Python基础入门自学——15--常用内建模块
python内置了许多非常有用的模块,无需额外安装和配置,即可直接使用。
datetime
datetime是Python处理日期和时间的标准库。
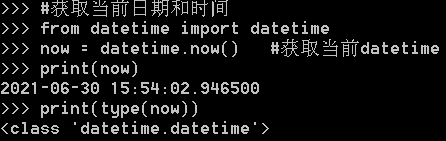
datetime是模块,datetime模块还包含一个datetime类,通过from datetime import datetime导入的才是datetime这个类。如果仅导入import datetime,则必须引用全名datetime.datetime。
datetime.now()返回当前日期和时间,其类型是datetime。

datetime转换为timestamp
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
你可以认为:
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
对应的北京时间是:
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00
可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
把一个datetime类型转换为timestamp只需要简单调用timestamp()方法:

Python的timestamp是一个浮点数,整数位表示秒。某些编程语言(如Java和JavaScript)的timestamp使用整数表示毫秒数,这种情况下只需要把timestamp除以1000就得到Python的浮点表示方法。
测试时的问题:
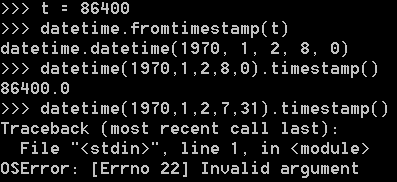
转换为timestamp只能从1970-1-2 8:0:0之后开始。
timestamp转换为datetime
要把timestamp转换为datetime,使用datetime提供的fromtimestamp()方法:
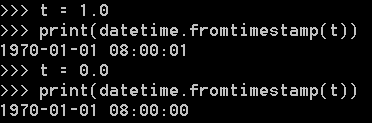
注意timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的。上述转换是在timestamp和本地时间做转换。
本地时间是指当前操作系统设定的时区。例如北京时区是东8区,则本地时间:2015-04-19 12:20:00,实际上就是UTC+8:00时区的时间:2015-04-19 12:20:00 UTC+8:00
而此刻的格林威治标准时间与北京时间差了8小时,也就是UTC+0:00时区的时间应该是:
2015-04-19 04:20:00 UTC+0:00
timestamp也可以直接被转换到UTC标准时区的时间:

str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:

字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。注意转换后的datetime是没有时区信息的。
datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:

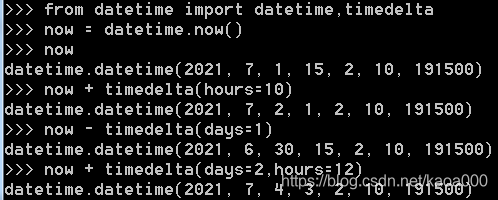
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
本地时间转换为UTC时间
本地时间是指系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。
一个datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,除非强行给datetime设置一个时区:

如果系统时区恰好是UTC+8:00,那么上述代码就是正确的,否则,不能强制设置为UTC+8:00时区。
时区转换
我们可以先通过utcnow()拿到当前的UTC时间,再转换为任意时区的时间:
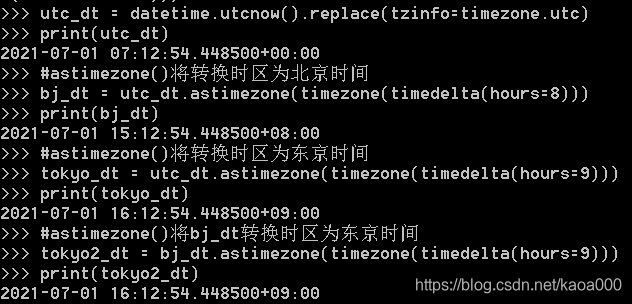
时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。利用带时区的datetime,通过astimezone()方法,可以转换到任意时区。
注:不是必须从UTC+0:00时区转换到其他时区,任何带时区的datetime都可以正确转换,例如上述bj_dt到tokyo_dt的转换。
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
如果要存储datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。
collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用。
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict。
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。如果要保持Key的顺序,可以用OrderedDict。OrderedDict的Key会按照插入的顺序排列,不是Key本身排序。
ChainMap
ChainMap可以把一组dict串起来并组成一个逻辑上的dict。ChainMap本身也是一个dict,但是查找的时候,会按照顺序在内部的dict依次查找。什么时候使用ChainMap最合适?举个例子:应用程序往往都需要传入参数,参数可以通过命令行传入,可以通过环境变量传入,还可以有默认参数。我们可以用ChainMap实现参数的优先级查找,即先查命令行参数,如果没有传入,再查环境变量,如果没有,就使用默认参数。
base64
Base64是一种用64个字符来表示任意二进制数据的方法。Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:

这样得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据字节数不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
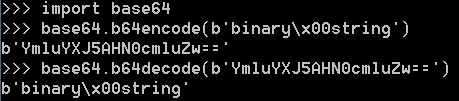
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_:
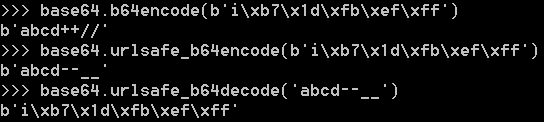
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码。Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
# 标准Base64:
'abcd' -> 'YWJjZA=='
# 自动去掉=:
'abcd' -> 'YWJjZA'
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
struct
Python没有专门处理字节的数据类型。但由于b'str'可以表示字节,所以,字节数组=二进制str。而在C语言中,可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
Python提供了一个struct模块来解决bytes和其他二进制数据类型的转换。struct的pack函数把任意数据类型变成bytes,unpack把bytes变成相应的数据类型。
hashlib
hashlib提供了常见的摘要算法,如MD5,SHA1等等。摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。MD5是最常见的摘要算法,一种常见的摘要算法是SHA1,比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞。
hmac
通过哈希算法,可以验证一段数据是否有效,方法就是对比该数据的哈希值。
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
如果salt是自己随机生成的,通常计算MD5时采用md5(message + salt)。但实际上,把salt看做一个“口令”,加salt的哈希就是:计算一段message的哈希时,根据不同口令计算出不同的哈希。要验证哈希值,必须同时提供正确的口令。
这实际上就是Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。和自定义的加salt算法不同,Hmac算法针对所有哈希算法都通用,无论是MD5还是SHA-1。采用Hmac替代自己的salt算法,可以使程序算法更标准化,也更安全。
Python内置的hmac模块实现了标准的Hmac算法,它利用一个key对message计算“杂凑”后的hash。
itertools
内建模块itertools提供了非常有用的用于操作迭代对象的函数。
itertools提供几个“无限”迭代器:
>>> import itertools
>>> natuals = itertools.count(1)
>>> for n in natuals:
... print(n)
...
1
2
3
...
因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()会把传入的一个序列无限重复下去:
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs:
... print(c)
...
'A'
'B'
'C'
'A'
'B'
'C'
...
同样停不下来。
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
>>> ns = itertools.repeat('A', 3)
>>> for n in ns:
... print(n)
...
A
A
A
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
itertools提供的几个迭代器操作函数更加有用:
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
>>> for c in itertools.chain('ABC', 'XYZ'):
... print(c)
# 迭代效果:'A' 'B' 'C' 'X' 'Y' 'Z'
groupby()把迭代器中相邻的重复元素挑出来放在一起:
>>> for key, group in itertools.groupby('AAABBBCCAAA'):
... print(key, list(group))
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果要忽略大小写分组,就可以让元素'A'和'a'都返回相同的key:
>>> for key, group in itertools.groupby('AaaBBbcCAAa', lambda c: c.upper()):
... print(key, list(group))
...
A ['A', 'a', 'a']
B ['B', 'B', 'b']
C ['c', 'C']
A ['A', 'A', 'a']
itertools模块提供的全部是处理迭代功能的函数,它们的返回值不是list,而是Iterator,只有用for循环迭代的时候才真正计算。
contextlib
在Python中,读写文件这样的资源要特别注意,必须在使用完毕后正确关闭它们。with语句允许我们非常方便地使用资源,而不必担心资源没有关闭。并不是只有open()函数返回的fp对象才能使用with语句。实际上,任何对象,只要正确实现了上下文管理,就可以用于with语句。
实现上下文管理是通过__enter__和__exit__这两个方法实现的。

这样就可以把自己写的资源对象用于with语句:
![]()
@contextmanager
编写__enter__和__exit__仍然很繁琐,因此Python的标准库contextlib提供了更简单的写法:

@contextmanager这个decorator接受一个generator,用yield语句把with ... as var把变量输出出去,然后,with语句就可以正常地工作了:
with create_query('Bob') as q:
q.query()
很多时候,希望在某段代码执行前后自动执行特定代码,也可以用@contextmanager实现:
@contextmanager
def tag(name):
print("<%s>" % name)
yield
print("" % name)
with tag("h1"):
print("hello")
print("world")
上述代码执行结果为:
hello
world
代码的执行顺序是:
with语句首先执行yield之前的语句,因此打印出
;
yield调用会执行with语句内部的所有语句,因此打印出hello和world;
最后执行yield之后的语句,打印出
。因此,@contextmanager让我们通过编写generator来简化上下文管理。
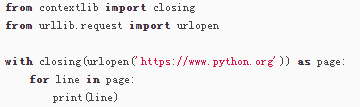
@closing
如果一个对象没有实现上下文,就不能把它用于with语句。这个时候,可以用closing()来把该对象变为上下文对象。例如,用with语句使用urlopen():
closing也是一个经过@contextmanager装饰的generator,这个generator编写起来其实非常简单:

它的作用就是把任意对象变为上下文对象,并支持with语句。
@contextlib还有一些其他decorator,便于我们编写更简洁的代码。