数据结构与算法学习笔记 5.串(字符串)
5.串(字符串)
5.1 串的定义
串(string)是由零个或多个字符组成的有限序列,叉叫字符串。
一般般记为S=“a1a2…an″ (n ≥) ,其中, s是串的名称,用双引号(有些书中也用单引号)括起来的字符序列是串的值,注意引号不属于串的内容。ai(1≤i≤n)可以是字母、数字或其他字符,i就是该字符在串中的位置。串中的字符数目n称为串的长度,定义中谈到“有限”是指长度″是一个有限的数值。零个字符的串称为空串(null string),它的长度为零,可以直接用两个双引号“""”表示。所谓的序列,说明串的相邻字符之间具有前驱和后继的关系。
空格串,是只包含空格的串。注意它与空串的区别。空格串是有内容有长度的,而且可以不止一个空格。 子串与主串,串中任意个数的连续字符组成的子序列称为该串的子串,相应地包含子串的串称为主串。子串在主串中的位置就是子串的第—个字符在主串中的序号。
5.2 串的比较
两个数字,很容易比较大小。2比1大,这完全正确,可是两个字符串如何比较?比如“silly",“stupid"这样的同样表达“愚蠢的”的单词字符串,它们在计算机中的大小其实取决于它们挨个字母的前后顺序。它们的第一个字母都是”s“,我们认为不存在大小差异,而第二个字母,由于”i“字母比”t“字母要靠前,所以”i“<“t” ,于是我们说"silly”<“stupid”。
事实上,串的比较是通过组成串的字符之间的编码来进行的,而字符的编码值得是字符在对应字符集中的序号。
计算机中常用的字符是使用标准的ASCII编码,更准确一点,由7位二进制数表示一个字符,总共可以表示128个字符。后来发现—些特殊符号的出现128个不够用,于是扩展ASCII码由8位二进制数表示一个字符,总共可以表示256个字符,这已经足够满足以英语为主的语言和特殊符号进行输入、存储、输出等操作的字符需要了。可是单我们国家就有除汉族外的满、回、藏、蒙古、维吾尔等多个少数民族文字,换作全世界估计要有成百上千种语言与文字,显然这256个字符是不够的,因此后来就有了Unicode 编码,比较常用的是由16位的二进制数表示一个字符,这样总共就可以表示216个字符, 约是65万多个字符,足够表示世界上所有语言的所有字符了。当然,为了和ASCII码兼容,Unicode的前256个字符与ASCII码完全相同。
所以如果我们要在C语言中比较两个串是否相等,必须是它们串的长度以及它们各个对应位置的字符都相等时,才算是相等。即给定两个串: s="a1a2…an", t="b1b2…bn", 当且仅当n=m,且a1=b1,a2=b2,…an=bn时,我们认为s=t。
那么对干两个串不相等时,如何判定它们的大小呢?我们这样定义:
给定两个串: s="a1a2…an", t="b1b2…bn",当满足以下条件之一时,s
(1) n
(2) 存在某个k<=min(m, n),使得ai=bi(i=1,2···,k-1),ak
5.3 串的抽象数据类型
串的逻辑结构和线性表很相似,不同之处在于串针对的是字符集,也就是串中的元素 是字符,哪怕串中的字符是由“123”这样的数字组成,或者是由“2010-10-10”这样的日期组成,它们都只能理解为长度为3和长度为10的字符串,每个元素都是字符而已。 因此,对于串的基本操作与线性表是有很大差别的。线性表更关注的是单个元素的操作,比如查找一个元素,插入或删除一个元素,但串中更多的是查找子串位置、得到指定位置子串、替换子串等操作。
下面是串的抽象数据结构:
ADT 串(string)
Data
串中元素仅有一个字符组成,相邻元素具有钱去和后继关系
Operation
StrAssign(T, *chars):生成一个其值等于字符串常量chars的串T
StrCopy(T,S):串S存在,由串S复制得串T
ClearString(S):串S存在,将串清空
StringEmpty(S):若串S为空,返回true,否则返回False
StrLength(S):返回串S的元素个数,即串的长度
StrCompare(S, T):若S>T,返回值>0,若S=T,返回0,若
5.4 串的存储结构
(1)串的顺序储存结构
串的顺顶序存储结构是用一组地址连续的存储单元来存储串中的字符序列的。按照预定 义的大小为每个定义的串变量分配—个固定长度的存储区。—般是用定长数组来定义。
串值的存储空间可在程序执行过程中动态分配而得。比如在计算机中存在一个自由存储区,叫做“堆”。这个堆可由C语言的动态分配函数malloc()和free()来管理。
(2)串的链式储存结构
对于串的链式存储结构,与线性表是相似的,但由于串结构的特殊性,结构中的每个元素数据是—个字符,如果也简单地应用链表存储串值,—个结点对应—个字符,就会存在很大的空间浪费。因此,一个结点可以存放一个字符,也可以考虑存放多个字符,最后一个结点为被占满时,可以用”#“或其他非串值字符补全。
但串的链式存储结构除了在连接串与串操作时有一定方便之外,总的来说不顺序存储灵活,性能也不如顺序存储结构好。
5.5 KMP模式匹配算法
5.5.1 KMP模式匹配算法原理
"字符串A是否为字符串B的子串?如果是的话出现在B的哪些位置?"该问题就是字符串匹配问题,字符串A称为模式串,字符串B称为主串。
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
本篇将以如下顺序来讲解KMP,
- 什么是KMP
- KMP有什么用
- 什么是前缀表
- 为什么一定要用前缀表
- 如何计算前缀表
- 前缀表与next数组
- 使用next数组来匹配
- 时间复杂度分析
- 构造next数组
- 使用next数组来做匹配
- 前缀表统一减一 C++代码实现
- 前缀表(不减一)C++实现
1)什么是KMP
说到KMP,先说一下KMP这个名字是怎么来的,为什么叫做KMP呢。
因为是由这三位学者发明的:Knuth,Morris和Pratt,所以取了三位学者名字的首字母。所以叫做KMP
2)KMP有什么用
所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
3)什么是前缀表
写过KMP的同学,一定都写过next数组,那么这个next数组究竟是个啥呢?
next数组就是一个前缀表(prefix table)。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
为了清楚地了解前缀表的来历,我们来举一个例子:
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
请记住文本串和模式串的作用,对于理解下文很重要,要不然容易看懵。前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,再重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
那么什么是前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
4)最长公共前后缀?
文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
正确理解什么是前缀什么是后缀很重要!
那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
我理解是用“最长相等前后缀” 更准确一些。
因为前缀表要求的就是相同前后缀的长度。
而最长公共前后缀里面的“公共”,更像是说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
所以字符串a的最长相等前后缀为0。 字符串aa的最长相等前后缀为1。 字符串aaa的最长相等前后缀为2。 等等…。
5)为什么一定要用前缀表
这就是前缀表,那为啥就能告诉我们上次匹配的位置,并跳过去呢?
回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图:
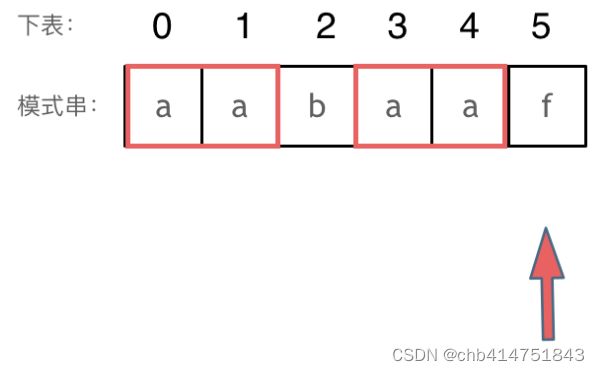
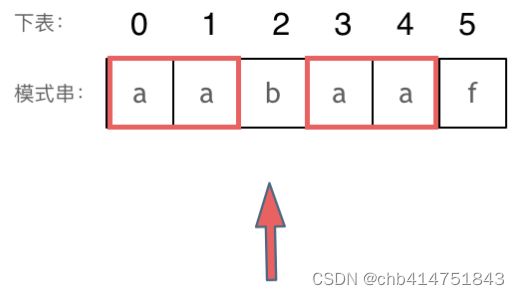
然后就找到了下标2,指向b,继续匹配:如图:
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配非常重要!
下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
很多介绍KMP的文章或者视频并没有把为什么要用前缀表?这个问题说清楚,而是直接默认使用前缀表。
6)如何计算前缀表
接下来就要说一说怎么计算前缀表。
如图:

长度为前1个字符的子串a,最长相同前后缀的长度为0。(注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。)

长度为前2个字符的子串aa,最长相同前后缀的长度为1。
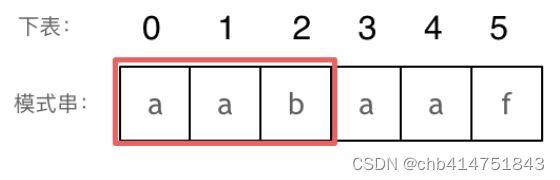
长度为前3个字符的子串aab,最长相同前后缀的长度为0。
以此类推: 长度为前4个字符的子串aaba,最长相同前后缀的长度为1。 长度为前5个字符的子串aabaa,最长相同前后缀的长度为2。 长度为前6个字符的子串aabaaf,最长相同前后缀的长度为0。
那么把求得的最长相同前后缀的长度就是对应前缀表的元素,如图:

可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
7)前缀表与next数组
很多KMP算法的时间都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
其实这并不涉及到KMP的原理,而是具体实现,next数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。
void getNext(int* next, const string& s) {//前缀表统一减1
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
void getNext(int* next, const string& s) {//正常前缀表
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
5.6 应用例题
1.力扣题号:344.反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
链接:https://leetcode.cn/problems/reverse-string
思路:
对于这道题目一些同学直接用C++里的一个库函数 reverse,调一下直接完事了, 相信每一门编程语言都有这样的库函数。
如果这么做题的话,这样大家不会清楚反转字符串的实现原理了。
但是也不是说库函数就不能用,是要分场景的。
如果在现场面试中,我们什么时候使用库函数,什么时候不要用库函数呢?
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
毕竟面试官一定不是考察你对库函数的熟悉程度, 如果使用python和java 的同学更需要注意这一点,因为python、java提供的库函数十分丰富。
如果库函数仅仅是解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
建议大家平时在leetcode上练习算法的时候本着这样的原则去练习,这样才有助于我们对算法的理解。
不要沉迷于使用库函数一行代码解决题目之类的技巧,不是说这些技巧不好,而是说这些技巧可以用来娱乐一下。
真正自己写的时候,要保证理解可以实现是相应的功能。
接下来再来讲一下如何解决反转字符串的问题。
在反转链表中,使用了双指针的方法。
那么反转字符串依然是使用双指针的方法,只不过对于字符串的反转,其实要比链表简单一些。
因为字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
题解代码1:
void reverseString(vector& s) {
for (int i = 0, j = s.size() - 1; i < s.size()/2; i++, j--) {
swap(s[i],s[j]);//swap互换两个容器的元素
}
}
题解代码2:
class Solution {
public:
void reverseString(vector& s) {
reverse(s.begin(), s.end());//reverse将容器内元素进行反转
}
};
2.力扣题号:541.反转字符串II
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
如果剩余字符少于 k 个,则将剩余字符全部反转。
如果剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符,其余字符保持原样。
链接:https://leetcode.cn/problems/reverse-string-ii
思路:
这道题目其实也是模拟,实现题目中规定的反转规则就可以了。
一些同学可能为了处理逻辑:每隔2k个字符的前k的字符,写了一堆逻辑代码或者再搞一个计数器,来统计2k,再统计前k个字符。
其实在遍历字符串的过程中,只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。
因为要找的也就是每2 * k 区间的起点,这样写,程序会高效很多。
所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
class Solution {
public:
string reverseStr(string s, int k) {
for (int i = 0; i < s.size(); i += 2*k) {
// 1. 每隔 2k 个字符的前 k 个字符进行反转
// 2. 剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符
if (i + k <= s.size()) {
reverse(s.begin() + i, s.begin() + i + k);
}
else {
// 3. 剩余字符少于 k 个,则将剩余字符全部反转。
reverse(s.begin() + i, s.end());
}
}
return s;
}
};
注解:在C++定义的容器类型中,只有vector和queue容器提供迭代器算数运算和除!=和==之外的关系运算:
iter+n //在迭代器上加(减)整数n,将产生指向容器中钱前面(后面)第n个元素的迭代器。新计算出来的迭代器必须指向容器中的元素或超出容器末端的下一个元素
iter-n
iter1+=iter2 //将iter1加上或减去iter2的运算结果赋给iter1。两个迭代器必须指向容器中的元素或超出容器末端的下一个元素
iter1-=iter2
iter1-iter2 //两个迭代器的减法,得出两个迭代器的距离。两个迭代器必须指向容器中的元素或超出容器末端的下一个元素
>,>=,<,<= //元素靠后的迭代器大于靠前的迭代器。两个迭代器必须指向容器中的元素或超出容器末端的下一个元素
3.力扣题目:剑指Offer 05.替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = “We are happy.”
输出:“We%20are%20happy.”
链接:https://leetcode.cn/problems/ti-huan-kong-ge-lcof
思路:
如果想把这道题目做到极致,就不要只用额外的辅助空间了!
首先扩充数组到每个空格替换成"%20"之后的大小。
然后从后向前替换空格,也就是双指针法:
i指向新长度的末尾,j指向旧长度的末尾。
有同学问了,为什么要从后向前填充,从前向后填充不行么?
从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
这么做有两个好处:
- 不用申请新数组。
- 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
时间复杂度,空间复杂度均超过100%的用户。
class Solution {
public:
string replaceSpace(string s) {
int count = 0;
int sOldSize = s.size();
for (int i = 0; i < sOldSize; i++) {
if (s[i] == ' ') {
count++;
}
}
//重新扩容
s.resize(s.size() + 2 * count);
int sNewSize = s.size();
//从后往前插入
for (int i = sOldSize -1, j = sNewSize - 1; i < j; i--, j--) {
if (s[i] != ' ') {
s[j] = s[i];
}
else {
s[j] = '0';
s[j - 1] = '2';
s[j - 2] = '%';
j -= 2;
}
}
return s;
}
};
4.力扣题号:151.反转字符串里的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
链接:https://leetcode.cn/problems/reverse-words-in-a-string
思路:
这道题目可以说是综合考察了字符串的多种操作。
一些同学会使用split库函数,分隔单词,然后定义一个新的string字符串,最后再把单词倒序相加,那么这道题题目就是一道水题了,失去了它的意义。
所以这里我还是提高一下本题的难度:不要使用辅助空间,空间复杂度要求为O(1)。
不能使用辅助空间之后,那么只能在原字符串上下功夫了。
想一下,我们将整个字符串都反转过来,那么单词的顺序指定是倒序了,只不过单词本身也倒序了,那么再把单词反转一下,单词不就正过来了。
所以解题思路如下:
- 移除多余空格
- 将整个字符串反转
- 将每个单词反转
举个例子,源字符串为:"the sky is blue "
- 移除多余空格 : “the sky is blue”
- 字符串反转:“eulb si yks eht”
- 单词反转:“blue is sky the”
这样我们就完成了翻转字符串里的单词。
思路很明确了,我们说一说代码的实现细节,就拿移除多余空格来说,一些同学会上来写如下代码:
void removeExtraSpaces(string& s) {
for (int i = s.size() - 1; i > 0; i--) {
if (s[i] == s[i - 1] && s[i] == ' ') {
s.erase(s.begin() + i);
}
}
// 删除字符串最后面的空格
if (s.size() > 0 && s[s.size() - 1] == ' ') {
s.erase(s.begin() + s.size() - 1);
}
// 删除字符串最前面的空格
if (s.size() > 0 && s[0] == ' ') {
s.erase(s.begin());
}
}
逻辑很简单,从前向后遍历,遇到空格了就erase。
如果不仔细琢磨一下erase的时间复杂度,还以为以上的代码是O(n)的时间复杂度呢。
想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作。
erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
//版本一
void removeExtraSpaces(string& s) {
int slowIndex = 0, fastIndex = 0; // 定义快指针,慢指针
// 去掉字符串前面的空格
while (s.size() > 0 && fastIndex < s.size() && s[fastIndex] == ' ') {
fastIndex++;
}
for (; fastIndex < s.size(); fastIndex++) {
// 去掉字符串中间部分的冗余空格
if (fastIndex - 1 > 0
&& s[fastIndex - 1] == s[fastIndex]
&& s[fastIndex] == ' ') {
continue;
} else {
s[slowIndex++] = s[fastIndex];
}
}
if (slowIndex - 1 > 0 && s[slowIndex - 1] == ' ') { // 去掉字符串末尾的空格
s.resize(slowIndex - 1);
} else {
s.resize(slowIndex); // 重新设置字符串大小
}
}
有的同学可能发现用erase来移除空格,在leetcode上性能也还行。主要是以下几点;:
- leetcode上的测试集里,字符串的长度不够长,如果足够长,性能差距会非常明显。
- leetcode的测程序耗时不是很准确的。
版本一的代码是一般的思考过程,就是 先移除字符串前的空格,再移除中间的,再移除后面部分。代码可以写的更精简,大家可以看 如下代码 removeExtraSpaces 函数的实现:
// 版本二
void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
int slow = 0;
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
s.resize(slow); //slow的大小即为去除多余空格后的大小。
}
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
还要实现反转字符串的功能,支持反转字符串子区间,如下:
// 反转字符串s中左闭右闭的区间[start, end]
void reverse(string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
整体代码如下:
class Solution {
public:
void reverse(string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
void removeExtraSpaces(string& s) {
int slowIndex = 0 , fastIndex = 0;//定义快慢指针
//去掉字符串前的空格
while (s.size() > 0 && s[fastIndex] == ' ') {
fastIndex++;
}
//去掉字符串中多余的字符
for (; fastIndex < s.size(); fastIndex++) {
if (fastIndex - 1 > 0 && s[fastIndex - 1] == s[fastIndex] && s[fastIndex] == ' ' ) {
continue;
}
else {
s[slowIndex++] = s[fastIndex];
}
}
//去掉字符串后的多余空格及大小
if (slowIndex - 1 > 0 && s[slowIndex - 1] == ' ') {
s.resize(slowIndex - 1);
}
else {
s.resize(slowIndex);
}
}
string reverseWords(string s) {
removeExtraSpaces(s);
reverse(s, 0, s.size()-1);
int start = 0;
for (int i = 0; i <= s.size(); i++) {
if (i == s.size() || s[i] == ' ') {//到达空格或字符串尾,说明一个单词结束
reverse(s, start, i - 1);//翻转
start = i + 1;//更新下一个单词的开始下标
}
}
return s;
}
};
5.力扣题号:151.反转字符串里的单词
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
链接:https://leetcode.cn/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof
思路:
为了让本题更有意义,提升一下本题难度:不能申请额外空间,只能在本串上操作。
不能使用额外空间的话,模拟在本串操作要实现左旋转字符串的功能还是有点困难的,可以通过局部反转+整体反转 达到左旋转的目的
代码如下:
class Solution {//版本1
public:
void reverse(string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
string reverseLeftWords(string s, int n) {
reverse(s, 0, n - 1);
reverse(s, n , s.size() - 1);
reverse(s, 0, s.size() - 1);
return s;
}
};
class Solution {//版本2
public:
string reverseLeftWords(string s, int n) {
reverse(s.begin(), s.begin() + n);
reverse(s.begin() + n , s.end());
reverse(s.begin(), s.end());
return s;
}
};
6.力扣题号:28.找出字符串中第一个匹配项的下标.
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string
思路:
利用KMP算法
class Solution {
public:
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
int j = 0;
int next[needle.size()];
getNext(next, needle);
for (int i = 0; i < haystack.size(); i++) {
while (j > 0 && haystack[i] != needle[j]) {
j = next[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == needle.size()) {
return i - j + 1;
}
}
return -1;
}
};
7.力扣题号:459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
链接:https://leetcode.cn/problems/repeated-substring-pattern
思路1:
KMP方法
代码:
class Solution {//KMP方法实现
public:
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != 0 && len % (len - next[len - 1]) == 0) {
return true;
}
return false;
}
};
思路2:
我们将两个 s 连在一起,并移除第一个和最后一个字符。如果 s 是该字符串的子串,那么 s 就满足题目要求。
class Solution {
public:
bool repeatedSubstringPattern(string s) {
//find找到字符串后返回查找的第一个字符位置,找不到返回-1
// int find(const string& str, int pos = 0) const; //查找str第一次出现位置,从pos开始查找
return (s + s).find(s, 1) != s.size();//从第一个位置开始找,若不是重复子串,一定找到最后的重复子串,位置索引等于s.size();
}
};