C++/MFC 面试题(一)
一、面向对象
- 面向对象的三大特性:封装、继承、多态
封装:
封装是把客观事物抽象成类,并且把自己的属性和方法让可信的类或对象操作,对不可性的隐藏。
继承:
可以让某个类型的对象获得另一个类型的对象的属性的方法。
多态:
虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
- 多态的实现
1)用抽象类实现多态
抽象类和抽象方法实现多态性
父类提供一系列规定, 约束子类的行为
父类可以提供一些共性的行为
2)用接口实现多态
生活中的接口最具代表性的就是插座,例如一个三接头的插头都能接在三孔插座中,因为这个是每个国家都有各自规定的接口规则,有可能到国外就不行,那是因为国外自己定义的接口类型。
- 接口与抽象类的区别
抽象类是一类事物的高度聚合,那么对于继承抽象类的子类来说,对于抽象类来说,属于“是”的关系;而接口是定义行为规范,因此对于实现接口的子类来说,相对于接口来说,是“行为需要按照接口来完成”。
二、MFC消息
- 消息类型
Windows消息 WM开头
控件通知 窗口和控件发往主窗口的消息
命令消息 WM_COMMAND - 消息机制
消息映射机制:MFC使用消息映射机制来处理消息,拥有一个消息与消息处理函数一一对应的消息映射表。当窗口发送数据的时候,会先去消息映射表里找到对应的消息处理函数,然后由消息处理函数进行相应的处理。
消息循环机制:应用程序如何不断为窗口传递消息?在一个循环内不断检测消息,并将消息发送到对于的窗口。 - 消息实现
MFC中的消息映射机制是在OnWndMsg()这个函数中实现的,而在这个函数里又会去查找相应的消息映射的宏。
MFC通过宏将指定的消息映射到派生类的成员函数中。
三、线程和进程
-
线程和进程的区别
线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。多线程主要是为了节约CPU时间,发挥利用,根据具体情况而定。线程的运行中需要使用计算机的内存资源和CPU。 -
MFC线程和普通线程的区别
分为界面线程和工作者线程,主要区别是消息循环
Win32 CreateThread
MFC界面线程 AfxBeginThread
Qt线程 继承Qthread类,然后重写run()方法;
C++11线程 Thread t(funThread);t.join()或者t.detach()来启动线程。 -
线程同步
在WIN32中,同步机制主要有以下几种:
事件
信号量
互斥量
临界区 -
事件(Event)
事件(Event)是WIN32提供的最灵活的线程间同步方式,事件可以处于激发状态(signaled or true)或未激发状态(unsignal or false)。根据状态变迁方式的不同,事件可分为两类:
(1)手动设置:这种对象只可能用程序手动设置,在需要该事件或者事件发生时,采用SetEvent及ResetEvent来进行设置。
(2)自动恢复:一旦事件发生并被处理后,自动恢复到没有事件状态,不需要再次设置。
使用”事件”机制应注意以下事项:
(1)如果跨进程访问事件,必须对事件命名,在对事件命名的时候,要注意不要与系统命名空间中的其它全局命名对象冲突;
(2)事件是否要自动恢复;
(3)事件的初始状态设置。
由于event对象属于内核对象,故进程B可以调用OpenEvent函数通过对象的名字获得进程A中event对象的句柄,然后将这个句柄用于ResetEvent、SetEvent和WaitForMultipleObjects等函数中。此法可以实现一个进程的线程控制另一进程中线程的运行, -
信号量(semaphore);
信号量是维护0到指定最大值之间的同步对象。信号量状态在其计数大于0时是有信号的,而其计数是0时是无信号的。信号量对象在控制上可以支持有限数量共享资源的访问。信号量的特点和用途可用下列几句话定义:
(1)如果当前资源的数量大于0,则信号量有效;
(2)如果当前资源数量是0,则信号量无效;
(3)系统决不允许当前资源的数量为负值;
(4)当前资源数量决不能大于最大资源数量。 -
互斥量(mutex);
采用互斥对象机制。 只有拥有互斥对象的线程才有访问公共资源的权限,因为互斥对象只有一个,所以能保证公共资源不会同时被多个线程访问。互斥不仅能实现同一应用程序的公共资源安全共享,还能实现不同应用程序的公共资源安全共享。 -
临界区(Critical section)。
临界区(Critical Section)是一段独占对某些共享资源访问的代码,在任意时刻只允许一个线程对共享资源进行访问。如果有多个线程试图同时访问临界区,那么在有一个线程进入后其他所有试图访问此临界区的线程将被挂起,并一直持续到进入临界区的线程离开。临界区在被释放后,其他线程可以继续抢占,并以此达到用原子方式操作共享资源的目的。
相关实现:
#include
CRITICAL_SECTION cs;//定义临界区对象
InitializeCriticalSection(&cs);//初始化临界区
EnterCriticalSection(&cs);//进入临界区
LeaveCriticalSection(&cs);//离开临界区
DeleteCriticalSection(&cs);//删除临界区 -
进程间通信
1)管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
3)信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;Linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
4)消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺
5)共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
6)信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
7)套接字(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
四、C++/C基础
- 数组和链表的区别
数组:内存中一块连续的区域,需要预留空间,插入和删除效率低,查询快,不利于扩展
链表:内存不要求连续,增加删除容易,查找效率低,扩展方便 - 虚函数表的实现
简单地说,每一个含有虚函数(无论是其本身的,还是继承而来的)的类都至少有一个与之对应的虚函数表,其中存放着该类所有的虚函数对应的函数指针 - delete和delete[]的区别
在回收用 new 分配的单个对象的内存空间的时候用 delete,回收用 new[] 分配的一组对象的内存空间的时候用 delete[]。 - 父类和子类
子类继承父类的所有属性和行为;
子类可以定义自己的属性和行为;
子类对父类的继承有三种方式:public,protectd,private;其继承方式指的是对父类成员的访问方式
再新建类时,需要调用构造函数,构造函数先进行初始化,再执行构造函数的函数体,因此新创建调用父类的构造函数再调用子类的构造函数;
有多重继承时,类的创建顺序和继承顺序有关,和初始化顺序无关;
子类中包含有父类:因此子类可以初始化父类的指针和引用,但是不能初始化父类对象; - 自己实现Array
template <class T>
class Array
{
protected:
T *data; //一个指向数组数据的指针
unsigned int base; //base为数组的起始下表
unsigned int length; //length为数组的长度
public:
Array(); //缺省的构造函数
Array(unsigned int, unsigned int = 0); //数组构造函数
~Array(); //析构函数
Array(Array const&); //拷贝构造函数
Array& operator = (Array const&); //重载等号操作符,用于一个数组给另外一个数组赋值
T const& operator [] (unsigned int) const; //重载中括号操作符,返回一个T数值常量,返回值不能被改变,在函数末尾加const表示this指针指向const
T& operator [] (unsigned int); //重载中括号操作符,返回一个T数值常量,其返回值可以被改变
T* Data() const; //返回数组数据的指针data
unsigned int Base() const; //返回成员base
unsigned int Length() const; //返回成员length
void SetBase(unsigned int); //设置成员变量base的数值
void SetLength(unsigned int); //设置成员变量length的数值
};
#include "Array.h"
template <class T>
Array<T>::Array() :
data(new T[10]),
base(0),
length(0)
{}
//缺省的构造函数不含变量,只需要给对象的变量一个初始值,时间复杂度O(1)
template <class T>
Array<T>::Array(unsigned int n, unsigned int m) :
data(new T[n]),
base(m),
length(n)
{}
//初始化数组,n为数组的长度,时间复杂度常量O(1)
template <class T>
Array<T>::Array(Array<T> const& array) :
data(new T[array.length]),
base(array.base),
length(array.length)
{
for (unsigned int i = 0; i < length; ++i)
data[i] = array.data[i];
}
//备份构造函数,将一个数组从赋值到另外一个数组,时间复杂度为O(n)
template <class T>
Array<T>::~Array()
{
delete[] data;
}
//析构函数,删除数组所占用的内存空间
template <class T>
T* Array<T>::Data() const
{
return data;
}
template <class T>
unsigned int Array<T>::Base() const
{
return base;
}
template <class T>
unsigned int Array<T>::Length() const
{
return length;
}
//这三个为存取器函数,用来返回成员,时间复杂度都为O(1)
template <class T>
T const& Array<T>::operator[] (unsigned int position) const
{
unsigned int const offset = position - base;
if (offset >= length)
throw out_of_range("invalid position");
return data[offset];
}
template <class T>
T& Array<T>::operator[] (unsigned int position)
{
unsigned int const offset = position - base;
if (offset >= length)
throw out_of_range("invalid position");
return data[offset];
}
//这两个都为取下表操作符的重载,区别是第一个返回值不可以作为左值,第二个返回值可以作为左值,时间复杂度都为O(1)
template <class T>
void Array<T>::SetBase(unsigned int newBase)
{
base = newBase;
}
template <class T>
void Array<T>::SetLength(unsigned int newLength)
{
T* const newData = new T[newLength];
unsigned int const min = length < newLength ? length : newLength;
for (unsigned int i = 0; i < min; ++i)
newData[i] = data[i];
delete[] data;
data = newData;
length = newLength;
}
//这两个函数来重设对象的成员,时间复杂度为T(m,n)=min(m,n)*T(T::T(T&))+O(1)
template <class T>
Array<T>& Array<T>::operator = (Array<T> const& array)
{
if (this != &array)
{
delete[] data;
base = array.base;
length = array.length;
data = new T[length];
for (unsigned int i = 0; i < length; ++i)
data[i] = array.data[i];
}
return this;
}
//重载赋值操作符,时间复杂度为O(n)
五、MFC类的继承关系
- 窗口类:
CObject–》CCmdTarget–》CWnd—》CFrameWnd (其他控件对象的容器) - 对话框类:
CObject–》CCmdTarget–》CWnd—》CDialog->CDialogEx - CWinApp类
CObject–》CCmdTarget–》CWinThread—》CWinApp ------》initinstance()
CObject:CObject是大多数MFC类的根类或基类。
对运行时类信息的支持、判断类是否是该类的实例:IsKindOf函数
动态创建的支持、运行时候可以来创建指定类:窗口对象、文档对象
串行化的支持层(不包括直接调用Serailize实现序列化),重载Serialize函数
这三种功能的层次依次升高。
CCmdTarget:MFC类库中消息映射体系的一个基类,是MFC处理命令消息的基础、核心。消息映射把命令或消息引导给用户为之编写的响应函数。
CCmdTarget:有两个与消息映射有密切关系的成员函数:DispatchCmdMsg和OnCmdMsg。
CWnd:提供了微软基础类库中所有窗口类的基本功能。
CWinThread:封装了对线程的操作,
CwinApp:应用程序类
CFrameWnd:往往用于创建应用程序的主窗口
六、异常处理
-
异常使用
throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
catch: 在您想要处理问题的地方,通过异常处理程序捕获异常.catch 关键字用于捕获异常,可以有多个catch进行捕获。
try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。 -
异常安全
构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不完整或没有完全初始化。
析构函数主要完成资源的清理,最好不要在析构函数内抛出异常,否则可能导致资源泄漏(内存泄漏、句柄未关闭等)。
C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出了异常,导致内存泄漏,在lock和unlock之间抛出了异常导致死锁,C++经常使用RAII(智能指针)来解决以上问题。 -
异常规范
异常规格说明的目的是为了让函数使用者知道该函数可能抛出的异常有哪些。 可以在函数的后面接throw(类型),列出这个函数可能抛掷的所有异常类型。
函数的后面接throw(),表示函数不抛异常。
若无异常接口声明,则此函数可以抛掷任何类型的异常。 -
异常类型
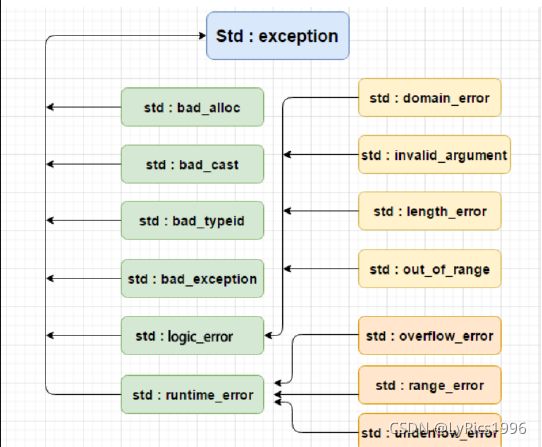
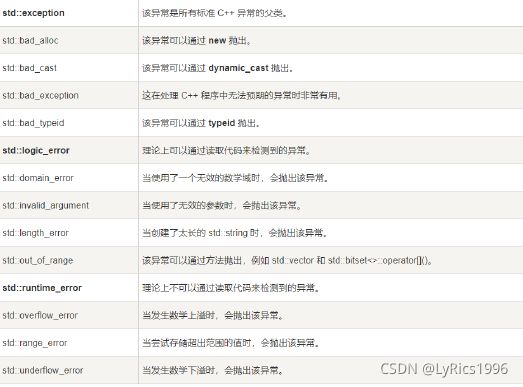
-
异常的优缺点
C++异常的优点:
1)异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。
2)返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误。
3)很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库。
4)很多测试框架都使用异常,这样能更好的使用单元测试等进行白盒的测试。
5)部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如T&operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误
C++异常的缺点:
1)异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
2)异常会有一些性能的开销。
3)C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题。
4)C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
5)异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。所以异常规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都使用 func()throw();的方式规范化。
七、设计模式
-
设计模式的种类
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。 -
单例模式中饿汉和懒汉的区别
饿汉:类加载时就已经实例化类,线程安全
懒汉:getinstance时再实例化, 非线程安全
八、智能指针
- 智能指针的含义与作用
1)从较浅的层面看,智能指针是利用了一种叫做RAII(资源获取即初始化)的技术对普通的指针进行封装,这使得智能指针实质是一个对象,行为表现的却像一个指针。
2)智能指针的作用是防止忘记调用delete释放内存和程序异常的进入catch块忘记释放内存。另外指针的释放时机也是非常有考究的,多次释放同一个指针会造成程序崩溃,这些都可以通过智能指针来解决。
3)智能指针还有一个作用是把值语义转换成引用语义。 - 智能指针的实质:
智能指针是一个类对象,这样在被调函数执行完,程序过期时,对象将会被删除(对象的名字保存在栈变量中),这样不仅对象会被删除,它指向的内存也会被删除的。 - 使用建议
智能指针在C++11版本之后提供,包含在头文件中,shared_ptr、unique_ptr、auto_ptr(已废弃)
建议:1-每种指针都有不同的使用范围,unique_ptr指针优于其它两种类型,除非对象需要共享时用shared_ptr。
2- 建议– 如果你没有打算在多个线程之间来共享资源的话,那么就请使用unique_ptr。
3 -建议- 使用make_shared而不是裸指针来初始化共享指针。
4 -建议 – 在设计类的时候,当不需要资源的所有权,而且你不想指定这个对象的生命周期时,可以考虑使用weak_ptr代替shared_ptr。 - shared_ptr
shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。 - unique_ptr
unique_ptr“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。相比与原始指针unique_ptr用于其RAII的特性,使得在出现异常的情况下,动态资源能得到释放。unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。unique_ptr指针与其所指对象的关系:在智能指针生命周期内,可以改变智能指针所指对象,如创建智能指针时通过构造函数指定、通过reset方法重新指定、通过release方法释放所有权、通过移动语义转移所有权。 - weak_ptr
weak_ptr是为了配合shared_ptr而引入的一种智能指针,因为它不具有普通指针的行为,没有重载operator*和->,它的最大作用在于协助shared_ptr工作,像旁观者那样观测资源的使用情况。weak_ptr可以从一个shared_ptr或者另一个weak_ptr对象构造,获得资源的观测权。但weak_ptr没有共享资源,它的构造不会引起指针引用计数的增加。使用weak_ptr的成员函数use_count()可以观测资源的引用计数,另一个成员函数expired()的功能等价于use_count()==0,但更快,表示被观测的资源(也就是shared_ptr的管理的资源)已经不复存在。weak_ptr可以使用一个非常重要的成员函数lock()从被观测的shared_ptr获得一个可用的shared_ptr对象, 从而操作资源。但当expired()==true的时候,lock()函数将返回一个存储空指针的shared_ptr。
九、性能优化
9. 1总体原则
1、用好的编译器并用好编译器(支持C++11的编译器,IntelC++(速度最快)、GNU的C++编译器GCC/G++(非常符合标准),Visual C++(性能折中),clang(最年轻Mac OS x))。
2、使用更好的算法。
3、使用更好的数据结构(不同的数据结构在使用内存管理器的方式也有所不同)。
4、使用更好的库(熟悉和掌握标准C++模板库对于进行性能优化的开发员是必须的技能,Boost Project 和 Google Code 公开了很多有用的库)。
5、减少内存分配和复制(减少对内存管理器的调用是一种非常有效的优化手段)。
6、优化内存管理(内存管理器的调度,丰富的API)。
7、移除计算(对于单条的C++语句进行优化)。
8、提高并发性(多个处理核心执行指令)。
9.2 影响优化的计算机行为
1、计算机的物理组成本身对计算机性能的限制。
2、计算机的主内存是比较慢的(通往主内存的接口是限制执行速度的瓶颈(冯*诺伊曼瓶颈),(摩尔定理)每年处理器的核心的数量都会增加,但是计算机的性能未必会提高,因为这些核心只是等待访问内存的机会(内存墙memory wall))。
3、计算机内存的访问方式(并非以字节为单位),某些内存访问会比其他的更慢(分为一级高速缓存(cache memory)、二级高速缓存、三级高速缓存、主内存、磁盘上的虚拟内存页)。
4、内存的容量是有限的,每个程序都会与其他程序竞争计算机资源,计算比做决定快。
5、在处理器中,访问内存的性能开销远比其他操作的性能开销大,非对齐访问所需要的时间是所有字节都在同一字节中的两倍。
6、访问频繁使用的内存地址的速度比访问非频繁使用的地址快,访问相邻地址的内存的速度比访问相互远隔的地址的内存块。
7、访问线程间共享的数据比访问非共享的数据资源慢很多。当并发线程共享数据时,同步代码降低了并发量。
8、有些语句隐藏了大量的计算,从语句的外表上看不出语句的性能开销会有多大。
9.3 性能测量
1、90/10规则:一个程序会花费90%的运行时去执行10%的代码。
2、只有正确且精确的测量才是准确的测量。
3、分辨率不是准确性。
4、在Windows上,clock()函数提供了可靠的毫秒级的时钟计时功能。在Windows8和之后的版本中,GetSystemTimePreciseAsfileTime()提供了亚微秒的计时功能。
5、计算一条C++语句对内存的读写次数,可以估算出一句C++ 语句的性能开销。
9.4 优化字符串的使用
1、由于字符串是动态分配内存的,因此它们的性能开销非常大。它们在表达式中的行为与值类似,它们的实现方式中需要大量的复制。
2、将字符串作为对象而非值可以降低内存分配和复制的频率。
3、为字符串预留内存空间可以减少内存分配的开销。
4、将指向字符串的常量引用传递给函数与传递值的结果几乎一样,但是更加高效。
5、将函数的结果通过输出参数作为引用返回给调用方会复用实参的存储空间,这可能比分配新的存储空间更加高效。
6、即使只是有时候会减少内存分配的开销,仍然是一种优化。
9.5 优化动态分配内存的变量
1、在C++程序中,乱用动态分配内存的变量是最大的“性能杀手”。
2、C++变量(每个普通数据类型的变量;每个数组,结构体或类实例)在内存中的布局都是固定的,它们的大小在编译时就已经确定了。
3、每个变量都有它的存储期(生命周期),只有在这段时间内变量所占用的存储空间或者内存字节中的值才是有意义的。为变量分配内存的开销取决于存储期(静态存储期、线性局部存储期、自动存储期、动态存储期)。
4、C++变量的所有者决定了变量什么时候会被创建,什么时候会被析构(变量所有权是一个单独的概念,与存储期不同)。动态变量的所有权必须有程序员执行并编写在程序逻辑中,它不受编译器控制,也不由C++定义。具有强定义所有权的程序会比所有权分散的程序更高效。
5、在C++中,动态变量是由 new 表达式创建,由 delete 表达式释放的。它们会调用C++标准库的内存管理函数。
6、智能指针会通过耦合动态变量的生命周期与拥有该变量的智能指针的生命周期,来实现动态变量所有权的自动化。C++允许多个指针和引用指向同一个动态变量,共享了所有权的动态变量开销更大。
7、静态的创建类成员并且在有必要时采用“两段初始化”,这样可以节省为这些成员变量分配内存的开销。
8、让主指针来拥有动态变量,使用无主指针替代共享所有权。
9、从性能优化的角度上看,使用指针或是引用进行赋值和参数传递,或是返回指针或引用更加高效,因为指针和引用时存储在寄存器中的。
10、当一个数据结构中的元素被存储在连续的存储空间中时,我们称这个数据结构为扁平的,相比于通用指针链接在一起的数据结构,扁平数据结构具有显著的性能优势
9.6 优化热点语句
1、除非有一些因素放大了语句的性能开销,否则不值得进行语句级别的性能优化,因为所能带来的性能提升不大。
2、循环中的语句的性能开销被放大的倍数是循环的次数。函数中的语句的性能开销被放大的倍数是函数被调用的次数。被频繁地调用的编程惯用法的性能开销被放大的倍数是其被调用的次数。
3、从循环中移除不变性代码(当代码不依赖于循环的归纳变量时,它就具有循环不变性),不过现代编译器非常善于找出循环中被重复计算的具有循环不变性的代码。
4、从循环中移除无谓的函数调用,一次函数调用可能会执行大量指令,这是影响程序性能的一个重要因素,如果一个函数具有循环不变性,那么将它移除到循环外有助于改善性能。有一种函数永远都可以被移动到循环外部,那就是返回值只依赖于函数参数而且没有副作用的纯函数。
5、从循环中移除隐含的函数调用;如果将函数签名从通过值传递实参修改为传递指向类的引用和指针,有时候可以在进行隐式函数调用时移除形参构建。
6、调用函数的开销是非常小的,只是执行函数体的开销可能非常大,如果一个函数被重复调用多次则累积的开销会变得很大。函数调用的开销主要包括函数调用的基本开销、虚函数的开销、继承中的成员函数调用、函数指针的开销等。函数的调用开销虽然很大,但正因为函数调用才实现了程序的一些复杂的功能。
6、调用操作系统的函数的开销是高成本的。
7、内联函数是一种有效的移除函数调用开销的方法。
9.7 使用更好的库
1、C++为常用功能提供了一个简洁的标准库。
*确定哪些依赖于实现的行为,如每种数据类型的最大值和最小值。
*易于使用但是编写和验证都很繁琐的可移植的超越函数(超越函数指的是变量之间的关系不能用有限次加、减、乘、除、乘方、开方运算表示的函数),如正弦函数和余弦函数、对数函数和幂函数、随机数函数等等。
*除了内存分配外,不依赖于操作系统的可移植的通用数据结构、如字符串、链表和表。
*可移植的通用数据查找算法、数据排序算法和数据转换算法。
*以一种独立于操作系统的方式与操作系统的基础服务相联系的执行内存分配、操作线程、管理和维护时间以及流I/O等任务的函数。
2、使用C++标准库的注意事项
*标准库的实现中有bug,(标准库和编译器是单独维护的,编译器中也可能存在bug,标准需求的改变、责任的分散、计划问题以及标准库的复杂度都会不可避免地影响它们的质量)。
*标准库的实现可能不符合C++标准,(库的发布计划和编译器是不同的,而编译器的发布计划与与C++标准不同,一个标准库的实现可能会领先或是落后于编译器)。
*对于标准库开发人员来说,性能并非是最终要的事情,(因为库会被长期使用,所以库的简单性和可维护性更加重要)。
*库的实现可能会让一些优化手段失效,C++标准库中的有些部分并非是有用的。
*标准库不如最好的原生函数,(标准库没有为某些操作系统提供异步文件I/O等特性,性能优化人员只能通过调用原生函数,牺牲可移植性来换取运行速度)。
3、C++标准库之所以提供这些函数和类,是因为要么无法以其他方式提供这些函数和类,要么这些函数和类被广泛地用于多种操作系统上。在对库进行性能优化时,测试用例非常关键;接口的稳定性是可交付的库的核心。
4、扁平继承层次关系(多数抽象都不会有超高三层类继承层次,一旦超高三次可能表明类的层次结构不够清晰,其引入的复杂性会导致性能的下降)。
扁平调用链(绝大多数抽象的实现都不会超高三层嵌套函数的调用,在已经充分解耦的库中是不会包含冗长的嵌套抽象调用链的)。
9.8 优化算法
1、高效的算法是计算机科学一直研究的主题,计算机科学家十分重视算法和数据结构的研究,因为它是展示优化代码的典型事例。当一个程序需要数秒内执行完毕,实际上却要花费数小时时,唯一可以用成功的优化方法可能就是选择一种高效的算法了。算法是一个非常重要且不能简而概之的主题,可以参考《算法导论》,进行更深入的学习。
2、优化模式
开发人员研究算法和数据结构的原因之一是其中蕴含着用于改善性能的“思维库”,这些改善性能的通用技巧是非常的使用的,其中的一些模式也是数据结构、C++语言特性和硬件创新的核心。
- 预计算;可以在程序早期,通过在热点代码前执行执行计算来将计算从热点部分中移除。
- 延迟计算;通过在正真需要执行计算时才执行计算,可将计算从某些代码路径上移除。
- 批量处理;每次对多个元素一起进行计算,而不是一次只对一个元素进行计算。
- 缓存;通过保存和复用高代价计算的结果来减少计算量,而不是重复进行计算。
- 特化;通过移除未使用的共性来减少计算量。
- 提高处理量;通过一次处理一大组数据来减少循环处理的开销。
- 提示;通过在代码中加入可能会改善性能的提示来减少计算量。
- 优化期待路径;以期待频率从高到低的顺序对输入数据或是运行时发生的事件进行测试。
- 散列法;计算可变成字符串等大型数据结构的压缩数值映射(散列值)。在进行比较时,用散列代替数据结构可以提高性能。
- 双重检查;通过先进行一项开销不大的检查,然后只在必要时才进行另外一项开销昂贵的检查来减少计算量。
9.9 优化查找和排序
1、改善查找性能的工具箱,测量当前的实现方式的性能来得到比较基准,识别出待优化的抽象活动,将待优化的活动分解为组件算法和数据结构,修改或是替换那些可能并非最优的算法和数据结构,然后进行性能测试以确定修改是否有效果。
2、标准库查找算法接受两个迭代器参数:一个指向待查找序列的开始位置,另一个则指向待查找序列的末尾位置(最后一个元素的下一个位置)。所有的算法还都接受一个要查找的键作为参数以及一个可选的比较函数参数。
3、使用C++标准库优化排序,在能够使用分而治之算法高效地进行查找之前,我们必须先对序列容器排序,C++标准库提供了两种能够高效地对序列容器进行排序的标准算法——std::sort()和std::stable_sort()。
十、优化并发
1、并发是多线程控制的同步执行,并发的目标不是减少指令执行的次数或是每秒访问数据的次数,而是通过提高计算资源的使用率来减少程序运行的时间的。
2、有很多机制能够为程序提供并发,其中有些基于操作系统或是硬件。C++标准库直接支持线程共享内存的并发模型。
3、计算机硬件、操作系统、函数库以及C++自身的特性都能够为程序提供并发支持。
- 时间分隔;这是操作系统的一个调度函数,为每个程序都分配时间块。操作系统是依赖于处理器和硬件的。它会使用计时器和周期性的中断来调整处理器的调度。
- 虚拟化;虚拟化技术是让操作系统将处理器的时间块分配给客户虚拟机,计算资源能够根据每台客户虚拟机上正在运行的程序的需求进行分配。
- 容器化;容器中包含了程序在检查点的文件系统镜像和内存镜像,其主机是一个操作系统,能够直接提供I/O和系统资源。
- 对称式多处理;是一种包含若干执行相同机器代码并访问相同物理内存的执行单元的计算机,现代多核处理器都是对称式多处理器。使用正真的硬件并发执行多线程控制。
- 同步多线程;有些处理器的硬件核心有两个或多个寄存器集,可以相应地执行两条或多条指令流。最高效第使用软件线程的方法是让软件线程数量与硬件线程数量匹配。
- 多进程;进程是并发的执行流,这些执行流有它们自己的受保护的虚拟内存空间,进程之间通过管道、队列、网路I/O或是其他不共享的机制进行通信,进程的主要优点是操作系统会隔离各个进程,使其不会互相干扰影响。
- 分布式处理;是指程序活动分布在一组处理器上,这些处理器可以不同。分布式处理系统通常会被分解为子系统,形成模块化的,易于理解的和能够重新配置的体系结构。
- 线程;线程是进程中的并发执行流,它们之间共享内存;与进程相比,线程的优点在于消耗的资源更少、创建和切换也更快。由于进程中的所有线程都共享相同的内存空间,所以一个线程写入无效的内存地址可能会覆盖掉其他线程的数据结构,导致线程奔溃或是出现不可预测的情况。
- 任务;任务是一个独立线程的上下文中能够被异步调用的执行单元,任务运行的基础是线性池。基于任务的并发构建于线程之上,因此任务也具有线程的优点和缺点。
4、如果没有竞争,那么一个多线程C++程序具有顺序一致性,理想的竞争一块短临界区的核心数量是两个。在临界区中执行I/O操作无法优化性能,可运行线程的数量应当少于或等于处理器核心数量。
十、业务功能
-
程序挂掉,如何自启,尤其是release版本下(如何优雅的程序崩溃)
思路1:守护进程
思路2:SetUnhandledExceptionFilter+ MiniDumpWriteDump + PDB解决方案
SetUnhandledExceptionFilter:Windows为应用程序提供了一种通过SetUnhandledExceptionFilter函数覆盖默认应用程序“崩溃”处理功能的方法,能够精确定位引起崩溃的代码行在事后调试中是非常宝贵的。
MiniDumpWriteDump:将用户模式minidump信息写入指定的文件。
PDB:PDB(Program Database,程序数据库)文件保存调试和项目状态信息
思路3:Google Breakpad方案
breakpad是google开发的一个跨平台C/C++ dump捕获开源库,崩溃文件使用微软的minidump格式存储,也支持发送这个dump文件到你的服务器,breakpad可以在程序崩溃时触发dump写入操作,也可以在没有触发dump时主动写dump文件。
思路4:观察者模式
思路5:Theron 和 Actor模型 -
TCP/IP相关

TCP与UDP区别:
TCP面向连接 (如打电话要先拨号建立连接); UDP是无连接 的,即发送数据之前不需要建立连接
TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
TCP对系统资源要求较多,UDP对系统资源要求较少。
-
http的请求方式
1)GET方法
GET方法用于使用给定的URI从给定服务器中检索信息,即从指定资源中请求数据。使用GET方法的请求应该只是检索数据,并且不应对数据产生其他影响。
GET请求是可以缓存的,我们可以从浏览器历史记录中查找到GET请求,还可以把它收藏到书签中;且GET请求有长度限制,仅用于请求数据(不修改)。
注:因GET请求的不安全性,在处理敏感数据时,绝不可以使用GET请求。
2)POST方法
POST方法用于将数据发送到服务器以创建或更新资源,它要求服务器确认请求中包含的内容作为由URI区分的Web资源的另一个下属。
POST请求永远不会被缓存,且对数据长度没有限制;我们无法从浏览器历史记录中查找到POST请求。
3)HEAD方法
HEAD方法与GET方法相同,但没有响应体,仅传输状态行和标题部分。这对于恢复相应头部编写的元数据非常有用,而无需传输整个内容。
4)PUT方法
PUT方法用于将数据发送到服务器以创建或更新资源,它可以用上传的内容替换目标资源中的所有当前内容
它会将包含的元素放在所提供的URI下,如果URI指示的是当前资源,则会被改变。如果URI未指示当前资源,则服务器可以使用该URI创建资源。
5)DELETE方法
DELETE方法用来删除指定的资源,它会删除URI给出的目标资源的所有当前内容。
6)CONNECT方法
CONNECT方法用来建立到给定URI标识的服务器的隧道;它通过简单的TCP / IP隧道更改请求连接,通常实使用解码的HTTP代理来进行SSL编码的通信(HTTPS)。
7)OPTIONS方法
OPTIONS方法用来描述了目标资源的通信选项,会返回服务器支持预定义URL的HTTP策略。
8)TRACE方法
TRACE方法用于沿着目标资源的路径执行消息环回测试;它回应收到的请求,以便客户可以看到中间服务器进行了哪些(假设任何)进度或增量。 -
网络通信百万级并发如何处理
orca是一个基于C++11/14风格的轻量级actor库,ping-pong测试显示性能较为优异

-
Json的特点
JSON 是轻量级的文本数据交换格式
JSON 具有自我描述性,更易理解
JSON 采用完全独立于语言的文本格式:与XML相比
类似于 XML 的特性:
JSON 是纯文本
JSON 具有“自我描述性”(人类可读)
JSON 具有层级结构(值中存在值)
JSON 可通过 JavaScript 进行解析
JSON 数据可使用 AJAX 进行传输相比 XML 的不同之处:
没有结束标签
更短
读写的速度更快
能够使用内建的 JavaScript eval() 方法进行解析
使用数组
不使用保留字 -
libcurl
libcurl作为是一个多协议的便于客户端使用的URL传输库,基于C语言,提供C语言的API接口,支持DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet and TFTP这些协议,同时支持使用SSL证书的安全文件传输:HTTP POST, HTTP PUT, FTP 上传, 基于HTTP形式的上传、代理、Cookies、用户加密码的认证等多种应用场景。另外,libcurl是一个高移植性的库,能在绝大多数系统上运行,包括Solaris, NetBSD, FreeBSD, OpenBSD, Darwin, HPUX, IRIX, AIX, Tru64, Linux, UnixWare, HURD, Windows, Amiga, OS/2, BeOs, Mac OS X, Ultrix, QNX, OpenVMS, RISC OS, Novell NetWare, DOS等。 -
rabbitmq的特点
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。
灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。
高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。
管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。
插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。 -
MQ、RPC的区别于联系
MQ 是生产者消费者模式。
RPC 是请求响应模式。
MQ 是面向数据的。
RPC 是面向动作的。
最大的区别是,rpc没有broker, 而消息队列是需要管理消息的存储的,rpc没有存储,只有通信。
不管是消息队列还是rpc调用都是 分布式下面的 通信方式。
消息队列最容易理解的方式就是生产者消费者模式,使两个应用解耦。mq等框架就是对这的具体实现。
rpc中主要有两点,一是消息的传输格式(文本或二进制),二是消息传输方式(http或tcp)。有的框架是对前者实现,如probuffer,有的是对后面实现,如netty,还有的就是一个整体实现,如thrift。
不管怎样,他们都是为了实现通信。 -
MFC中PostMessage和sendMessage的区别
1)返回值
其中 函数4 个参数的意义是一样的,返回值类型不同(其实从数据上看他们一样是一个 32 位的数,只是意义不一样),LRESULT 表示的是消息被处理后的返回值,BOOL 表示的是消息是不是 Post 成功。
LRESULT SendMessage ( HWND hWnd,
UINT Msg,
WPARAM wParam,
LPARAM lParam );
BOOL PostMessage( HWND hWnd,
UINT Msg,
WPARAM wParam,
LPARAM lParam);
2)PostMessage 是异步的,SendMessage 是同步的。
PostMessage 只把消息放到队列,不管消息是不是被处理就返回,消息可能不被处理;
SendMessage等待消息被处理完了才返回,如果消息不被处理,发送消息的线程将一直处于阻塞状态,等待消息的返回。
同一个线程内:
SendMessage 发送消息时,由USER32.DLL模块调用目标窗口的消息处理程序,并将结果返回,SendMessage 在同一个线程里面发送消息不进入线程消息队列;PostMessage 发送的消息要先放到消息队列,然后通过消息循环分派到目标窗口(DispatchMessage)。
不同线程内:
SendMessage 发送消息到目标窗口的消息队列,然后发送消息的线程在USER32.DLL模块内监视和等待消息的处理结果,直到目标窗口的才处理返回,SendMessage在返回之前还需要做许多工作,如响应别的线程向它发送的SendMessage().PostMessge() 到别的线程的时候最好使用PostThreadMessage 代替。PostMessage()的HWND 参数可以为NULL,相当于PostThreadMessage() + GetCrrentThreadId.
3)系统只整理和编号系统消息(0 到 WM_USER 之间的消息),发送用户消息(WM_USER 以上)到别的进程时,需要自己定义。
用 PostMessage、SendNotifyMessage、SendMessageCallback 等异步函数发送系统消息时,参数里不可以使用指针,因为发送者并不等待消息的处理就返回,接受者还没处理指针就已经被释放了。