MIT 6.824 Lab 1 MapReduce
MapReduce
目标
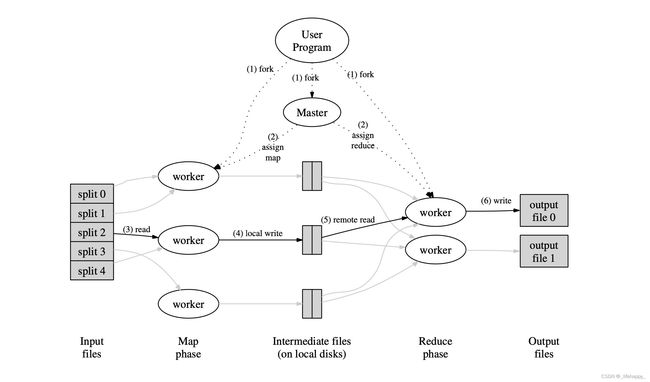
根据论文所说明的,有MASTER和WORKER两类工作节点,以下实现大都按照论文所说的实现,但是在对MASTER的实现上有所改动:
- MASTER向WORKER发送心跳检测,这里改为了对分配出去的任务进行超时监控。
MASTER:
- 接收MapReduce任务(需要处理的文件),并生成对应的Map任务。
- 接受WORKER的任务分配请求,按需给WORKER分配任务(Map or Reduce)。
- 对分配给WORKER的任务(Map or Reduce)进行超时监控。
- 当Map任务完成时,自动创建对应的Reduce任务。
- 当Reduce任务完成时,结束所用工作,退出程序。
WORKER:
- 向MASTER提交任务分配请求。
- 根据MASTER的任务分配请求进行判定处理(Map、Reduce、Waite、Exit)。
- 当任务(Map or Reduce)完成时,通知MASTER。
实现
ProcessStatus
用来表示Master当前的状态,有如下四种:
- 接受完MapReduce文件,处于Maping状态。
- 已经成功处理完Map任务,处于Reducing状态。
- 所有的Map和Reduce任务都已经完成,处于Done状态。
- 当所有的Map(or Reduce)任务都已经分配出去,但是还没有接受到所有的成功反馈,处于Waiting状态。
type MasterStatu int
const (
Maping MasterStatu = 0
Reducing MasterStatu = 1
Done MasterStatu = 2
Waiting MasterStatu = 3
)
RPC定义
提交任务分配请求(GetOneJob)
Request
type GetOneJobRequest struct {
}
Response
-
任务的类型,可以根据MasterStatu来判断,有四种:Map,Reduce,Waite,Done。
-
如果是Map任务:
需要进行Map的文件路径。
Master给当前Worker命名的编号,为了给存储中间键值的文件命名。
后续有多少个Reduce任务,为了给存储分散中间键值的文件命名。
-
如果是Reduce任务:
存储哪些Map任务的Worker成功了,为了寻找Reduce任务的文件。
当前Worker分配的是第几个Reduce任务。
type GetOneJobResponce struct {
JobType MasterStatu
FilePath string
WorkerNumber int
NReduce int
PathList []int
ReduceNumber int
}
提交任务完成记录(JobDone)
Request
-
当前完成的是什么类型的任务,Map or Reduce。
-
如果是Map任务:
当前完成的Map任务的文件地址。
当前Worker的编号。
-
如果是Reduce任务:
当前完成的Reduce任务的编号。
type JobDoneRequest struct {
JobType MasterStatu
FilePath string
WorkerNumber int
}
Response
type JobDoneResponse struct {
}
Master
Master的结构体描述,有当前状态、Map任务、Reduce任务等。
type Master struct {
Mu sync.Mutex
Statu MasterStatu
NReduce int
NMapJob int
WorkerNumber int // 进行reduce任务的时候,给worker编号,为了存放intermediate信息
MapJob map[string]bool // 没有开始做的MapJob,按照文件拆分
MapJobDone map[string]int // 已经做完的MapJob,存放(key = file, value = worknumber)
MapJobList []int // 存放所有的worknumber
ReduceJob map[int]bool // 没有开始做的ReduceJob,按照 0 ~ nReduce 编号
ReduceJobDone map[int]bool // 已经做完的ReduceJob
}
GetOneJob
根据Rpc的定义,应该有一个分配任务的函数,这里分配任务也应该是按照Master当前的状态去分配:
func (m *Master) GetOneJob(req *GetOneJobRequest, resp *GetOneJobResponce) error {
m.Mu.Lock()
defer m.Mu.Unlock()
switch m.Statu {
case Maping:
JobType, FilePath, WorkerNumber := m.AssignMapJob()
resp.JobType = JobType
resp.FilePath = FilePath
resp.WorkerNumber = WorkerNumber
resp.NReduce = m.NReduce
case Reducing:
JobType, PathList, ReduceNumber := m.AssignReduceJob()
resp.JobType = JobType
resp.PathList = PathList
resp.ReduceNumber = ReduceNumber
case Done:
resp.JobType = Done
}
return nil
}
-
AssignMapJob
如果没有MapJob说明,所有任务都在执行,并且还有任务没有完成,所以Worker应该是要进入Waite,否则一定有Map任务分配给Worker,任取一个MapJob出来即可,对应的要开一个协程来对超时的任务进行重加载。
func (m *Master) AssignMapJob() (MasterStatu, string, int) { if len(m.MapJob) == 0 { return Waiting, "", 0 } // 找到map任务 JobType := Maping FilePath := "" for k := range m.MapJob { FilePath = k break } delete(m.MapJob, FilePath) go MapJobTLE(FilePath, m) return JobType, FilePath, m.GetWorkerNumber() } -
AssignReduceJob
具体逻辑同AssignMapJob。
func (m *Master) AssignReduceJob() (MasterStatu, []int, int) { if len(m.ReduceJob) == 0 { return Waiting, []int{}, 0 } // 一定找到一个任务 ReduceNumber := 0 for k := range m.ReduceJob { ReduceNumber = k } delete(m.ReduceJob, ReduceNumber) go ReduceJobTLE(ReduceNumber, m) return Reducing, m.MapJobList, ReduceNumber }
JobDone
这里通知的只有两种状态:Map or Reduce。由于是并发,所以只要记录第一个完成该任务的信息即可。
当所有Map任务都完成时,记得初始化Reduce任务,并切换进入Reducing状态。
当所有Reduce任务都完成时,同样也是切换进入Done状态。
func (m *Master) JobDone(req *JobDoneRequest, resp *JobDoneResponse) error {
m.Mu.Lock()
defer m.Mu.Unlock()
switch req.JobType {
case Maping:
_, done := m.MapJobDone[req.FilePath]
if !done {
m.MapJobDone[req.FilePath] = req.WorkerNumber
delete(m.MapJob, req.FilePath)
}
if len(m.MapJobDone) == m.NMapJob {
m.initReduceJob()
}
case Reducing:
m.ReduceJobDone[req.WorkerNumber] = true
delete(m.ReduceJob, req.WorkerNumber)
if len(m.ReduceJobDone) == m.NReduce {
m.Statu = Done
}
}
return nil
}
Worker
Worker
Worker的入口函数,具体作用就是不断地向Master发送Rpc请求,去获取任务。
DoMap和DoReduce的实现可以直接参照给定的参考程序,基本逻辑都是差不多的,一些区别:
- Map的中间键值需要通过ihash函数将其分为nReduce份存储。
- Reduce应该是从多份文件中读到中间键值再进行操作。
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
resp := &GetOneJobResponce{}
ok := call("Master.GetOneJob", &GetOneJobRequest{}, resp)
if !ok || resp.JobType == Done { // master已经关闭,或者任务执行完了
return
}
// fmt.Printf("%v\n", resp)
switch resp.JobType {
case Maping:
DoMap(mapf, resp.FilePath, resp.WorkerNumber, resp.NReduce)
case Reducing:
DoReduce(reducef, resp.PathList, resp.ReduceNumber)
case Waiting:
time.Sleep(5 * time.Second)
}
}
}
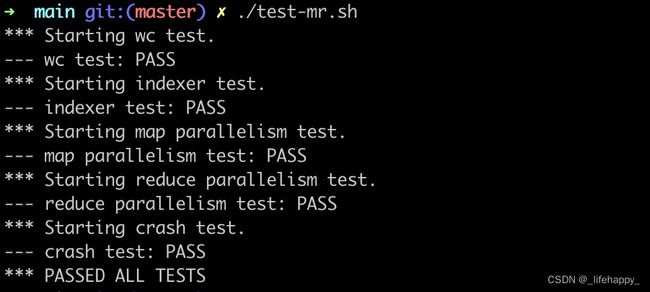
成果