vπθ(s0)]=Eπθ′[t=0∑∞γtr(st,at)]+Eπθ′[t=0∑∞γt(γVπθ(st+1)−Vπθ(st))]=Eπθ′[t=0∑∞γt[r(st,at)+γVπθ(st+1)−Vπθ(st)]]
很自然的,红色标注的部分和我们之前介绍过的优势函数形式一致,因此,等式可以变为: = E π θ ′ [ ∑ t = 0 ∞ γ t A π θ ( s t , a t ) ] =\mathbb{E}_{\textcolor{blue}{\pi_{\theta^{\prime}}}}\left[\sum_{t=0}^\infty\gamma^tA^{\textcolor{red}{\pi_\theta}}(s_t,a_t)\right] =Eπθ′[t=0∑∞γtAπθ(st,at)]
使用重要性采样
直接对上式进行采样是困难的,因为 π θ ′ \pi_{\theta^{\prime}} πθ′是我们需要求解的策略,但我们又要用它来收集样本。把所有可能的新策略都拿来收集数据,然后判断哪个策略满足上述条件的做法显然是不现实的。因此,我们需要用到重要性采样(Importance Sampling)。 J ( θ ′ ) − J ( θ ) = E τ ∼ p θ ′ ( τ ) [ ∑ t = 0 ∞ γ t A π θ ( s t , a t ) ] \begin{aligned}&J(\theta^{\prime})-J(\theta)\\&=\mathbb{E}_{\tau\sim p_{\theta^{\prime}}(\tau)}\left[\sum_{t=0}^\infty\gamma^tA^{\pi_\theta}(s_t,a_t)\right]\end{aligned} J(θ′)−J(θ)=Eτ∼pθ′(τ)[t=0∑∞γtAπθ(st,at)]
E τ ∼ p θ ′ ( τ ) \mathbb{E}_{\tau\sim p_{\theta^{\prime}}(\tau)} Eτ∼pθ′(τ)可以拆分成先采样出状态 s t s_t st,再基于 π θ ′ \pi_{\theta'} πθ′采样出动作 a t a_t at,于是有:
= ∑ t E s t ∼ p θ ′ ( s t ) [ E a t ∼ π θ ′ ( a t ∣ s t ) [ γ t A π θ ( s t , a t ) ] ] =\sum_t\mathbb{E}_{s_t\sim p_{\theta^{\prime}}(s_t)}[\mathbb{E}_{a_t\sim\pi_{\theta^{\prime}}(a_t|s_t)}[\gamma^tA^{\pi_\theta}(s_t,a_t)]] =t∑Est∼pθ′(st)[Eat∼πθ′(at∣st)[γtAπθ(st,at)]]
再利用重要性采样的方法,可得
= ∑ t E s t ∼ p θ ′ ( s t ) [ E a t ∼ π θ ( a t ∣ s t ) [ π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) γ t A π θ ( s t , a t ) ] ] =\sum_t\mathbb{E}_{s_t\sim p_{\theta^{\prime}}(s_t)}[\mathbb{E}_{a_t\sim\pi_\theta(a_t|s_t)}[\frac{\pi_{\theta^{\prime}}(a_t|s_t)}{\pi_\theta(a_t|s_t)}\gamma^tA^{\pi_\theta}(s_t,a_t)]] =t∑Est∼pθ′(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]
忽略状态分布的差异
不过,此时前面依然是 E s t ∼ p θ ′ ( s t ) \mathbb{E}_{s_t\sim p_{\theta^{\prime}}(s_t)} Est∼pθ′(st), s t s_t st需要基于 π θ ′ \pi_{\theta'} πθ′进行采样。对此,TRPO忽略状态分布的差异.当策略更新前后的变化较小时,可以近似地令 π θ ( s t ) ≈ π θ ′ ( s t ) \pi_{\theta}(s_t)\approx\pi_{\theta'}(s_t) πθ(st)≈πθ′(st)。现在,假设使用确定性策略,且当 π θ ′ ( s t ) ≠ π θ ( s t ) \pi_{\theta^{\prime}}(s_t)\neq\pi_\theta\mathrm{~(s_t)} πθ′(st)=πθ (st)的概率小于时;或者假设使用随机性策略,且当 a ′ ∼ π θ ′ ( ⋅ ∣ s t ) ≠ a ∼ π θ ( ⋅ ∣ s t ) a^{\prime}{\sim}\pi_{\theta^{\prime}}(\cdot|s_t)\neq a{\sim}\pi_\theta(\cdot|s_t) a′∼πθ′(⋅∣st)=a∼πθ(⋅∣st)的概率小于时,则新策略可以由与旧策略相等的部分和不相等的部分之和组成: p θ ′ ( s t ) = ( 1 − ϵ ) t p θ ( s t ) + ( 1 − ( 1 − ϵ ) t ) p m i s t a k e ( s t ) p_{\theta'}(s_t)=(1-\epsilon)^tp_\theta(s_t)+(1-(1-\epsilon)^t)p_{mistake}(s_t) pθ′(st)=(1−ϵ)tpθ(st)+(1−(1−ϵ)t)pmistake(st)
移项可得,
∣ p θ ′ ( s t ) − p θ ( s t ) ∣ = ( 1 − ( 1 − ϵ ) t ) ∣ p m i s t a k e ( s t ) − p θ ( s t ) ∣ ≤ 2 ( 1 − ( 1 − ϵ ) t ) ≤ 2 ϵ t \begin{aligned}|p_{\theta^{\prime}}(s_t)-p_\theta(s_t)|&=(1-(1-\epsilon)^t)|p_{mistake}(s_t)-p_\theta(s_t)|\\ &\leq2(1-(1-\epsilon)^t)\\&\leq2\epsilon t\end{aligned} ∣pθ′(st)−pθ(st)∣=(1−(1−ϵ)t)∣pmistake(st)−pθ(st)∣≤2(1−(1−ϵ)t)≤2ϵt
⚠️You Should Know
1. ∣ p m i s t a k e ( s t ) − p θ ( s t ) ∣ ≤ 2 |p_{mistake}(s_t)-p_\theta(s_t)| \leq2 ∣pmistake(st)−pθ(st)∣≤2,概率上下差值最大为2
2. ( 1 − ϵ ) t ≥ 1 − ϵ t f o r ϵ ∈ [ 0 , 1 ] (1-\epsilon)^t\geq1-\epsilon t\mathrm{~for~}\epsilon\in[0,1] (1−ϵ)t≥1−ϵt for ϵ∈[0,1]泰勒展开
最后,我们可以让 π θ ( s t ) ≈ π θ ′ ( s t ) \pi_{\theta}(s_t)\approx\pi_{\theta'}(s_t) πθ(st)≈πθ′(st) J ( θ ′ ) − J ( θ ) ≈ ∑ t E s t ∼ p θ ( s t ) [ E a t ∼ π θ ( a t ∣ s t ) [ π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) γ t A π θ ( s t , a t ) ] ] J(\theta^{\prime})-J(\theta)\approx\sum_t\mathbb{E}_{s_t\sim p_\theta(s_t)}[\mathbb{E}_{a_t\sim\pi_\theta(a_t|s_t)}[\frac{\pi_{\theta^{\prime}}(a_t|s_t)}{\pi_\theta(a_t|s_t)}\gamma^tA^{\pi_\theta}(s_t,a_t)]] J(θ′)−J(θ)≈t∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]
约束策略的变化
为了保证新旧策略足够接近,TRPO 使用了库尔贝克-莱布勒(Kullback-Leibler,KL)散度来约束策略更新的幅度。 θ ′ ← arg max θ ′ ∑ t E s t ∼ p θ ( s t ) [ E a t ∼ π θ ( a t ∣ s t ) [ π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) γ t A π θ ( s t , a t ) ] ] s u c h t h a t E s t ∼ p ( s t ) [ D K L ( π θ ′ ( a t ∣ s t ) ∥ π θ ( a t ∣ s t ) ) ] ≤ ϵ \begin{aligned} &\theta'\leftarrow\arg\max_{\theta'}\sum_t\mathbb{E}_{s_t\sim p_\theta(s_t)}[\mathbb{E}_{a_t\sim\pi_\theta(a_t|s_t)}[\frac{\pi_{\theta'}(a_t|s_t)}{\pi_\theta(a_t|s_t)}\gamma^tA^{\pi_\theta}(s_t,a_t)]] \\ &\mathrm{such~that~}\mathbb{E}_{s_t\sim p(s_t)}[D_{KL}(\pi_{\theta^{\prime}}(a_t|s_t)\parallel\pi_\theta(a_t|s_t))]\leq\epsilon \end{aligned} θ′←argθ′maxt∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]such that Est∼p(st)[DKL(πθ′(at∣st)∥πθ(at∣st))]≤ϵ
⚠️You Should Know
1.当 θ = θ ′ \theta=\theta' θ=θ′时,上述目标函数以及其约束都为0;此外,当 θ = θ ′ \theta=\theta' θ=θ′时,约束对 θ \theta θ的梯度也为0.
2.实际多使用constraint violate as penalty进行求解 θ ′ ← arg max θ ′ ∑ t E s t ∼ p θ ( s t ) [ E a t ∼ π θ ( a t ∣ s t ) [ π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) γ t A π θ ( s t , a t ) ] ] − λ ( D K L ( π θ ′ ( a t ∣ s t ) ∥ π θ ( a t ∣ s t ) ) − ϵ ) \begin{aligned}\theta'\leftarrow\arg\max_{\theta'}\sum_t\mathbb{E}_{s_t\sim p_\theta(s_t)}[\mathbb{E}_{a_t\sim\pi_\theta(a_t|s_t)}[\frac{\pi_{\theta'}(a_t|s_t)}{\pi_\theta(a_t|s_t)}\gamma^tA^{\pi_\theta}(s_t,a_t)]]\\-\lambda(D_{KL}(\pi_{\theta'}(a_t|s_t)\parallel\pi_\theta(a_t|s_t))-\epsilon)\end{aligned} θ′←argθ′maxt∑Est∼pθ(st)[Eat∼πθ(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]−λ(DKL(πθ′(at∣st)∥πθ(at∣st))−ϵ)
2.1优化上式,更新 θ ′ \theta' θ′
2.2更新惩罚项 λ ← λ + α ( D K L ( π θ ′ ( a t ∣ s t ) ∥ π θ ( a t ∣ s t ) ) − ϵ ) \lambda\leftarrow\lambda+\alpha(D_{KL}(\pi_{\theta^{\prime}}(a_{t}|s_{t})\parallel\pi_{\theta}(a_{t}|s_{t}))-\epsilon) λ←λ+α(DKL(πθ′(at∣st)∥πθ(at∣st))−ϵ)(若KL散度超出 ϵ \epsilon ϵ,则进行惩罚,超出越多,惩罚越多)
近似求解
上述式子的求解还是比较困难的,因此,TRPO进行了近似求解。为了方便描述,我们将目标函数和约束转化为以下形式: θ k + 1 = arg max θ L ( θ k , θ ) s . t . D ˉ K L ( θ ∣ ∣ θ k ) ≤ δ \begin{aligned}\theta_{k+1}=\arg\max_{\theta}\mathcal{L}(\theta_k,\theta)\\\mathrm{s.t.~}\bar{D}_{KL}(\theta||\theta_k)\le\delta\end{aligned} θk+1=argθmaxL(θk,θ)s.t. DˉKL(θ∣∣θk)≤δ
其中, L ( θ k , θ ) = E s , a ∼ π θ k [ π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) ] , \mathcal{L}(\theta_k,\theta)=\underset{s,a\sim\pi_{\theta_k}}{\operatorname*{E}}\left[\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s,a)\right], L(θk,θ)=s,a∼πθkE[πθk(a∣s)πθ(a∣s)Aπθk(s,a)], D ˉ K L ( θ ∣ ∣ θ k ) = E s ∼ π θ k [ D K L ( π θ ( ⋅ ∣ s ) ∣ ∣ π θ k ( ⋅ ∣ s ) ) ] . \bar{D}_{KL}(\theta||\theta_{k})=\mathop{\mathrm{E}}_{s\sim\pi_{\theta_{k}}}\left[D_{KL}\left(\pi_{\theta}(\cdot|s)||\pi_{\theta_{k}}(\cdot|s))\right].\right. DˉKL(θ∣∣θk)=Es∼πθk[DKL(πθ(⋅∣s)∣∣πθk(⋅∣s))].
对其基于 θ k \theta_k θk进行泰勒展开: L ( θ k , θ ) ≈ g T ( θ − θ k ) D ˉ K L ( θ ∣ ∣ θ k ) ≈ 1 2 ( θ − θ k ) T H ( θ − θ k ) \begin{aligned} \mathcal{L}(\theta_{k},\theta)& \approx g^{T}(\theta-\theta_{k}) \\ \bar{D}_{KL}(\theta||\theta_{k})& \approx\frac12(\theta-\theta_k)^TH(\theta-\theta_k) \end{aligned} L(θk,θ)DˉKL(θ∣∣θk)≈gT(θ−θk)≈21(θ−θk)TH(θ−θk)
其中 g g g表示目标函数的梯度 ∇ θ J ( π θ ) \nabla_{\theta}J(\pi_{\theta}) ∇θJ(πθ), H H H表示策略之间平均 KL 距离的黑塞矩阵(Hessian matrix)。因此,我们可以将问题转化为一个近似的优化问题: θ k + 1 = arg max θ g T ( θ − θ k ) s.t. 1 2 ( θ − θ k ) T H ( θ − θ k ) ≤ δ . \begin{aligned}\theta_{k+1}=\arg\max_{\theta}g^T(\theta-\theta_k)\\\text{s.t. }\frac{1}{2}(\theta-\theta_k)^TH(\theta-\theta_k)\leq\delta.\end{aligned} θk+1=argθmaxgT(θ−θk)s.t. 21(θ−θk)TH(θ−θk)≤δ.
此时,我们可以用卡罗需-库恩-塔克(Karush-Kuhn-Tucker,KKT)条件直接导出上述问题的解:
θ k + 1 = θ k + 2 δ g T H − 1 g H − 1 g \theta_{k+1}=\theta_k+\sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θk+1=θk+gTH−1g2δH−1g
⚠️You Should Know
1.进一步的求解需要用到共轭梯度法(conjugate gradient method)或者拉格朗日对偶法(Lagrangian duality)。共轭梯度法(TRPO所用)的具体求解参考《动手学强化学习》第11.4节;拉格朗日对偶法(Lagrangian duality)则可参考Boyd的凸优化 —— Convex Optimization by Boyd and Vandenberghe, especially chapters 2 through 5.
2.一般来说,用神经网络表示的策略函数的参数数量都是成千上万的,计算和存储黑塞矩阵 H H H的逆矩阵会耗费大量的内存资源和时间。TRPO 通过共轭梯度法(conjugate gradient method)回避了这个问题,它的核心思想是直接计算 H x Hx Hx向量, ( x = H − 1 g ) (x=H^{-1}g) (x=H−1g) , x x x即参数更新方向,而非存储黑塞矩阵 H H H。公式描述如下: H x = ∇ θ ( ( ∇ θ D ˉ K L ( θ ∣ ∣ θ k ) ) T x ) , Hx=\nabla_{\theta}\left(\left(\nabla_{\theta}\bar{D}_{KL}(\theta||\theta_{k})\right)^{T}x\right), Hx=∇θ((∇θDˉKL(θ∣∣θk))Tx),
线性搜索
如果到此为止,计算出最终的结果,那么现在的算法和Natural Policy Gradient差不多。由于 TRPO 算法用到了泰勒展开的 1 阶和 2 阶近似,这并非精准求解,最终的策略结果并非能得到提升,并且未必能满足 KL 散度限制。因此,TRPO 在每次迭代的最后进行一次线性搜索(Line Search),以确保找到满足条件。具体来说,就是找到一个最小的非负整数 i i i,使得按照 θ k + 1 = θ k + α i 2 δ x T H x x \theta_{k+1}=\theta_k+\alpha^i\sqrt{\frac{2\delta}{x^THx}}x θk+1=θk+αixTHx2δx
其中 α ∈ ( 0 , 1 ) \alpha \in (0,1) α∈(0,1)是一个决定线性搜索长度的超参数。求出的 θ k + 1 \theta_{k+1} θk+1依然满足最初的 KL 散度限制,并且确实能够提升目标函数 L ( θ k , θ ) \mathcal{L}(\theta_k,\theta) L(θk,θ)。
算法伪代码


广义优势估计
现在,我们还缺少一种合适的方法用来估计优势函数 A A A。目前比较常用的一种方法为广义优势估计(Generalized Advantage Estimation,GAE),接下来我们简单介绍一下 GAE 的做法。首先,用 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t=r_t+\gamma V(s_{t+1})-V(s_t) δt=rt+γV(st+1)−V(st)表示时序差分误差,其中 V V V是一个已经学习的状态价值函数。于是,根据多步时序差分的思想,有: A t ( 1 ) = δ t = − V ( s t ) + r t + γ V ( s t + 1 ) A t ( 2 ) = δ t + γ δ t + 1 = − V ( s t ) + r t + γ r t + 1 + γ 2 V ( s t + 2 ) A t ( 3 ) = δ t + γ δ t + 1 + γ 2 δ t + 2 = − V ( s t ) + r t + γ r t + 1 + γ 2 r t + 2 + γ 3 V ( s t + 3 ) ⋮ ⋮ A t ( k ) = ∑ l = 0 k − 1 γ l δ t + l = − V ( s t ) + r t + γ r t + 1 + … + γ k − 1 r t + k − 1 + γ k V ( s t + k ) \begin{aligned} &A_{t}^{(1)}&& =\delta_{t} &&&& =-V(s_t)+r_t+\gamma V(s_{t+1}) \\ &A_{t}^{(2)}&& =\delta_t+\gamma\delta_{t+1} &&&& =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2V(s_{t+2}) \\ &A_t^{(3)}&& =\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2} &&&& =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+\gamma^3V(s_{t+3}) \\ &&\vdots&&&&\vdots\\ &A_t^{(k)}&& =\sum_{l=0}^{k-1}\gamma^l\delta_{t+l} &&&& =-V(s_t)+r_t+\gamma r_{t+1}+\ldots+\gamma^{k-1}r_{t+k-1}+\gamma^kV(s_{t+k}) \end{aligned} At(1)At(2)At(3)At(k)⋮=δt=δt+γδt+1=δt+γδt+1+γ2δt+2=l=0∑k−1γlδt+l⋮=−V(st)+rt+γV(st+1)=−V(st)+rt+γrt+1+γ2V(st+2)=−V(st)+rt+γrt+1+γ2rt+2+γ3V(st+3)=−V(st)+rt+γrt+1+…+γk−1rt+k−1+γkV(st+k)
然后,GAE 将这些不同步数的优势估计进行指数加权平均: A t G A E = ( 1 − λ ) ( A t ( 1 ) + λ A t ( 2 ) + λ 2 A t ( 3 ) + ⋯ ) = ( 1 − λ ) ( δ t + λ ( δ t + γ δ t + 1 ) + λ 2 ( δ t + γ δ t + 1 + γ 2 δ t + 2 ) + ⋯ ) = ( 1 − λ ) ( δ ( 1 + λ + λ 2 + ⋯ ) + γ δ t + 1 ( λ + λ 2 + λ 3 + ⋯ ) + γ = ( 1 − λ ) ( δ t 1 1 − λ + γ δ t + 1 λ 1 − λ + γ 2 δ t + 2 λ 2 1 − λ + ⋯ ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \begin{aligned} A_{t}^{GAE}& =(1-\lambda)(A_t^{(1)}+\lambda A_t^{(2)}+\lambda^2A_t^{(3)}+\cdots) \\ &=(1-\lambda)(\delta_t+\lambda(\delta_t+\gamma\delta_{t+1})+\lambda^2(\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2})+\cdots) \\ &=(1-\lambda)(\delta(1+\lambda+\lambda^2+\cdots)+\gamma\delta_{t+1}(\lambda+\lambda^2+\lambda^3+\cdots)+\gamma \\ &=(1-\lambda)\left(\delta_t\frac1{1-\lambda}+\gamma\delta_{t+1}\frac\lambda{1-\lambda}+\gamma^2\delta_{t+2}\frac{\lambda^2}{1-\lambda}+\cdots\right) \\ &=\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l} \end{aligned} AtGAE=(1−λ)(At(1)+λAt(2)+λ2At(3)+⋯)=(1−λ)(δt+λ(δt+γδt+1)+λ2(δt+γδt+1+γ2δt+2)+⋯)=(1−λ)(δ(1+λ+λ2+⋯)+γδt+1(λ+λ2+λ3+⋯)+γ=(1−λ)(δt1−λ1+γδt+11−λλ+γ2δt+21−λλ2+⋯)=l=0∑∞(γλ)lδt+l
其中, λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1]是在 GAE 中额外引入的一个超参数。当时 λ = 0 \lambda=0 λ=0, A t G A E = δ t = r t + γ V ( s t + 1 ) − V ( s t ) A_t^{GAE}=\delta_t=r_t+\gamma V(s_{t+1})-V(s_t) AtGAE=δt=rt+γV(st+1)−V(st),也即是仅仅只看一步差分得到的优势;当时 λ = 1 \lambda=1 λ=1, A t G A E = ∑ l = 0 ∞ γ l δ t + l = ∑ l = 0 ∞ γ l r t + l − V ( s t ) . A_t^{GAE}=\sum_{l=0}^{\infty}\gamma^l\delta_{t+l}=\sum_{l=0}^{\infty}\gamma^lr_{t+l}-V(s_t). AtGAE=∑l=0∞γlδt+l=∑l=0∞γlrt+l−V(st).,则是看每一步差分得到优势的完全平均值。
由于广义优势估计(GAE)的实现有很多变化,下面是一种可能的实现方法:
def calculate_gae(rewards, values, gamma=0.99, lambda_=0.95):
"""
计算广义优势估计(GAE)的值
:param rewards: 一组连续的状态动作奖励(reward),list
:param values: 一组连续的状态的价值(value), list
:param gamma: 衰减系数,float
:param lambda_: GAE超参数,float
:return: 估计的优势值(advantages),list
"""
# 计算 TD 计算误差 delta
deltas = [r + gamma * v_next - v for r, v, v_next in zip(rewards, values, values[1:] + [0])]
# 计算 GAE
advantages = []
advantage = 0
for delta in reversed(deltas):
advantage = gamma * lambda_ * advantage + delta
advantages.append(advantage)
advantages.reverse()
return advantages
这个函数的输入是同步的状态动作奖励和状态价值列表,以及GAE的超参数。它通过计算TD误差(delta)和广义优势估计(GAE),输出估计的优势值(advantages)。
在训练过程中,我们会调用这个函数来计算advantages。例子伪代码如下:
for _ in range(num_iterations):
#执行策略,获取state,action,reward
states, actions, rewards = run_policy(env, model, num_steps)
#计算所有状态的值
values = calculate_values(env, model, states)
#计算所有状态的advantages
advantages = calculate_gae(rewards, values)
#更新策略
update_policy(model, states, actions, advantages)
这些伪代码只是一个粗略的概念,实际实现中需要很多细节。
代码实践
离散动作空间
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
# 输入是某个状态,输出则是状态的价值。
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class TRPO:
def __init__(self, state_dim, hidden_dim, action_dim, lambda_, gamma, alpha,
kl_constraint, critic_lr, device, numOfEpisodes, env):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
# 策略网络参数不需要优化器更新
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
# GAE参数
self.lambda_ = lambda_
# KL距离最大限制
self.kl_constraint = kl_constraint
# 线性搜索参数
self.alpha = alpha
self.device = device
self.env = env
self.numOfEpisodes = numOfEpisodes
def take_action(self, state):
state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
return action_dist.sample().item()
def cal_advantage(self, gamma, lambda_, td_delta):
td_delta = td_delta.detach().numpy()
advantages = []
advantage = 0.0
for delta in reversed(td_delta):
advantage = gamma * lambda_ * advantage + delta
advantages.append(advantage)
advantages.reverse()
return torch.FloatTensor(np.array(advantages))
# compute surrogate object function
def compute_surrogate_obj(self, states, actions, advantage, old_log_probs, actor):
log_probs = torch.log(actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs)
return torch.mean(ratio * advantage)
def hessian_matrix_vector_product(self, states, old_action_dists, vector):
# 计算黑塞矩阵和一个向量的乘积
new_action_dists = torch.distributions.Categorical(self.actor(states))
kl = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists, new_action_dists)) # 计算平均KL距离
kl_grad = torch.autograd.grad(kl, self.actor.parameters(), create_graph=True)
kl_grad_vector = torch.cat([grad.view(-1) for grad in kl_grad])
# KL距离的梯度先和向量进行点积运算
kl_grad_vector_product = torch.dot(kl_grad_vector, vector)
grad2 = torch.autograd.grad(kl_grad_vector_product, self.actor.parameters())
grad2_vector = torch.cat([grad.view(-1) for grad in grad2])
return grad2_vector
# 共轭梯度法求解方程
def conjugate_gradient(self, grad, states, old_action_dists):
x = torch.zeros_like(grad)
r = grad.clone()
p = grad.clone()
rdotr = torch.dot(r, r)
for i in range(10): # 共轭梯度主循环
Hp = self.hessian_matrix_vector_product(states, old_action_dists,
p)
alpha = rdotr / torch.dot(p, Hp)
x += alpha * p
r -= alpha * Hp
new_rdotr = torch.dot(r, r)
if new_rdotr < 1e-10:
break
beta = new_rdotr / rdotr
p = r + beta * p
rdotr = new_rdotr
return x
def line_search(self, states, actions, advantage, old_log_probs,
old_action_dists, max_vec): # 线性搜索
old_para = torch.nn.utils.convert_parameters.parameters_to_vector(
self.actor.parameters())
old_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, self.actor)
for i in range(15): # 线性搜索主循环
coef = self.alpha**i
new_para = old_para + coef * max_vec
new_actor = copy.deepcopy(self.actor)
torch.nn.utils.convert_parameters.vector_to_parameters(
new_para, new_actor.parameters())
new_action_dists = torch.distributions.Categorical(
new_actor(states))
kl_div = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists,
new_action_dists))
new_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, new_actor)
if new_obj > old_obj and kl_div < self.kl_constraint:
return new_para
return old_para
def update(self, transition_dict):
states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device)
terminateds = torch.tensor(transition_dict['terminateds'], dtype=torch.float).view(-1, 1).to(self.device)
truncateds = torch.tensor(transition_dict['truncateds'], dtype=torch.float).view(-1, 1).to(self.device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - terminateds + truncateds)
td_delta = td_target - self.critic(states)
# estimate advantage using GAE
advantage = self.cal_advantage(self.gamma, self.lambda_, td_delta.cpu()).to(self.device)
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()
old_action_dists = torch.distributions.Categorical(self.actor(states).detach())
# update Value function
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# estimate policy gradient
# compute surrogate object function
surrogate_obj = self.compute_surrogate_obj(states, actions, advantage, old_log_probs, self.actor)
grads = torch.autograd.grad(surrogate_obj, self.actor.parameters())
obj_grad = torch.cat([grad.view(-1) for grad in grads]).detach()
# use the conjugate gradient algorithm to compute x = H^(-1)g
descent_direction = self.conjugate_gradient(obj_grad, states, old_action_dists)
Hd = self.hessian_matrix_vector_product(states, old_action_dists,
descent_direction)
max_coef = torch.sqrt(2 * self.kl_constraint / (torch.dot(descent_direction, Hd) + 1e-8))
# update the policy by backtracking line search
new_para = self.line_search(states, actions, advantage, old_log_probs,
old_action_dists,
descent_direction * max_coef)
# 用线性搜索后的参数更新策略
torch.nn.utils.convert_parameters.vector_to_parameters(new_para, self.actor.parameters())
def TRPOrun(self):
returnList = []
for i in range(10):
with tqdm(total=int(self.numOfEpisodes / 10), desc='Iteration %d' % i) as pbar:
for episode in range(int(self.numOfEpisodes / 10)):
# initialize state
state, info = self.env.reset()
terminated = False
truncated = False
episodeReward = 0
transition_dict = {
'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'terminateds': [], 'truncateds': []}
# Loop for each step of episode:
while 1:
action = self.take_action(state)
next_state, reward, terminated, truncated, info = self.env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['terminateds'].append(terminated)
transition_dict['truncateds'].append(truncated)
state = next_state
episodeReward += reward
if terminated or truncated:
break
self.update(transition_dict)
returnList.append(episodeReward)
if (episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (self.numOfEpisodes / 10 * i + episode + 1),
'return':
'%.3f' % np.mean(returnList[-10:])
})
pbar.update(1)
return returnList

从结果中可以看到,TRPO收敛速度相对较快,性能优异。
超参数参考:
agent = TRPO(state_dim=env.observation_space.shape[0],
hidden_dim=256,
action_dim=2,
lambda_=0.95,
gamma=0.99,
alpha=0.5,
kl_constraint=0.0005,
critic_lr=1e-2,
device=device,
numOfEpisodes=1000,
env=env)
连续动作空间
下面代码仅列出了需要修改部分的代码。
class PolicyNetContinuous(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNetContinuous, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc_mu = torch.nn.Linear(hidden_dim, action_dim)
self.fc_std = torch.nn.Linear(hidden_dim, action_dim)
# 高斯分布的均值和标准差
def forward(self, x):
x = F.relu(self.fc1(x))
mu = 2.0 * torch.tanh(self.fc_mu(x))
std = F.softplus(self.fc_std(x))
return mu, std
class TRPO:
def __init__(self, state_dim, hidden_dim, action_dim, lambda_, gamma, alpha,
kl_constraint, critic_lr, device, numOfEpisodes, env):
self.actor = PolicyNetContinuous(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
# 策略网络参数不需要优化器更新
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
# GAE参数
self.lambda_ = lambda_
# KL距离最大限制
self.kl_constraint = kl_constraint
# 线性搜索参数
self.alpha = alpha
self.device = device
self.env = env
self.numOfEpisodes = numOfEpisodes
def take_action(self, state):
state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)
mu, std = self.actor(state)
action_dist = torch.distributions.Normal(mu, std)
action = action_dist.sample()
return [action.item()]
# compute surrogate object function
def compute_surrogate_obj(self, states, actions, advantage, old_log_probs, actor):
mu, std = actor(states)
action_dists = torch.distributions.Normal(mu, std)
log_probs = action_dists.log_prob(actions)
ratio = torch.exp(log_probs - old_log_probs)
return torch.mean(ratio * advantage)
def hessian_matrix_vector_product(self, states, old_action_dists, vector, damping=0.1):
# 计算黑塞矩阵和一个向量的乘积
mu, std = self.actor(states)
new_action_dists = torch.distributions.Normal(mu, std)
kl = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists, new_action_dists)) # 计算平均KL距离
kl_grad = torch.autograd.grad(kl, self.actor.parameters(), create_graph=True)
kl_grad_vector = torch.cat([grad.view(-1) for grad in kl_grad])
# KL距离的梯度先和向量进行点积运算
kl_grad_vector_product = torch.dot(kl_grad_vector, vector)
grad2 = torch.autograd.grad(kl_grad_vector_product, self.actor.parameters())
grad2_vector = torch.cat([grad.view(-1) for grad in grad2])
return grad2_vector + damping * vector
def line_search(self, states, actions, advantage, old_log_probs,
old_action_dists, max_vec):
old_para = torch.nn.utils.convert_parameters.parameters_to_vector(
self.actor.parameters())
old_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, self.actor)
for i in range(15):
coef = self.alpha**i
new_para = old_para + coef * max_vec
new_actor = copy.deepcopy(self.actor)
torch.nn.utils.convert_parameters.vector_to_parameters(
new_para, new_actor.parameters())
mu, std = new_actor(states)
new_action_dists = torch.distributions.Normal(mu, std)
kl_div = torch.mean(
torch.distributions.kl.kl_divergence(old_action_dists,
new_action_dists))
new_obj = self.compute_surrogate_obj(states, actions, advantage,
old_log_probs, new_actor)
if new_obj > old_obj and kl_div < self.kl_constraint:
return new_para
return old_para
def update(self, transition_dict):
states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device)
terminateds = torch.tensor(transition_dict['terminateds'], dtype=torch.float).view(-1, 1).to(self.device)
truncateds = torch.tensor(transition_dict['truncateds'], dtype=torch.float).view(-1, 1).to(self.device)
rewards = (rewards + 8.0) / 8.0 # 对奖励进行修改,方便训练
td_target = rewards + self.gamma * self.critic(next_states) * (1 - terminateds + truncateds)
td_delta = td_target - self.critic(states)
# estimate advantage using GAE
advantage = self.cal_advantage(self.gamma, self.lambda_, td_delta.cpu()).to(self.device)
mu, std = self.actor(states)
old_action_dists = torch.distributions.Normal(mu.detach(), std.detach())
old_log_probs = old_action_dists.log_prob(actions)
# update Value function
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# estimate policy gradient
# compute surrogate object function
surrogate_obj = self.compute_surrogate_obj(states, actions, advantage, old_log_probs, self.actor)
grads = torch.autograd.grad(surrogate_obj, self.actor.parameters())
obj_grad = torch.cat([grad.view(-1) for grad in grads]).detach()
# use the conjugate gradient algorithm to compute x = H^(-1)g
descent_direction = self.conjugate_gradient(obj_grad, states, old_action_dists)
Hd = self.hessian_matrix_vector_product(states, old_action_dists,
descent_direction)
max_coef = torch.sqrt(2 * self.kl_constraint / (torch.dot(descent_direction, Hd) + 1e-8))
# update the policy by backtracking line search
new_para = self.line_search(states, actions, advantage, old_log_probs,
old_action_dists,
descent_direction * max_coef)
# 用线性搜索后的参数更新策略
torch.nn.utils.convert_parameters.vector_to_parameters(new_para, self.actor.parameters())
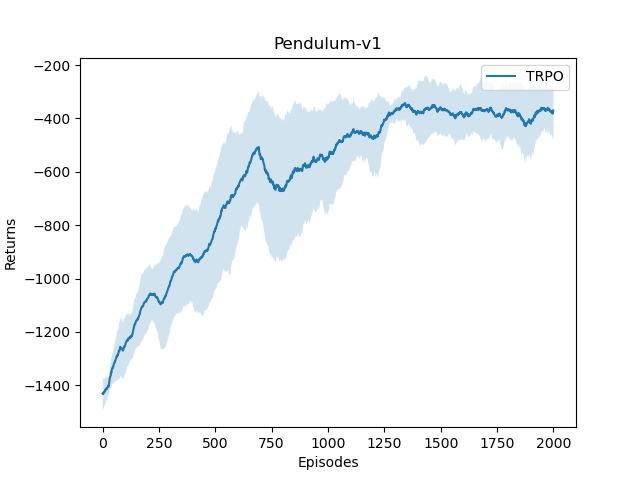
用 TRPO 在与连续动作交互的倒立摆环境中能够取得非常不错的效果,这说明 TRPO 中的信任区域优化方法在离散和连续动作空间都能有效工作。
超参数参考:
agent = TRPO(state_dim=env.observation_space.shape[0],
hidden_dim=256,
action_dim=env.action_space.shape[0],
lambda_=0.85,
gamma=0.90,
alpha=0.5,
kl_constraint=0.0005,
critic_lr=1e-2,
device=device,
numOfEpisodes=2000,
env=env)
参考
[1] 伯禹AI
[2] https://www.davidsilver.uk/teaching/
[3] 动手学强化学习
[4] Reinforcement Learning
[5] SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization [C]// International conference on machine learning, PMLR, 2015:1889-1897.
[6] Schulman J. Optimizing expectations: From deep reinforcement learning to stochastic computation graphs[D]. UC Berkeley, 2016.
[7] https://spinningup.openai.com/en/latest/algorithms/trpo.html